Modele de regresie
Curs 7 - Regresie liniară multiplă - Interpretări geometrice
1 Interpretări geometrice - coeficientul de determinare
În această secțiune vom prezenta descompunerea ANOVA a modelului de regresie, vom defini, dintr-o perspectivă geometrică, coeficientul de determinare multiplă și vom investiga o serie de proprietăți ale acestuia.
Vom considera atât modelul de regresie liniară multiplă în care este inclus termenul liber cât și cel în care acesta nu apare. Fie astfel, modelul de regresie liniară \(\symbf Y = \symbf X\symbf \beta + \symbf \varepsilon\) în care \(\symbf Y\in\mathbb{R}^n\) este vectorul răspuns, \(\symbf X = \left[\mathbf{1}|\symbf X_1|\cdots|\symbf X_p\right]\in\mathcal{M}_{n, p+1}(\mathbb{R})\) sau \(\symbf X = \left[\symbf X_1|\cdots|\symbf X_p\right]\in\mathcal{M}_{n, p}(\mathbb{R})\) (pentru modelul fără termenul liber) este matricea de design (\(\mathrm{rang}(\symbf X) = p+1\) respectiv \(\mathrm{rang}(\symbf X) = p\)), \(\symbf \beta\in\mathbb{R}^{p+1}\) sau \(\symbf \beta\in\mathbb{R}^{p}\) este vectorul parametrilor după caz și \(\symbf \varepsilon\in\mathbb{R}^n\) este vectorul termenilor eroare.
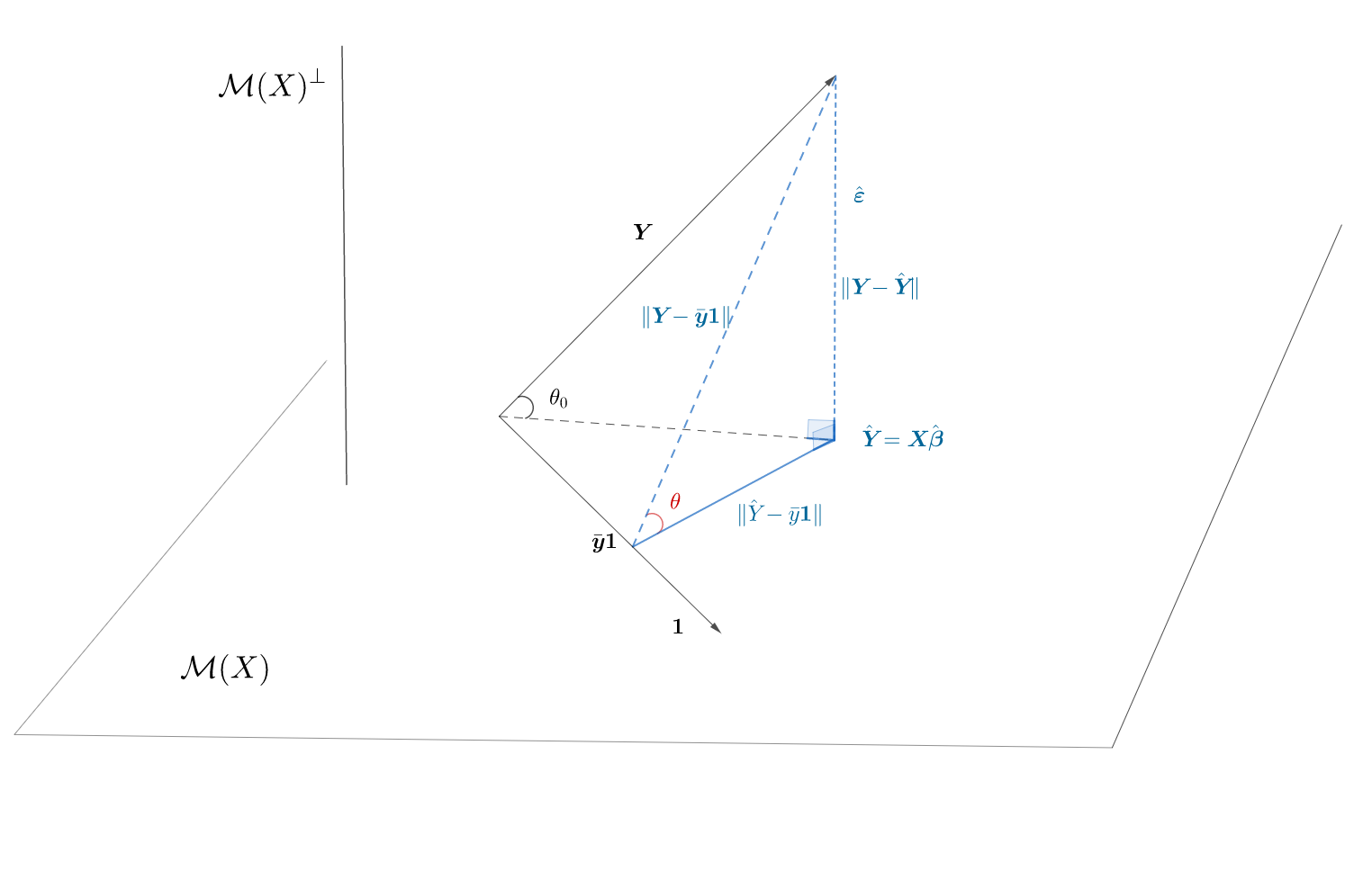
Notăm, ca și până acum, cu \(\mathcal{M}(X)\) subspațiul generat de coloanele matricii \(\symbf X\), cu \(\mathcal{M}(X)^\perp\) subspațiul ortogonal, cu \(\hat{\symbf Y} = \symbf X\hat{\symbf\beta}\) proiecția ortogonală a lui \(\symbf Y\) pe \(\mathcal{M}(X)\) și cu \(\hat{\symbf\varepsilon} = \symbf Y - \hat{\symbf Y}\in\mathcal{M}(X)^\perp\) vectorul valorilor reziduale.
Dacă modelul de regresie considerat nu include termenul liber (\(\beta_0\)) atunci, conform figurii de mai sus, observăm că putem aplica Teorema lui Pitagora direct (în triunghiul determinat de \(\symbf Y\), \(\hat{\symbf Y}\) și \(\hat{\symbf \varepsilon}\)) și obținem că
\[ \begin{aligned} \lVert \symbf Y\rVert^2 &= \lVert \hat{\symbf Y}\rVert^2 + \lVert\hat{\symbf\varepsilon}\rVert^2\\ &= \lVert \symbf X \hat{\symbf \beta}\rVert^2 + \lVert \symbf Y - \symbf X \hat{\symbf \beta}\rVert^2\\ SS_T &= SS_{reg} + RSS. \end{aligned} \]
Pe de altă parte, atunci când modelul include și termenul liber (cum este cazul în cele mai multe aplicații), atunci tot prin aplicarea Teoremei lui Pitagora, dar de această dată în triunghiul albastru, are loc următoarea descompunere (descompunerea ANOVA pentru regresie)
\[ \begin{aligned} \lVert \symbf Y - \bar{\symbf y}\mathbf{1}\rVert^2 &= \lVert \hat{\symbf Y} - \bar{\symbf y}\mathbf{1}\rVert^2 + \lVert\hat{\symbf\varepsilon}\rVert^2\\ SS_T &= SS_{reg} + RSS\\ \end{aligned} \]
unde
\(SS_{T} = \lVert \symbf Y - \bar{\symbf y}\mathbf{1}\rVert^2\) se numește suma abaterilor pătratice totale (variația totală)
\(SS_{reg} = \lVert \hat{\symbf Y} - \bar{\symbf y}\mathbf{1}\rVert^2\) se numește suma abaterilor pătratice de regresie (variația explicată de model)
\(RSS = \lVert \symbf Y - \hat{\symbf Y}\rVert^2 = \lVert\hat{\symbf\varepsilon}\rVert^2\) se numește suma abaterilor pătratice reziduale (variația reziduală)
astfel
\[ \text{Variația totală} = \text{Variația explicată de regresie } + \text{ Variația reziduală}. \]
Definiția 1.1 (Coeficientul de determinare) Coeficientul de determinare \(R^2\) (în R are denumirea de \(\texttt{Multiple R-Squared}\)) este definit prin
\[ R^2 = \cos^2(\theta_0) = \frac{\lVert \hat{\symbf Y}\rVert^2}{\lVert \symbf Y\rVert^2} = 1 - \frac{\lVert\hat{\symbf\varepsilon}\rVert^2}{\lVert \symbf Y\rVert^2} = 1 - \frac{RSS}{SS_T} \]
atunci când termenul liber nu este inclus în model și prin
\[ \begin{aligned} R^2 &= \cos^2(\theta) = \frac{\text{Variația explicată de model}}{\text{Variația totală}} = \frac{\lVert \hat{\symbf Y} - \bar{\symbf y}\mathbf{1}\rVert^2}{\lVert \symbf Y - \bar{\symbf y}\mathbf{1}\rVert^2} \\ &= 1 - \frac{\lVert\hat{\symbf\varepsilon}\rVert^2}{\lVert \symbf Y - \bar{\symbf y}\mathbf{1}\rVert^2} = 1 - \frac{RSS}{SS_T} \end{aligned} \]
atunci când termenul liber este inclus în model.
Din descompunerea ANOVA pentru regresie putem interpreta coeficientul de determinare (procentul din varianța totală explicat de model) astfel: cu cât este mai aproape \(R^2\) de \(1\) cu atât este mai mică suma abaterilor pătratice reziduale \(\lVert\hat{\symbf\varepsilon}\rVert^2 = \sum_{i=1}^{n}\hat{\varepsilon}_i^2\), prin urmare cu atât este mai bună potrivirea modelului pe date (ajustarea/fitul) - cazul extrem în care avem \(R^2 = 1\) implică \(\lVert\hat{\symbf\varepsilon}\rVert^2 = 0\) ceea ce înseamnă că punctele se regăsesc în hiperplanul de regresie și avem potrivire perfectă; pe de altă parte, cu cât \(R^2\) este mai aproape de \(0\), cu atât potrivirea pe date este slabă (ajustarea nu este prea bună) - cazul limită \(R^2 = 0\) implică faptul că predicția răspunsului \(y_i\) este întotdeauna egală cu media \(\bar{y}\) răspunsului și nu depinde de valorile covariabilelor, ceea ce arată că acestea nu au niciun impact asupra explicării modelului.
Trebuie să ținem cont că suntem în ipoteza în care modelul liniar considerat este adecvat datelor, în caz contrar (i.e. atunci când există relații neliniare între covariabile și răspuns), în care modelul nu este specificat corespunzător, putem avea un coeficient de determinare apropiat de \(0\) și cu toate acestea covariabilele să aibă o mare putere explicativă asupra răspunsului. Prin urmare, folosirea coeficientului de determinare ca (singură) măsură de ajustare a modelului se poate dovedi înșelătoare.
În Figura 1.2 avem diagramele de împrăștiere a patru modele simulate care întorc aproximativ același coeficient de determinare \(R^2 \approx 0.76\). Dacă în figura din stânga sus avem un exemplu de situație normală, în figura din dreapta sus variația reziduală este mai scăzută decât cea din primul grafic dar atunci și variația lui \(x\) este mai mică conducând la o valoare similară a lui \(R^2\). Figura din stânga jos arată o corelație puternică între răspuns și variabila explicativă (un coeficient de corelație de \(0.954\)), cu excepția a două observații aberante (outlier) iar figura din dreapta jos prezintă un model specificat incorect, relația fiind una pătratică.
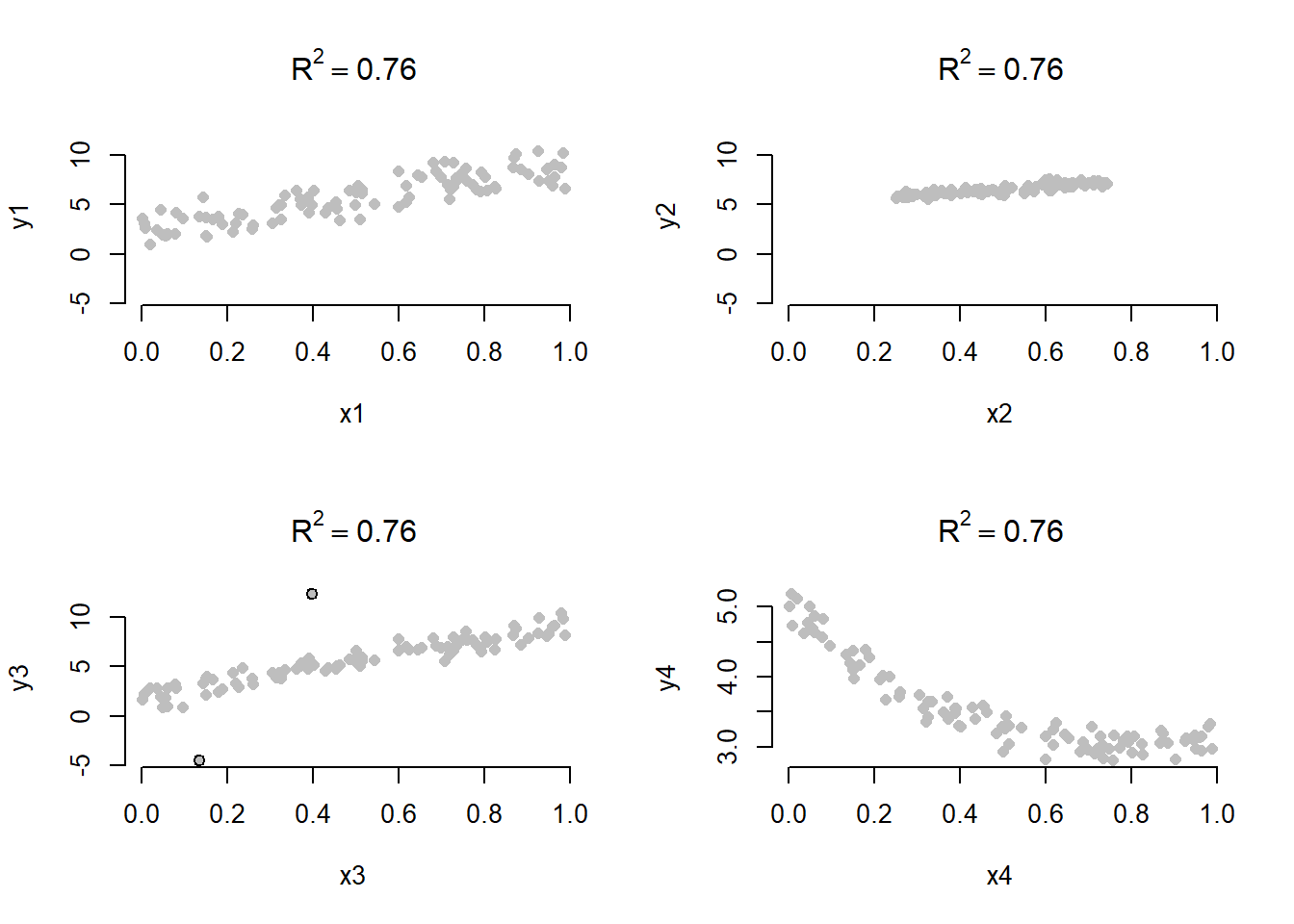
Este important de remarcat și că în modelul de regresie liniară multiplă, ca și în cazul modelului de regresie liniară simplă, putem interpreta coeficientul de determinare ca fiind pătratul coeficientului de corelație dintre răspuns \(y_i\) și valorile ajustate \(\hat{y}_i\): \(R^2 = r_{\symbf Y\hat{\symbf Y}}^2\).
Atunci când vrem să comparăm diferite modele pe baza coeficientului de determinare, trebuie să avem grijă ca următoarele condiții să fie îndeplinite:
fiecare model trebuie să aibă aceeași variabilă răspuns, nu putem compara modele în care primul are ca variabilă răspuns pe \(y\) iar al doilea pe \(h(y)\), \(h\) o transformare
fiecare model trebuie să aibă același număr de parametrii
fiecare model trebuie să includă termenul liber
Astfel, în general, nu putem folosi coeficientul de determinare pentru compararea modelelor după cum se vede și în exemplul următor.
Exemplul 1.1 (Prețul chiriilor în Munchen - compararea modelelor după \(R^2\)) După cum am văzut în Exemplul 1.1 și Exemplul 1.3 din Cursul 5, putem explicita relația dintre prețul chiriei pe metrul pătrat al apartamentelor din Munchen în funcție de suprafața de locuit a acestora prin diferite modele de regresie liniară:
\[ \begin{aligned} M_1 &: pret{\_m^2}_i = \beta_0 + \beta_1 \times suprafata_i + \varepsilon_i,\\ M_2 &: pret{\_m^2}_i = \beta_0 + \beta_1 \times \frac{1}{suprafata_i} + \varepsilon_i, \\ M_3 &: pret{\_m^2}_i = \beta_0 + \beta_1 \times suprafata_i + \beta_2 \times suprafata_i^2 + \varepsilon_i\\ M_4 &: pret{\_m^2}_i = \beta_0 + \beta_1 \times suprafata_i + \beta_2 \times suprafata_i^2 + \beta_3 \times suprafata_i^3 + \varepsilon_i \end{aligned} \] Tabelul 1.1 de mai jos include modelele estimate împreună cu coeficienții de determinare corespunzători:
| Modelul | Modelul estimat | Coeficientul de determinare \(R^2\) |
|---|---|---|
| \(M_1\) | \(\widehat{pret{\_m^2}_i} = 9.469 140.178 \times suprafata_i\) | 0.116 |
| \(M_2\) | \(\widehat{pret{\_m^2}_i} = 4.732 + 140.178\times \frac{1}{suprafata_i}\) | 0.154 |
| \(M_3\) | \(\begin{aligned}\widehat{pret{\_m^2}_i} &= 11.83 -0.106\times suprafata_i \\ &+ 4.7\times 10^{-4}\times suprafata_i^2\end{aligned}\) | 0.143 |
| \(M_4\) | \(\begin{aligned}\widehat{pret{\_m^2}_i} &= 14.28 -0.218\times suprafata_i \\ &+ 0.002\times suprafata_i^2 -6\times 10^{-6}\times suprafata_i^3\end{aligned}\) | 0.15 |
Se observă că pentru toate cele patru modele, coeficientul de determinare este relativ scăzut motivul principal fiind că, pe lângă variabilitatea mare a datelor, modelele nu includ o mare parte din covariabilele cu mare impact explicativ.
Dacă ne uităm la primele două modele, observăm că \(M_2\) are un coeficient de determinare mai mare \(R^2_{M_2} = 0.154 \geq R^2_{M_1} = 0.116\). Cum ambele modele conțin același număr de parametrii deducem că acest model este de preferat între cele două. Dacă ne uităm la modelele \(M_1\), \(M_3\) și \(M_4\) constatăm că acestea sunt modele imbricate (nested models) ceea ce înseamnă că modelul \(M_4\) include atât modelul \(M_3\) (\(\beta_3 = 0\)) cât și pe \(M_1\) (\(\beta_3 = \beta_2 = 0\)) iar modelul \(M_3\) îl conține pe \(M_1\) ca și caz particular (\(\beta_2 = 0\)). După cum vom vedea în Propoziția @ref(prop:reg-c7-prp1), asta implică faptul că \(M_1\) are cel mai mic coeficient de determinare între cele trei modele, \(M_3\) are al doilea cel mai mic \(R^2\) iar \(M_4\) are cel mai mare \(R^2\). O comparație între cele trei modele, în funcție de \(R^2\), în acest caz nu este recomandată deoarece modelele au un număr diferit de parametrii. Este de asemenea important de remarcat faptul că un model cu un număr mai mare de parametrii nu implică neapărat că are și un coeficient de determinare mai mare față de un model cu un număr mai mic de parametrii. Acest fenomen se observă atunci când comparăm \(M_2\) cu \(M_3\), \(R^2_{M_2} = 0.154 \geq R^2_{M_3} = 0.143\). În acest caz, modelul \(M_2\) este de preferat modelului \(M_3\) deoarece conține un număr mai mic de parametrii și are un coeficient \(R^2\) mai mare.
Arată codul R din exemplul de mai sus
# Compararea modelelor dupa coeficientul de determinare
munich <- read.table("dataIn/Munchen.raw", header = TRUE)
# model 1
munich_mod_rsq1 <- lm(rentsqm ~ area,
data = munich)
coef_munich_mod_rsq1 <- round(coef(munich_mod_rsq1), 3)
R2_mod_rsq1 <- round(summary(munich_mod_rsq1)$r.squared, 3)
# model 2
munich_mod_rsq2 <- lm(rentsqm ~ I(1/area),
data = munich)
coef_munich_mod_rsq2 <- round(coef(munich_mod_rsq2), 3)
R2_mod_rsq2 <- round(summary(munich_mod_rsq2)$r.squared, 3)
# model 3
munich_mod_rsq3 <- lm(rentsqm ~ I(area) + I(area^2),
data = munich)
coef_munich_mod_rsq3 <- round(coef(munich_mod_rsq3), 4)
R2_mod_rsq3 <- round(summary(munich_mod_rsq3)$r.squared, 3)
# model 4
munich_mod_rsq4 <- lm(rentsqm ~ I(area) + I(area^2) + I(area^3),
data = munich)
coef_munich_mod_rsq4 <- round(coef(munich_mod_rsq4), 6)
R2_mod_rsq4 <- round(summary(munich_mod_rsq4)$r.squared, 3)Cum coeficientul de determinare \(R^2 = 1 - \frac{RSS}{SS_{T}} = 1 - \frac{\hat{\sigma}}{SS_{T}}[n-(p+1)]\) observăm că acesta crește odată cu numărul de variabile explicative \(p\). În cele ce urmează vom defini o variantă a coeficientului de determinare care să amelioreze această problemă. Cum \(R^2\) nu ține cont de dimensiunea spațiului \(\mathcal{M}(X)\) se definește coeficientul de determinare ajustat \(R_a^2\) (în R are denumirea de \(\texttt{Adjusted R-Squared}\)).
Definiția 1.2 (Coeficientul de determinare ajustat) Coeficientul de determinare ajustat \(R_a^2\) este definit prin
\[ R_a^2 = 1 - \frac{\frac{\lVert\hat{\symbf\varepsilon}\rVert^2}{n-(p+1)}}{\frac{\lVert \symbf Y \rVert^2}{n}} = 1 - \frac{n}{n-(p+1)}\frac{\lVert\hat{\symbf\varepsilon}\rVert^2}{\lVert \symbf Y \rVert^2} = 1 - \frac{n}{n-(p+1)}(1 - R^2) \]
atunci când termenul liber nu este inclus în model și respectiv prin
\[ R_a^2 = 1 - \frac{\frac{\lVert\hat{\symbf\varepsilon}\rVert^2}{n-(p+1)}}{\frac{\lVert \symbf Y - \bar{\symbf y}\mathbf{1}\rVert^2}{n-1}} = 1 - \frac{n-1}{n-(p+1)}\frac{\lVert\hat{\symbf\varepsilon}\rVert^2}{\lVert \symbf Y - \bar{\symbf y}\mathbf{1}\rVert^2} = 1 - \frac{n-1}{n-(p+1)}(1 - R^2). \]
atunci când termenul liber este inclus în model.
Ajustarea corespunde la împărțirea normelor la pătrat cu dimensiunea subspațiului din care fac parte vectorii. Notăm de asemenea că \(R^2_a\) nu mai măsoară proporția variabilității lui \(y\) explicate de modelul de regresie și în plus \(R^2_a\leq 1\) și poate lua chiar și valori negative.
Exemplul 1.2 (Compararea coeficienților de determinare \(R^2\) și \(R^2_{a}\)) Pentru a vedea diferența dintre cei doi coeficienți de determinare considerăm următorul studiu de simulare în care presupunem că generăm observațiile \(x_{i1}, x_{i2}, x_{i3}, y_i\) pentru \(i = 1,2,\ldots,n =100\) conform modelului de regresie liniară
\[ y_i = \beta_0 + \beta_1 x_{i1} + \beta_2 x_{i2} + \beta_3 x_{i3} + \varepsilon_i, \]
unde \(x_1,x_2, x_3\sim \mathcal{N}(0,1)\) și \(\varepsilon_i\sim \mathcal{N}(0, 9)\). La aceste date adăugăm \(p-3 = 94\) variabile explicative fictive \(x_j\sim\mathcal{N}(0,1)\) care sunt independente de \(y\) rezultând într-un total de \(p=97\) covariabile dintre care doar primele două (\(x_1\) și \(x_2\)) sunt relevante în explicarea răspunsului. Calculăm coeficienții de determinare \(R^2(j)\) și respectiv \(R^2_a(j)\) pentru fiecare dintre modelele
\[ y = \beta_0 + \beta_1 x_{1} + \beta_2 x_{2} + \cdots + \beta_j x_{j} + \varepsilon, \]
unde \(j = 1, 2, \ldots, p\) și trasăm pe același grafic curbele \((j, R^2(j))\) și \((j, R^2_a(j))\). Cum \(R^2\) și \(R^2_a\) sunt variabile aleatoare, repetăm experimentul de \(M = 200\) ori.
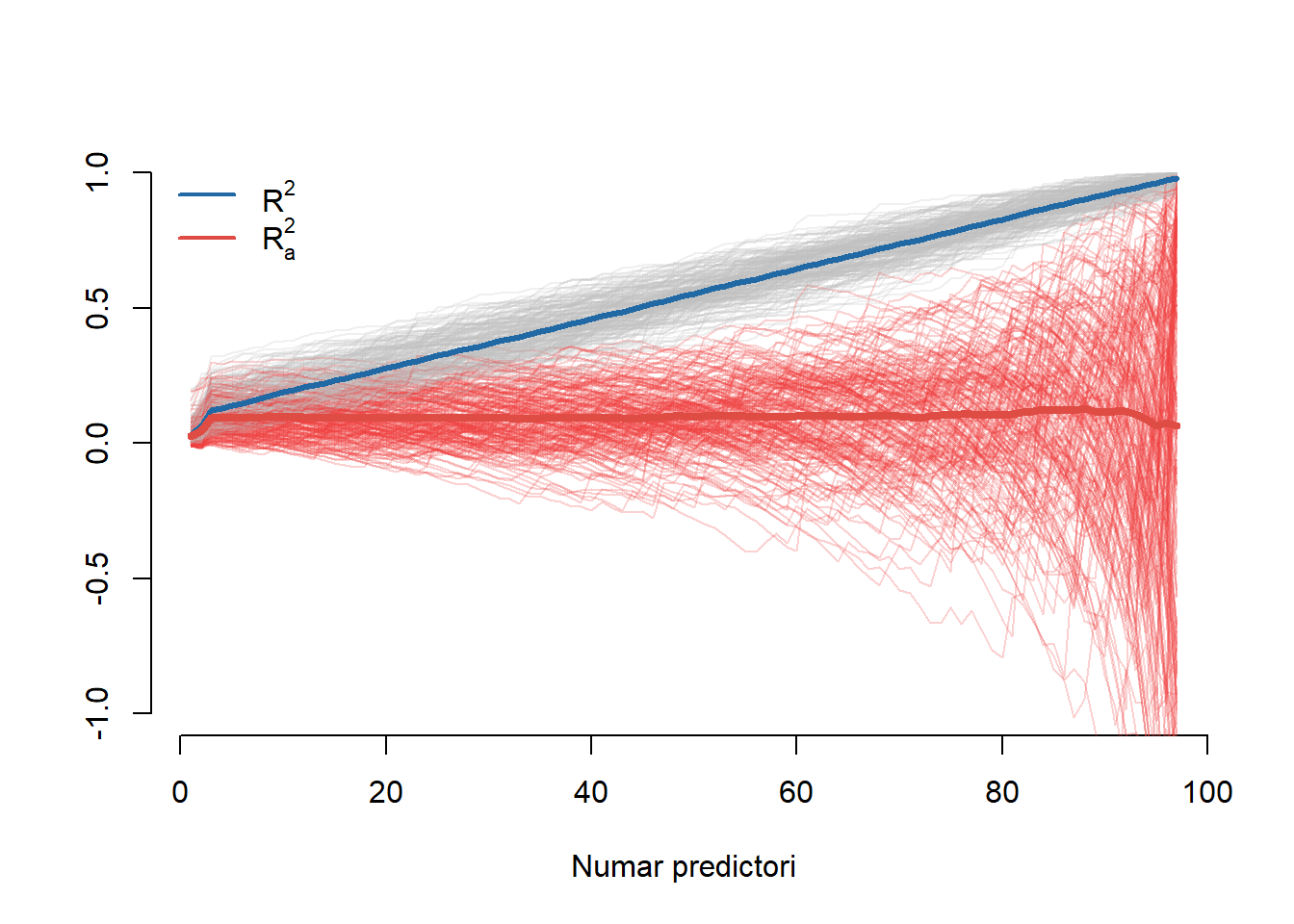
Rezultatele sunt ilustrate în figura de mai jos (curbele îngroșate sunt curbele medii). Putem observa că \(R^2\) crește liniar odată cu numărul de predictori din model chiar dacă doar primii trei predictori sunt relevanți în explicarea lui \(y\). Pe de altă parte \(R^2_a\) crește în primele trei covariabile după care descrește încet arătând că, în medie, numărul optim de covariabile din model sunt în jurul lui \(p = 3\). Cu toate acestea se constată că \(R^2_a\) are o variabilitate mare atunci când \(p\) se apropie de \(n-3\), o consecință a factorului \(n-1\).
Arată codul R din exemplul de mai sus
n <- 100
p <- n-3
M <- 200
R2_sim <- matrix(0, nrow = M, ncol = p)
R2a_sim <- matrix(0, nrow = M, ncol = p)
set.seed(23456)
beta <- c(0.5, -0.5, 0.7, rep(0, p-3))
for (j in 1:M){
X <- matrix(rnorm(n*p), nrow = n, ncol = p)
Y <- drop(X %*% beta + rnorm(n, sd = 3))
data_sim <- data.frame(y = Y, x = X)
for (i in 1:p){
s_model <- summary(lm(y ~ X[,1:i], data = data_sim))
R2_sim[j, i] <- s_model$r.squared
R2a_sim[j, i] <- s_model$adj.r.squared
}
}
# mean R2
m_R2 <- colMeans(R2_sim)
# mean R2a
m_R2a <- colMeans(R2a_sim)
# plots
plot(1:p, R2_sim[1,], type = "n",
ylim = c(-1, 1),
xlab = "Numar predictori",
ylab = "",
bty = "n")
for (j in 1:M){
lines(1:p, R2_sim[j,],
col = addTrans("grey", 60))
lines(1:p, R2a_sim[j, ],
col = addTrans("brown2", 60))
}
lines(1:p, m_R2,
col = myblue, lwd = 3)
lines(1:p, m_R2a,
col = myred, lwd = 4)
legend("topleft",
legend = c(latex2exp::TeX("$R^2$"), latex2exp::TeX("$R^2_a$")),
lty = c(1,1),
lwd = c(2, 2),
col = c(myblue, myred),
bty = "n")Următorul rezultat justifică relația care există între coeficienții de determinare în cazul modelelor imbricate.
Propoziția 1.1 Fie \(\symbf Z\in\mathcal{M}_{n,q}(\mathbb{R})\) o matrice de rang \(q\) și \(\symbf X\in\mathcal{M}_{n,p}(\mathbb{R})\) o matrice de rang \(p\), \(p>q\), compusă din cei \(q\) vectori coloană ai lui \(\symbf Z\) și din alți \(p-q\) vectori liniar independenți. Considerăm modelele următoare:
\[\begin{align*} \symbf Y &= \symbf Z\symbf \beta + \symbf\varepsilon,\\ \symbf Y &= \symbf X\symbf \gamma + \symbf\eta \end{align*}\]
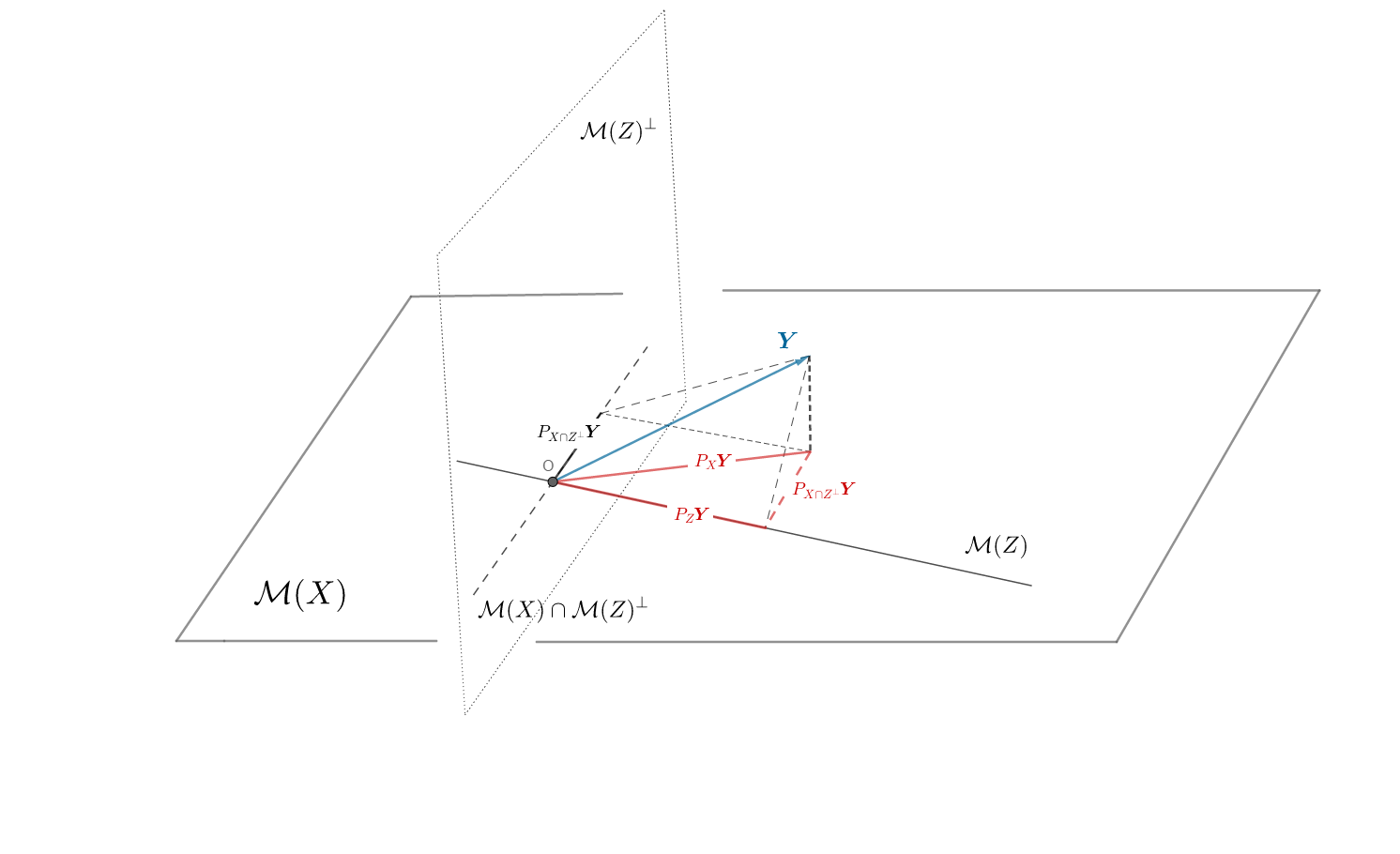
Presupunem, pentru simplitate, că niciun model nu conține termenul liber (constanta). Notăm cu \(P_X\) și \(P_Z\) matricele de proiecție ortogonală pe subspațiile \(\mathcal{M}(X)\) și respectiv \(\mathcal{M}(Z)\), generate de coloanele lui \(\symbf X\) și \(\symbf Z\). De asemenea notăm cu \(P_{X\cap Z^\perp}\) matricea de proiecție ortogonală pe \(\mathcal{M}(X)\cap \mathcal{M}(Z)^\perp\), subspațiul ortogonal al lui \(\mathcal{M}(Z)\) din \(\mathcal{M}(X)\), astfel
\[ \mathbb{R}^n = \mathcal{M}(X) \oplus \mathcal{M}(X)^\perp = \left(\mathcal{M}(Z) \oplus \left(\mathcal{M}(X)\cap \mathcal{M}(Z)^\perp\right) \right) \oplus \mathcal{M}(X)^\perp \]
Atunci:
Are loc relația \(\lVert P_X\symbf Y\rVert^2 = \lVert P_Z\symbf Y\rVert^2 + \lVert P_{X\cap Z^\perp}\symbf Y\rVert^2\).
Între coeficienții de determinare ai celor două modele există inegalitatea \(R_X^2\geq R_Z^2\).
Demonstrație (Propoziția 1.1). Această propoziție face referire la modele imbricate - nested models.
- Deoarece \(\mathcal{M}(\symbf Z)\subset\mathcal{M}(\symbf X)\) și aplicând teorema celor trei perpendiculare1 avem, vezi figura de mai jos,
\[\begin{align*} \hat{\symbf Y}_p &= P_X\symbf Y = (\underbrace{P_Z + P_{Z^\perp}}_{I}) P_X\symbf Y = P_Z P_X \symbf Y + P_{Z^\perp}P_X\symbf Y\\ &= P_X\symbf Y + P_{X\cap Z^\perp} \symbf Y = \hat{\symbf Y}_q + P_{X\cap Z^\perp} \symbf Y \end{align*}\]
și din Teorema lui Pitagora (vezi triunghiul roșu) deducem că
\[ \lVert P_X\symbf Y\rVert^2 = \lVert P_Z\symbf Y\rVert^2 + \lVert P_{X\cap Z^\perp}\symbf Y\rVert^2. \]
- Dacă modelul nu are termenul liber (constanta) atunci coeficientul de determinare este definit prin \(R_X^2 = \frac{\lVert P_{X}\symbf Y\rVert^2}{\lVert\symbf Y\rVert^2}\) prin urmare
\[ R_X^2 = \frac{\lVert P_{X}\symbf Y\rVert^2}{\lVert\symbf Y\rVert^2} = \frac{\lVert P_Z\symbf Y\rVert^2 + \lVert P_{X\cap Z^\perp}\symbf Y\rVert^2}{\lVert\symbf Y\rVert^2} = R_Z^2 + \frac{\lVert P_{X\cap Z^\perp}\symbf Y\rVert^2}{\lVert\symbf Y\rVert^2}\geq R_Z^2. \]
Rezultatul de mai sus se generalizează și în cazul modelelor imbricate care conțin termenul constant și ne arată că modelul mai mare are un coeficient de determinare superior modelului mai mic. Altfel spus, dacă la un model dat adăugăm una sau mai multe variabile explicative ameliorăm variabilitatea explicată de model, chiar dacă variabilele explicative suplimentare nu sunt pertinente! În acest caz este de preferat coeficientul de determinare ajustat.
2 Exerciții
Următorul exercițiu este o aplicație numerică de calcul a coeficienților de determinare în contextul unui model de regresie cu două covariabile.
Exercițiul 2.1 Ne propunem să determinăm evoluția unei variabile răspuns \(y_i\) în funcție de două variabile explicative \(x_i\) și \(z_i\). Fie \(\symbf X = (\mathbf{1}, \symbf x, \symbf z)\) matricea de design.
- Am obținut rezultatele următoare
\[ \symbf X^\intercal\symbf X = \begin{pmatrix}25 & 0 & 0\\ ? & 9.3 & 5.4\\ ? & ? & 12.7\end{pmatrix} \]
- Determinați valorile care lipsesc (?).
- Cât este \(n\) ?
- Calculați coeficientul de corelație dintre \(\symbf x\) și \(\symbf z\).
- Modelul de regresie liniară a lui \(\symbf Y\) în funcție de \(\mathbf{1}, \symbf x, \symbf z\) este
\[ \symbf Y = -1.6\symbf 1 + 0.61 \symbf x + 0.46 \symbf z + \hat{\symbf \varepsilon}, \quad \lVert\hat{\symbf \varepsilon}\rVert^2 = 0.3 \]
- Determinați \(\bar{\symbf y}\).
- Calculați suma abaterilor pătratice de regresie \(SS_{reg}\), suma abaterilor pătratice totale \(SS_T\), coeficientul de determinare și coeficientul de determinare ajustat.
Soluție (Exercițiul 2.1). Avem
- Pentru a determina cele trei valori care lipsesc să notăm că matricea \(\symbf X^\intercal\symbf X\) este simetrică, prin urmare \(\symbf X^\intercal\symbf X = \left(\symbf X^\intercal\symbf X\right)^\intercal\) de unde
\[ \begin{pmatrix}25 & 0 & 0\\ ? & 9.3 & 5.4\\ ? & ? & 12.7\end{pmatrix} = \begin{pmatrix}25 & ? & ?\\ 0 & 9.3 & ?\\ 0 & 5.4 & 12.7\end{pmatrix} \]
ceea ce conduce la valorile \(0, 0, 5.4\).
- Pentru a determina valoarea lui \(n\) să observăm că
\[ \symbf X^\intercal\symbf X = \begin{pmatrix}\mathbf{1}^\intercal \\ \symbf x^\intercal\\ \symbf z^\intercal\end{pmatrix}\begin{pmatrix}\mathbf{1} & \symbf x & \symbf z\end{pmatrix} = \begin{pmatrix}\mathbf{1}^\intercal \mathbf{1} & \mathbf{1}^\intercal\symbf x & \mathbf{1}^\intercal\symbf z \\ \symbf x^\intercal\mathbf{1} & \symbf x^\intercal\symbf x & \symbf x^\intercal\symbf z\\ \symbf z^\intercal\mathbf{1} & \symbf z^\intercal\symbf x & \symbf z^\intercal\symbf z\end{pmatrix} = \begin{pmatrix}n & n\bar x & n\bar z \\ n\bar x & \symbf x^\intercal\symbf x & \symbf x^\intercal\symbf z\\ n\bar z & \symbf z^\intercal\symbf x & \symbf z^\intercal\symbf z\end{pmatrix} \]
ceea ce arată că \(n = \left(\symbf X^\intercal\symbf X\right)_{1,1} = 25\).
- Coeficientul de corelație dintre \(\symbf x\) și \(\symbf z\) este dat de
\[ r_{\symbf x,\symbf z} = \frac{\sum_{i=1}^{n}(x_i - \bar x)(z_i - \bar z)}{\sqrt{\sum_{i = 1}^{n}(x_i - \bar x)^2}\sqrt{\sum_{i = 1}^{n}(z_i - \bar z)^2}} \]
și cum, din punctul anterior \(\bar x = \frac{\left(\symbf X^\intercal\symbf X\right)_{1,2}}{n} = 0\) și \(\bar z = \frac{\left(\symbf X^\intercal\symbf X\right)_{1,3}}{n} = 0\) rezultă că
\[ \begin{aligned} r_{\symbf x,\symbf z} &= \frac{\sum_{i=1}^{n}x_iz_i}{\sqrt{\sum_{i = 1}^{n}x_i^2}\sqrt{\sum_{i = 1}^{n}z_i^2}} = \frac{\symbf x^\intercal\symbf z}{\sqrt{\symbf x^\intercal\symbf x}\sqrt{\symbf z^\intercal\symbf z}} \\ &= \frac{\left(\symbf X^\intercal\symbf X\right)_{2,3}}{\sqrt{\left(\symbf X^\intercal\symbf X\right)_{2,2}}\sqrt{\left(\symbf X^\intercal\symbf X\right)_{3,3}}} = \frac{5.4}{\sqrt{9.3}\sqrt{12.7}}\approx 0.5 \end{aligned} \]
- Avem modelul
\[ y_i = -1.6 + 0.61 x_i + 0.46 z_i + \hat{\varepsilon}_i \]
care prin sumare devine
\[ \bar y = -1.6 + 0.61 \bar x + 0.46 \bar z + \frac{1}{n}\sum_{i=1}^{n}\hat{\varepsilon}_i. \]
Cum \(\mathbf{1}\) aparține modelului, deci \(\mathbf{1}\in\mathcal{M}(\symbf X)\) și ținând cont de faptul că \(\hat{\symbf \varepsilon}\in\mathcal{M}(X)^\perp\) deducem că \(\langle\mathbf{1}, \hat{\symbf \varepsilon}\rangle = 0\) sau \(\frac{1}{n}\sum_{i=1}^{n}\hat{\varepsilon}_i = 0\). Astfel
\[ \bar y = -1.6 + 0.61 \underbrace{\bar x}_{=0} + 0.46 \underbrace{\bar z}_{= 0} + \underbrace{\frac{1}{n}\sum_{i=1}^{n}\hat{\varepsilon}_i}_{=0} = -1.6. \]
- Avem că suma abaterilor pătratice explicate de model este dată de
\[ SS_{reg} = \lVert\hat{\symbf Y} - \bar y\mathbf{1}\rVert^2 = \sum_{i=1}^{n}(\hat{y}_i - \bar y)^2 = \sum_{i=1}^{n}(0.61 x_i + 0.46 z_i)^2 \]
adică
\[ \begin{aligned} SS_{reg} &= \lVert\hat{\symbf Y} - \bar y\mathbf{1}\rVert^2 = 0.61^2\sum_{i=1}^{n}x_i^2 + 2\times 0.61\times 0.46\sum_{i=1}^{n}x_iz_i + 0.46^2\sum_{i=1}^{n}z_i^2\\ &= 0.61^2\left(\symbf X^\intercal\symbf X\right)_{2,2} + 2\times 0.61\times 0.46\left(\symbf X^\intercal\symbf X\right)_{2,3} + 0.46^2\left(\symbf X^\intercal\symbf X\right)_{3,3} = 9.18. \end{aligned} \]
Suma abaterilor pătratice totale se determină folosind formula de descompunere a varianței:
\[ \underbrace{SS_T}_{\lVert\symbf Y - \bar y\mathbf{1}\rVert^2} = \underbrace{SS_{reg}}_{\lVert\hat{\symbf Y} - \bar y\mathbf{1}\rVert^2} + \underbrace{RSS}_{\lVert\hat{\symbf \varepsilon}\rVert^2} = 9.18 + 0.3 = 9.48. \]
Coeficientul de determinare \(R^2\) este
\[ R^2 = \frac{SS_{reg}}{SS_T} = \frac{9.18}{9.48}\approx 0.968 \]
ceea ce arată că aproximativ \(97\%\) din variabilitatea datelor este explicată de modelul de regresie iar coeficientul de determinare ajustat este
\[ \begin{aligned} R_1^2 &= 1 - \frac{n-1}{n-(p+1)}\frac{\lVert\hat{\symbf\varepsilon}\rVert^2}{\lVert \symbf Y - \bar{\symbf y}\mathbf{1}\rVert^2} \\ &= 1 - \frac{n-1}{n-(p+1)}\left(1 - R^2\right) = 1 - \frac{25 - 1}{25 - (2 + 1)}(1-0.968)\approx 0.965 \end{aligned} \]
ceea ce verifică relația generală \(R_a^2<R^2\).
Exercițiul 2.2 (Model cu două variabile explicative) Ne propunem să determinăm evoluția unei variabile răspuns \(y_i\) în funcție de două variabile explicative \(x_i\) și \(z_i\). Fie \(\boldsymbol X = (\mathbf{1}, \boldsymbol x, \boldsymbol z)\) matricea de design.
- Am obținut rezultatele următoare
\[ \boldsymbol X^\intercal\boldsymbol X = \begin{pmatrix}25 & 0 & 0\\ ? & 9.3 & 5.4\\ ? & ? & 12.7\end{pmatrix} \]
- Determinați valorile care lipsesc (?).
- Cât este \(n\) ?
- Calculați coeficientul de corelație dintre \(\boldsymbol x\) și \(\boldsymbol z\).
- Modelul de regresie liniară a lui \(\boldsymbol Y\) în funcție de \(\mathbf{1}, \boldsymbol x, \boldsymbol z\) este
\[ \boldsymbol Y = -1.6\boldsymbol 1 + 0.61 \boldsymbol x + 0.46 \boldsymbol z + \hat{\boldsymbol \varepsilon}, \quad \lVert\hat{\boldsymbol \varepsilon}\rVert^2 = 0.3 \]
- Determinați \(\bar{\boldsymbol y}\).
- Calculați suma abaterilor pătratice de regresie \(SS_{reg}\), suma abaterilor pătratice totale \(SS_T\), coeficientul de determinare și coeficientul de determinare ajustat.
Note de subsol
Teorema celor trei perpendiculare spune că dacă \(\symbf V\) și \(\symbf W\) sunt două subspații vectoriale astfel încât \(\symbf V\subset \symbf W\) atunci \(P_V P_W = P_W P_V = P_V\).↩︎