Modele de regresie
Curs 8 - Regresie liniară multiplă - Modelul condiționat normal
1 Modelul (condiționat) normal
Considerăm modelul de regresie \(\symbf Y = \symbf X\symbf \beta + \symbf \varepsilon\) în care \(\symbf Y\in\mathbb{R}^n\) este vectorul răspuns, \(\symbf X = \left[\mathbf{1}|\symbf X_1|\cdots|\symbf X_p\right]\in\mathcal{M}_{n, p+1}(\mathbb{R})\) este matricea de design, \(\symbf \beta\in\mathbb{R}^{p+1}\) este vectorul parametrilor și \(\symbf \varepsilon\in\mathbb{R}^n\) este vectorul termenilor eroare. Până acum, ipotezele modelului erau
\[ \begin{array}{ll} \mathcal{H}_1: \, rang(\symbf X) = p+1\\ \mathcal{H}_2: \, \mathbb{E}[\symbf \varepsilon] = 0,\, Var(\symbf \varepsilon) = \sigma^2 I_n \end{array} \]
și proprietățile estimatorilor rezultați din metoda celor mai mici pătrate au fost obținute fără a face apel la repartiția termenilor eroare.
În această secțiune ne propunem să studiem proprietățile statistice ale modelului de regresie liniară plasându-ne într-un context parametric și anume în contextul modelului gaussian:
\[ \begin{array}{ll} \mathcal{H}_1: \, rang(\symbf X) = p+1\\ \mathcal{H}_2': \, \symbf \varepsilon \sim\mathcal{N}(0, \sigma^2 I_n) \end{array} \]
Observăm că ipoteza \(\mathcal{H}_2'\) este un caz particular al ipotezei \(\mathcal{H}_2\) și în plus implică faptul că reziduurile sunt independente și identic repartizate condiție care nu era necesară până acum. Ipoteza de normalitate a erorilor ne permite să scriem funcția de verosimilitate asociată modelului, să deducem repartițiile estimatorilor propuși, să construim intervale de încredere și să testăm ipoteze statistice asupra parametrilor modelului.
2 Estimatori obținuți prin metoda verosimilității maxime
Odată cu ipoteza suplimentară de normalitate a termenilor eroare, putem determina estimatorii de verosimilitate maximă. Rezultatul următor face legătura dintre estimatorii obținuți prin metoda celor mai mici pătrate din capitolul anterior și cei obținuți prin metoda verosimilității maxime.
Propoziția 2.1 Considerăm modelul de regresie liniară \(\symbf Y = \symbf X\symbf \beta + \symbf\varepsilon\) sub ipotezele \(\mathcal{H}_1\) și \(\mathcal{H}_2'\) de mai sus. Atunci estimatorii de verosimilitate maximă pentru \(\symbf \beta\) și \(\sigma^2\) sunt dați de
\[ \hat{\symbf\beta}_{VM} = (\symbf{X}^\intercal \symbf X)^{-1}\symbf{X}^\intercal \symbf Y, \quad \hat{\sigma}_{VM}^2 = \frac{\lVert\symbf Y - \symbf X\hat{\symbf\beta}_{VM}\rVert^2}{n}=\frac{n - (p+1)}{n}\hat{\sigma}^2. \]
Demonstrație (Propoziția 2.1). Începem prin a observa că din modelul de regresie
\[ y_i = \symbf x_i^\intercal\symbf\beta + \varepsilon_i \]
și conform ipotezei \(\mathcal{H}_2'\) avem \(\varepsilon_i\sim\mathcal{N}(0, \sigma^2)\) prin urmare \(y_i\sim\mathcal{N}(\symbf x_i^\intercal\symbf\beta, \sigma^2)\) și în plus \(y_i\) sunt variabile aleatoare independente deoarece \(\varepsilon_i\) sunt independente. Astfel funcția de verosimilitate se scrie
\[ \begin{aligned} L(\symbf\beta, \sigma^2;\symbf Y) &= \prod_{i = 1}^{n}f_{Y}(y_i) = \left(\frac{1}{\sqrt{2\pi\sigma^2}}\right)^n e^{-\frac{1}{2\sigma^2}\sum_{i = 1}^{n}(y_i - \symbf x_i^\intercal\symbf\beta)^2} \\ &= \left(\frac{1}{\sqrt{2\pi\sigma^2}}\right)^n e^{-\frac{1}{2\sigma^2}\lVert\symbf Y - \symbf X\symbf\beta\rVert^2} \end{aligned} \]
ceea ce conduce la logaritmul funcției de verosimilitate
\[ \ell(\symbf\beta, \sigma^2;\symbf Y) = \log L(\symbf\beta, \sigma^2;\symbf Y) = -\frac{n}{2}\log{2\pi\sigma^2} -\frac{1}{2\sigma^2}\lVert\symbf Y - \symbf X\symbf\beta\rVert^2. \]
Vrem să determinăm
\[ (\hat{\symbf\beta}_{VM}, \hat{\sigma}_{VM}^2) = \underset{(\symbf\beta, \sigma^2)\in\mathbb{R}^{p+1}\times(0,\infty)}{\arg\max} \ell(\symbf\beta, \sigma^2;\symbf Y) \]
și observăm că pentru \(\sigma^2\) fixat, a maximiza funcția \(\ell(\symbf\beta, \sigma^2;\symbf Y)\) revine la a determina valoarea lui \(\symbf\beta\) care minimizează \(\lVert\symbf Y - \symbf X\symbf\beta\rVert^2\), aceasta ne fiind alta decât \(\hat{\symbf\beta}\) obținut prin metoda celor mai mici pătrate. Astfel găsim că
\[ \hat{\symbf\beta}_{VM} = \hat{\symbf\beta} = (\symbf{X}^\intercal \symbf X)^{-1}\symbf{X}^\intercal \symbf Y. \]
Pentru a determina \(\hat{\sigma}_{VM}^2\) să observăm că problema revine la a determina soluția ecuației
\[ \frac{\partial l(\hat{\symbf\beta}_{VM}, \sigma^2;\symbf Y)}{\partial \sigma^2} = -\frac{n}{2\sigma^2} + \frac{1}{2\sigma^4}\lVert\symbf Y - \symbf X\hat{\symbf\beta}_{VM}\rVert^2 = 0 \]
care este \(\hat{\sigma}_{VM}^2 = \frac{\lVert\symbf Y - \symbf X\hat{\symbf\beta}_{VM}\rVert^2}{n}=\frac{\lVert\symbf Y - \symbf X\hat{\symbf\beta}\rVert^2}{n}\). Comparând acest rezultat cu cel obținut prin metoda celor mai mici pătrate observăm că
\[ \hat{\sigma}_{VM}^2 = \frac{n - (p+1)}{n}\hat{\sigma}^2, \]
deci estimatorul de verosimilitate maximă \(\hat{\sigma}_{VM}^2\) a lui \(\sigma^2\) este un estimator deplasat.
Se poate arăta că estimatorii de verosimilitate maximă \(\hat{\symbf\beta}_{VM} = \hat{\symbf\beta}\) și \(\hat{\sigma}_{VM}^2 = \frac{n - (p+1)}{n}\hat{\sigma}^2\) și prin urmare și cei obținuți prin metoda celor mai mici pătrate sunt suficienți în sensul că niciun alt estimator nu poate să îmbunătățească estimarea lui \(\symbf\beta\) și \(\sigma^2\) plecând de la eșantionul dat (Rencher and Schaalje 2008). Mai mult, dacă în ipotezele \(\mathcal{H}_1\) și \(\mathcal{H}_2\) estimatorul \(\hat{\symbf\beta}\) era de varianță minimală în clasa estimatorilor liniari nedeplasați (Teorema Gauss-Markov - Propoziția 1.3 din Cursul 6) în ipoteza suplimentară de normalitate \(\mathcal{H}_2'\) acest rezultat se extinde la clasa tuturor estimatorilor nedeplasați. În același mod și \(\hat{\sigma}^2\) are varianță minimală în clasa tuturor estimatorilor nedeplasați pentru \(\sigma^2\) (Rencher and Schaalje 2008).
În cele ce urmează vom considera estimatorul nedeplasat \(\hat{\sigma}^2 = \frac{\lVert\symbf Y - \symbf X\hat{\symbf\beta}\rVert^2}{n - (p+1)} = \frac{\sum_{i=1}^{n}\hat{\varepsilon}_i^2}{n - (p+1)}\) ca estimator al lui \(\sigma^2\).
3 Repartițiile estimatorilor
Înainte de a investiga repartițiile estimatorilor \(\hat{\symbf\beta}\) și \(\hat{\sigma}^2\) pentru modelul de regresie liniară multiplă sub ipoteza de normalitate, să reamintim câteva noțiuni legate de vectorii gaussieni (pentru mai multe detalii se poate consulta (Seber and Lee 2003, Capitolul 2) sau (Jacod and Protter 2003, Capitolul 16)).
Spunem că un vector \(\symbf Y = (Y_1,\ldots,Y_n)\in\mathbb{R}^n\) este un vector gaussian dacă toate combinațiile liniare \(\sum_{i=1}^{n}a_iY_i\) sunt repartizate normal (posibil degenerat dacă toți coeficienții sunt nuli). Acest vector admite o medie \(\symbf\mu = \mathbb{E}[\symbf Y]\) și o matrice de varianță-covarianță \(\Sigma_{\symbf Y} = \mathbb{E}[(\symbf Y - \symbf\mu)(\symbf Y - \symbf\mu)^\intercal]\) care caracterizează complet repartiția lui \(\symbf Y\). În acest caz notăm \(\symbf Y \sim\mathcal{N}(\symbf\mu, \Sigma_{\symbf Y})\). Un vector gaussian \(\symbf Y\) admite o densitate de repartiție \(f_{\symbf Y}\) pe \(\mathbb{R}^n\) dacă și numai dacă matricea sa de varianță-covarianță \(\Sigma_{\symbf Y}\) este inversabilă și în acest caz
\[ f_{\symbf Y}(\symbf y) = \frac{1}{(2\pi)^{\frac{n}{2}}\sqrt{\det{\Sigma_{\symbf Y}}}} e^{-\frac{1}{2}(\symbf y - \symbf \mu)^\intercal \Sigma_{\symbf Y}^{-1}(\symbf y - \symbf \mu)} \]
În cazul în care matricea \(\Sigma_{\symbf Y}\) nu este inversabilă înseamnă că \(\symbf Y\) ia valori într-un subspațiu de dimensiune \(n_0<n\) unde este repartizat ca un vector gaussian de dimensiune \(n_0\).
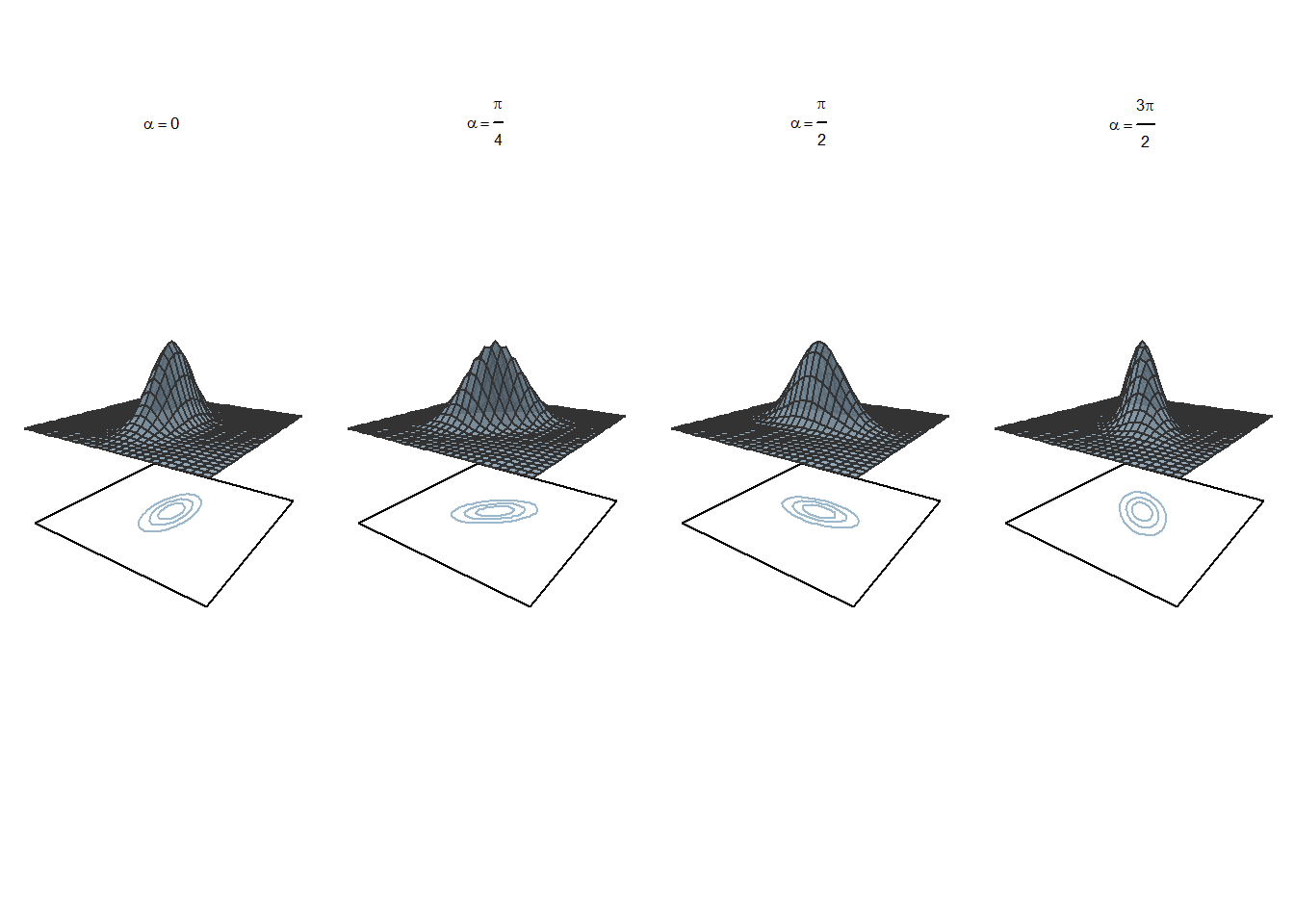
Figura @ref(fig:reg-c8-fig1) de mai jos prezintă patru repartiții normale bivariate (\(n=2\)) \(\symbf Y \sim\mathcal{N}(\symbf\mu, \Sigma_{\symbf Y})\), cu \(\symbf\mu = (\mu_1, \mu_2)^\intercal\) iar \(\Sigma_{\symbf Y} = \begin{pmatrix}\sigma_{11} & \sigma_{12}\\ \sigma_{21} & \sigma_{22}\end{pmatrix}= \begin{pmatrix}\sigma_{1}^2 & \sigma_{12}\\ \sigma_{12} & \sigma_{2}^2\end{pmatrix}\), rotite cu unghiul \(\alpha\). În acest caz densitatea de repartiție este
\[ f_{\symbf Y}(y_1,y_2) = \frac{1}{2\pi\sigma_1\sigma_2\sqrt{1-\rho^2}}e^{-\frac{1}{2(1-\rho^2)}\left[\left(\frac{y_1 - \mu_1}{\sigma_1}\right)^2 - 2\rho\left(\frac{y_1 - \mu_1}{\sigma_1}\right)\left(\frac{y_2 - \mu_2}{\sigma_2}\right) + \left(\frac{y_2 - \mu_2}{\sigma_2}\right)^2\right]} \]
unde \(\rho = \frac{\sigma_{12}}{\sigma_1\sigma_2}\) este coeficientul de corelație.
Una dintre proprietățile importante ale vectorilor gaussieni este stabilitatea prin transformări afine: dacă \(\symbf A\in\mathcal{M}_{m,n}(\mathbb{R})\) și \(\symbf b\in\mathcal{M}_{m,1}(\mathbb{R})\) sunt respectiv o matrice și un vector de scalari atunci
\[ \symbf Y \sim\mathcal{N}(\symbf\mu, \Sigma_{\symbf Y}) \Longrightarrow \symbf A\symbf Y + \symbf b \sim\mathcal{N}(\symbf A\symbf\mu + \symbf b, \symbf A\Sigma_{\symbf Y}\symbf A^\intercal) \]
De asemenea, plecând de la funcția caracteristică, se poate verifica proprietatea de independență a componentelor unui vector gaussian care ne spune că acestea sunt independente dacă și numai dacă matricea de varianță-covarianță este o matrice diagonală (Jacod and Protter 2003).
Avem următorul rezultat care face legătura dintre repartiția normală și repartiția \(\chi^2\):
Propoziția 3.1 Fie \(\symbf Y \sim\mathcal{N}(\symbf\mu, \Sigma_{\symbf Y})\) un vector gaussian în \(\mathbb{R}^n\). Dacă \(\Sigma_{\symbf Y}\) este o matrice inversabilă atunci
\[ (\symbf Y - \symbf \mu)^\intercal \Sigma_{\symbf Y}^{-1}(\symbf Y - \symbf \mu) \sim \chi_n^2 \]
repartiția \(\chi^2\) cu \(n\) grade de libertate.
Deoarece matricea de varianță-covarianță \(\Sigma_{\symbf Y}\) este o matrice simetrică și pozitiv definită atunci din Teorema de descompunere spectrală ea se poate descompune sub forma \(\Sigma_{\symbf Y} = \symbf Q\symbf\Delta \symbf Q^\intercal\) unde \(\symbf Q = [\symbf v_1,\ldots,\symbf v_n]\) este o matrice ortogonală (\(\symbf Q^\intercal = \symbf Q^{-1}\)) formată din vectorii proprii \(\symbf v_1,\ldots,\symbf v_n\) corespunzători valorilor proprii \(\lambda_1,\ldots,\lambda_n\), iar \(\symbf \Delta\) este matricea diagonală \(\mathrm{diag}(\lambda_1,\ldots,\lambda_n)\). Dacă notăm cu \(\symbf \Delta^{-\frac{1}{2}}\) matricea diagonală de coeficienți diagonali \(\frac{1}{\sqrt{\lambda_1}},\ldots,\frac{1}{\sqrt{\lambda_n}}\) (aceste fracții există deoarece pozitiv definirea matricei \(\Sigma_{\symbf Y}\) implică faptul că valorile proprii \(\lambda_i>0\), \(i = 1,\ldots,n\)) atunci
\[ \Sigma_{\symbf Y} = \symbf Q\symbf\Delta \symbf Q^\intercal \Longrightarrow \Sigma_{\symbf Y}^{-1} = \symbf Q\symbf\Delta^{-1} \symbf Q^\intercal = \left(\symbf Q\symbf\Delta^{-\frac{1}{2}} \symbf Q^\intercal\right)\left(\symbf Q\symbf\Delta^{-\frac{1}{2}} \symbf Q^\intercal\right) = \Sigma_{\symbf Y}^{-\frac{1}{2}}\Sigma_{\symbf Y}^{-\frac{1}{2}}. \]
Prin urmare găsim că
\[ (\symbf Y - \symbf \mu)^\intercal \Sigma_{\symbf Y}^{-1}(\symbf Y - \symbf \mu) = \left(\Sigma_{\symbf Y}^{-\frac{1}{2}}(\symbf Y - \symbf \mu)\right)^\intercal\left(\Sigma_{\symbf Y}^{-\frac{1}{2}}(\symbf Y - \symbf \mu)\right) \]
și cum vectorii gaussieni rămân gaussieni și prin aplicarea unor transformări afine (vezi rezultatul de mai sus) avem că
\[ \symbf Y \sim\mathcal{N}(\symbf\mu, \Sigma_{\symbf Y}) \Longrightarrow \Sigma_{\symbf Y}^{-\frac{1}{2}}(\symbf Y - \symbf \mu) \sim\mathcal{N}(0, I_n). \]
Astfel vectorul \(\symbf V = [\symbf V_1,\ldots,\symbf V_n]^\intercal = \Sigma_{\symbf Y}^{-\frac{1}{2}}(\symbf Y - \symbf \mu)\), care nu este altceva decât vectorul \(\symbf Y\) centrat și redus, este gaussian standard (\(\symbf V_j\sim\mathcal{N}(0,1)\) și \(\symbf V_i\) și \(\symbf V_j\) sunt independente) și
\[ (\symbf Y - \symbf \mu)^\intercal \Sigma_{\symbf Y}^{-1}(\symbf Y - \symbf \mu) = \lVert \symbf V\rVert^2 = \symbf V_1^2 + \cdots + \symbf V_n^2\sim\chi^2_n. \]
Următorul rezultat, cunoscut sub denumirea de Teorema lui Cochran (a se vedea (Sen and Srivastava 2012) sau (Greene 2011) pentru o demonstrație a acestui rezultat), asigură că descompunerea unui vector gaussian în componente independente pe subspații ortogonale ne dă vectori independenți a căror repartiție o putem explicita. Această teoremă poate fi văzută și ca o generalizare a Teoremei lui Pitagora:
Propoziția 3.2 (Teorema lui Cochran) Fie \(\symbf Y \sim\mathcal{N}(\symbf\mu, \sigma^2 I_n)\), \(\mathcal{M}\subset\mathbb{R}^n\) un subspațiu de dimensiune \(p\), \(P\) matricea de proiecție ortogonală pe \(\mathcal{M}\) și \(P_\perp = I_n - P\) matricea de proiecție ortogonală pe \(\mathcal{M}^\perp\). Au loc următoarele proprietăți:
\(P\symbf Y\sim\mathcal{N}(P\symbf\mu, \sigma^2 P)\) și \(P_\perp\symbf Y\sim\mathcal{N}(P_\perp\symbf\mu, \sigma^2 P_\perp)\)
vectorii \(P\symbf Y\) și \(P_\perp\symbf Y = \symbf Y - P\symbf Y\) sunt independenți
\(\frac{\lVert P(\symbf Y - \symbf\mu)\rVert^2}{\sigma^2}\sim\chi_p^2\) și \(\frac{\lVert P_\perp(\symbf Y - \symbf\mu)\rVert^2}{\sigma^2}\sim\chi_{n-p}^2\).
Acum avem instrumentele necesare pentru a deduce repartițiile estimatorilor în modelul gaussian de regresie liniară.
Propoziția 3.3 Considerăm modelul de regresie liniară \(\symbf Y = \symbf X\symbf \beta + \symbf \varepsilon\), sub ipotezele \(\mathcal{H}_1\) și \(\mathcal{H}_2'\). Dacă presupunem că varianța \(\sigma^2\) este cunoscută atunci au loc proprietățile
Vectorul \(\hat{\symbf \beta}\) este un vector gaussian de medie \(\symbf \beta\) și matrice de varianță-covarianță \(\sigma^2(\symbf X^\intercal\symbf X)^{-1}\), i.e. \(\hat{\symbf \beta}\sim\mathcal{N}(\symbf \beta, \sigma^2(\symbf X^\intercal\symbf X)^{-1})\)
\(\hat{\symbf \beta}\) și \(\hat{\sigma}^2\) sunt independenți
\([n-(p+1)]\frac{\hat{\sigma}^2}{\sigma^2}\sim\chi^2_{n-(p+1)}\)
Demonstrație (Propoziția 3.3). Avem
- Pentru a arăta că vectorul \(\hat{\symbf \beta}\) este un vector gaussian vom folosi expresia acestuia obținută prin metoda celor mai mici pătrate
\[ \hat{\symbf \beta} = (\symbf X^\intercal\symbf X)^{-1}\symbf X^\intercal\symbf Y = (\symbf X^\intercal\symbf X)^{-1}\symbf X^\intercal(\symbf X\symbf \beta + \symbf \varepsilon) = \symbf \beta + (\symbf X^\intercal\symbf X)^{-1}\symbf X^\intercal \symbf \varepsilon. \]
Conform ipotezei \(\mathcal{H}_2'\), \(\symbf \varepsilon\sim\mathcal{N}(0,\sigma^2 I_n)\) este un vector gaussian prin urmare și \(\hat{\symbf \beta} = \symbf \beta + \underbrace{(\symbf X^\intercal\symbf X)^{-1}\symbf X^\intercal}_{\symbf A} \symbf \varepsilon\) este tot un vector gaussian repartizat
\[ \hat{\symbf \beta} = \symbf \beta + \underbrace{(\symbf X^\intercal\symbf X)^{-1}\symbf X^\intercal}_{\symbf A} \symbf \varepsilon = \symbf \beta + \symbf A\symbf \varepsilon \sim \mathcal{N}\left(\symbf \beta, \symbf A \sigma^2 I_n\symbf A^\intercal\right) = \mathcal{N}\left(\symbf \beta, \sigma^2(\symbf X^\intercal\symbf X)^{-1}\right) \]
deoarece \(\symbf A \sigma^2 I_n\symbf A^\intercal = (\symbf X^\intercal\symbf X)^{-1}\symbf X^\intercal \sigma^2 I_n \symbf X(\symbf X^\intercal\symbf X)^{-1} = \sigma^2(\symbf X^\intercal\symbf X)^{-1}\).
- Fie \(\mathcal{M}(X)\) subspațiul lui \(\mathbb{R}^n\) generat de coloanele matricei \(\symbf X\) și fie \(P_{X} = \symbf X(\symbf X^\intercal\symbf X)^{-1}\symbf X^\intercal\) matricea de proiecție ortogonală pe \(\mathcal{M}(X)\). Avem
\[ \hat{\symbf \beta} = (\symbf X^\intercal\symbf X)^{-1}\symbf X^\intercal\symbf Y = (\symbf X^\intercal\symbf X)^{-1}\symbf X^\intercal\left(\underbrace{\symbf X(\symbf X^\intercal\symbf X)^{-1}\symbf X^\intercal}_{=P_X}\right)\symbf Y = (\symbf X^\intercal\symbf X)^{-1}\symbf X^\intercal P_X\symbf Y \]
prin urmare \(\hat{\symbf \beta}\) este un vector aleator ce depinde de \(P_X\symbf Y\). Observăm de asemenea că din definiția lui \(\hat{\sigma}^2\),
\[ \hat{\sigma}^2 = \frac{\lVert\hat{\symbf\varepsilon}\rVert^2}{n - (p+1)} = \frac{\lVert \symbf Y - P_X\symbf Y\rVert^2}{n - (p+1)} \]
acesta este o funcție de \(\symbf Y - P_X\symbf Y\). Aplicând Teorema lui Cochran (Propoziția 3.2 de mai sus) observăm că vectorii \(P_X\symbf Y\) și \(\symbf Y - P_X\symbf Y\) sunt independenți prin urmare și \(\hat{\symbf \beta}\) și \(\hat{\sigma}^2\) sunt independenți ca funcții de vectori independenți.
- Notând cu \(P_{X^\perp}\) proiecția ortogonală pe subspațiul ortogonal \(\mathcal{M}(X)^\perp\), subspațiu de dimensiune \(n-(p+1)\), avem
\[ \hat{\symbf\varepsilon} = \symbf Y - P_X\symbf Y = P_{X^\perp}\symbf Y = P_{X^\perp}(\underbrace{\symbf X\symbf \beta}_{\in\mathcal{M}(X)} + \symbf \varepsilon) = P_{X^\perp}\symbf \varepsilon, \]
unde \(\symbf \varepsilon\sim\mathcal{N}(0,\sigma^2 I_n)\).
Din Teorema lui Cochran (Propoziția 3.2) găsim că
\[ (n-(p+1))\frac{\hat{\sigma}^2}{\sigma^2} = \frac{\lVert P_{X^\perp}\symbf \varepsilon\rVert^2}{\sigma^2} = \frac{\lVert P_{X^\perp}\left(\symbf \varepsilon - \mathbb{E}[\symbf \varepsilon]\right)\rVert^2}{\sigma^2}\sim \chi^2_{n - (p+1)}. \square \]
Putem observa că rezultatul anterior nu este suficient pentru a determina o regiune de încredere pentru coeficienții modelului de regresie \(\symbf \beta\) deoarece varianța \(\sigma^2\) a fost presupusă cunoscută, fenomen care nu este aplicabil în caz general. Rezultatul următor vine să acopere acest deficit.
Propoziția 3.4 Considerăm modelul de regresie liniară \(\symbf Y = \symbf X\symbf \beta + \symbf \varepsilon\), sub ipotezele \(\mathcal{H}_1\) și \(\mathcal{H}_2'\) și presupunem că varianța \(\sigma^2\) nu este cunoscută. Atunci au loc proprietățile
- pentru \(j\in\{0,1,\ldots, p\}\), notând cu \(\left[(\symbf X^\intercal\symbf X)^{-1}\right]_{j+1,j+1}\) elementul \(j+1\) de pe diagonala matricei \((\symbf X^\intercal\symbf X)^{-1}\), avem
\[ \hat{\beta}_j\sim \mathcal{N}(\beta_j, \sigma^2\left[(\symbf X^\intercal\symbf X)^{-1}\right]_{j+1,j+1}), \quad T_j = \frac{\hat{\beta}_j - \beta_j}{\hat{\sigma}\sqrt{\left[(\symbf X^\intercal\symbf X)^{-1}\right]_{j+1,j+1}}} = \frac{\hat{\beta}_j - \beta_j}{\hat{\sigma}_{\hat{\beta}_j}}\sim t_{n-(p+1)} \]
- fie \(R\in\mathcal{M}_{q,p+1}(\mathbb{R})\) o matrice de rang \(q\) (\(q\leq p+1\)) atunci
\[ \frac{1}{q\hat{\sigma}^2}\left(R(\hat{\symbf\beta} - \symbf\beta)\right)^\intercal\left[R(\symbf X^\intercal\symbf X)^{-1}R^\intercal\right]^{-1}R(\hat{\symbf\beta} - \symbf\beta) \sim F_{q, n - (p+1)} \]
Demonstrație (Propoziția 3.4). Avem
- Din Propoziția 3.3 am văzut că \(\hat{\symbf \beta}\sim\mathcal{N}(\symbf \beta, \sigma^2(\symbf X^\intercal\symbf X)^{-1})\) prin urmare
\[ \hat{\beta}_j\sim \mathcal{N}(\beta_j, \sigma^2\left[(\symbf X^\intercal\symbf X)^{-1}\right]_{j+1,j+1}) \]
ceea ce implică \(\frac{\hat{\beta}_j - \beta_j}{\sigma\sqrt{\left[(\symbf X^\intercal\symbf X)^{-1}\right]_{j+1,j+1}}}\sim\mathcal{N}(0,1)\).
Scriind
\[ T_j = \frac{\frac{\hat{\beta}_j - \beta_j}{\sigma\sqrt{\left[(\symbf X^\intercal\symbf X)^{-1}\right]_{j+1,j+1}}}}{\frac{\hat{\sigma}}{\sigma}} = \frac{\frac{\hat{\beta}_j - \beta_j}{\sigma\sqrt{\left[(\symbf X^\intercal\symbf X)^{-1}\right]_{j+1,j+1}}}}{\sqrt{\frac{(n - (p+1))\frac{\hat{\sigma}^2}{\sigma^2}}{n-(p+1)}}} \]
și ținând cont de faptul că \((n-(p+1))\frac{\hat{\sigma}^2}{\sigma^2}\sim\chi^2_{n-(p+1)}\) iar \(\hat{\beta}_j\) și \(\hat{\sigma}^2\) sunt independente, deducem că \(T_j \sim t_{n-(p+1)}\).
- Să remarcăm că matricea \(R(\symbf X^\intercal\symbf X)^{-1}R^\intercal\) pătratică de ordin \(q\) este inversabilă deoarece matricea \((\symbf X^\intercal\symbf X)^{-1}\) este de rang \(p+1\), \(p+1\geq q\). Cum \(\hat{\symbf \beta}\) este un vector gaussian deducem că și \(R\hat{\symbf \beta}\) este un vector gaussian de medie și matrice de covarianță
\[ R\hat{\symbf \beta}\sim\mathcal{N}\left(R\symbf \beta, \sigma^2 R(\symbf X^\intercal\symbf X)^{-1} R^\intercal\right) \]
Astfel, conform Propoziția 3.1 privind legătura dintre repartiția normală și repartiția \(\chi^2\), rezultă că
\[ \frac{1}{\sigma^2}\left(R(\hat{\symbf\beta} - \symbf\beta)\right)^\intercal\left[R(\symbf X^\intercal\symbf X)^{-1}R^\intercal\right]^{-1}R(\hat{\symbf\beta} - \symbf\beta)\sim \chi^2_q. \]
În expresia de mai sus, înlocuim pe \(\sigma^2\) cu \(\hat{\sigma}^2\) și ținând cont că \(\hat{\symbf\beta}\) și \(\hat{\sigma}^2\) sunt independente iar \((n-(p+1))\frac{\hat{\sigma}^2}{\sigma^2}\sim\chi^2_{n-(p+1)}\) concluzionăm că
\[ \begin{aligned} \frac{1}{q\hat{\sigma}^2}&\left(R(\hat{\symbf\beta} - \symbf\beta)\right)^\intercal\left[R(\symbf X^\intercal\symbf X)^{-1}R^\intercal\right]^{-1}R(\hat{\symbf\beta} - \symbf\beta) = \frac{\frac{\frac{1}{\sigma^2}\left(R(\hat{\symbf\beta} - \symbf\beta)\right)^\intercal\left[R(\symbf X^\intercal\symbf X)^{-1}R^\intercal\right]^{-1}R(\hat{\symbf\beta} - \symbf\beta)}{q}}{\frac{(n-(p+1))\frac{\hat{\sigma}^2}{\sigma^2}}{n-(p+1)}} \\ &\sim\frac{\frac{\chi^2_q}{q}}{\frac{\chi^2_{n - (p+1)}}{n-(p+1)}} = F_{q, n - (p+1)}. \end{aligned} \]
Ca aplicație vom considera următorul exemplu:
Exemplul 3.1 (Aplicație pentru regresia liniară simplă) Vom exemplifica rezultatul celui de-al doilea subpunct al Propoziția 3.4 pentru cazul particular în care \(p+1=q=2\) iar matricea \(R=I_2\). Avem că
\[ R(\hat{\symbf\beta} - \symbf\beta) = \begin{pmatrix}\hat{\beta}_0 - \beta_0\\ \hat{\beta}_1 - \beta_1\end{pmatrix} \]
și dacă termenul liber face parte din modelul de regresie atunci matricea \(\symbf X^\intercal\symbf X\) devine (a se vedea și Exemplul 1.2)
\[ \symbf X^\intercal\symbf X = \begin{pmatrix}n & \sum x_i\\ \sum x_i & \sum x_i^2\end{pmatrix}. \]
Astfel găsim că \(\frac{1}{q\hat{\sigma}^2}\left(R(\hat{\symbf\beta} - \symbf\beta)\right)^\intercal\left[R(\symbf X^\intercal\symbf X)^{-1}R^\intercal\right]^{-1}R(\hat{\symbf\beta} - \symbf\beta)\) se rescrie ca
\[ \frac{1}{2\hat{\sigma}^2}\left[n(\hat{\beta}_0 - \beta_0)^2 + 2n\bar{x}(\hat{\beta}_0 - \beta_0)(\hat{\beta}_1 - \beta_1) + \sum_{i=1}^{n}x_i^2(\hat{\beta}_1 - \beta_1)^2\right] \sim F_{2, n - 2} \]
proprietate care coincide cu rezultatul obținut în cazul regresiei liniare simple. Mai mult, dacă \(p+1 = q\) și \(R = I_{p+1}\) atunci repartiția distanței (ponderate de inversa matricei de covarianță) dintre estimatorul obținut prin metoda celor mai mici pătrate \(\hat{\symbf\beta}\) și valoarea reală \(\symbf \beta\) este \(F_{p+1, n - (p+1)}\):
\[ \frac{1}{\hat{\sigma}^2(p+1)}(\hat{\symbf\beta} - \symbf\beta)^\intercal(\symbf X^\intercal\symbf X)^{-1}(\hat{\symbf\beta} - \symbf\beta)\sim F_{p+1, n - (p+1)}. \]
4 Intervale și regiuni de încredere
Rezultatele din propozițiile anterioare conduc la următoarele intervale (atunci când parametrii sunt considerați separat) și regiuni de încredere (atunci când luăm în calcul mai mulți parametrii simultan prin urmare ținem cont și de dependența dintre ei) pentru parametrii modelului de regresie liniară:
- Un interval de încredere bilateral de nivel de încredere \(1-\alpha\) pentru parametrul \(\beta_j\), \(j\in\{0,1,\ldots,p\}\) este dat de
\[ IC^{1-\alpha}(\beta_j) = \left[\hat{\beta}_j - t_{n-(p+1)}\left(1-\frac{\alpha}{2}\right)\hat{\sigma}\sqrt{\left[(\symbf X^\intercal\symbf X)^{-1}\right]_{j+1,j+1}}, \hat{\beta}_j + t_{n-(p+1)}\left(1-\frac{\alpha}{2}\right)\hat{\sigma}\sqrt{\left[(\symbf X^\intercal\symbf X)^{-1}\right]_{j+1,j+1}}\right] \] unde \(t_{n-(p+1)}\left(1-\frac{\alpha}{2}\right)\) este cuantila de ordin \(1-\frac{\alpha}{2}\) a repartiției Student \(t_{n-(p+1)}\).
- Un interval de încredere bilateral de nivel de încredere \(1-\alpha\) pentru \(\sigma^2\) este dat de
\[ IC^{1-\alpha}(\sigma^2) = \left[\frac{[n - (p+1)]\hat{\sigma}^2}{\chi^2_{n - (p+1)}\left(1-\frac{\alpha}{2}\right)}, \frac{[n - (p+1)]\hat{\sigma}^2}{\chi^2_{n - (p+1)}\left(\frac{\alpha}{2}\right)}\right] \]
unde \(\chi^2_{n - (p+1)}\left(1-\frac{\alpha}{2}\right)\) și \(\chi^2_{n - (p+1)}\left(\frac{\alpha}{2}\right)\) sunt cuantilele de ordin \(1-\frac{\alpha}{2}\) și respectiv \(\frac{\alpha}{2}\) a repartiției \(\chi^2_{n - (p+1)}\).
- O regiune de încredere de nivel de încredere \(1-\alpha\) pentru \(q\) (\(q\leq p+1\)) parametrii \(\beta_j\), notați \((\beta_{j_1},\ldots,\beta_{j_q})\), este dată de
- atunci când \(\sigma\) este cunoscută, de
\[ RC^{1-\alpha}(R\symbf \beta) = \left\{R\symbf \beta\in\mathbb{R}^q\,|\, \frac{1}{\sigma^2}\left(R(\hat{\symbf\beta} - \symbf\beta)\right)^\intercal\left[R(\symbf X^\intercal\symbf X)^{-1}R^\intercal\right]^{-1}R(\hat{\symbf\beta} - \symbf\beta) \leq \chi^2_q(1-\alpha)\right\} \]
- atunci când \(\sigma\) este necunoscută, de
\[ RC^{1-\alpha}(R\symbf \beta) = \left\{R\symbf \beta\in\mathbb{R}^q\,|\, \frac{1}{q\hat{\sigma}^2}\left(R(\hat{\symbf\beta} - \symbf\beta)\right)^\intercal\left[R(\symbf X^\intercal\symbf X)^{-1}R^\intercal\right]^{-1}R(\hat{\symbf\beta} - \symbf\beta) \leq f_{q, n - (p+1)}(1-\alpha)\right\} \]
unde \(R\) este o matrice de dimensiune \(q\times(p+1)\) cu toate elementele nule exceptând elementele \(R_{i,j_i}\) care sunt egale cu \(1\) iar \(f_{q, n - (p+1)}(1-\alpha)\) este cuantila de ordin \(1-\alpha\) a repartiției Fisher-Snedecor \(F_{q, n - (p+1)}\) cu \(q\) grade de libertate la numărător și \(n-(p+1)\) grade de libertate la numitor.
Exemplul 4.1 (Regiune de încredere caz particular) Ca ilustrare a regiunii de încredere de mai sus, să presupunem că \(p\geq 2\) și \(q = 2\) iar matricea \(R\) este
\[ R = \begin{pmatrix}1 & 0 & 0 & \cdots & 0\\ 0 & 1 & 0 & \cdots & 0\end{pmatrix} \]
ceea ce conduce la \(R(\hat{\symbf\beta} - \symbf\beta) = \begin{pmatrix}\hat{\beta}_0 - \beta_0\\ \hat{\beta}_1 - \beta_1\end{pmatrix}\). Dacă presupunem că \(\sigma^2\) este necunoscut atunci regiunea de încredere pentru \((\beta_0,\beta_1)\), \(RC^{1-\alpha}(\beta_0,\beta_1)\) este dată de
\[ \small \left\{(\beta_0,\beta_1)\in\mathbb{R}^2\,|\, \frac{1}{2\hat{\sigma}^2}\begin{pmatrix}\hat{\beta}_0 - \beta_0 & \hat{\beta}_1 - \beta_1\end{pmatrix}\left[R(\symbf X^\intercal\symbf X)^{-1}R^\intercal\right]^{-1}\begin{pmatrix}\hat{\beta}_0 - \beta_0\\ \hat{\beta}_1 - \beta_1\end{pmatrix} \leq f_{2, n - (p+1)}(1-\alpha)\right\} \normalsize \]
și notând cu \(c_{ij}\) elementul de pe linia \(i\) coloana \(j\) a matricei \((\symbf X^\intercal\symbf X)^{-1}\), găsim că
\[ RC^{1-\alpha}(\beta_0,\beta_1) = \left\{(\beta_0,\beta_1)\in\mathbb{R}^2\,|\,\frac{c_{22}(\hat{\beta}_0 - \beta_0)^2 - 2c_{12}(\hat{\beta}_0 - \beta_0)(\hat{\beta}_1 - \beta_1) + c_{11}(\hat{\beta}_1 - \beta_1)^2}{2\hat{\sigma}^2(c_{11}c_{22} - c_{12}^2)}\leq f_{2, n - (p+1)}(1-\alpha)\right\} \]
ceea ce arată că regiunea are formă de elipsă (vezi (Ornea and Turtoi 2000, Capitolul 2, Secțiunea 16)). Figura următoare ilustrează această regiune pentru date simulate conform modelului de regresie liniară simplă \(y_i = 3 + 7x_i - \varepsilon_i\), cu \(x_i\sim\mathcal{U}[-5, 5]\) iar \(\varepsilon_i\sim\mathcal{N}(0, 4)\):
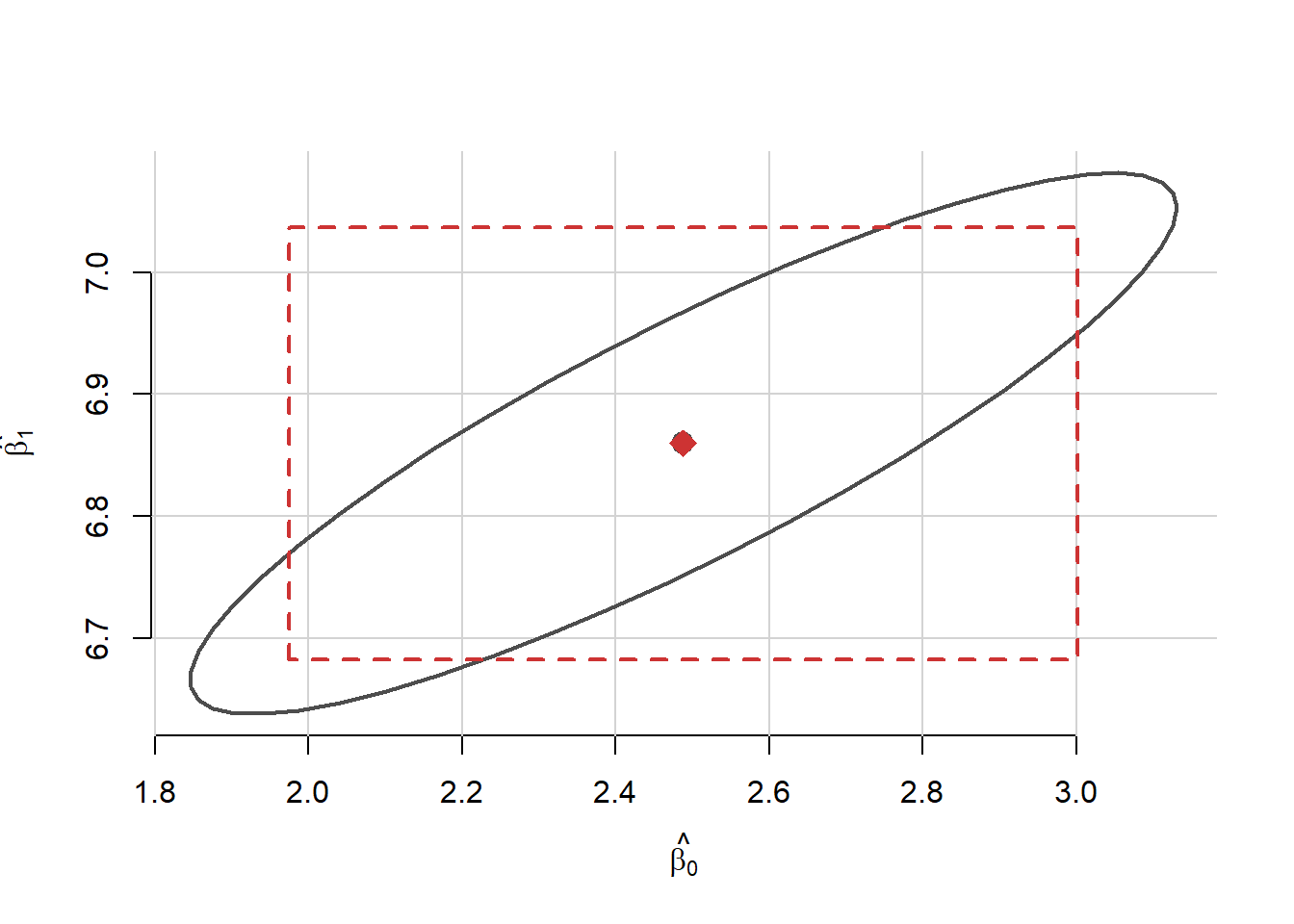
Arată codul R din exemplul de mai sus
set.seed(1234)
n <- 250
x <- -5 + 5*runif(n)
y <- 3 + 7*x - 2*rnorm(n)
dat_rc <- data.frame(x = x, y = y)
mod_sim_rc <- lm(y ~ x, data = dat_rc)
par(bty = "n")
# trasam regiunea de incredere
confidenceEllipse(mod_sim_rc,
xlab = expression(hat(beta[0])),
ylab = expression(hat(beta[1])),
col = "grey30")
points(coef(mod_sim_rc)[1], coef(mod_sim_rc)[2],
pch = 18, col = "brown3",
cex = 2)
# trasam intervalele de incredere
IC_sim_rc <- confint(mod_sim_rc)
lines(c(IC_sim_rc[1,1],
IC_sim_rc[1,1],
IC_sim_rc[1,2],
IC_sim_rc[1,2],
IC_sim_rc[1,1]),
c(IC_sim_rc[2,1],
IC_sim_rc[2,2],
IC_sim_rc[2,2],
IC_sim_rc[2,1],
IC_sim_rc[2,1]),lty=2, lwd = 2,
col = "brown3")Următorul exemplu face referire la prețul chiriilor din orașul Munchen:
Exemplul 4.2 (Prețul chiriilor în Munchen) În acest exemplu vom explicita relația dintre prețul chiriei pe metrul pătrat în raport cu inversul suprafeței de locuit și anul de construcție a imobilului folosind modelul de regresie prezentat în Exemplul 1.3 din Cursul 5 în care am considerat variabila centrată \(suprafata{\_}inv{\_}cen\) și variabilele ortogonale \(an{\_}co{\_}j\)
\[ \begin{aligned} \widehat{pret{\_m^2}_i} &= \beta_0 + \beta_1 \times suprafata{\_inv\_cen} + \beta_2\times an{\_co\_1} + \beta_3\times an{\_co\_2} \\ &+\beta_4\times an{\_co\_3} \end{aligned} \]
Modelul estimat este
\[ \begin{aligned} \widehat{pret{\_m^2}_i} &= 7.111 + 129.572 \times suprafata{\_inv\_cen} + 43.938\times an{\_co\_1} \\ &\quad + 27.539\times an{\_co\_2} -1.756\times an{\_co\_3} \end{aligned} \]
Intervalele de încredere pentru coeficienții modelului de regresie la un nivel de încredere de \(1-\alpha = 95\%\) sunt
\[ \begin{aligned} IC(\hat{\beta}_0)^{1-\alpha} &= \left[7.039, 7.183\right],\\ IC(\hat{\beta}_1)^{1-\alpha} &= \left[118.717, 140.426\right],\\ IC(\hat{\beta}_2)^{1-\alpha} &= \left[39.875, 48.002\right],\\ IC(\hat{\beta}_3)^{1-\alpha} &= \left[23.501, 31.577\right],\\ IC(\hat{\beta}_4)^{1-\alpha} &= \left[-5.756, 2.244\right], \end{aligned} \]
iar intervalul de încredere pentru \(\sigma^2\) la același nivel de încredere este
\[ IC(\hat{\sigma}^2)^{1-\alpha} = \left[3.9591228, 4.3753046\right]. \]
În figura de mai jos sunt prezentate regiunile de încredere pentru toate perechile de parametrii ai modelului împreună cu intervalele de încredere corespunzătoare (elipse versus dreptunghiuri):
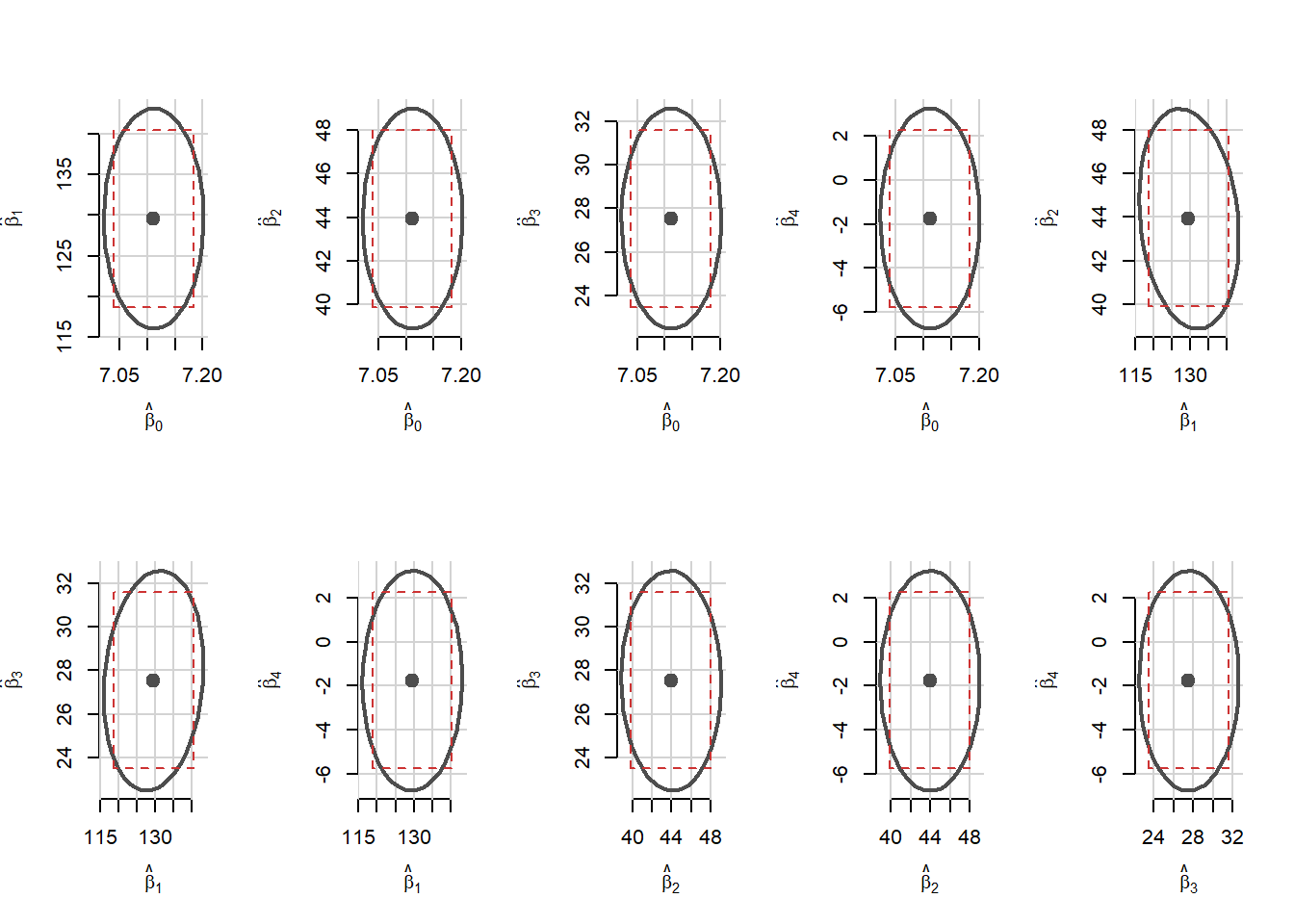
Arată codul R din exemplul de mai sus
# Model ortogonal
# estimate the model rentsqm = beta_0 + beta_1*(1/area) + beta_2*yearc + beta_3*yearc^2 + beta_4*yearc^3 + epsilon
# using 1/area centered and orthogonal polynomials for yearc
munich <- read.table("dataIn/Munchen.raw", header = TRUE)
munich_ma_mod4 <- lm(rentsqm ~ I(1/area - mean(1/area)) + poly(yearc,3),
data = munich)
s_munich_ma_mod4 <- summary(munich_ma_mod4)
coef_munich_ma_mod4 <- round(coef(munich_ma_mod4), 3)
IC_munich_ma_mod4 <- confint(munich_ma_mod4, level = 0.95)
IC4 <- round(IC_munich_ma_mod4, 3)
alpha <- 0.05
IC4_sigma <- c(s_munich_ma_mod4$sigma^2*munich_ma_mod4$df.residual/qchisq(1-alpha/2, df = munich_ma_mod4$df.residual),
s_munich_ma_mod4$sigma^2*munich_ma_mod4$df.residual/qchisq(alpha/2, df = munich_ma_mod4$df.residual))
par(mfrow = c(2, 5),
bty = "n")
for (i in 1:4){
for(j in (i+1):5){
confidenceEllipse(munich_ma_mod4,
which.coef = c(i, j),
xlab = latex2exp::TeX(paste0("$\\hat{\\beta}_{", i-1, "}$")),
ylab = latex2exp::TeX(paste0("$\\hat{\\beta}_{", j-1, "}$")),
col = "grey30")
lines(c(IC_munich_ma_mod4[i,1],
IC_munich_ma_mod4[i,1],
IC_munich_ma_mod4[i,2],
IC_munich_ma_mod4[i,2],
IC_munich_ma_mod4[i,1]),
c(IC_munich_ma_mod4[j,1],
IC_munich_ma_mod4[j,2],
IC_munich_ma_mod4[j,2],
IC_munich_ma_mod4[j,1],
IC_munich_ma_mod4[j,1]),lty=2,
col = "brown3")
}
}Atunci când vrem să facem o predicție dorim să evaluăm certitudinea cu care această predicție este efectuată. Având în vedere variabilitate noi valori pe care vrem să o prezicem este de așteptat ca intervalul de predicție să fie mai mare decât cel de încredere la același nivel de încredere.
Propoziția 4.1 Fie \((x_{n+1,1}, \ldots, x_{n+1,p})\) o nouă observație și considerăm \(\symbf x_{n+1}^\intercal = (1, x_{n+1,1}, \ldots, x_{n+1,p})\). Ne propunem să prezicem valoarea \(y_{n+1}\) conform modelului
\[ y_{n+1} = \symbf x_{n+1}^\intercal\symbf \beta + \varepsilon_{n+1} \]
cu \(\varepsilon_{n+1}\sim\mathcal{N}(0,\sigma^2)\) independentă de \(\varepsilon_i\), \(1\leq i\leq n\).
Un interval de predicție de nivel de încredere \(1-\alpha\) pentru \(y_{n+1}\) este dat de
\[ \scriptsize \left[\symbf x_{n+1}^\intercal \hat{\symbf \beta} \pm t_{n-(p+1)}\left(1-\frac{\alpha}{2}\right)\hat{\sigma}\sqrt{1 + \symbf x_{n+1}^\intercal(\symbf X^\intercal\symbf X)^{-1}\symbf x_{n+1}}\right] \normalsize \]
Demonstrație (Propoziția 4.1). Plecând de la un eșantion de talie \(n\), \((\symbf x_1, y_1), \ldots, (\symbf x_n, y_n)\), găsim estimatorul de verosimilitate maximă (același cu cel obținut prin metoda celor mai mici pătrate) \(\hat{\symbf\beta}\) a lui \(\symbf\beta\) cu ajutorul căruia putem prezice valoarea \(\hat{y}_{n+1}\) după relația
\[ \hat{y}_{n+1} = \symbf x_{n+1}^\intercal\hat{\symbf \beta}. \]
Pentru a cuantifica eroarea de predicție \(y_{n+1} - \hat{y}_{n+1}\) folosim următoarea descompunere
\[ y_{n+1} - \hat{y}_{n+1} = \symbf x_{n+1}^\intercal\left(\symbf \beta - \hat{\symbf \beta}\right) + \varepsilon_{n+1}, \]
care este o sumă de două variabile gaussiene independente, \(\varepsilon_{n+1}\) și \(\hat{\symbf \beta}\) care este un vector gaussian care depinde de \(\varepsilon_i\), \(1\leq i\leq n\). Prin urmare \(y_{n+1} - \hat{y}_{n+1}\) este un vector gaussian și ținând cont că matricea de varianță-covarianță \(Var(\hat{\varepsilon}_{n+1}) = \sigma^2\left(1 + \symbf x_{n+1}^\intercal(\symbf X^\intercal \symbf X)^{-1}\symbf x_{n+1}\right)\) avem
\[ y_{n+1} - \hat{y}_{n+1} \sim \mathcal{N}\left(0, \sigma^2\left(1 + \symbf x_{n+1}^\intercal(\symbf X^\intercal \symbf X)^{-1}\symbf x_{n+1}\right)\right). \]
Această relație se rescrie sub forma
\[ \frac{y_{n+1} - \hat{y}_{n+1}}{\sigma\sqrt{(1 + \symbf x_{n+1}^\intercal(\symbf X^\intercal \symbf X)^{-1}\symbf x_{n+1}}} \sim \mathcal{N}(0, 1) \]
și înlocuind \(\sigma\) cu estimatorul său \(\hat{\sigma}\) obținem
\[ \begin{aligned} \frac{y_{n+1} - \hat{y}_{n+1}}{\hat{\sigma}\sqrt{(1 + \symbf x_{n+1}^\intercal(\symbf X^\intercal \symbf X)^{-1}\symbf x_{n+1}}} &= \frac{\frac{y_{n+1} - \hat{y}_{n+1}}{\sigma\sqrt{(1 + \symbf x_{n+1}^\intercal(\symbf X^\intercal \symbf X)^{-1}\symbf x_{n+1}}}}{\frac{\sigma}{\hat{\sigma}}} \\ &= \frac{\frac{y_{n+1} - \hat{y}_{n+1}}{\sigma\sqrt{(1 + \symbf x_{n+1}^\intercal(\symbf X^\intercal \symbf X)^{-1}\symbf x_{n+1}}}}{\sqrt{\frac{\frac{[n - (p+1)]\sigma}{\hat{\sigma}}}{n - (p+1)}}} \sim \frac{\mathcal{N}(0,1)}{\sqrt{\frac{\chi^2_{n-(p+1)}}{n - (p+1)}}}. \end{aligned} \]
Remarcăm că numărătorul și numitorul sunt variabile aleatoare independente deoarece \(y_{n+1} - \hat{y}_{n+1} = \symbf x_{n+1}^\intercal\left(\symbf \beta - \hat{\symbf \beta}\right) + \varepsilon_{n+1}\) este independentă de \(\hat{\sigma}\) pentru că \(\hat{\sigma}\) este independentă de \(\hat{\symbf \beta}\) și de \(\varepsilon_{n+1}\) (estimatorul \(\hat{\sigma}\) nu depinde decât de \(\varepsilon_i\), \(1\leq i\leq n\)). Prin urmare găsim că
\[ \frac{y_{n+1} - \hat{y}_{n+1}}{\hat{\sigma}\sqrt{(1 + \symbf x_{n+1}^\intercal(\symbf X^\intercal \symbf X)^{-1}\symbf x_{n+1}}} \sim t_{n-(p+1)} \]
de unde rezultă intervalul de încredere dorit.
5 Testarea ipotezelor statistice
În această secțiune vom prezenta o serie de teste statistice de semnificație pentru coeficienții necunoscuți \(\symbf\beta\) ai modelului de regresie liniară. Pentru aceasta ne vom plasa în contextul modelului de regresie liniară multiplă sub ipoteza de normalitate a termenilor eroare \(\mathcal{H}_2'\), chiar dacă mare parte din rezultatele ce vor fi prezentate sunt robuste la deviații mici de la această ipoteză în special atunci când talia eșantionului \(n\) este mare (Sen and Srivastava 2012) sau (Rencher and Schaalje 2008).
Vom începe prin a da un exemplu în care se justifică necesitatea testării de ipoteze statistice în contextul modelului de regresie.
Exemplul 5.1 (Prețul chiriilor în Munchen - testare de ipoteze statistice) Ne plasăm în contextul setului de date referitor la prețul chiriilor apartamentelor din orașul Munchen. În acest exemplu vom folosi atât datele din anul 1999 cât și pe cele din anul 2001 pentru a face o comparație între prețuri. Setul de date Munchen2 conține \(n = 4571\) observații referitoare la prețul chiriei apartamentelor pentru anii 1999 (3082observații) și 2001 (1489 observații). Considerăm modelul de regresie
\[ \small \begin{aligned} pret{\_m^2}_i &= \beta_0 + \beta_1\times suprafata{\_inv}{\_cen}_i + \beta_2\times an{\_co\_1} + \beta_3\times an{\_co\_2} +\beta_4\times an{\_co\_3} \\ &\quad + \beta_5\times nbucatarie + \beta_6\times pbucatarie + \beta_7\times an01 + \varepsilon_i \end{aligned} \normalsize \]
unde \(suprafata{\_inv}{\_cen}\) este covariabila dată de inversa suprafeței de locuit centrată în zero, \(an{\_co\_j}\) sunt variabilele rezultate prin aplicarea polinoamelor ortogonale de grad 3 (a se vedea Exemplul 1.4 din Cursul 5) anului de construcție, \(nbucatarie\) și \(pbucatarie\) sunt variabile indicator ajutătoare care specifică tipul de bucătărie al locuinței și sunt rezultate din variabila categorială bucătărie care avea nivelele substandard (categorie de referință), standard/normală și respectiv premium. Covariabila \(an01\) este o variabilă indicator care precizează dacă observația este din anul 1999 (\(an01 = 0\)) sau 2001 (\(an01 = 1\)).
Modelul estimat rezultat este
\[ \begin{aligned} \widehat{pret{\_m^2}_i} &= 6.932 + 123.77\times suprafata{\_inv}{\_cen}_i + 49.373\times an{\_co\_1} + 29.5\times an{\_co\_2} \\ &\quad -0.884\times an{\_co\_3} + 1.043\times nbucatarie + 1.302\times pbucatarie -0.185\times an01 \end{aligned} \]
ceea ce arată că prețul mediu net pe metrul pătrat al chiriei pentru apartamentele din anul 2001 scade cu aproape \(0.185\) euro față de cele din anul 1999. Se poate pune întrebarea dacă această descreștere este semnificativă (poate fi extrapolată la întreaga populație) sau este datorată variabilității eșantionării aleatoare, prin urmare vrem să verificăm dacă parametrul \(\beta_7\) este diferit în mod semnificativ față de \(0\) ceea ce în termeni de teste statistice se scrie sub forma:
\[ H_0: \beta_7 = 0 \quad \text{versus}\quad H_1: \beta_7\neq 0. \]
Alte întrebări asupra acestui model pot să apară, de exemplu putem să verificăm dacă tipul de bucătărie este semnificativ în explicarea prețului chiriei pe metrul pătrat, adică dacă coeficienții \(\beta_5\) și \(\beta_6\) sunt simultan \(0\):
\[ H_0: \begin{pmatrix}\beta_5\\ \beta_6\end{pmatrix} = \begin{pmatrix}0\\0\end{pmatrix} \quad \text{versus}\quad H_1: \begin{pmatrix}\beta_5\\ \beta_6\end{pmatrix} \neq \begin{pmatrix}0\\0\end{pmatrix}. \]
O altă întrebare, ținând seama că estimatorii coeficienților \(\hat{\beta}_5 = 1.043\) și \(\hat{\beta}_6 = 1.302\) nu sunt foarte diferiți, ar fi dacă este necesar să diferențiem între apartamentele cu bucătărie standard și cele cu bucătărie premium:
\[ H_0: \beta_5 = \beta_6 \quad \text{versus}\quad H_1: \beta_5\neq \beta_6. \]
Arată codul R din exemplul de mai sus
# noile date pentru anul 2001
munich2 <- read.table("dataIn/Munchen2.raw", header = TRUE)
n1999 <- munich2 %>% filter(year01 == 0) %>% count()
n2001 <- munich2 %>% filter(year01 == 1) %>% count()
# estimam modelul
munich2_mod1 <- lm(rentsqm_euro ~ I(1/area - mean(1/area)) + poly(yearc,3) + nkitchen + pkitchen + year01 ,
data = munich2)
munich2_mod1_coef <- round(coef(munich2_mod1),3)Toate întrebările puse în Exemplul 5.1 sunt ilustrative pentru modelul de regresie în general și testele statistice de semnificație corespunzătoare pot fi scrise sub forma:
- Teste asupra modelelor imbricate - în acest caz avem un test compus asupra subvectorului \(\symbf\beta_0 = (\beta_0,\ldots,\beta_{p_0})^\intercal\)
\[ H_0: \symbf\beta_0 = \symbf 0 \quad \text{versus}\quad H_1: \symbf\beta_0 \neq \symbf 0. \]
- Test de semnificație asupra unui coeficient
\[ H_0: \beta_j = 0 \quad \text{versus}\quad H_1: \beta_j\neq 0. \]
- Testul global asupra tutoror covariabielor din model
\[ H_0: \beta_1 = \cdots = \beta_p = 0 \quad \text{versus}\quad H_1: \exists j\in\{1, 2,\ldots, p\} \text{ cu } \beta_j\neq 0. \]
- Testul asupra unei ipoteze liniare generalizate
\[ H_0: R\symbf \beta = r \quad \text{versus}\quad H_1: R\symbf \beta \neq r \]
unde \(R\) este o matrice dimensiune \(q\times(p+1)\) cu \(rang(R) = q\leq p+1\) iar \(r\) este un vector de dimensiune \(q\).
În secțiunile următoare vom încerca să construim pentru fiecare astfel de test statistica de test precum și regiunea critică corespunzătoare.
5.1 Teste asupra modelelor imbricate
Considerăm modelul de regresie liniară
\[ \symbf Y = \symbf X\symbf \beta + \symbf \varepsilon \]
sub ipotezele \(\mathcal{H}_1: \, rang(\symbf X) = p+1\) și \(\mathcal{H}_2': \, \symbf \varepsilon \sim\mathcal{N}(0, \sigma^2 I_n)\). În particular, acest model ne spune că \(\mathbb{E}[\symbf Y] = \symbf X\symbf \beta\in\mathcal{M}(X)\) unde \(\mathcal{M}(X)\) este subspațiul de dimensiune \(p+1\) a lui \(\mathbb{R}^n\) generat de coloanele matricii de design \(\symbf X\).
Pentru început, în această secțiune ne propunem să testăm dacă ultimii \(q\) coeficienți, \(q = p - p_0\leq p+1\), sunt nuli, altfel spus vrem să testăm ipotezele
\[ H_0:\, \beta_{p_0+1} = \cdots = \beta_p = 0 \quad \text{versus}\quad H_1:\,\exists j\in\{p_0+1,\ldots,p\}\, \beta_j\neq 0 \]
În termeni de model, ipoteza \(H_0\) ne spune că modelul revine la
\[ \symbf Y = \symbf X_0\symbf \beta_0 + \symbf \varepsilon_0 \]
sub ipotezele \(\mathcal{H}_1: \, rang(\symbf X_0) = p_0+1\) și \(\mathcal{H}_2': \, \symbf \varepsilon_0 \sim\mathcal{N}(0, \sigma^2 I_n)\), unde matricea \(\symbf X_0\in\mathcal{M}_{n,p_0+1}(\mathbb{R})\) este compusă din primele \(p_0+1\) coloane ale lui \(\symbf X\) iar \(\symbf \beta_0\in\mathcal{M}_{p_0+1,1}(\mathbb{R})\) (în acest model am inclus și termenul liber și acesta este motivul pentru care avem \(p_0 + 1\) și nu \(p_0\)).
Fie \(\mathcal{M}(X_0)\) subspațiul lui \(\mathcal{M}(X)\) de dimensiune \(p_0\) generat de coloanele lui \(\symbf X_0\) (deoarece \(\mathrm{rang}(\symbf X) = p+1\) deducem că \(\mathrm{rang}(\symbf X_0) = p_0+1\)). Sub ipoteza \(H_0\) avem că \(\mathbb{E}[\symbf Y] = \symbf X_0\symbf \beta_0\in\mathcal{M}(X_0)\).
Odată ce avem fixate ipotezele procedurii de testare, mai rămâne de a determina statistica de test corespunzătoare și regiunea critică a testului. Următoarea propoziție face lumină în acest sens folosind o abordare geometrică (pentru o versiune analitică se poate consulta Propoziția 5.4).
Propoziția 5.1 (Testul lui Fisher asupra modelelor imbricate) Sub ipoteza nulă \(H_0\) statistica de test
\[ F = \frac{n - (p+1)}{q}\frac{\lVert\hat{\symbf Y} - \hat{\symbf Y}_0\rVert^2}{\lVert\symbf Y - \hat{\symbf Y}\rVert^2} = \frac{n - (p+1)}{q}\frac{RSS_0 - RSS}{RSS} \sim F_{q, n - (p+1)} \]
unde \(q = p - p_0\) iar \(F_{q, n - (p+1)}\) este repartiția lui Fisher cu \((q, n - (p+1))\) grade de libertate.
Demonstrație (Propoziția 5.1). Vom prezenta mai jos o abordare din punct de vedere geometric a problemei de testare. Considerăm spațiul \(\mathcal{M}(X_0)\subset\mathcal{M}(X)\) și am văzut că sub ipoteza nulă avem \(\mathbb{E}[\symbf Y] = \symbf X_0\symbf \beta_0\in\mathcal{M}(X_0)\). În această situație, metoda celor mai mici pătrate consistă în proiectarea lui \(\symbf Y\) pe spațiul \(\mathcal{M}(X_0)\) pentru a obține vectorul valorilor ajustate \(\hat{\symbf Y}_0\) (a se vedea Figura 5.1 de mai jos).
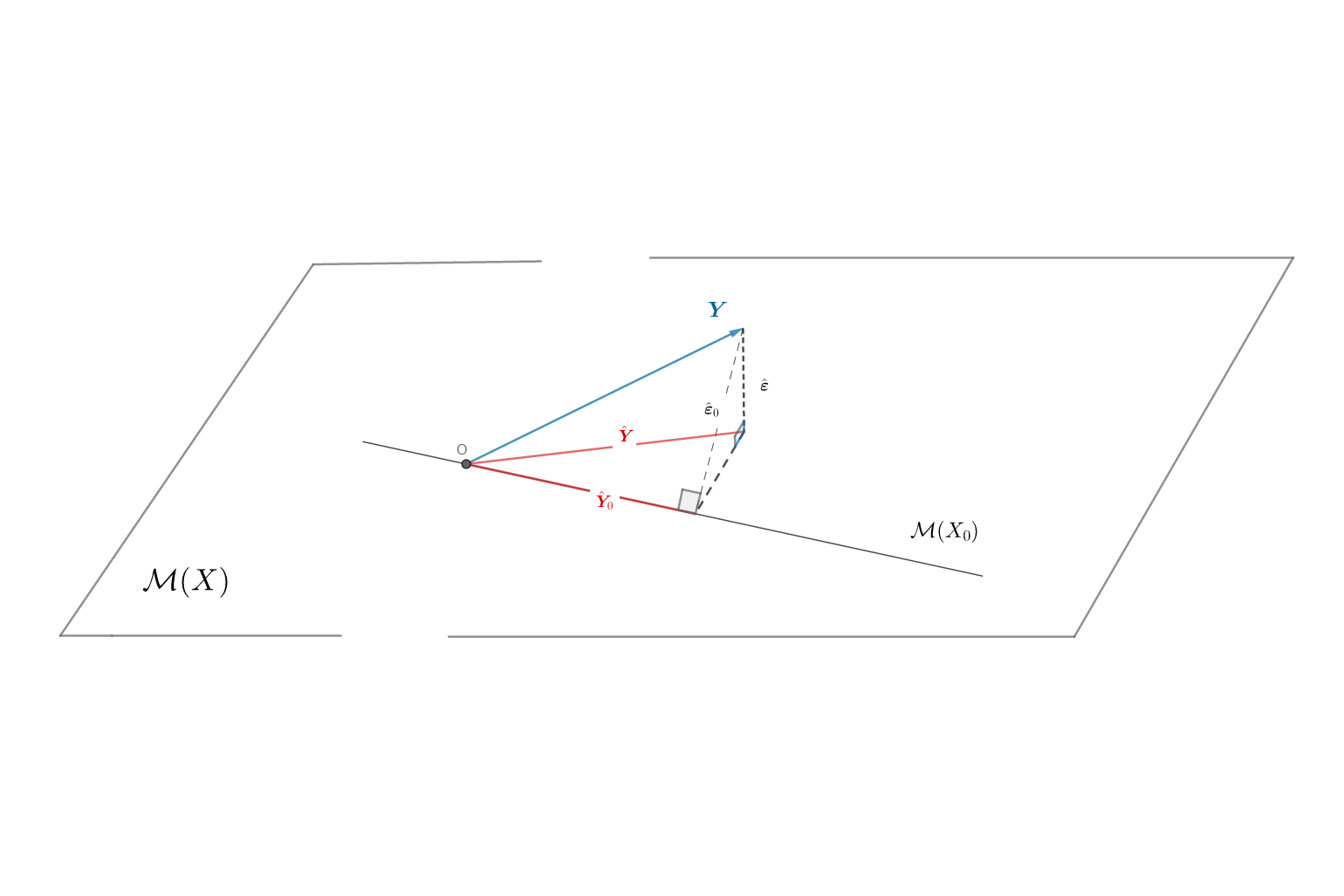
Ideea procedurii de testare, și prin urmare a deciziei de a respinge sau nu ipoteza nulă, este următoarea: dacă proiecția \(\hat{\symbf Y}_0\) a lui \(\symbf Y\) pe \(\mathcal{M}(X_0)\) este aproape de proiecția \(\hat{\symbf Y}\) a lui \(\symbf Y\) pe \(\mathcal{M}(X)\) atunci nu respingem ipoteza nulă, în caz contrar o respingem în favoarea alternativei \(H_1\). De fapt, dacă informația adusă de cele două modele nu diferă foarte mult atunci este recomandat să păstrăm modelul mai simplu (principiul parcimoniei).
Pentru a cuantifica apropierea dintre cele două proiecții putem considera distanța euclidiană \(\lVert\hat{\symbf Y} - \hat{\symbf Y}_0\rVert^2\) dintre acestea. Această distanță variază în funcție de datele și de unitățile de măsură a acestora și pentru a evita această problemă de scară se recomandă standardizarea acestei distanțe prin împărțirea ei la pătratul normei erorii reziduale \(\lVert\hat{\symbf \varepsilon}\rVert^2 = \lVert\symbf Y - \hat{\symbf Y}\rVert^2 = [n - (p+1)]\hat{\sigma}^2\). Cum vectorii aleatori \(\hat{\symbf Y} - \hat{\symbf Y}_0\) și \(\hat{\symbf \varepsilon}\) nu aparțin în subspații de aceeași dimensiune trebuie să îi împărțim și prin gradele de libertate corespunzătoare, respectiv \(q = p - p_0\) și \(n - (p+1)\). Obținem astfel statistica de test
\[ F = \frac{\frac{\lVert\hat{\symbf Y} - \hat{\symbf Y}_0\rVert^2}{p-p_0}}{\frac{\lVert\symbf Y - \hat{\symbf Y}\rVert^2}{n - (p+1)}} = \frac{n - (p+1)}{p - p_0}\frac{\lVert\hat{\symbf Y} - \hat{\symbf Y}_0\rVert^2}{\lVert\symbf Y - \hat{\symbf Y}\rVert^2}. \]
Pentru a putea utiliza această statistică de test este necesar să determinăm repartiția sa sub ipoteza nulă. Notând cu \(P_X\) și respectiv \(P_{X_0}\) matricele de proiecție ortogonală pe \(\mathcal{M}(X)\) și \(\mathcal{M}(X_0)\), știm că
\[ \hat{\symbf Y} - \hat{\symbf Y}_0 = P_X\symbf Y - P_{X_0}\symbf Y \]
și cum \(\mathcal{M}(X_0)\subset \mathcal{M}(X)\), deci \(P_{X_0}\symbf Y = P_{X_0}P_{X}\symbf Y\) și
\[ \hat{\symbf Y} - \hat{\symbf Y}_0 = P_{X}\symbf Y - P_{X_0}\symbf Y = (I_n - P_{X_0})P_X\symbf Y = P_{X_0}^\perp P_{X}\symbf Y. \]
Astfel am găsit că \(\hat{\symbf Y} - \hat{\symbf Y}_0\in\mathcal{M}(X_0)^\perp\cap \mathcal{M}(X)\) și cum \(\symbf Y - \hat{\symbf Y}\in\mathcal{M}(X)^\perp\) găsim că \(\hat{\symbf Y} - \hat{\symbf Y}_0 \perp \symbf Y - \hat{\symbf Y}\). Vectorii \(\hat{\symbf Y} - \hat{\symbf Y}_0\) și \(\symbf Y - \hat{\symbf Y}\) sunt elemente din spații ortogonale ceea ce implică \(Cov(\hat{\symbf Y} - \hat{\symbf Y}_0, \symbf Y - \hat{\symbf Y}) = 0\) și cum sunt și vectori gaussieni (conform ipotezei \(\mathcal{H}_2'\)) deducem că sunt și independenți ceea ce arată că numărătorul și numitorul lui \(F\) sunt independente.
Conform Teoremei lui Cochran (a se vedea Propoziția 3.2) avem pentru numitor
\[ \frac{1}{\sigma^2}\lVert\symbf Y - \hat{\symbf Y}\rVert^2 = \frac{1}{\sigma^2}\lVert P_{X^\perp}\symbf Y\rVert^2 = \frac{1}{\sigma^2}\lVert P_{X^\perp}(\symbf X\symbf\beta + \symbf\varepsilon)\rVert^2 = \frac{1}{\sigma^2}\lVert P_{X^\perp}\symbf\varepsilon\rVert^2\sim\chi^2_{n - (p+1)} \]
iar pentru numărător
\[ \frac{1}{\sigma^2}\lVert P_{X_0}^\perp P_{X}(\symbf Y - \symbf X\symbf\beta)\rVert^2 \sim \chi^2_{q} \]
Sub \(H_0\), parametrul \(\lVert P_{X_0}^\perp P_{X}\symbf X\symbf\beta\rVert^2\) este nul deoarece \(\symbf X\symbf\beta\in\mathcal{M}(X_0)\) ceea ce conduce la
\[ \frac{1}{\sigma^2}\lVert\hat{\symbf Y} - \hat{\symbf Y}_0\rVert^2 = \frac{1}{\sigma^2}\lVert P_{X_0}^\perp P_{X}\symbf Y\rVert^2 \overset{H_0}{=} \frac{1}{\sigma^2}\lVert P_{X_0}^\perp P_{X}(\symbf Y - \symbf X\symbf\beta)\rVert^2 \sim \chi^2_{q} \]
prin urmare
\[ F\overset{H_0}{\sim} F_{q, n - (p+1)}. \]
Putem observa de asemenea că aplicând Teorema lui Pitagora (în triunghiul punctat cu negru)
\[ \begin{aligned} \lVert\symbf Y - \hat{\symbf Y}_0\rVert^2 &= \lVert\symbf Y - P_X\symbf Y + P_X\symbf Y - P_{X_0}\symbf Y\rVert^2 = \lVert (I_n - P_X)\symbf Y + P_{X_0}P_X\symbf Y - P_{X_0}\symbf Y\rVert^2 \\ &= \lVert P_{X^\perp}\symbf Y + (I_n - P_{X_0})P_X\symbf Y \rVert^2 = \lVert P_{X^\perp}\symbf Y + P_{{X_0}^\perp}P_X\symbf Y \rVert^2\\ &= \lVert P_{X^\perp}\symbf Y\rVert^2 + \lVert P_{{X_0}^\perp}P_X\symbf Y\rVert^2 = \lVert\symbf Y - \hat{\symbf Y}\rVert^2 + \lVert\hat{\symbf Y} - \hat{\symbf Y}_0\rVert^2 \end{aligned} \]
altfel spus
\[ \lVert\hat{\symbf Y} - \hat{\symbf Y}_0\rVert^2 = \lVert\symbf Y - \hat{\symbf Y}_0\rVert^2 - \lVert\symbf Y - \hat{\symbf Y}\rVert^2 = RSS_0 - RSS \]
ceea ce justifică a doua scriere a statisticii de test.
Se poate arăta (Rencher and Schaalje 2008, Teorema 8.3) că dacă termenul liber face parte din ambele modele (sau nu face parte din niciunul) atunci statistica de test precedentă se poate exprima în funcție de coeficienții de determinare \(R^2\) și respectiv \(R^2_0\) corespunzători modelelor considerate:
\[ F = \frac{n - (p+1)}{q}\frac{R^2 - R^2_0}{1 - R^2} \]
prin urmare dacă avem la dispoziție coeficienții de determinare ai celor două modele putem efectua testul de semnificație a lui Fisher pentru modele imbricate.
Exemplul 5.2 (Prețul chiriilor în Munchen - test asupra coeficienților) În contextul modelului de regresie din Exemplul 5.1 ne propunem să testăm semnificația efectului bucătăriei asupra prețului pe metrul pătrat. Astfel considerăm ipotezele
\[ H_0: \begin{pmatrix}\beta_5\\ \beta_6\end{pmatrix} = \begin{pmatrix}0\\0\end{pmatrix} \quad \text{versus}\quad H_1: \begin{pmatrix}\beta_5\\ \beta_6\end{pmatrix} \neq \begin{pmatrix}0\\0\end{pmatrix}. \]
Pentru a calcula statistica de test (în R folosim comanda linearHypothesis din pachetul car - a se consulta de exemplu anexele) vom folosi expresia \(F = \frac{n - (p+1)}{q}\frac{RSS_0 - RSS}{RSS}\) unde în cazul nostru avem \(n - (p+1) = 4565\) (\(n =4571\) și \(p = 7\)), \(q = 2\) (\(p_0 = 5\)), \(RSS_0 = 1.8236158\times 10^{4}\) și \(RSS =1.7602848\times 10^{4}\) ceea ce rezultă într-o valoare a statisticii de \(F = 82.083\) .
La un nivel de semnificativitate de \(\alpha = 0.05\) găsim că cuantila repartiției Fisher este egală cu
\[ f_{2, 4563}(0.95) = 2.998 \]
și cum \(F = 82.083>2.998= f_{2,4563}(0.95)\) putem respinge ipoteza nulă la acest prag de semnificație. Astfel putem concluziona că efectul tipului de bucătărie prezintă o influență semnificativă asupra prețului mediu net al chiriei pe metrul pătrat. Cu toate acestea asta nu înseamnă că ambii coeficienți sunt nenuli, unul ar putea fi nul pentru a respinge \(H_0\).
Arată codul R din exemplul de mai sus
# testing linear hypothesis: beta_5 = 0, beta_6=0
library(car)
test_munich2_mod1 <- linearHypothesis(munich2_mod1, c("nkitchen = 0", "pkitchen = 0"))
n <- length(munich2$rent_euro)
p <- 7
p0 <- 5
q <- test_munich2_mod1$Res.Df[1] - test_munich2_mod1$Res.Df[2]5.2 Testul Student de semnificație a unui coeficient
În această secțiune vom considera un caz particular al testului pentru modele imbricate.
Propoziția 5.2 (Testul Student de semnificație a unui coeficient) Ne propunem să testăm ipoteza nulă \(H_0:\, \beta_j = 0\) versus ipoteza alternativă \(H_1:\, \beta_j \neq 0\). Statistica de test este
\[ F = \frac{\lVert\hat{\symbf Y} - \hat{\symbf Y}_0\rVert^2}{\hat{\sigma}^2} = \frac{\hat{\beta}_j^2}{\hat{\sigma}_{\hat{\beta}_j}^2} \sim F_{1, n - (p+1)}(1-\alpha)\} \]
care este echivalentă cu statistica \(T_j = \frac{\hat{\beta}_j}{\hat{\sigma}_{\hat{\beta}_j}}\).
Demonstrație (Propoziția 5.2). Această problemă este un caz particular al rezultatului obținut anterior pentru \(q = 1\). Avem statistica de test
\[ F = \frac{n - (p+1)}{1}\frac{\lVert\hat{\symbf Y} - \hat{\symbf Y}_0\rVert^2}{\lVert\symbf Y - \hat{\symbf Y}\rVert^2} = \frac{\lVert\hat{\symbf Y} - \hat{\symbf Y}_0\rVert^2}{\hat{\sigma}^2} \]
u ajutorul căreia putem construi regiunea critică
\[ C = \{\omega\,|\,F(\omega)>f_{1, n - (p+1)}(1-\alpha)\}. \]
În modelul redus, \(\symbf X_0\) este matricea \(\symbf X = [\symbf X_0|X_{j+1}]\) fără coloana \(j+1\) (corespunzătoare coeficientului \(\beta_j\)) cu \(j = 0,1,\ldots, p\), prin urmare
\[ \begin{aligned} F &= \frac{\lVert\hat{\symbf Y} - \hat{\symbf Y}_0\rVert^2}{\hat{\sigma}^2} = \frac{\lVert\symbf X\hat{\symbf\beta} - P_{X_0}\symbf X\hat{\symbf\beta}\rVert^2}{\hat{\sigma}^2} = \frac{\lVert X_{j+1}\hat{\beta}_j - \hat{\beta}_j P_{X_0}X_{j+1}\rVert^2}{\hat{\sigma}^2} \\ &= \frac{\hat{\beta}_j^2}{\hat{\sigma}^2}X_{j+1}^\intercal(I-P_{X_0})X_{j+1}. \end{aligned} \]
Ținând cont că \(\symbf X = [\symbf X_0|X_{j+1}]\) avem că
\[ \symbf X^\intercal\symbf X = \begin{pmatrix}\symbf X_0^\intercal\symbf X_0 & \symbf X_0^\intercal X_{j+1}\\ X_{j+1}^\intercal\symbf X_0 & X_{j+1}^\intercal X_{j+1}\end{pmatrix} \]
și folosind formula de inversare a matricilor de tip bloc (a se vedea demonstrația Propoziției 1.8 din Cursul 6) găsim că
\[ \begin{aligned} \left[(\symbf X^\intercal\symbf X)^{-1}\right]_{j+1,j+1} &= \left(X_{j+1}^\intercal X_{j+1} - X_{j+1}^\intercal\symbf X_0 (\symbf X_0^\intercal\symbf X_0)^{-1}\symbf X_0^\intercal X_{j+1}\right)^{-1} \\ &= (X_{j+1}^\intercal(I-P_{X_0})X_{j+1})^{-1}. \end{aligned} \]
Se observă astfel că acest test este echivalent cu testul bazat pe statistica de test repartizată student cu \(n - (p+1)\) grade de libertate (mai exact \(F^2 = T_j\))
\[ T_j = \frac{\hat{\beta}_j}{\hat{\sigma}_{\hat{\beta}_j}} = \frac{\hat{\beta}_j}{\hat{\sigma}\sqrt{\left[(\symbf X^\intercal\symbf X)^{-1}\right]_{j+1,j+1}}}. \]
Regiunea critică a testului este
\[ C = \left\{\omega\,|\,T_j(\omega)>t_{n - (p+1)}\left(1-\frac{\alpha}{2}\right)\right\}. \]
Aceasta este forma sub care testul de semnificativitate pentru un coeficient apare în limbajul R. Mai mult, cu o mică modificare a statisticii de test se pot testa ipotezele un pic mai generale
\[ H_0:\, \beta_j = r_j \quad\text{versus}\quad H_1:\, \beta_j \neq r_j \]
folosind \(T_j= \frac{\hat{\beta}_j-r_j}{\hat{\sigma}_{\hat{\beta}_j}}\).
Exemplul 5.3 (Prețul chiriilor în Munchen - testul Student asupra coeficienților) În contextul modelului de regresie liniară prezentat în Exemplul 5.1 putem testa semnificativitatea coeficienților modelului. Tabelul de mai jos prezintă rezultatele obținute în mod standard atunci când se folosește funcția lm() din R:
| Variabila | Coeficientul | Eroarea standard | t-statistica | p-valoarea |
|---|---|---|---|---|
| \(intercept\) | 6.932 | 0.038 | 184.539 | < 0.001 |
| \(suprafata{\_inv\_cen}\) | 123.77 | 4.429 | 27.945 | < 0.001 |
| \(an{\_co\_1}\) | 49.373 | 2.026 | 24.373 | < 0.001 |
| \(an{\_co\_2}\) | 29.5 | 2.025 | 14.567 | < 0.001 |
| \(an{\_co\_3}\) | -0.884 | 1.972 | -0.448 | 0.654 |
| \(nbucatarie\) | 1.043 | 0.102 | 10.279 | < 0.001 |
| \(pbucatarie\) | 1.302 | 0.152 | 8.552 | < 0.001 |
| \(an01\) | -0.185 | 0.062 | -2.981 | 0.003 |
În tabel se regăsesc numele variabilelor care apar în model, valorile estimate ale coeficienților \(\hat{\beta}_j\), erorile standard \(\hat{\sigma}_{\hat{\beta}_j}\), valorile statisticilor de test \(T_j\) pentru \(H_0:\, \beta_j = 0\) versus \(H_1:\, \beta_j\neq 0\) și p-valorile corespunzătoare (pragul minim de semnificație \(\alpha\) pentru care respingem ipoteza nulă).
Observăm că scăderea de preț, în medie, cu \(0.185\) euro pentru anul 2001 este semnificativă din punct de vedere statistic comparativ cu anul 1999.
5.3 Testul lui Fisher global
Testul global al lui Fisher răspunde la următoarea întrebare: este vreunul dintre predictori folositor în explicarea răspunsului?
Propoziția 5.3 (Testul lui Fisher global) O procedură de testare pentru ipotezele
\[ H_0:\, \beta_1 = \ldots = \beta_p = 0 \quad \text{versus}\quad H_1:\,\exists j\in\{1,\ldots,p\}\, \beta_j\neq 0 \]
are la bază statistica de test
\[ F = \frac{n - (p+1)}{p}\frac{\lVert\hat{\symbf Y} - \hat{\symbf Y}_0\rVert^2}{\lVert\symbf Y - \hat{\symbf Y}\rVert^2} = \frac{n - (p+1)}{p}\frac{R^2}{1 - R^2} \sim F_{p, n - (p+1)}. \]
Demonstrație (Propoziția 5.3). Vrem să testăm dacă variabilele explicative au sau nu influență asupra variabilei răspuns, cu alte cuvinte vrem să testăm dacă toți coeficienții sunt nuli exceptând constanta (\(\beta_0\)) - acesta este testul care apare ca rezultat atunci când efectuăm sumarul modelului liniar în R (comanda summary(model)). Suntem în cazul particular în care \(\hat{\symbf Y}_0 = \bar{y}\mathbf{1}\) și obținem din Propoziția ?@prp-reg-c8-prp7 statistica de test a lui Fisher (testul global al lui Fisher)
\[ F = \frac{n - (p+1)}{p}\frac{\lVert\hat{\symbf Y} - \hat{\symbf Y}_0\rVert^2}{\lVert\symbf Y - \hat{\symbf Y}\rVert^2} \sim F_{p, n - (p+1)} \] sau exprimată în termeni de coeficient de determinare
\[ F = \frac{n - (p+1)}{p}\frac{R^2}{1 - R^2} \sim F_{p, n - (p+1)}. \]
5.4 Legătura cu testul bazat pe raportul de verosimilități
În rezultatul următor facem legătura dintre testul propus în Propoziția 5.1 pentru modele imbricate și testul bazat pe raportul de verosimilități.
Propoziția 5.4 (Testul lui Fisher și cel al raportului de verosimilități) Vrem să testăm ipotezele
\[ H_0:\, \beta_{p_0+1} = \cdots = \beta_p = 0 \quad \text{versus}\quad H_1:\,\exists j\in\{p_0+1,\ldots,p\}\, \beta_j\neq 0 \]
cu ajutorul testului bazat pe raportul de verosimilități. Arătați că acest test este echivalent cu testul \(F\) al lui Fisher.
Demonstrație (Propoziția 5.4). Testul bazat pe raportul de verosimilitate este
\[ \Lambda(\mathbf{y})=\frac{\sup_{\theta\in\Theta_0}L(\theta|\mathbf{y})}{\sup_{\theta\in\Theta}L(\theta|\mathbf{y})}, \]
unde \(\Theta\) este spațiul parametrilor modelului, \(\Theta_0\) este spațiul parametrilor corespunzător ipotezei nule iar \(L(\theta|\mathbf{x})\) este funcția de verosimilitate.
Observăm că spațiul parametrilor modelului este
\[ \Theta = \left\{(\symbf \beta, \sigma^2)|\,\symbf \beta\in\mathbb{R}^{p+1}, \sigma^2\in (0,\infty)\right\}, \]
cel corespunzător ipotezei nule este
\[ \Theta_0 = \left\{(\symbf \beta_0, \sigma^2)|\,\symbf \beta_0\in\mathbb{R}^{p_0}, \sigma^2\in (0,\infty)\right\} \]
iar funcția de verosimilitate este
\[ L(\symbf\beta, \sigma^2;\symbf Y) = \prod_{i = 1}^{n}f_{Y}(y_i) = \left(\frac{1}{\sqrt{2\pi\sigma^2}}\right)^n e^{-\frac{1}{2\sigma^2}\sum_{i = 1}^{n}(y_i - \symbf x_i^\intercal\symbf\beta)^2} = \left(\frac{1}{\sqrt{2\pi\sigma^2}}\right)^n e^{-\frac{1}{2\sigma^2}\lVert\symbf Y - \symbf X\symbf\beta\rVert^2}. \]
Observăm că
\[ \sup_{\theta\in\Theta}L(\theta|\mathbf{y}) = \sup_{\symbf\beta, \sigma^2} L(\symbf\beta, \sigma^2;\symbf Y) = L(\hat{\symbf\beta}_{VM}, \hat{\sigma}^2_{VM};\symbf Y) \]
unde \(\hat{\symbf\beta}_{VM}=\hat{\symbf\beta}\) este estimatorul obținut prin metoda celor mai mici pătrate iar \(\hat{\sigma}^2_{VM} = \frac{\lVert\symbf Y - \symbf X\hat{\symbf\beta}\rVert^2}{n} = \frac{RSS}{n}\). Astfel găsim
\[ \sup_{\theta\in\Theta}L(\theta|\mathbf{y}) = \sup_{\symbf\beta, \sigma^2} L(\symbf\beta, \sigma^2;\symbf Y) = \left(\frac{n}{2\pi\lVert\symbf Y - \symbf X\hat{\symbf\beta}\rVert^2}\right)^{\frac{n}{2}}e^{-\frac{n}{2}} = \left(\frac{n}{2\pi RSS}\right)^{\frac{n}{2}}e^{-\frac{n}{2}}. \]
Sub \(H_0\) avem
\[ sup_{\theta\in\Theta_0}L(\theta|\mathbf{y}) = \sup_{\symbf\beta_0, \sigma^2\in\Theta_0} L(\symbf\beta_0, \sigma^2;\symbf Y) = L(\hat{\symbf\beta}_{0}, \hat{\sigma}^2_{0};\symbf Y) = \left(\frac{n}{2\pi RSS_{0}}\right)^{\frac{n}{2}}e^{-\frac{n}{2}} \]
unde \(RSS_0 = \lVert\symbf Y - \symbf X_0\hat{\symbf\beta}_0\rVert^2\) iar \(\hat{\sigma}^2_{0} = \frac{\lVert\symbf Y - \symbf X_0\hat{\symbf\beta}_0\rVert^2}{n} = \frac{RSS_0}{n}\).
Prin urmare raportul de verosimilitate devine
\[ \Lambda(\mathbf{y})=\frac{\sup_{\theta\in\Theta_0}L(\theta|\mathbf{y})}{\sup_{\theta\in\Theta}L(\theta|\mathbf{y})} = \frac{\left(\frac{n}{2\pi RSS_{0}}\right)^{\frac{n}{2}}e^{-\frac{n}{2}}}{\left(\frac{n}{2\pi RSS}\right)^{\frac{n}{2}}e^{-\frac{n}{2}}} = \left(\frac{RSS_0}{RSS}\right)^{-\frac{n}{2}} \]
iar regiunea critică a testului se scrie (testul respinge ipoteza nulă atunci când statistica \(\Lambda\) este suficient de mică)
\[ C = \left\{\symbf Y\in\mathbb{R}^n\,|\, \Lambda(\symbf Y)< \lambda_0 \right\}. \]
Observăm că pentru \(\lambda>0\), funcția \(h(\lambda) = \lambda^{-\frac{2}{n}}-1\) este descrescătoare, adică \(\lambda<\lambda_0\) implică \(h(\lambda)>h(\lambda_0)\). Avem
\[ h(\lambda)>h(\lambda_0) \iff \frac{RSS_0 - RSS}{RSS}>h(\lambda_0) \iff \frac{n - (p+1)}{p - p_0}\frac{RSS_0 - RSS}{RSS}>f_0 \]
unde \(f_0\) se determină din condiția
\[ \mathbb{P}_{H_0}\left(\frac{n - (p+1)}{p - p_0}\frac{RSS_0 - RSS}{RSS}>f_0\right) = \alpha \]
și cum \(\frac{n - (p+1)}{p - p_0}\frac{RSS_0 - RSS}{RSS}\sim F_{(p+1) - p_0, n - (p+1)}\) conform Propoziția 5.1 deducem că \(f_0 = f_{p - p_0, n - (p+1)}(1-\alpha)\). Am găsit că regiunea critică a testului bazat pe raportul de verosimilitate este identică cu cea a testului \(F\) a lui Fisher (a se vedea Propoziția 5.1).
5.5 Testarea ipotezei liniare generalizate
În această secțiune prezentăm un test statistic care generalizează testele menționate în secțiunile anterioare. Toate testele prezentate până acum pot fi văzute ca un caz particular al ipotezei liniare generale
\[ H_0:\, R\symbf \beta = r \quad \text{versus}\quad H_1:\, R\symbf \beta \neq r \]
unde \(R\) este o matrice dimensiune \(q\times(p+1)\) cu \(rang(R) = q\leq p+1\) iar \(r\) este un vector de dimensiune \(q\).
De exemplu, pentru testarea ipotezei din modelele imbricate, \(H_0:\, \beta_{p_0+1} = \cdots = \beta_p = 0\) versus \(H_1:\,\exists j\in\{p_0+1,\ldots,p\}\, \beta_j\neq 0\) putem alege
\[ R = \begin{pmatrix}0 & I_q\end{pmatrix} \quad\text{și}\quad r = 0_q \]
iar pentru testarea semnificativității coeficientului \(\beta_j\) alegem \(R = (0,\ldots,0,1,0,\ldots,0)^\intercal\) unde \(1\) se află pe poziția \(j+1\) și \(r = 0\) scalar. Mai mult, pentru testarea egalității a doi coeficienți \(\beta_i = \beta_j\) alegem
\[ R = (0,\ldots,0,\underbrace{1}_{i+1},0\ldots,0,\underbrace{-1}_{j+1},0,\ldots,0). \]
Impunând restricția \(R\symbf \beta = r\) revine la a impune \(q\) (rangul matricii \(R\)) restricții liniare asupra parametrilor ceea ce implică faptul că răspunsul mediu \(\mathbb{E}[\symbf Y]\) nu mai aparține spațiului generat de coloanele matricii de design, i.e. \(\mathbb{E}[\symbf Y]\notin \mathcal{M}(X)\), ci unui subspațiu generat de coloanele matricii \(\symbf X\) care satisfac restricția \(R\symbf \beta = 0\).
Definiția 5.1 (Ipoteză liniară generală) Se numește ipoteză liniară generală asociată modelului de regresie liniară multiplă, ipoteza \(H_0\) de forma \(R\symbf \beta = r\), unde \(R\) este o matrice de dimensiune \(q\times(p+1)\) și de rang \(q\) iar \(r\) este un vector de dimensiune \(q\).
Avem următorul rezultat a cărui demonstrație se poate consulta spre exemplu în (Rencher and Schaalje 2008) sau (Sen and Srivastava 2012):
Propoziția 5.5 (Testul lui Fisher pentru o ipoteză liniară) Fie modelul de regresie liniară \(\symbf Y = \symbf X\symbf \beta + \symbf\varepsilon\) sub ipotezele \(\mathcal{H}_1\) și \(\mathcal{H}_2'\). Ne propunem să testăm ipoteza liniară generală \(H_0:\, R\symbf \beta = r\), unde \(R\) are rangul \(q\) versus alternativa \(H_1:\, R\symbf \beta \neq r\). Fie \(\mathcal{M}_0\) subspațiul lui \(\mathcal{M}(X)\) de dimensiune \(p + 1 - q\) generat de restricția \(R\symbf \beta = r\) (sub \(H_0\)) și \(\mathcal{M}(X)\) subspațiul de dimensiune \(p+1\) asociat lui \(H_1\).
Pentru a testa cele două ipoteze vom folosi statistica de test \(F\) care sub ipoteza nulă verifică
\[ \begin{aligned} F &= \frac{\dim(\mathcal{M}(X)^\perp)}{\dim(\mathcal{M}_0^\perp\cap\mathcal{M}(X))}\frac{\lVert\hat{\symbf Y} - \hat{\symbf Y}_0\rVert^2}{\lVert\symbf Y - \hat{\symbf Y}\rVert^2} = \frac{n - (p+1)}{q}\frac{\lVert\symbf Y - \hat{\symbf Y}_0\rVert^2 - \lVert\symbf Y - \hat{\symbf Y}\rVert^2}{\lVert\symbf Y - \hat{\symbf Y}\rVert^2} \\ &= \frac{n - (p+1)}{q}\frac{RSS_0 - RSS}{RSS}\sim F_{q, n - (p+1)} \end{aligned} \]
În plus avem că \(\hat{\symbf Y}_0\) este
\[ \symbf X\hat{\symbf\beta}_0 = \symbf X\hat{\symbf\beta} + \symbf X (\symbf X^\intercal\symbf X)^{-1}R^\intercal\left[R(\symbf X^\intercal\symbf X)^{-1}R^\intercal\right]^{-1}(r - R\hat{\symbf\beta}). \]
Demonstrație (Propoziția 5.5). Vom arăta pentru început că estimatorul obținut prin metoda celor mai mici pătrate cu restricții (sub \(H_0\)), definit prin
\[ \hat{\beta}_0 =\operatorname{argmin}\|Y-X \beta\|^2 \quad \text { astfel ca } \quad R \beta=r, \]
este egal cu
\[ \hat{\beta}_0=\hat{\beta}+\left(X^{\intercal} X\right)^{-1} R^{\intercal}\left[R\left(X^{\intercal} X\right)^{-1} R^{\intercal}\right]^{-1}(r-R \hat{\beta}). \]
Vom folosi metoda multiplicatorilor lui Lagrange. Pentru aceasta considerăm lagrangianul
\[ \begin{aligned} \mathcal{L} &= \|Y-X \beta\|^2-\lambda^{\intercal}(R \beta-r) \\ &= Y^{\intercal} Y+\beta^{\intercal} X^{\intercal} X \beta-2 Y^{\intercal} X \beta - \lambda^{\intercal}(R \beta-r) \end{aligned} \]
Condițiile lui Lagrange permit obținerea unui minim
\[ \left\{\begin{array}{l} \frac{\partial \mathcal{L}}{\partial \beta}=-2 X^{\intercal} Y+2 X^{\intercal} X \hat{\beta}_0-R^{\intercal} \hat{\lambda}=0 \\ \frac{\partial \mathcal{L}}{\partial \lambda}=R \hat{\beta}_0-r=0 \end{array}\right. \]
Înmulțind la stânga prima egalitate cu \(R\left(X^{\prime} X\right)^{-1}\), deducem
\[ \begin{aligned} -2 R\left(X^{\intercal} X\right)^{-1} X^{\intercal} Y+2 R\left(X^{\intercal} X\right)^{-1} X^{\intercal} X \hat{\beta}_0-R\left(X^{\intercal} X\right)^{-1} R^{\intercal} \hat{\lambda} & =0 \\ -2 R\left(X^{\intercal} X\right)^{-1} X^{\intercal} Y+2 R \hat{\beta}_0-R\left(X^{\intercal} X\right)^{-1} R^{\intercal} \hat{\lambda} & =0 \\ -2 R\left(X^{\intercal} X\right)^{-1} X^{\intercal} Y+2 r-R\left(X^{\intercal} X\right)^{-1} R^{\intercal} \hat{\lambda} & =0 \end{aligned} \]
Obținem astfel pentru \(\hat{\lambda}\)
\[ \hat{\lambda}=2\left[R\left(X^{\intercal} X\right)^{-1} R^{\intercal}\right]^{-1}\left[r-R\left(X^{\intercal} X\right)^{-1} X^{\intercal} Y\right] \]
Înlocuim acum \(\hat{\lambda}\) și găsim
\[ \begin{array}{r} -2 X^{\intercal} Y+2 X^{\intercal} X \hat{\beta}_0-R^{\intercal} \hat{\lambda}=0 \\ -2 X^{\intercal} Y+2 X^{\intercal} X \hat{\beta}_0-2 R^{\intercal}\left[R\left(X^{\intercal} X\right)^{-1} R^{\intercal}\right]^{-1}\left[r-R\left(X^{\intercal} X\right)^{-1} X^{\intercal} Y\right]=0 \end{array} \]
de unde obținem \(\hat{\beta}_0\), folosindu-ne de faptul că în modelul nerestricționat avem \(\hat{\beta}=\left(X^{\intercal} X\right)^{-1} X^{\intercal} Y\), prin urmare
\[ \begin{aligned} \hat{\beta}_0 & =\left(X^{\intercal} X\right)^{-1} X^{\intercal} Y+\left(X^{\intercal} X\right)^{-1} R^{\intercal}\left[R\left(X^{\intercal} X\right)^{-1} R^{\intercal}\right]^{-1}(r-R \hat{\beta}) \\ & =\hat{\beta}+\left(X^{\intercal} X\right)^{-1} R^{\intercal}\left[R\left(X^{\intercal} X\right)^{-1} R^{\intercal}\right]^{-1}(r-R \hat{\beta}) \end{aligned} \]
Funcția \(\|Y-X \beta\|^2\) care trebuie minimizată este o funcție convexă pe o mulțime convexă (de constrângeri liniare), astfel încât minimul este unic.
Plecând de la expresia estimatorului \(\hat{\beta}_0\), înmulțindu-l cu \(X\) obținem imediat că:
\[ \hat{Y}_0=X \hat{\beta}_0=X \hat{\beta}+X\left(X^{\top} X\right)^{-1} R^{\top}\left[R\left(X^{\top} X\right)^{-1} R^{\top}\right]^{-1}(r-R \hat{\beta}), \]
Fie acum \(P=X\left(X^{\top} X\right)^{-1} X^{\top}\) și respectiv \(P_0\) matricele ortogonale de proiecție pe spațiile \(\mathcal{M}(X)\) și \(\mathcal{M}_0\). Atunci reziduurile sunt
\[ e=Y-\hat{Y}=(I-P) Y, \quad e_0=Y-\hat{Y}_0=\left(I-P_0\right) Y, \]
și
\[ R S S=\|e\|^2=Y^{\top}(I-P) Y, \quad R S S_0=\left\|e_0\right\|^2=Y^{\top}\left(I-P_0\right) Y . \]
Cum \(\mathcal{M}_0 \subset \mathcal{M}(X)\), avem \(P_0 P=P_0\) și \(P P_0=P_0\), astfel rezultă că \(P-P_0\) este o matrice de proiecție ortogonală pe \(\mathcal{M}(X) \cap \mathcal{M}_0^{\perp}\) și în particular este simetrică și idempotentă. Acum:
\[ RSS_0-RSS=Y^{\top}\left[\left(I-P_0\right)-(I-P)\right] Y=Y^{\top}\left(P-P_0\right) Y \]
dar, fiindcă \(\left(P-P_0\right)\) proiectează pe componenta din \(\mathcal{M}(X)\) ortogonală la \(\mathcal{M}_0\), avem și
\[ Y^{\top}\left(P-P_0\right) Y=\left\|\left(P-P_0\right) Y\right\|^2=\left\|\hat{Y}-\hat{Y}_0\right\|^2 \]
deci:
\[ RSS_0-RSS=\left\|\hat{Y}-\hat{Y}_0\right\|^2 . \]
Am văzut că:
\[ \hat{\beta}_0-\hat{\beta}=\left(X^{\top} X\right)^{-1} R^{\top} \left[R\left(X^{\top} X\right)^{-1} R^{\top}\right]^{-1}(r-R \hat{\beta}) \]
și aplicând \(X\) :
\[ \hat{Y}_0-\hat{Y}=X\left(\hat{\beta}_0-\hat{\beta}\right)=X\left(X^{\top} X\right)^{-1} R^{\top} \left[R\left(X^{\top} X\right)^{-1} R^{\top}\right]^{-1}(r-R \hat{\beta}) \]
prin urmare
\[ \begin{aligned} \left\|\hat{Y}-\hat{Y}_0\right\|^2 &= (r-R \hat{\beta}) ^{\top} \left[R\left(X^{\top} X\right)^{-1} R^{\top}\right]^{-1} \underbrace{R\left(X^{\top} X\right)^{-1} X^{\top} X\left(X^{\top} X\right)^{-1} R^{\top}}_{=R\left(X^{\top} X\right)^{-1} R^{\top}} \left[R\left(X^{\top} X\right)^{-1} R^{\top}\right]^{-1} (r-R \hat{\beta}) \\ &= (r-R \hat{\beta})^{\top} \left[R\left(X^{\top} X\right)^{-1} R^{\top}\right]^{-1} (r-R \hat{\beta}) \end{aligned} \]
Cum \(\left\|\hat{Y}-\hat{Y}_0\right\|^2=RSS_0-RSS\), avem
\[ RSS_0-RSS=(r-R \hat{\beta})^{\top}\left[R\left(X^{\top} X\right)^{-1} R^{\top}\right]^{-1}(r-R \hat{\beta}) . \] Pentru a determina repartiția lui \(F\) sub \(H_0\) să observăm că în ipoteza nulă, media \(\mu=\mathbb{E}(Y)=X \beta\) aparține lui \(\mathcal{M}_0\) și putem scrie \(Y=\mu+\varepsilon\). Cum \(RSS_0-RSS=Y^{\top}\left(P-P_0\right) Y\) iar \(\left(P-P_0\right) \mu=0\) fiindcă \(\mu \in \mathcal{M}_0\), obținem
\[ RSS_0-RSS=\varepsilon^{\top}\left(P-P_0\right) \varepsilon. \]
Cum \(P-P_0\) este o matrice de proiecție ortogonală pe \(\mathcal{M}(X) \cap \mathcal{M}_0^{\perp}\) de rang
\[ \operatorname{rang}\left(P-P_0\right)=\operatorname{dim}(\mathcal{M}(X))-\operatorname{dim}\left(\mathcal{M}_0\right)=(p+1)-(p+1-q)=q \]
deducem că (formă pătratică de normale)
\[ \frac{\varepsilon^{\top}\left(P-P_0\right) \varepsilon}{\sigma^2} \sim \chi_q^2. \]
De asemenea, cum \(RSS=Y^{\top}\left(I-P\right) Y\) și \(\mu \in \mathcal{M}(X)\) găsim că \(\left(I-P\right)\mu = 0\), astfel
\[ RSS=\varepsilon^{\top}\left(I-P\right) \varepsilon. \]
Dar \(I-P\) este o matrice de proiecție ortogonală pe \(\mathcal{M}(X)\) de rang \(n-(p+1)\) prin urmare
\[ \frac{RSS}{\sigma^2}=\frac{\varepsilon^{\top}\left(I-P\right) \varepsilon}{\sigma^2} \sim \chi_{n-(p+1)}^2. \]
În plus, subspațile pe care proiectează \(P-P_0\) și \(I-P\) sunt ortogonale:
\[ \mathcal{M}(X) \cap \mathcal{M}_0^{\perp} \perp \mathcal{M}(X)^{\perp} \]
și cum \(\varepsilon \sim \mathcal{N}\left(0, \sigma^2 I\right)\), aceasta implică independența variabilelor \(\varepsilon^{\top}\left(P-P_0\right) \varepsilon\) și \(varepsilon^{\top}(I-P) \varepsilon\) (componentele ortogonale sunt independente). Rezultă astfel că
\[ \begin{aligned} F &= \frac{n - (p+1)}{q}\frac{\lVert\boldsymbol Y - \hat{\boldsymbol Y}_0\rVert^2 - \lVert\boldsymbol Y - \hat{\boldsymbol Y}\rVert^2}{\lVert\boldsymbol Y - \hat{\boldsymbol Y}\rVert^2} \\ &= \frac{n - (p+1)}{q}\frac{RSS_0 - RSS}{RSS}\sim F_{q, n - (p+1)}. \end{aligned} \]
6 Exerciții
Exercițiul 6.1 (Metoda celor mai mici pătrate cu restricții) Considerăm modelul de regresie liniară multiplă \(Y=X \beta+\varepsilon\). Definim estimatorul obținut prin metoda celor mai mici pătrate clasic și cel cu restricții prin
\[ \begin{aligned} \hat{\beta} & =\operatorname{argmin}\|Y-X \beta\|^2 \\ \hat{\beta}_c & =\operatorname{argmin}\|Y-X \beta\|^2 \quad \text { astfel ca } \quad R \beta=r, \end{aligned} \]
unde \(R\) este o matrice de dimensiune \(q \times p\) de rang \(q \leq p\) și \(r\) un vector din \(\mathbb{R}^q\).
Calculați estimatorul obținut prin metoda celor mai mici pătrate.
Verificați că estimatorul obținut prin metoda celor mai mici pătrate cu restricții este egal cu
\[ \hat{\beta}_c=\hat{\beta}+\left(X^{\intercal} X\right)^{-1} R^{\intercal}\left[R\left(X^{\intercal} X\right)^{-1} R^{\intercal}\right]^{-1}(r-R \hat{\beta}). \]
Calculați eroare pătratică medie a lui \(\hat{\beta}_c\) și comparați cu eroarea pătratică medie a estimatorului obținut prin metoda celor mai mici pătrate ordinare.
Ilustrați în
Rrezultatele din punctele de mai sus.
Exercițiul 6.2 (Înălțimea arborelui de eucalipt) Dorim să explicăm înălțimea unui arbore \(y\) (măsurată în metrii) în funcție de diametrul său \(x\) (măsurat în centimetrii) la 1.3 m de sol și de radicalul acestuia. Dispunem de \(n = 1429\) de perechi \((x_i, y_i)\) de măsurători (a se vedea de mai jos).
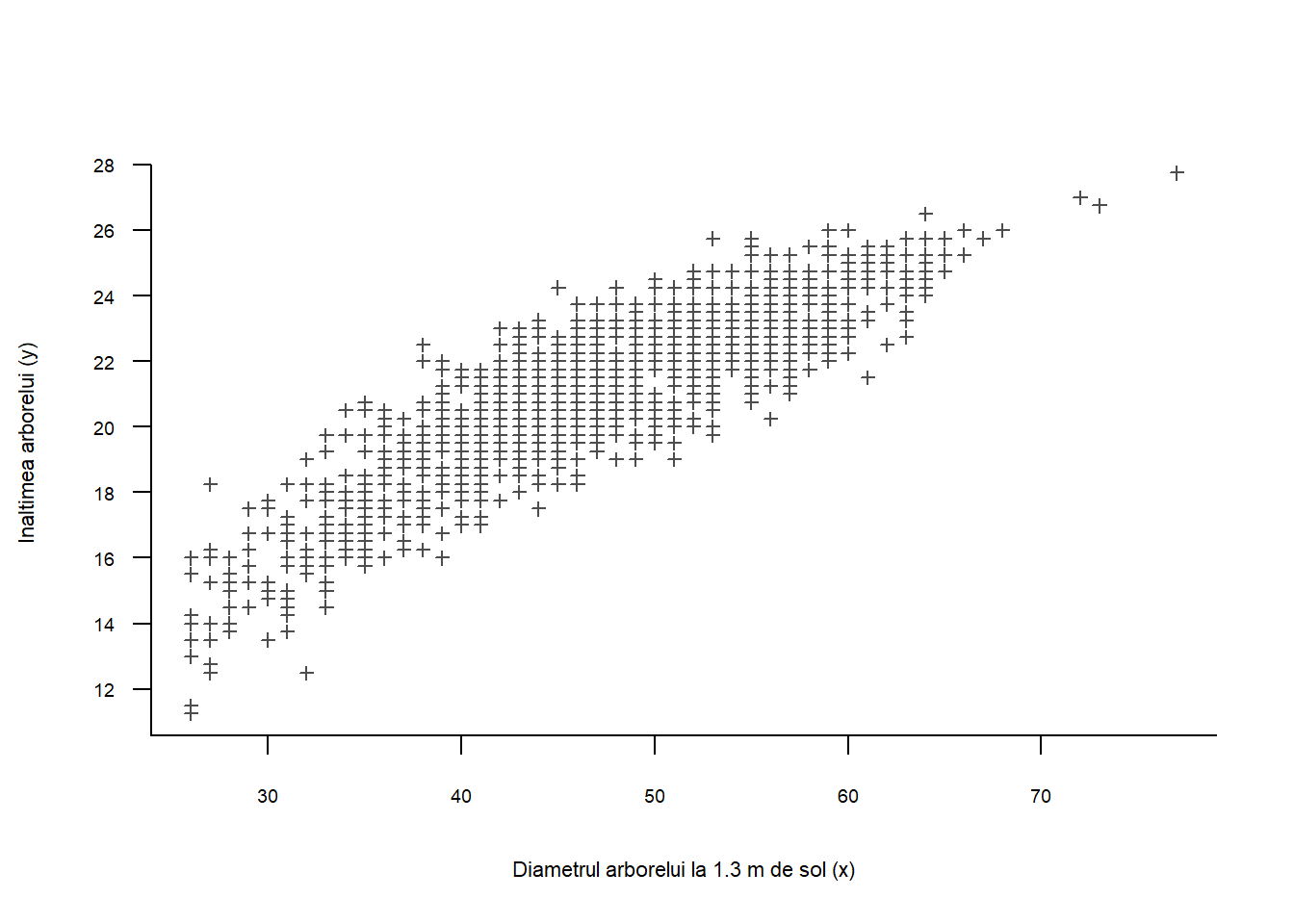
Considerăm modelul de regresie următor:
\[ y_i = \beta_0 + \beta_1 x_i + \beta_2\sqrt{x_i} + \varepsilon_i, \quad 1\leq i\leq n \]
unde \(\varepsilon_i\) sunt variabile aleatoare independente, repartizate normal de medie \(0\) și dispersie \(\sigma^2\). Considerând
\[ \boldsymbol X = \begin{pmatrix}1 & x_1 & \sqrt{x_1}\\ \vdots &\vdots &\vdots \\ 1 & x_n & \sqrt{x_n}\end{pmatrix} \quad \text{și}\quad \boldsymbol Y = \begin{pmatrix}y_1 \\ \vdots\\ y_n\end{pmatrix} \]
am observat
\[ \boldsymbol X^\intercal\boldsymbol X = \begin{pmatrix}? & ? & 9791.6\\ ? & 3306476 & ? \\ ? & 471237.9 & 67660\end{pmatrix}, \quad \boldsymbol X^\intercal\boldsymbol Y = \begin{pmatrix}30312.5 \\ 1461695.8\\ 209685.6\end{pmatrix}, \quad \boldsymbol Y^\intercal\boldsymbol Y = 651857.9. \]
Determinați valorile necunoscute, \(?\), din matricea \(\boldsymbol X^\intercal\boldsymbol X\).
Care este valoarea diametrului mediu \(\bar{x}\) și care este înălțimea medie \(\bar{y}\) ?
În urma calculului obținem (cu aproximație)
\[ \left(\boldsymbol X^\intercal\boldsymbol X\right)^{-1} = \begin{pmatrix}5.295 & 0.116 & -1.577\\ 0.116 & 0.002 & -0.035 \\ -1.577 & -0.035 & 0.471\end{pmatrix}. \]
Calculați estimatorii \(\hat{\beta}_0, \hat{\beta}_1, \hat{\beta}_2\) prin metoda celor mai mici pătrate și reprezentați pe graficul de mai sus curba de regresie.
Calculați estimatorul lui \(\sigma^2\) și construiți un interval de încredere de nivel de încredere de \(95\%\) pentru \(\beta_2\).
Testați ipoteza \(\beta_1 = 0\) la un nivel de semnificație de \(10\%\).
Construiți cîte un interval de predicție de nivel \(95\%\) pentru \(y_{n+1}\) știind că \(x_{n+1} = 49\) și respectiv \(x_{n+1} = 25\). Care dintre acestea este mai mare ? Ne așteptam la așa ceva ?
Exercițiul 6.3 (Modele imbricate și \(R^2\)) Considerăm modelul de regresie liniară
\[ \boldsymbol Y = \boldsymbol X\boldsymbol \beta + \boldsymbol \varepsilon \]
sub ipotezele \(\mathcal{H}_1: \, rang(\boldsymbol X) = p+1\) și \(\mathcal{H}_2': \, \boldsymbol \varepsilon \sim\mathcal{N}(0, \sigma^2 I_n)\).
Ne propunem să testăm dacă ultimii \(q\) coeficienți, \(q = p - p_0\leq p+1\), sunt nuli, altfel spus vrem să testăm ipotezele
\[ H_0:\, \beta_{p_0+1} = \cdots = \beta_p = 0 \quad \text{versus}\quad H_1:\,\exists j\in\{p_0+1,\ldots,p\}\, \beta_j\neq 0 \]
Sub ipoteza nulă \(H_0\) statistica de test
\[ F = \frac{n - (p+1)}{q}\frac{\lVert\hat{\boldsymbol Y} - \hat{\boldsymbol Y}_0\rVert^2}{\lVert\boldsymbol Y - \hat{\boldsymbol Y}\rVert^2} = \frac{n - (p+1)}{q}\frac{RSS_0 - RSS}{RSS} \sim F_{q, n - (p+1)} \]
unde \(q = p - p_0\) iar \(F_{q, n - (p+1)}\) este repartiția lui Fisher cu \((q, n - (p+1))\) grade de libertate.
Arătați că statistica de test F se poate scrie sub forma
\[ F=\frac{R^2-R_0^2}{1-R^2} \frac{n-(p+1)}{p-p_0}, \]
unde \(R^2\) și \(R_0^2\) sunt coeficienții de determinare pentru modelul complet și respectiv modelul redus (modelul sub ipoteza \(H_0\)).
Exercițiul 6.4 (Echivalența dintre testul student și testul lui Fisher) Dorim să demonstrăm echivalența dintre testele Student și Fisher pentru nulitatea unui parametru. Luăm în considerare modelul \(Y=X \beta+\varepsilon\) în condițiile ipotezelor clasice, pentru care dorim să testăm nulitatea ultimului coeficient \(\beta_{p+1}\).
Reamintiți statistica \(T\) a testului Student sub ipoteza \(\mathrm{H}_{0}: \beta_{p+1}=0\).
Furnizați statistica \(F\) a testului Fisher pentru modelele imbricate corespunzătoare.
Fie \(T_{n}\) o variabilă care urmează o repartiție Student cu \(n\) grade de libertate. Reamintiți definiția acesteia și deduceți repartiția variabilei \(F_{n}=T_{n}^{2}\).
Se notează matricea de design sub formă de bloc \(X=\left[X_{0} \mid X_{p+1}\right]\), unde \(X_{0}=\left[X_{1}|\ldots| X_{p}\right]\) este matricea \(n \times p\) a primelor \(p\) coloane ale lui \(X\), iar \(X_{p+1}\) este ultima sa coloană. Scrieți matricea \(X^{\intercal} X\) sub forma a \(4\) blocuri.
Pe baza formulei de inversiune matricială pe blocuri, deduceți că
\[ \left[\left(X^{\intercal} X\right)^{-1}\right]_{p+1, p+1}=\left(X_{p+1}^{\intercal}\left(I_{n}-P_{0}\right) X_{p+1}\right)^{-1} \]
unde \(P_{0}\) este matricea \(n \times n\) de proiecție ortogonală pe spațiul \(\mathcal{M}_{0}\) generat de coloanele lui \(X_{0}\).
- Notând cu \(\hat{Y}\) și \(\hat{Y}_{0}\) proiecțiile ortogonale ale lui \(Y\) pe \(\mathcal{M}\) și \(\mathcal{M}_{0}\), și justificând faptul că
\[ \hat{Y}_{0}=P_{0} Y=P_{0} P Y=P_{0} \hat{Y} \]
arătați că
\[ \hat{Y}-\hat{Y}_{0}=\hat{\beta}_{p+1}\left(I_{n}-P_{0}\right) X_{p+1} \]
- Deduceți că \(F=T^{2}\) și concluzionați.
Exercițiul 6.5 (Model cu trei variabile explicative) Se consideră un model de regresie de forma:
\[ y_{i}=\beta_{1}+\beta_{2} x_{i, 2}+\beta_{3} x_{i, 3}+\beta_{4} x_{i, 4}+\varepsilon_{i}, \quad 1 \leq i \leq n . \]
Se presupune că \(x_{i, j}\) nu sunt aleatorii. Se presupune că termenii eroare \(\varepsilon_{i}\) ai modelului sunt variabile aleatoare independente, gaussiene, centrate, cu aceeași varianță \(\sigma^{2}\). Notăm, ca de obicei
\[ X=\begin{bmatrix} 1 & x_{1,2} & x_{1,3} & x_{1,4} \\ \vdots & \vdots & \vdots & \vdots\\ 1 & x_{n, 2} & x_{n, 3} & x_{n, 4} \end{bmatrix}, \quad Y=\begin{bmatrix} y_{1} \\ \vdots \\ y_{n} \end{bmatrix}, \quad \beta=\begin{bmatrix} \beta_{1} \\ \beta_{2} \\ \beta_{3} \\ \beta_{4} \end{bmatrix} \]
Un calcul preliminar a dat
\[ X^{\intercal} X=\begin{bmatrix} 50 & 0 & 0 & 0 \\ 0 & 20 & 15 & 4 \\ 0 & 15 & 30 & 10 \\ 0 & 4 & 10 & 40 \end{bmatrix}, \quad X^{\intercal} Y=\begin{bmatrix} 100 \\ 50 \\ 40 \\ 80 \end{bmatrix}, \quad Y^{\intercal} Y=640 . \]
Admitem că
\[ \begin{bmatrix} 20 & 15 & 4 \\ 15 & 30 & 10 \\ 4 & 10 & 40 \end{bmatrix}^{-1}=\frac{1}{13720}\begin{bmatrix} 1100 & -560 & 30 \\ -560 & 784 & -140 \\ 30 & -140 & 375 \end{bmatrix} \]
Calculați \(\hat{\beta}\), estimatorul obținut prin metoda celor mai mici pătrate pentru \(\beta\), suma pătratelor reziduurilor \(\sum_{i=1}^{50} \hat{\varepsilon}_{i}^{2}\) și dați estimatorul lui \(\sigma^{2}\).
Dați un interval de încredere pentru \(\beta_{2}\), la nivelul de \(95\%\). Procedați la fel pentru \(\sigma^{2}\) (se dă \(c_{1}=29\) și \(c_{2}=66\) pentru cuantilele de ordinul \(2.5\%\) și \(97.5\%\) ale unei repartiții \(\chi^2\) cu \(46\) de grade de libertate).
Testați validitatea globală a modelului (\(\beta_{2}=\beta_{3}=\beta_{4}=0\)) la nivelul de semnificație de \(5\%\) (se dă \(f_{3,46}(0,95)=\) 2,80 pentru cuantila de ordinul \(95\%\) a unei repartiții Fisher cu \((3,46)\) grade de libertate).
Se presupune că \(x_{51,2}=1, x_{51,3}=-1\) și \(x_{51,4}=0,5\). Dați un interval de predicție de nivel \(95\%\) pentru \(y_{51}\).
Ilustrați în
Rpunctele anterioare.
Exercițiul 6.6 (Modelul Cobb-Douglas) Avem pentru \(n\) întreprinderi valoarea capitalului \(K_{i}\), ocuparea forței de muncă \(L_{i}\) și valoarea adăugată \(V_{i}\). Presupunem că funcția de producție a acestor întreprinderi este de tip Cobb-Douglas:
\[ V_{i}=\lambda L_{i}^{\beta} K_{i}^{\gamma} \]
și prin logaritmare:
\[ \log V_{i}=\alpha+\beta \log L_{i}+\gamma \log K_{i} \]
Modelul liniar asociat este:
\[ \log V_{i}=\alpha+\beta \log L_{i}+\gamma \log K_{i}+\varepsilon_{i} \]
unde \(\varepsilon_{i}\) sunt presupuse i.i.d. de repartiție \(\mathcal{N}\left(0, \sigma^{2}\right)\).
Scrieți modelul sub forma matricială \(Y=X b+\varepsilon\), specificând \(Y\), \(X\) și \(b\). Reamintiți expresia estimatorului obținut prin metoda celor mai mici pătrate \(\hat{b}\). Precizați matricea sa de varianță-covarianță. Precizați un estimator nedeplasat pentru \(\sigma^{2}\) și un estimator nedeplasat pentru \(\operatorname{Var}(\hat{b})\).
Pentru \(1658\) de întreprinderi, am obținut prin metoda celor mai mici pătrate următoarele rezultate:
\[ \left\{\begin{array}{l} \log V_{i}=3.136+0.738 \log L_{i}+0.282 \log K_{i} \\ R^{2}=0.945 \\ RSS=148.27 \end{array}\right. \]
De asemenea, avem:
\[ \left(X^{\intercal} X\right)^{-1}=\begin{bmatrix} 0.0288 & 0.0012 & -0.0034 \\ 0.0012 & 0.0016 & -0.0010 \\ -0.0034 & -0.0010 & 0.0009 \end{bmatrix} \]
Calculați \(\hat{\sigma}^{2}\) și o estimare a \(\operatorname{Var}(\hat{b})\).
Dați un interval de încredere la nivelul de încredere de \(95\%\) pentru \(\beta\). Aceeași întrebare pentru \(\gamma\).
Testați la nivelul de semnificație de \(5\%\) ipoteza nulă \(H_{0}: \gamma=0\) versus ipoteza alternativă \(H_{1}: \gamma>0\).
Vrem să testăm ipoteza conform căreia randamentele de scală sunt constante (o funcție de producție \(F\) are randament de scală constant dacă \(\forall \alpha \in \mathbb{R}^{+}\), \(F(\alpha L, \alpha K)= \alpha F(L, K)\). Care sunt constrângerile verificate de model atunci când randamentele de scală sunt constante? Testați la nivelul de semnificație de \(5\%\) ipotezele \(H_{0}\): randamentele sunt constante, față de \(H_{1}\): randamentele sunt crescânde.
Exercițiul 6.7 (Model cu două variabile explicative II) Se ia în considerare următorul model de regresie:
\[ y_{i}=\beta_{1}+\beta_{2} x_{i, 2}+\beta_{3} x_{i, 3}+\varepsilon_{i}, \quad 1 \leq i \leq n \]
\(x_{i, j}\) sunt variabile explicative ale modelului, \(\varepsilon_{i}\) sunt variabile aleatoare independente, cu repartiție normală centrată, care admit aceeași varianță \(\sigma^{2}\). Stabilind:
\[ X=\begin{bmatrix} 1 & x_{1,2} & x_{1,3} \\ \vdots & \vdots & \vdots \\ 1 & x_{n, 2} & x_{n, 3} \end{bmatrix} \quad \text { și } \quad Y=\begin{bmatrix} y_{1} \\ \vdots \\ y_{n} \end{bmatrix} \]
am observat că
\[ X^{\intercal} X=\begin{bmatrix} 30 & 20 & 0 \\ 20 & 20 & 0 \\ 0 & 0 & 10 \end{bmatrix}, \quad X^{\intercal} Y=\begin{bmatrix} 15 \\ 20 \\ 10 \end{bmatrix}, \quad Y^{\intercal} Y=59.5 . \]
Determinați valoarea lui \(n\), media lui \(x_{i, 3}\), coeficientul de corelație al lui \(x_{i, 2}\) și al lui \(x_{i, 3}\).
Estimați \(\beta_{1}, \beta_{2}, \beta_{3}, \sigma^{2}\) prin metoda celor mai mici pătrate.
Calculați pentru \(\beta_{2}\) un interval de încredere de \(95\%\) și testați ipoteza \(\beta_{3}=0.8\) la un nivel de semnificație de \(10\%\).
Testați \(\beta_{2}+\beta_{3}=3\) împotriva \(\beta_{2}+\beta_{3} \neq 3\), la un nivel de semnificație de \(5\%\).
Care este valoarea lui \(\bar{y}\), media empirică a lui \(y_{i}\)? Deduceți coeficientul de determinare ajustat \(R_{a}^{2}\).
Construiți un interval de predicție de nivel \(95\%\) pentru \(y_{n+1}\) cunoscând: \(x_{n+1,2}=3\) și \(x_{n+1,3}=0.5\).
Exercițiul 6.8 (Testare) Ne interesează modelul \(Y=X \beta+\varepsilon\) în condițiile ipotezelor clasice. Am obținut pentru \(21\) de date:
\[ \begin{aligned} \hat{y} & =6.683_{(2.67)}+0.44_{(2.32)} x_{1}+0.425_{(2.47)} x_{2}+0.171_{(2.09)} x_{3}+0.009_{(2.24)} x_{4} \\ R^{2} & =0.54 \end{aligned} \]
unde, pentru fiecare coeficient, numărul dintre paranteze reprezintă valoarea absolută a statisticii testului.
Care sunt ipotezele utilizate modelului?
Testează nulitatea lui \(\beta_{1}\) la pragul de semnificație de \(5\%\).
Puteți testa \(\mathrm{H}_{0}: \beta_{3}=1\) versus \(\mathrm{H}_{1}: \beta_{3} \neq 1\) ?
Testați nulitatea simultană a parametrilor asociați variabilelor \(x_{1}, \ldots, x_{4}\) la pragul de semnificație de \(5\%\).
Exercițiul 6.9 (Regresie liniară multiplă II) Se consideră modelul liniar
\[ Y_{i}=a+b W_{i}+c Z_{i}+\varepsilon_{i}, \quad i=1, \ldots, n \]
unde \(W_{i}\) și \(Z_{i}\) sunt numere reale fixe, \(\varepsilon_{i}\) sunt variabile aleatoare reale independente cu aceeași repartiție \(\mathcal{N}\left(0, \sigma^{2}\right)\), iar \(a, b, c, \sigma^{2}\) sunt parametri reali necunoscuți. Notăm cu \(W, Y, Z\) vectorii coloane ai lui \(\mathbb{R}^{n}\) cu coordonatele respective \(\left(W_{i}\right),\left(Y_{i}\right),\left(Z_{i}\right)\), iar \(\bar{W}=\frac{1}{n} \sum_{i=1}^{n} W_{i}\), \(\langle W, Z\rangle=\sum_{i=1}^{n} W_{i} Z_{i}\), \(\|W\|^{2}=\langle W, W\rangle\) și așa mai departe pentru celelalte variabile. În tot ce urmează, presupunem că \(\bar{W}=\bar{Z}=0\),
\[ \|W\|=\|Z\|=r>0, \quad\langle W, Z\rangle=r^{2} \sin \theta, \quad \theta \in (-\pi / 2, \pi / 2). \]
Calculați estimatorii obținuți prin metoda celor mai mici pătrate \(\widehat{a}\), \(\widehat{b}\), \(\widehat{c}\), pentru \(a\), \(b\), \(c\) în funcție de \(r\), \(\theta\) și de produsele scalare de tipul celui de mai sus. Determinați repartiția comună a \(\left(\widehat{a}, \widehat{b}, \widehat{c}, \widehat{\sigma}^{2}\right)\), unde \(\widehat{\sigma}^{2}\) este estimatorul obișnuit nedeplasat al lui \(\sigma^{2}\).
Dați un interval de încredere pentru \(c\) de nivel \(1-\alpha\), \(\alpha \in (0,1)\). Care este media pătratului lungimii sale? Cum variază în funcție de \(\theta\) ?
Dați un paralelipiped dreptunghic de încredere pentru \((a, b, c)\) de nivel \(97\%\) când \(n=27\).
Construiți un elipsoid de încredere pentru \((a, b, c)\) de nivel \(97\%\) pentru \(n=27\).
Referințe
Greene, William H. 2011. Econometric Analysis. 7th ed. Prentice Hall. http://gen.lib.rus.ec/book/index.php?md5=A0CEC5F0E1D09DF6E99A0E52B9B60DBB.
Jacod, Jean, and Philip Protter. 2003. Probability Essentials. Springer.
Ornea, L., and A. Turtoi. 2000. O Introducere in Geometrie. Fundatia Theta.
Rencher, Alvin C, and G Bruce Schaalje. 2008. Linear Models in Statistics. John Wiley & Sons.
Seber, George, and Alan Lee. 2003. Linear Regression Analysis. 2nd ed. Wiley.
Sen, Ashish, and Muni Srivastava. 2012. Regression Analysis: Theory, Methods, and Applications. Springer Science & Business Media.