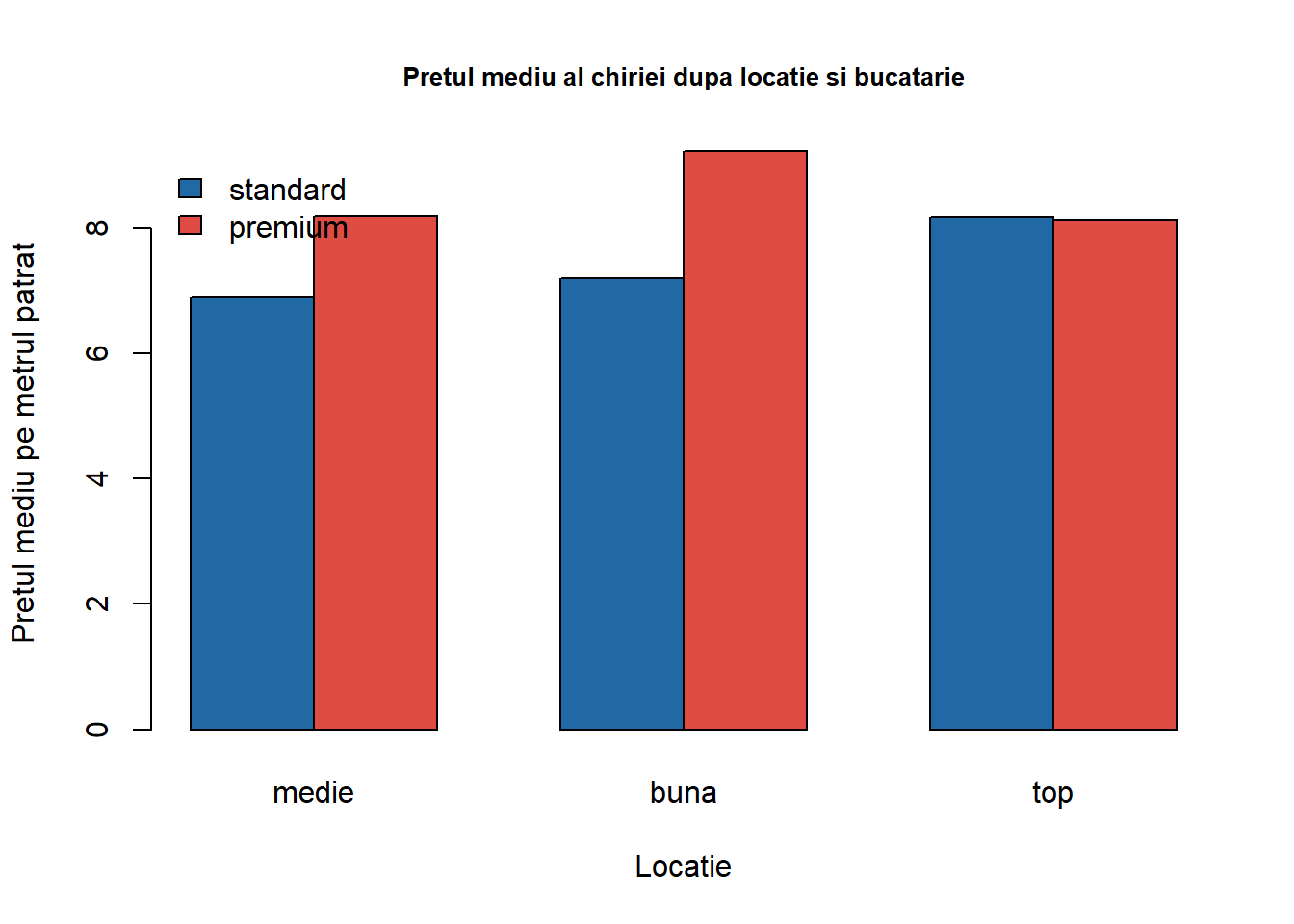Diagrama cu batoane sau bare (barplot) este o metodă grafică folosită cu precădere atunci când datele sunt discrete (date calitative). O diagramă de tip barplot trasează bare verticale sau orizontale, în general separate de un spațiu alb, pentru a evidenția frecvențele de apariție a observațiilor după categoriile corespunzătoare.
Să presupunem că \(X\) este o variabilă aleatoare discretă cu funcția de masă dată de \(p(x)=\mathbb{P}(X = x)\) și \(X_1, X_2, \ldots, X_n\) un eșantion de volum \(n\) din populația \(p(x)\). Dacă \(X\) ia un număr finit de valori, \(X\in\mathcal{A}\) cu \(\mathcal{A} = \{a_1, \ldots, a_m\}\), atunci un estimator nedeplasat și consistent al lui \(p(a_j)\) este
\[
\hat{p}(\tilde{a}_{m+1}) = \frac{1}{n}\sum_{i = 1}^{n}\mathbf{1}_{\left\{X_i \geq a_{m+1}\right\}}.
\] În practică, alegerea lui \(m\) se face așa încât \(\hat{p}(a_m)\geq 2\hat{p}(\tilde{a}_{m+1})\). O diagramă cu bare este o ilustrare a lui \(a_j\) versus \(\hat{p}(a_j)\).
În R, diagrama cu bare se ilustrează prin intermediul funcției barplot().
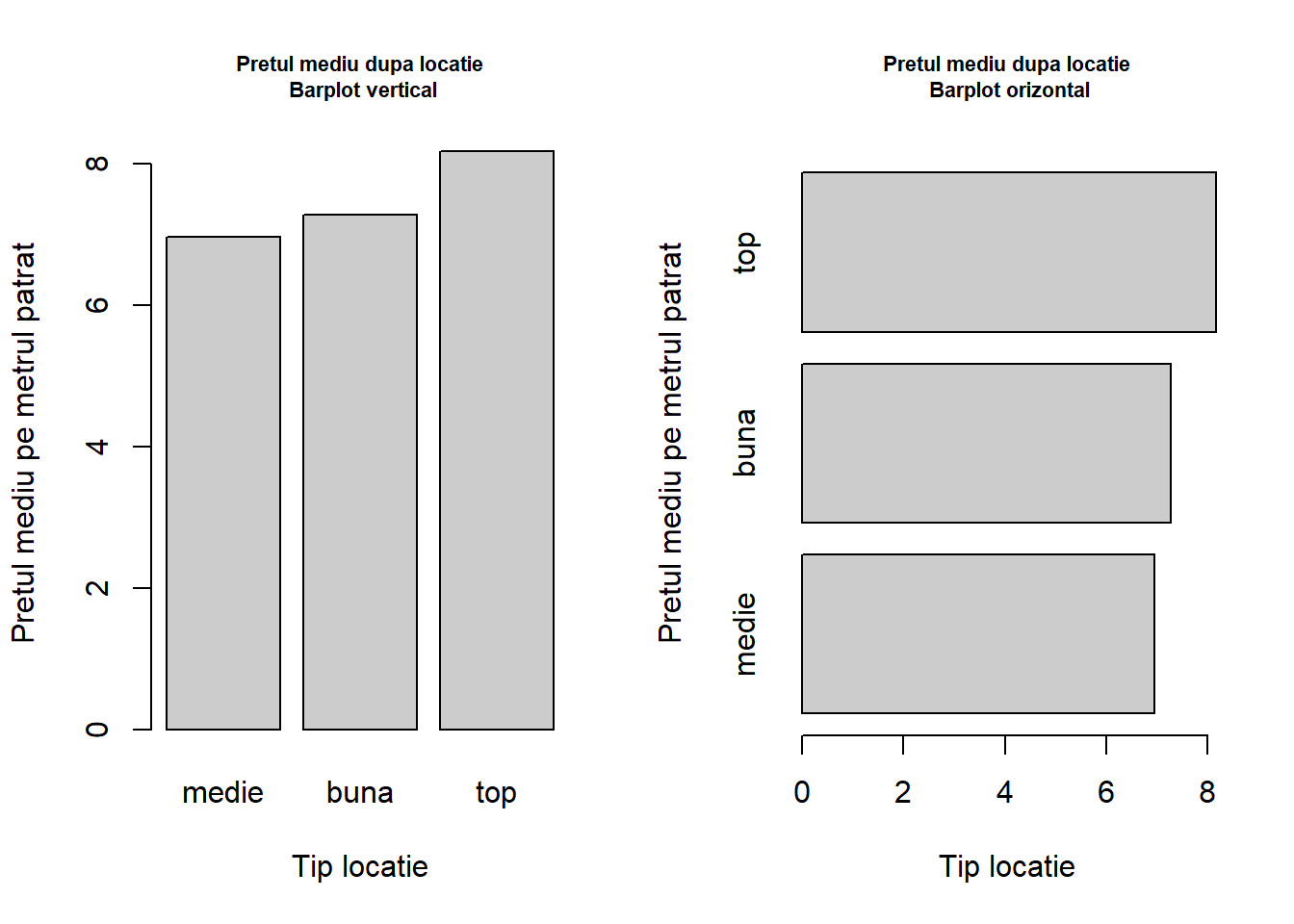
Exemplul 1.1 (Prețul chiriilor în Munchen) Atunci când facem referire la setul de date privind indicii prețului chiriei în orașul Munchen, și ne interesăm la relația dintre prețul lunar mediu net pe \(m^2\) și locația avem următorul cod R și următoarea diagramă cu bare.
munich <-read.table("dataIn/rent99.raw", header =TRUE)munich <- munich %>%mutate(location_lab =case_when(location ==1~"medie", location ==2~"buna", location ==3~"top",TRUE~as.character(location)))munich$location_lab <-factor(munich$location_lab, levels =c("medie", "buna", "top"))par(mfrow =c(1, 2))rent_munich <-aggregate(rentsqm ~ location_lab, data = munich, FUN = mean)barplot(height = rent_munich$rentsqm,names.arg = rent_munich$location_lab,xlab ="Tip locatie",ylab ="Pretul mediu pe metrul patrat",main ="Pretul mediu dupa locatie\n Barplot vertical",col ="grey80", cex.main =0.7)barplot(height = rent_munich$rentsqm,names.arg = rent_munich$location_lab,xlab ="Tip locatie",ylab ="Pretul mediu pe metrul patrat",main ="Pretul mediu dupa locatie\n Barplot orizontal",horiz =TRUE,col ="grey80", cex.main =0.7)
Figura 1.1: Prețul mediu pe metrul pătrat în funcție de tipul locației apartamentului: diagramă cu bare verticală și orizontală.
Dacă în plus vrem să afișăm prețul mediu al chiriei pe \(m^2\) în funcție de tipul de locație al apartamentului și calitatea bucătăriei atunci avem următorul cod R:
munich <- munich %>%mutate(kitchen_lab =case_when(kitchen ==0~"standard", kitchen ==1~"premium", TRUE~as.character(kitchen)))munich$kitchen_lab <-factor(munich$kitchen_lab, levels =c("standard", "premium"))# calculam pretul mediu dupa locatie si bucatarierent_location_kitchen <-aggregate(munich$rentsqm, by =list(munich$location_lab, munich$kitchen_lab), FUN = mean) # transformam rezultatul sub forma de matricerent_location_kitchen <-as.matrix(rent_location_kitchen)# aducem la forma necesara pentru barplotrent_lk <-matrix(as.numeric(rent_location_kitchen[,3]), nrow =3)colnames(rent_lk) <-unique(rent_location_kitchen[,2])rownames(rent_lk) <-unique(rent_location_kitchen[, 1])rent_lk <-t(rent_lk)barplot(rent_lk, beside =TRUE,legend.text =TRUE, args.legend =list(x ="topleft", bty ="n"),col =c(myblue, myred),main ="Pretul mediu al chiriei dupa locatie si bucatarie",cex.main =0.8,xlab ="Locatie",ylab ="Pretul mediu pe metrul patrat")
Figura 1.2: Prețul mediu pe metrul pătrat în funcție de tipul locației apartamentului și tipul de bucătărie.
1.2 Histograma
Histograma este un exemplu de metodă neparametrică de estimare a densității de probabilitate. Fie \(X_1, X_2, \ldots, X_n\) un eșantion de volum \(n\) dintr-o populație cu densitate de probabilitate \(f\). Fără a restrânge generalitatea putem să presupunem că \(X_i\in[0,1]\) (în caz contrar putem scala observațiile la acest interval).
Fie \(m\) un număr natural și să considerăm diviziunea intervalului \([0,1]\) (fiecare subinterval din diviziune se numește bin):
Notăm cu \(h = \frac{1}{m}\) lungimea intervalelor din diviziune (a bin-urilor), \(p_j = \mathbb{P}(X_i\in B_j) = \int_{B_j}f(t)\,dt\) probabilitatea ca o observație să se afle în subintervalul \(B_j\) și \(\hat{p}_j = \frac{1}{n}\sum_{i = 1}^{n}\mathbf{1}_{\left\{X_i \in B_j\right\}}\) numărul de observații, din cele \(n\), care se află în intervalul \(B_j\). Observăm că \(\hat{p}_j\) este un estimator nedeplasat și consistent pentru \(p_j\).
Alegerea numărului de bin-uri și a mărimii acestora nu este o problemă trivială. De exemplu, D. Scott propune o variantă de alegere a lui \(m\) în articolul (Scott 1979). Un rezultat similar, dar mai robust, a fost obținut de D. Freedman și P. Diaconis în (Freedman and Diaconis 1981). Câteva dintre metodele de alegere a mărimii bin-ului sunt prezentate în următoarea pagină de Wikipedia.
În R, funcția hist() este folosită pentru trasarea unei histograme. Această funcție utilizează ca metodă predefinită de alegere a mărimii bin-urilor, metoda lui Sturges (a se vedea articolul (Sturges 1926)), i.e. \(m = \lceil \log_2(n)\rceil + 1\).
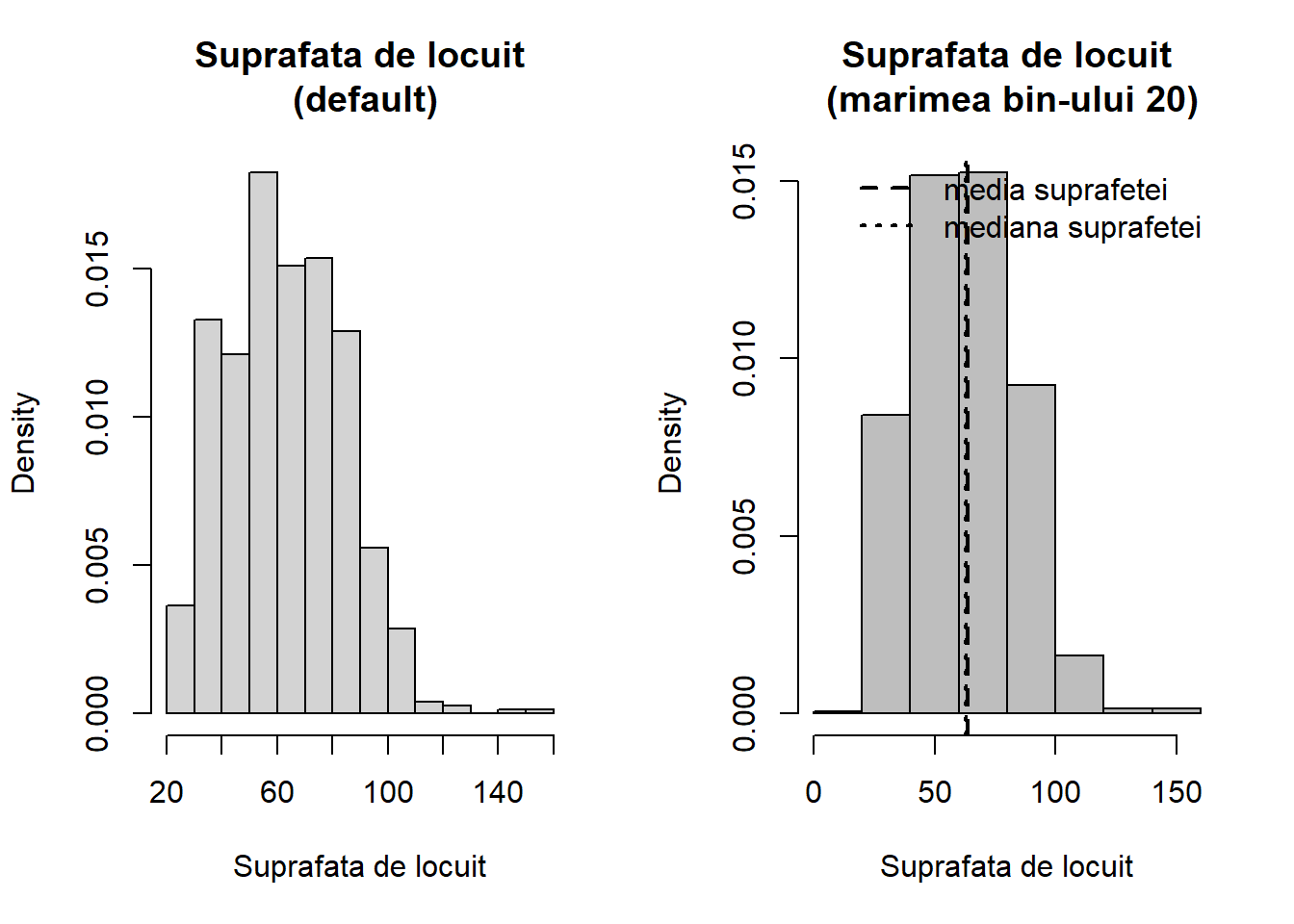
Exemplul 1.2 (Prețul chiriilor în Munchen) Dacă ne raportăm la setul de date munich și dorim să investigăm cu ajutorul unei histograme cum este repartizată suprafața de locuit a apartamentelor construite după anul 1966 și care se află într-o locație medie avem următorul cod R:
munich_sub <- munich %>%filter(yearc >=1966, location_lab =="medie")par(mfrow =c(1,2))hist(munich_sub$area, freq =FALSE,main ="Suprafata de locuit\n (default)", xlab="Suprafata de locuit")hist(munich_sub$area, freq =FALSE,breaks=seq(0,175,20),col="gray",main="Suprafata de locuit\n (marimea bin-ului 20)",xlab="Suprafata de locuit")abline(v=c(mean(munich_sub$area), median(munich_sub$area)), lty=c(2,3), lwd=2)legend("topright", legend=c("media suprafetei","mediana suprafetei"),lty=c(2,3), lwd=2,bty ="n")
Figura 1.3: Repartiția variabilei area.
Exercițiul 1.1 Să presupunem că în fișierul studFMI.txt am stocat date privind sexul (f/h), înălțimea (în cm) și greutatea (în kg) a studenților de master de la Facultatea de Matematică și Informatică. Vrem să investigăm, trasând pe același grafic, cum este repartizată înălțimea și respectiv greutatea studenților în funcție de sex.
sex height weight
1 h 168 69
2 h 177 73
3 f 164 53
4 f 166 57
5 h 165 60
6 f 150 42
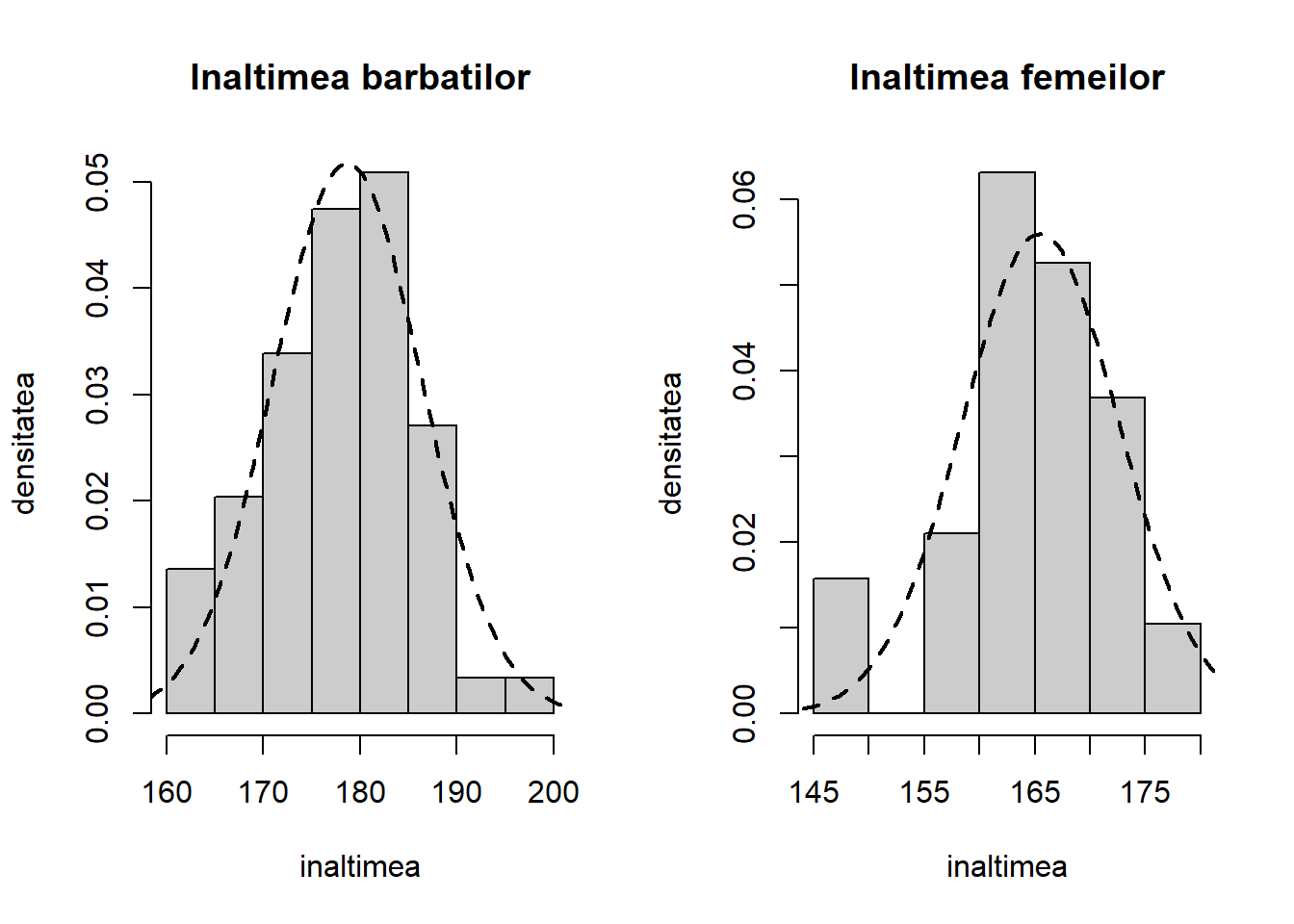
Separăm înălțimea (greutatea este exercițiu!) bărbaților și a femeilor:
# h vine de la hommes iar f de la femmeshm <- stud$height[stud$sex =="h"]hf <- stud$height[stud$sex =="f"]par(mfrow =c(1,2))hist(hm, freq =FALSE, col =grey(0.8),main ="Inaltimea barbatilor", xlab ="inaltimea",ylab ="densitatea")tm =seq(min(hm)-5, max(hm)+5, length.out =100)lines(tm, dnorm(tm, mean(hm), sd(hm)), lty =2, lwd =2)hist(hf, freq =FALSE, col =grey(0.8),main ="Inaltimea femeilor", xlab ="inaltimea",ylab ="densitatea")tf =seq(min(hf)-5, max(hf)+5, length.out =100)lines(tf, dnorm(tf, mean(hf), sd(hf)), lty =2, lwd =2)
Figura 1.4: Repartiția înălțimii studenților de sex masculin și feminin în setul de date.
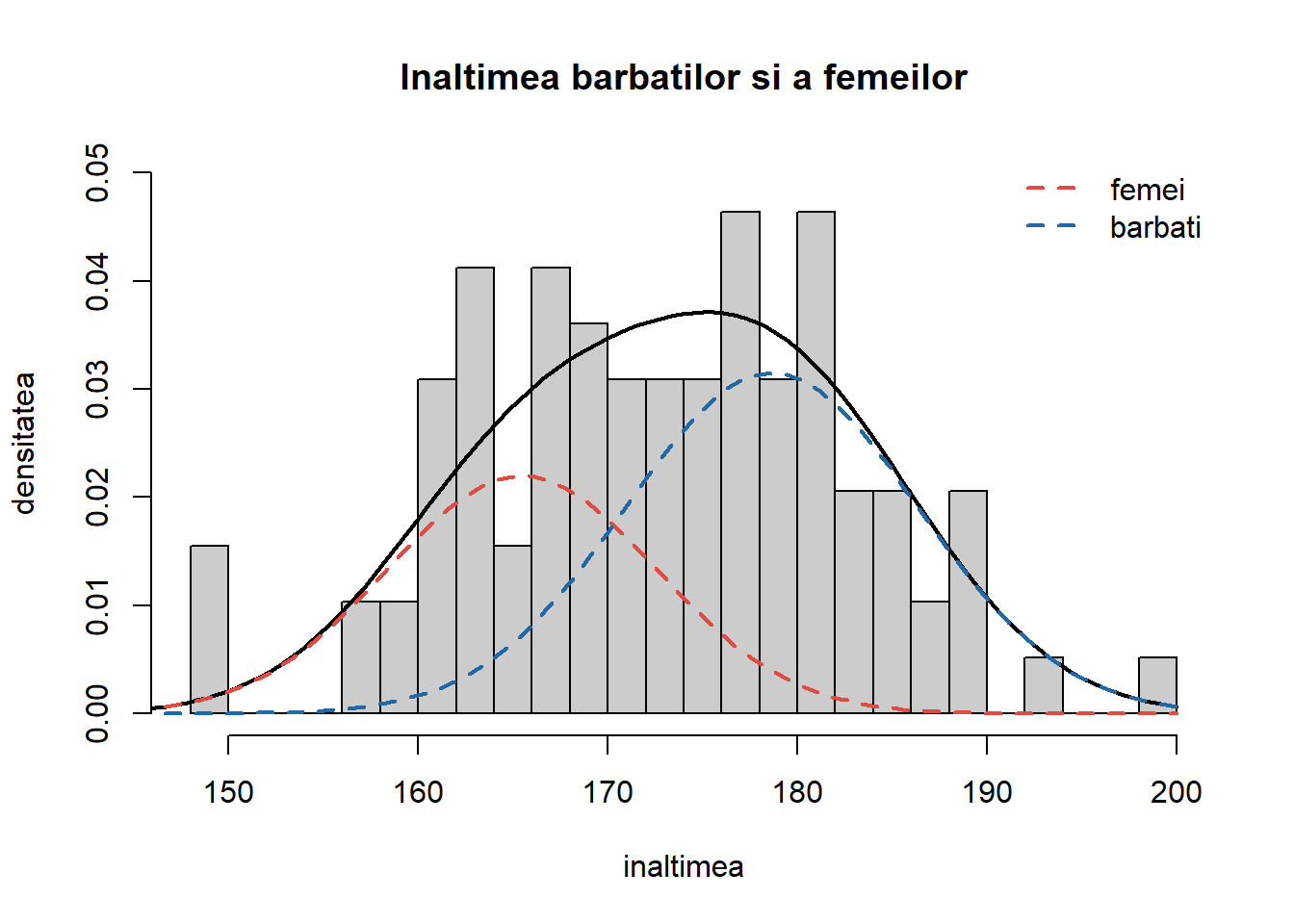
Reprezentăm repartiția înălțimilor luate împreună și evidențiem mixtura celor două repartiții după sex:
height <- stud$heighthist(height, proba =TRUE, breaks=25, col =grey(0.8), main ="Inaltimea barbatilor si a femeilor",xlab ="inaltimea",ylab ="densitatea",ylim =c(0, 0.05))t <-seq(145,200,length=100)x1 <-dnorm(t,mean(hf),sd(hf))x2 <-dnorm(t,mean(hm),sd(hm))# proportia de femei (din nr de studenti)pf <-length(hf)/length(height)# mixtura dintre rep inaltimilor f si hx3 <- pf*x1 + (1-pf)*x2lines(t, x3, lwd =2)lines(t, pf*x1, col = myred, lty =2, lwd =2)lines(t, (1-pf)*x2, col = myblue, lty =2, lwd =2)legend("topright", c("femei","barbati"), col =c(myred,myblue), lty =2, lwd =2, bty ="n")
Figura 1.5: Repartiția studenților după înălțime și evidențierea mixturii celor două repartiții după sex.
1.3 Boxplot-ul
Una dintre metodele grafice des întâlnite în vizualizarea datelor (cantitative) unidimensionale este boxplot-ul (eng. box and whisker plot - cutia cu mustăți). Această metodă grafică descriptivă este folosită în principal pentru a investiga atât forma repartiției (simetrică sau asimetrică) datelor cât și variabilitatea acestora precum și pentru detectarea și ilustrarea schimbărilor de locație și variație între diferitele grupuri de date.
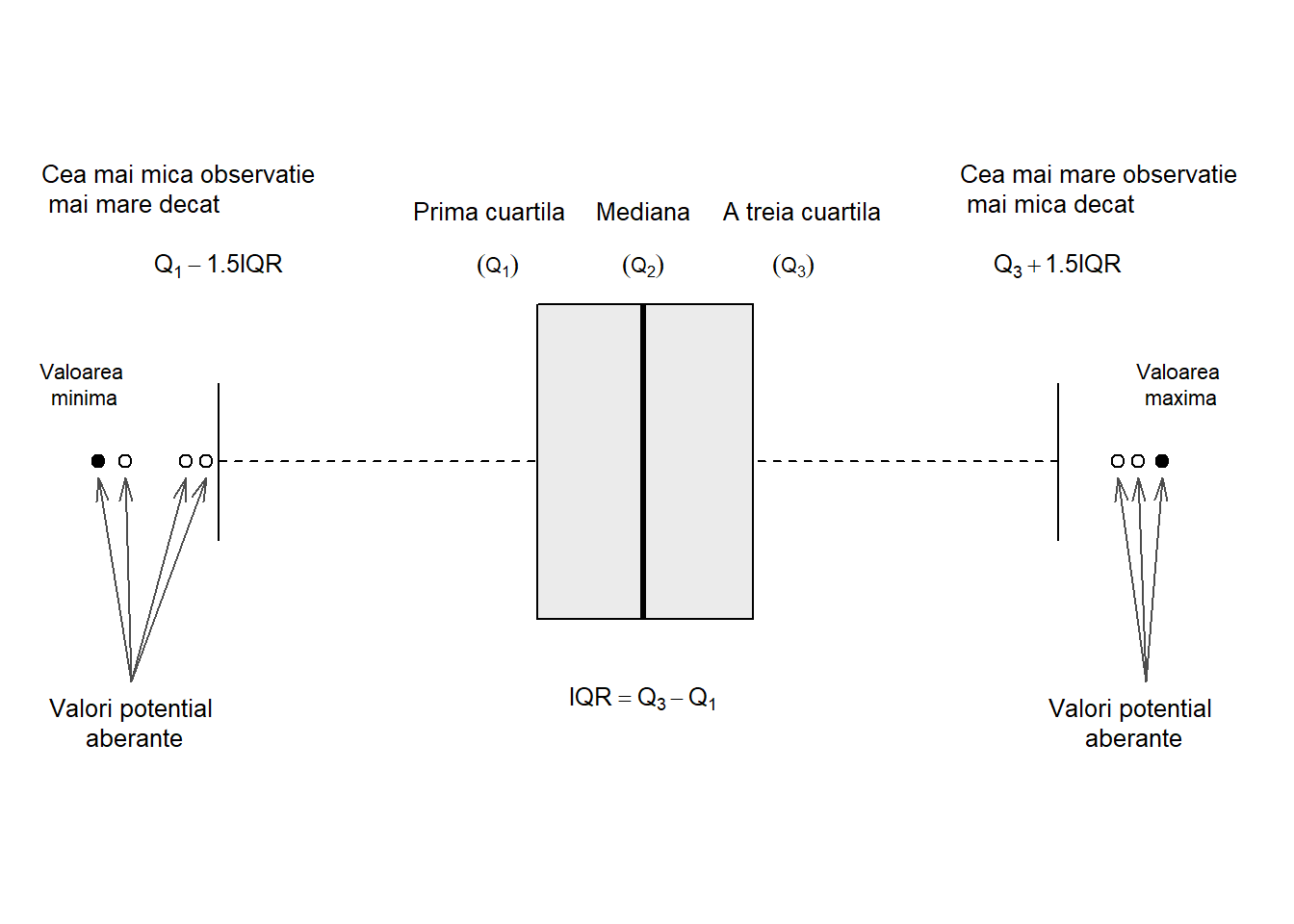
După cum putem vedea și în Figura 1.6 de mai jos, cutia este definită, de la stânga la dreapta (sau de jos în sus în funcție de cum este reprezentat boxplot-ul: orizontal sau vertical), de prima cuartilă \(Q_1\) și de a treia curatilă \(Q_3\) ceea ce înseamnă că \(50\%\) dintre observații se află în interiorul cutiei. Linia din interiorul cutiei este determinată de mediană sau a doua cuartilă \(Q_2\).
Mustățile care pornesc de o parte și de alta a cutiei sunt determinate astfel (vom folosi convenția folosită de John Tukey în (J. 1977, pag. 40-56)): mustața din stânga este determinată de cea mai mică observație mai mare decât \(Q_1-1.5 IQR\) iar cea din dreapta de cea mai mare observație din setul de date mai mică decât \(Q_3+1.5IQR\), unde \(IQR = Q_3-Q_1\) este distanța dintre cuartile (interquartile range).
Valorile observațiilor din setul de date care sunt sau prea mici sau prea mari se numesc valori aberante (outliers) și conform lui Tukey sunt definite astfel: valori strict aberante care se află la \(3IQR\) deasupra celei de-a treia curtilă \(Q_3\) sau la \(3IQR\) sub prima cuartilă (\(x<Q_1-3IQR\) sau \(x>Q_3+3IQR\)) și valori potențial aberante care se află la \(1.5IQR\) deasupra celei de-a treia curtilă \(Q_3\) sau la \(1.5IQR\) sub prima cuartilă (\(x<Q_1-1.5IQR\) sau \(x>Q_3+1.5IQR\)).
Figura 1.6: Diagramă ilustrativă a unui boxplot.
În R metoda grafică boxplot se poate trasa cu ajutorul funcției boxplot(). Aceasta primește ca argumente sau un vector de observații numerice x, atunci când dorim să ilustrăm repartiția unei variabile, sau o formulă de tipul y~grup, unde y este un vector numeric care va fi împărțit în funcție de variabila discretă grup, atunci când vrem să comparăm aceeași variabilă numerică în funcție de una discretă (calitativă). Pentru mai multe informații puteți consulta documentația funcției, i.e. ?boxplot.
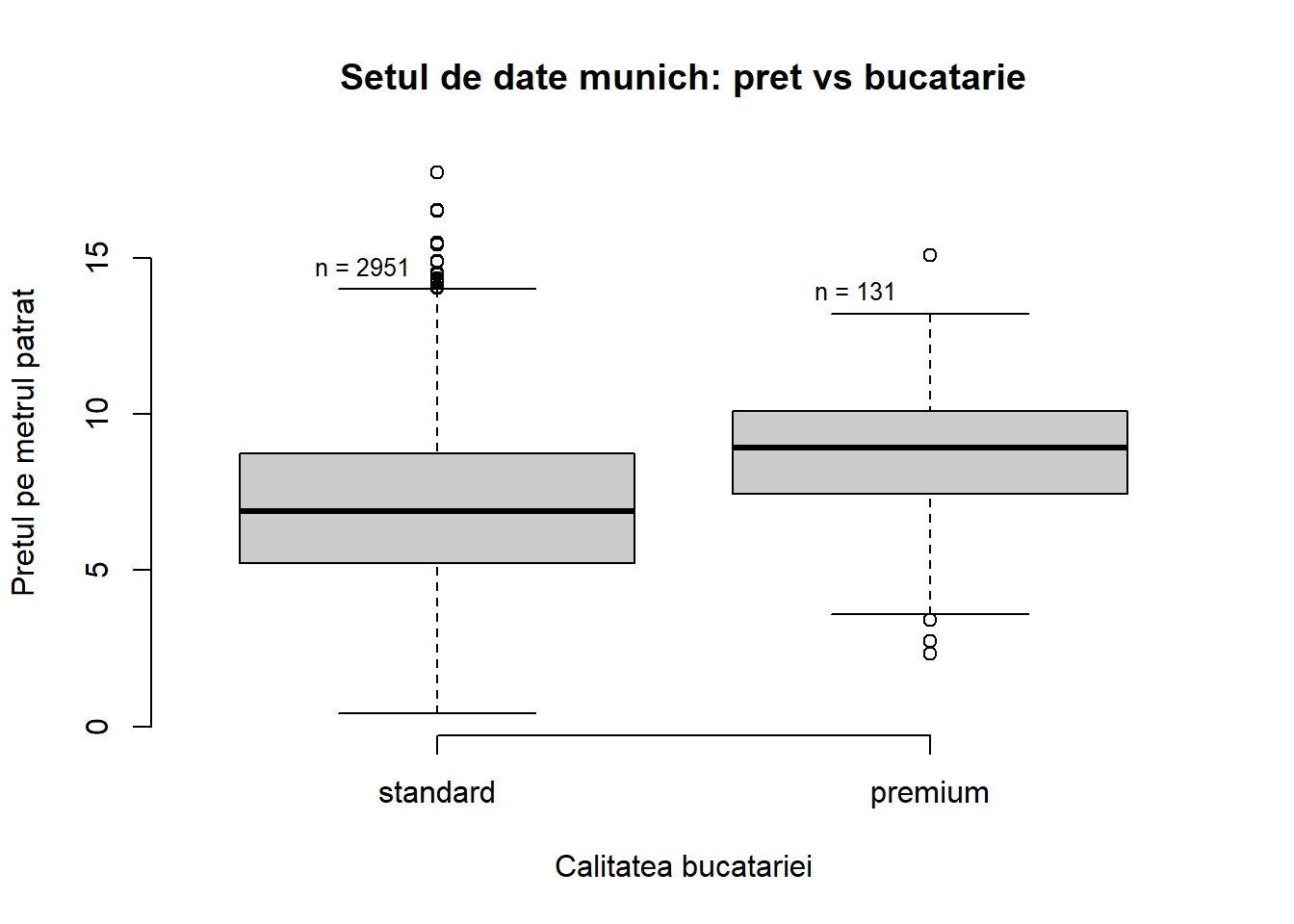
Exemplul 1.3 (Prețul chiriilor în Munchen) Raportându-ne la setul de date referitor la prețul chiriilor în Munchen vrem să investigăm modul în care variază prețul median net pe metrul pătrat al apartamentelor în raport cu tipul de bucătărie. Avem următorul cod R:
par(bty ="n")bp <-boxplot(munich$rentsqm ~ munich$kitchen_lab,xlab ="Calitatea bucatariei", ylab ="Pretul pe metrul patrat",col ="grey80",main ="Setul de date munich: pret vs bucatarie")text(c(1:length(unique(munich$kitchen_lab))) -0.15, bp$stats[nrow(bp$stats) , ] +0.75 , paste("n = ", table(munich$kitchen_lab),sep=""),cex =0.8)
Figura 1.7: Prețul median net pe metrul pătrat în funcție de calitatea bucătăriei.
Observăm că valoarea mediană a prețului lunar net al chiriei crește odată cu calitatea bucătăriei apartamentului.
1.4 Graficul de tip cuantilă-cuantilă
Graficul de tip cuantilă-cuantilă (quantile-quantile plot sau q-q plot pe scurt) este o metodă grafică introdusă în (Wilk and Gnanadesikan 1968) și folosită pentru a determina dacă două eșantioane provin din populații cu repartiție comună. Un q-q plot ilustrează grafic cuantilele empirice ale primului eșantion față de cuantilele empirice (sau teoretice) ale celui de-al doilea eșantion.
Fiind date două eșantioane, \(X_1,X_2,\ldots,X_n\sim F\) și respectiv \(Y_1, Y_2, \ldots, Y_m\sim G\), fie \(\hat{x}_p(n) = \hat{F}_n^{-1}(p)\) și \(\hat{y}_p(m) = \hat{G}_m^{-1}(p)\) cuantilele empirice de ordin \(p\) asociate celor două eșantioane. Metoda q-q plot implică trasarea pe același grafic al punctelor de coordonate \((\hat{x}_p(n), \hat{y}_p(m))\) pentru diverse valori ale lui \(p\in(0,1)\). După cum am văzut la cursul de statistică, cunatila empirică de ordin \(p\) coincide cu una dintre statisticile de ordine \(\hat{x}_p = X_{(i)} \iff \hat{x}_p = X_{(\lceil np \rceil)}\) (deci \(X_{(k)}\) este cuantila de ordin \(\frac{k}{n}\)) și prin urmare putem considera că
\[
p\in \left\{\begin{array}{ll}
\left\{\frac{i}{n}\,|\,1\leq i\leq n\right\}, & n\leq m\\
\left\{\frac{i}{m}\,|\,1\leq i\leq m\right\}, & n\geq m.
\end{array}\right.
\] În practică, pentru a avea \(p<1\) vom considera că \(X_{(k)}\) este cuantila de ordin \(\frac{k}{n+1}\) (unii autori consideră că \(X_{(k)}\) este cuantila de ordin \(\frac{k-0.5}{n}\) sau încă de ordin \(\frac{k-3/8}{n+1/4}\)), astfel
În R putem folosi funcția qqplot() pentru a trasa graficul cuantilă-cuantilă (tastați ?qqplot pentru a vedea documentația acestei funcții).
Exercițiul 1.2 Construiți în R o funcție qqgraf() care să traseze graficul cuantilă-cuantilă pentru două eșantioane.
Soluție. Următorul cod R implementează această funcție:
qqgraf <-function(x, y, line =TRUE,type ="1",xlab =deparse(substitute(x)), ylab =deparse(substitute(y)), ...){ sx <-sort(x) sy <-sort(y) lenx <-length(sx) leny <-length(sy) len <-ifelse(lenx>leny, leny, lenx)if (type =="1"){ p =1:len/(len+1) }elseif(type =="2"){ p = (1:len -0.5)/len }else{ p = (1:len -3/8)/(len+1/4) } qx <-quantile(x, probs = p) qy <-quantile(y, probs = p)plot(qx, qy, pch =21, bg =grey(0.8, 0.8),bty ="n", xlab = xlab, ylab = ylab, ...)# abline(a = mean(y)-mean(x), b = sd(y)/sd(x))if (line ==TRUE)abline(a =0, b =1, lwd =2, lty =2, col = myred)}
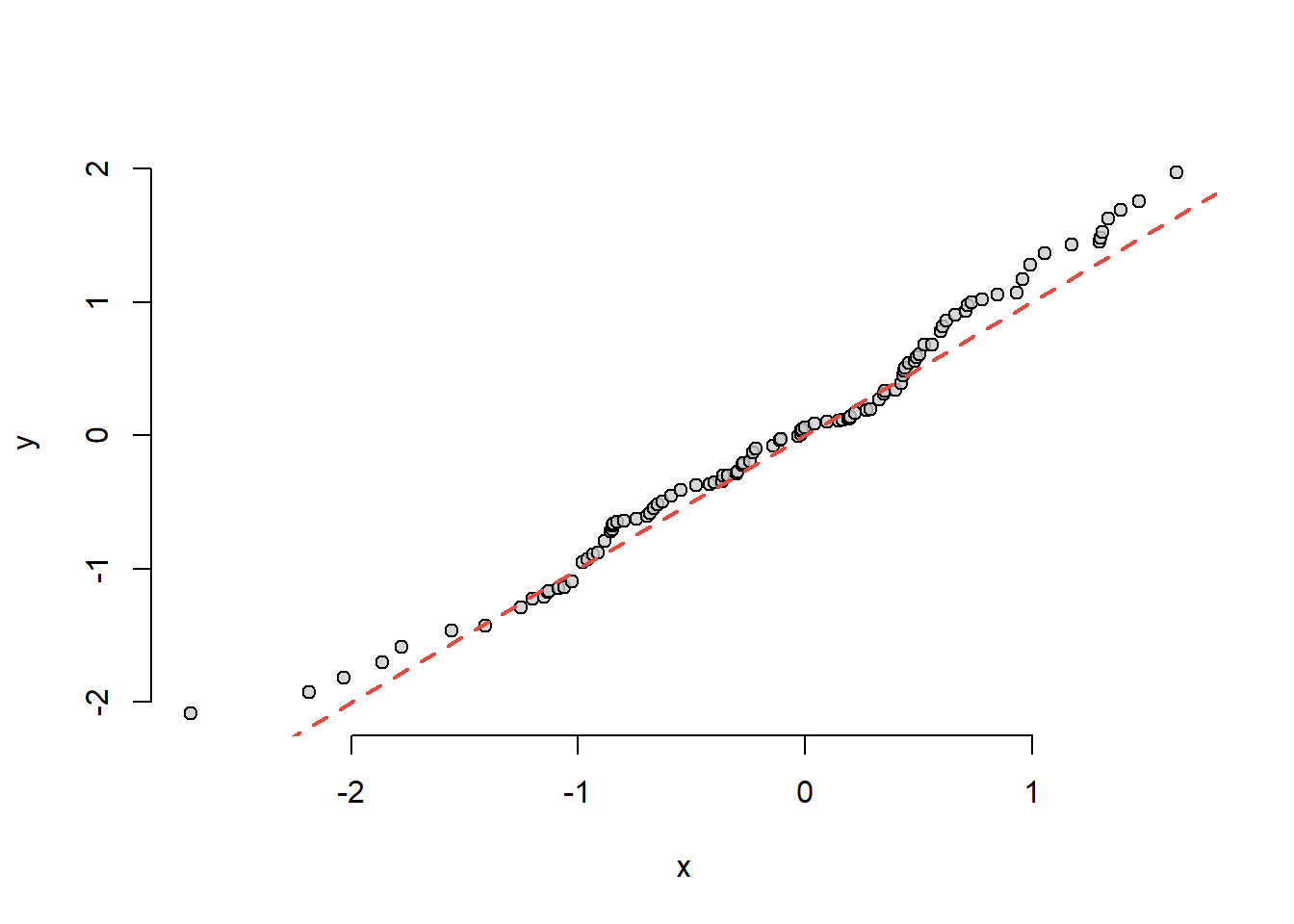
Observăm că dacă cele două eșantioane ar proveni de la aceeași populație (\(F = G\)) atunci punctele ar fi aliniate aproximativ pe o dreaptă (prima bisectoare \(y=x\)).
x <-rnorm(100)y <-rnorm(150)qqgraf(x, y)
Figura 1.8: Ilustrarea graficului cuantilă-cuantilă pentru două eșantioane provenite dintr-o populație normală.
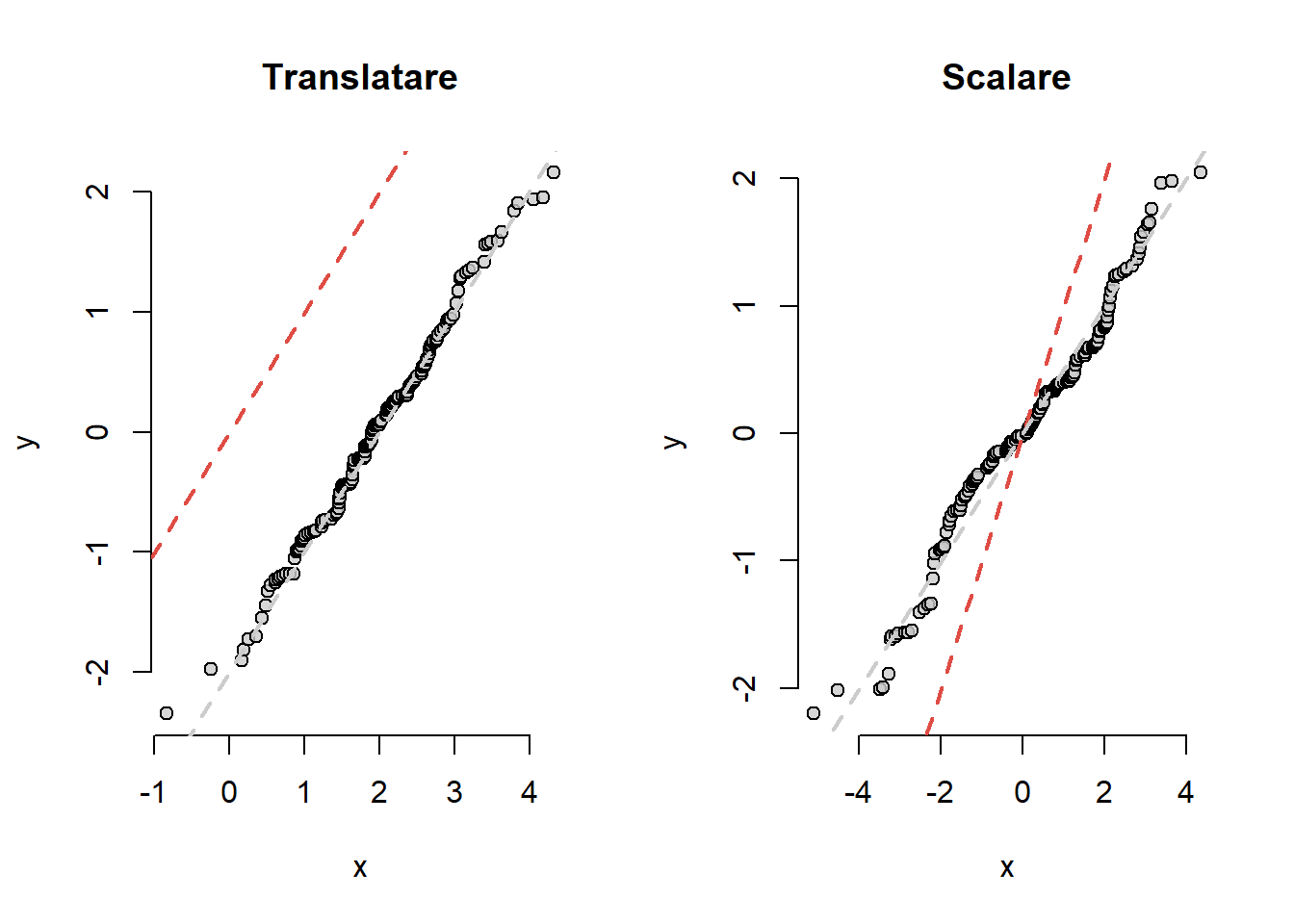
O deviere de la prima bisectoare indică o diferență între formele celor două repartiții din care au provenit datele. Atunci când cele două repartiții au aceeași formă dar au medii și respectiv abateri standard diferite atunci graficul rămâne liniar numai că ordonata la origine și panta dreptei nu vor mai fi \(0\) și respectiv \(1\). O ordonată la origine diferită de \(0\) arată o translatare în repartiții (schimbare de locație) iar o pantă neunitară indică o schimbare de scală.
par(mfrow =c(1,2))x <-rnorm(200, 2, 1)y <-rnorm(150)qqgraf(x, y, main ="Translatare")abline(a =-2, b =1, col ="grey80", lty =2, lwd =2)x <-rnorm(200, 0, 2)y <-rnorm(150)qqgraf(x, y, main ="Scalare")abline(a =0, b =1/2, col ="grey80",lty =2, lwd =2)
Figura 1.9: Evidențierea fenomenului de translație și respectiv scalare în graficul cuantilă-cuantilă.
Graficul cuantilă-cuantilă poate fi folosit și pentru a verifica dacă un eșantion provine dintr-o repartiție specificată, astfel, dat fiind \((X_1, X_2, \ldots, X_n)(\omega) = (x_1, x_2, \ldots, x_n)\) un eșantion de volum \(n\) vrem să verificăm dacă acesta provine dintr-o populație (specificată) \(F\). Dacă \(\hat{x}_p(n)\) este cuantila empirică de ordin \(p\) și \(x_p = F^{-1}(p)\) este cuantila teoretică de ordin \(p\) asociată lui \(F\), atunci graficul cuantilă-cuantilă este determinat de punctele \(\left(x_p,\hat{x}_p(n)\right)\), \(p\in(0,1)\). Folosind alegerea lui \(p\) de mai sus (care evită singularitățile \(F^{-1}(1) = \infty\)) și ținând cont că \(\hat{x}_{\frac{i}{n+1}}(n) = X_{(i)}\) avem că graficul cuantilă-cuantilă este determinat de mulțimea de puncte
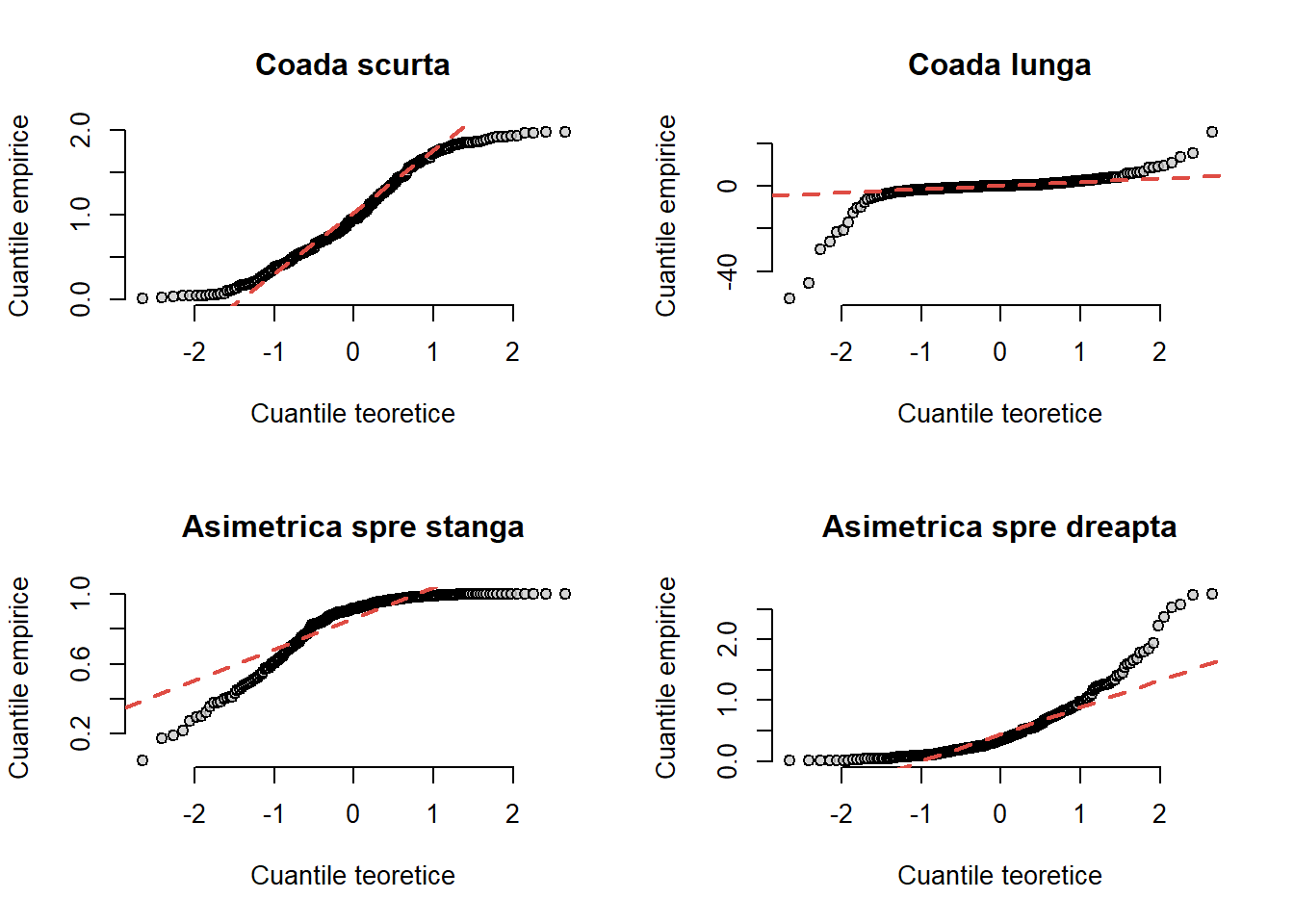
Pentru a verifica dacă datele provin dintr-o repartiție normală este suficient să alegem \(F = \Phi\), cu \(\Phi(x)\) funcția de repartiție a normalei standard (acest grafic se mai numește și normal probability plot sau normal-quantile plot). Dacă punctele se află (aproximativ) pe o dreaptă atunci putem spune că datele provin dintr-o repartiție (aproximativ) normală. Deplasarea față de normalitate este indicată prin deplasarea față de o dreaptă. Un grafic în formă de U arată că repartiția este asimetrică iar un grafic în formă de S ne spune că avem diferențe între coada repartiției normale și cea care a generat setul de date.
În R putem trasa graficul cuantilă-cuantilă pentru o populație normală cu ajutorul funcției qqnorm() iar dreapta de referință cu ajutorul funcției qqline(). Pentru mai multe detalii privind aceste funcții tastați ?qqnorm și ?qqline.
Exercițiul 1.3 Construiți în R o funcție qq_norm() care să traseze graficul cuantilă-cuantilă (normal-quantile plot) pentru a verifica dacă un eșantion provine dintr-o populație normală.
Soluție. Codul funcției qq_norm() este dat mai jos:
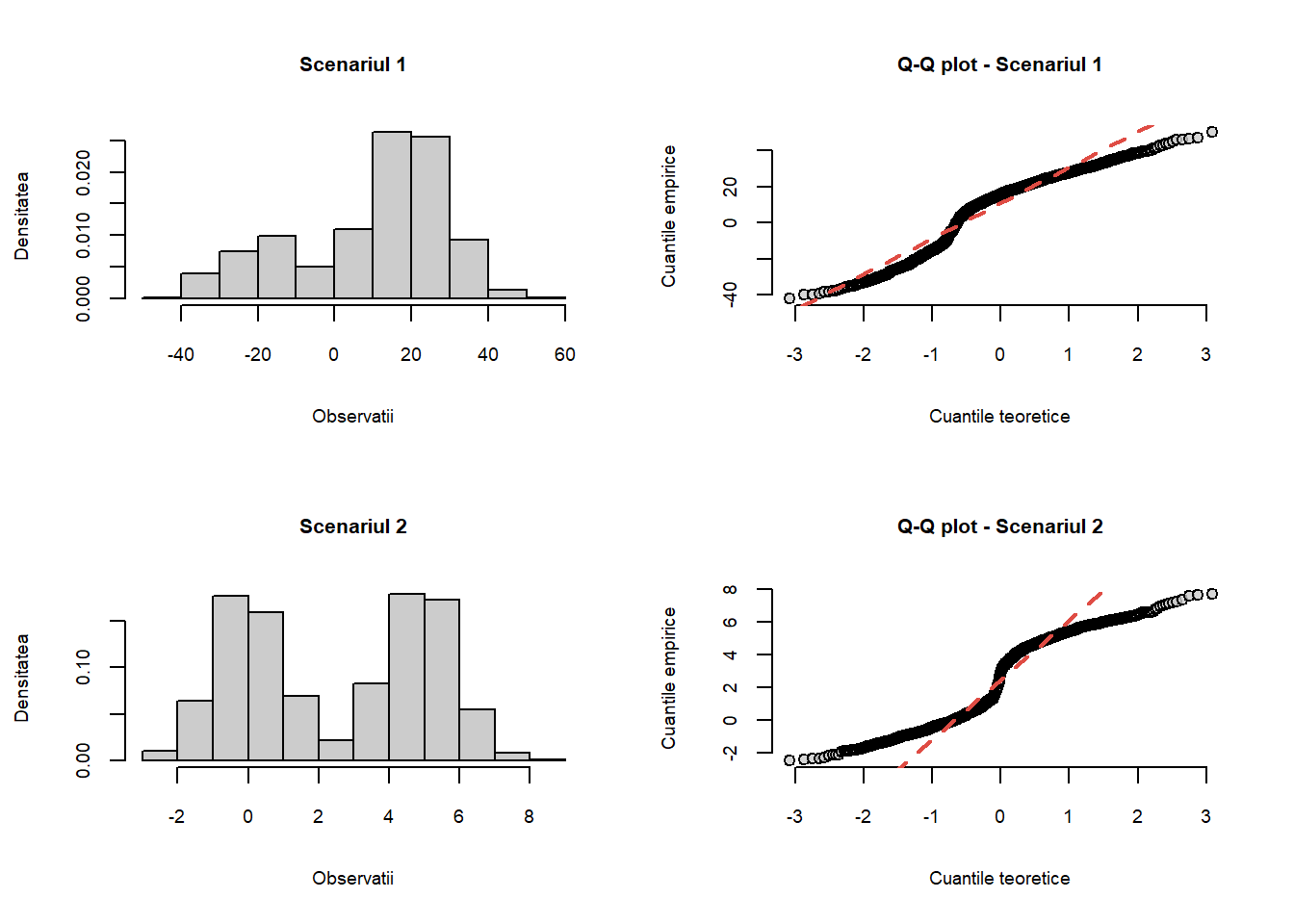
Apelând această funcție putem vizualiza ce se întâmplă în situația în care eșantionul provine dintr-o repartiție cu coadă scurtă, coadă lungă sau asimetrică.
par(mfrow =c(2,2))n <-250# coada scurta x_st <-runif(n, min=0, max=2)qq_norm(x_st, main ="Coada scurta")# coada lunga x_ht <-rcauchy(n, location=0, scale=1)qq_norm(x_ht, main ="Coada lunga")# asimetrica spre stanga x_sn <-rbeta(n, 2, 0.5, ncp =2)qq_norm(x_sn, main ="Asimetrica spre stanga")# asimetrica spre dreapta x_sp <-rexp(n, 2)qq_norm(x_sp, main ="Asimetrica spre dreapta")
Figura 1.10: Graficul cuantilă-cuantilă pentru diverse scenarii.
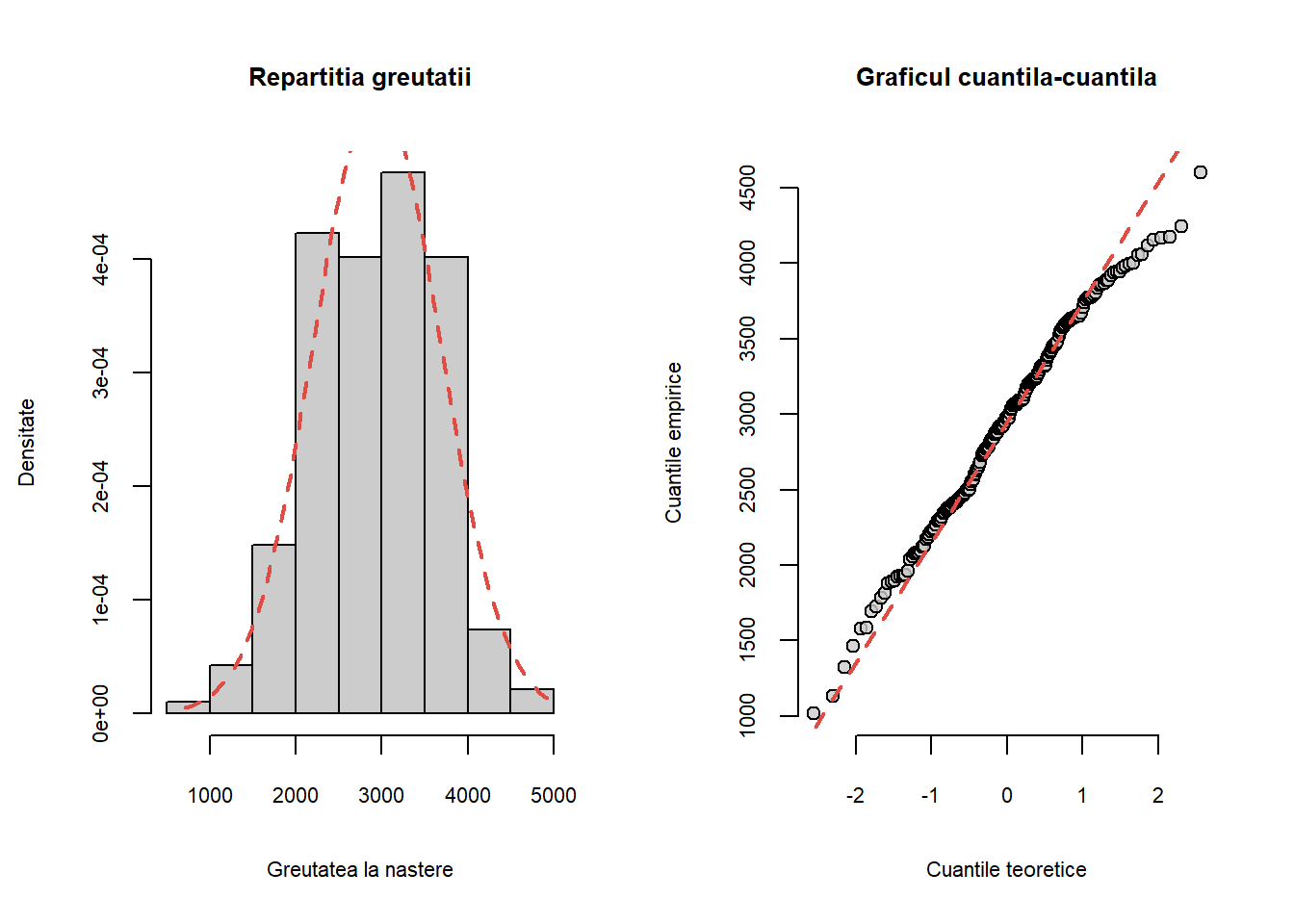
Exercițiul 1.4 Considerați setul de date birthwt din pachetul MASS. Trasați histograma greutății la naștere a copiilor (variabila bwt) și graficul cuantilă-cuantilă pentru o populație normală. Comparați grafic dacă repartiția greutății copiilor la naștere diferă în funcție de statutul de fumător al mamei.
Soluție. Repartiția eșantionului peste care am suprapus densitatea normală corespunzătoare, împreună cu graficul cuantilă-cuantilă sunt ilustrate de codul R următor:
par(mfrow =c(1,2), cex.main =0.8,cex.axis =0.7,cex.lab =0.7)hist(birthwt$bwt, probability =TRUE, col ="grey80",main ="Repartitia greutatii",xlab ="Greutatea la nastere",ylab ="Densitate")t <-seq(min(birthwt$bwt), max(birthwt$bwt), length.out =100)x <-dnorm(t, mean(birthwt$bwt), sd(birthwt$bwt))lines(t, x, lwd =2, lty =2,col = myred)qq_norm(birthwt$bwt, main ="Graficul cuantila-cuantila")
Figura 1.11: Histograma greutății la naștere a copiilor și graficul cuantilă-cuantilă corespunzător.
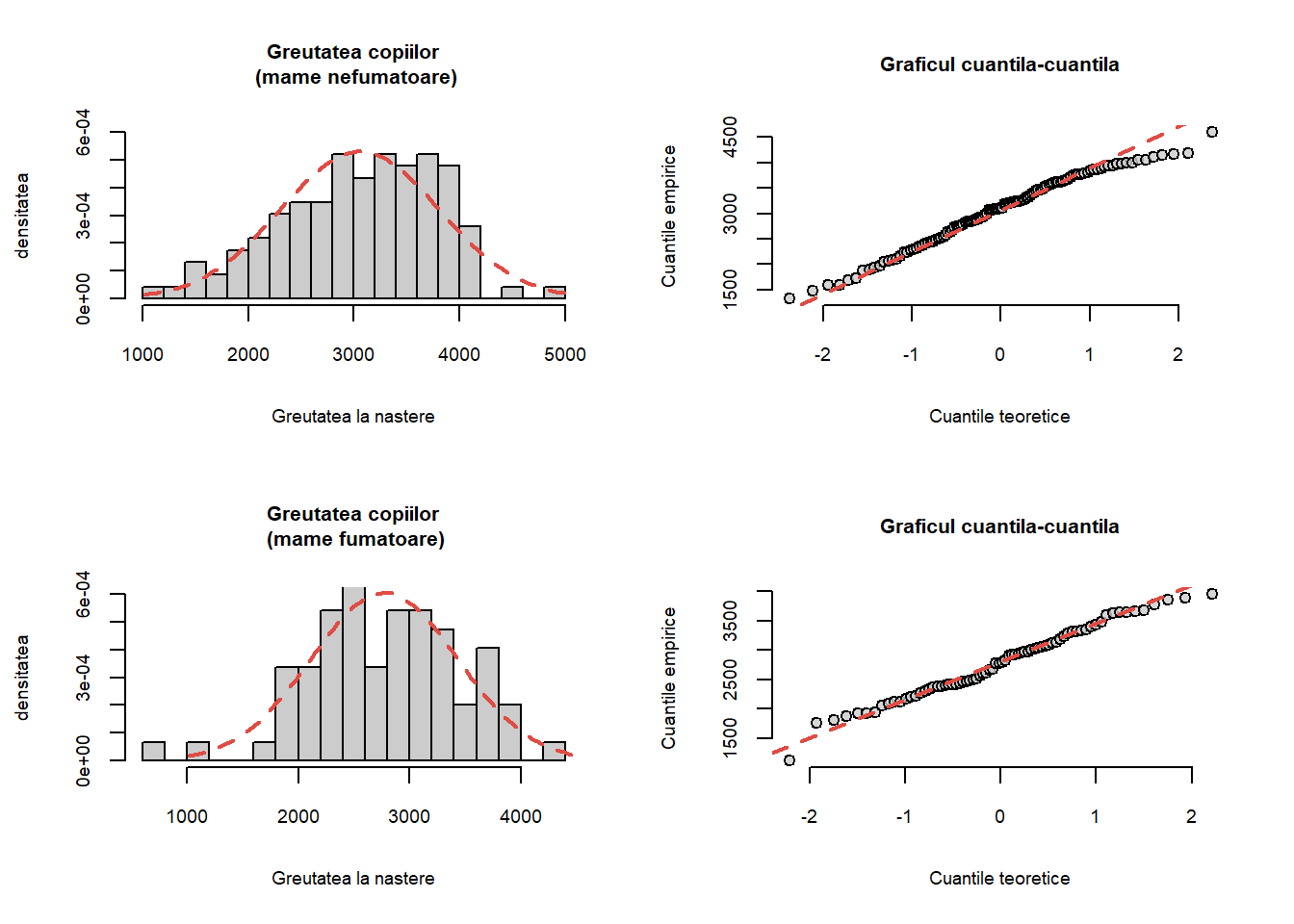
Greutatea la naștere a copiilor din setul de date în funcție de statutul de fumător al mamei este evidențiat mai jos:
Figura 1.12: Repartiția greutății copiilor la naștere în funcție de statutul de fumător al mamei.
Ce se întâmplă atunci când avem o mixtură de repartiții? Următoarea funcție permite generarea unui eșantion dintr-o mixtură de două repartiții normale: