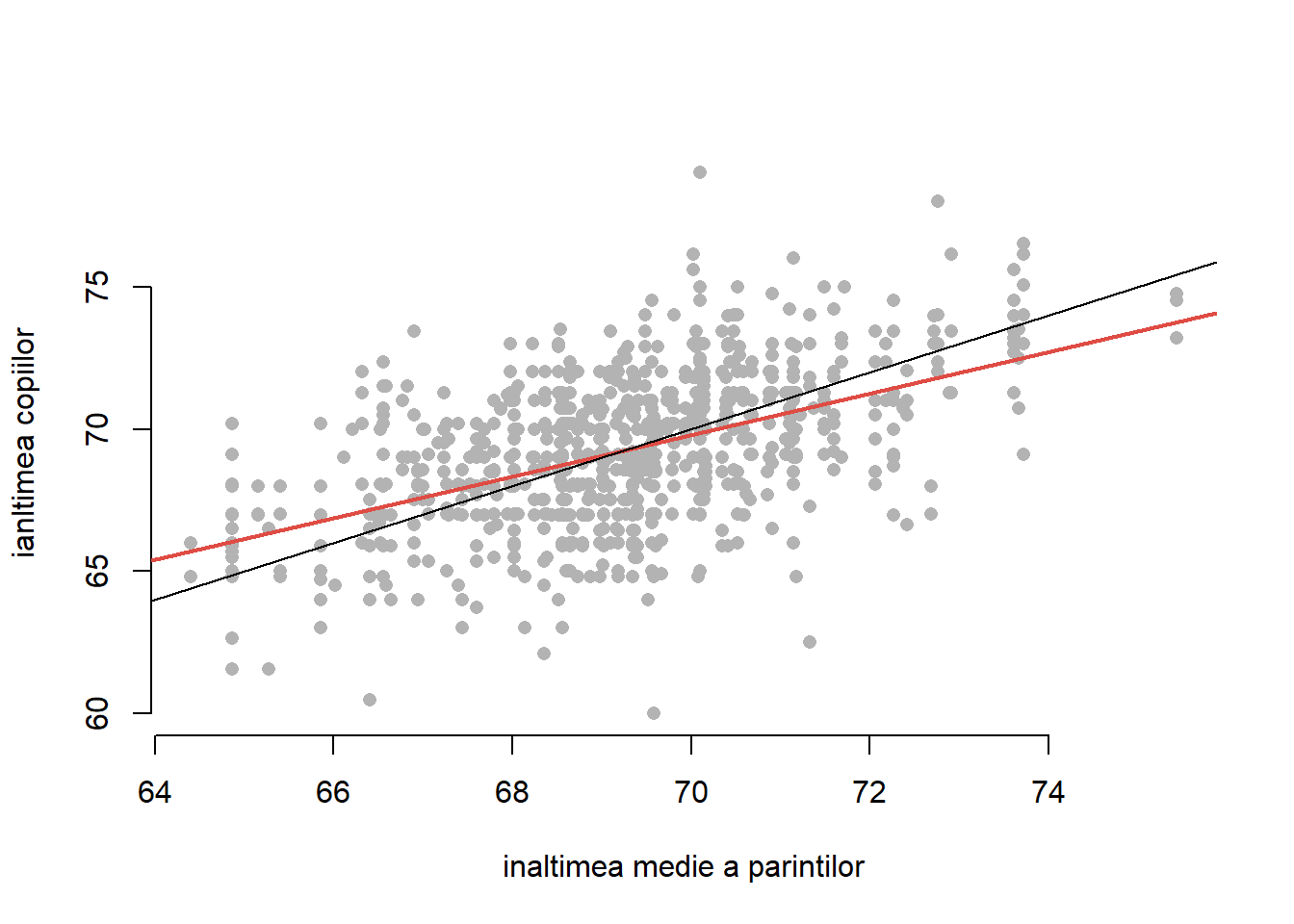
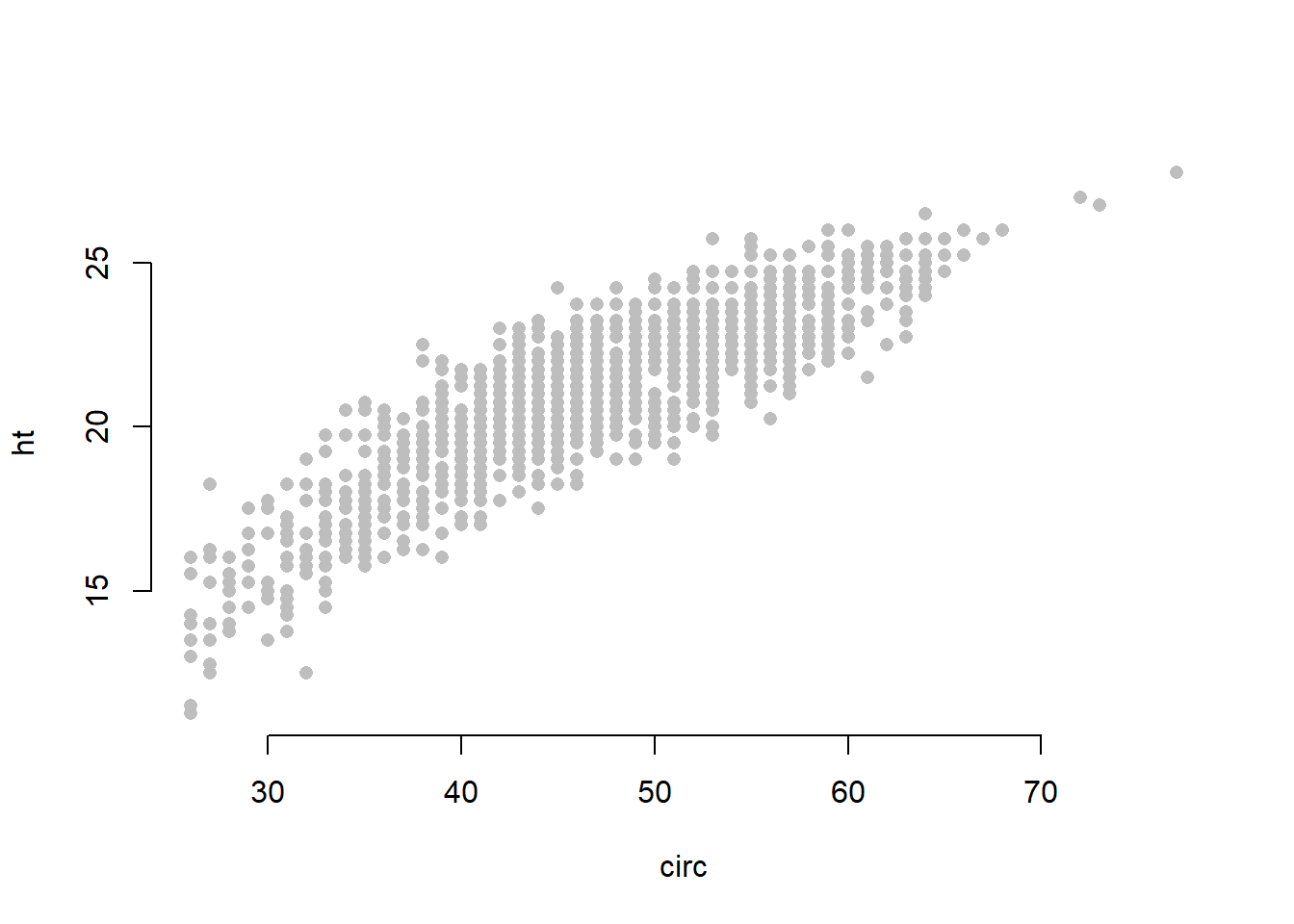Cuvântul “regresie” provine de la Sir Francis Galton (1822 - 1911) care, fiind interesat de problema transmiterii unui caracter ereditar de la părinți la copii, a strâns date despre înălțimea părinților și cea a copiilor lor ajunși adolescenți1. Astfel, Galton a încercat să examineze relația dintre înălțimea copiilor și înălțimea medie a părinților (a ajustat diferențele naturale dintre sexe înmulțind înălțimea persoanelor de sex feminin cu un coeficient de 1.08).
Arată codul R
data_Galton <-read.table("dataIn/galton-stata11.tab", header =TRUE)data_Galton <- data_Galton %>%mutate(mother_c =1.08* mother,avg_parents = (father + mother_c)/2,height_c =ifelse(gender =="F", 1.08*height, height))plot(data_Galton$avg_parents, data_Galton$height_c,bty ="n",xlab ="inaltimea medie a parintilor",ylab ="ianltimea copiilor", pch =16,col ="grey70")galton_model <-lm(height_c ~ avg_parents, data = data_Galton)abline(galton_model$coefficients, col = myred,lwd =2, lty =1)abline(a =0, b =1)
Figura 1.1: Înălțimea medie a părinților versus înălțimea copiilor.
A observat că între înălțimea copiilor (ajunși la vârstă adultă) și înălțimea medie a părinților există o relație (aproximativ) liniară cu o pantă de 2/3 (mai exact 0.7290562). Având o pantă mai mică de \(1\), Galton a tras concluzia că acei copii care provin din familii cu părinți foarte înalți (sau scunzi) sunt în general mai scunzi (înalți) decât părinții lor. Astfel, oricare ar fi situația (familii cu părinți înalți ori scunzi), înălțimea copiilor tinde spre media populației, ceea ce Galton a numit regresie spre medie. Cu alte cuvinte, Galton a studiat modul în care variabila explicativă\(x\) = “înălțimea medie a părinților” influențează variabila răspuns\(y\) = “înălțimea copiilor” și a propus, ținând cont de faptul că relația dintre cele două variabile nu este exact liniară ci depinde de erori aleatoare, următorul model
\[
y = \beta_0 + \beta_1 x + \varepsilon
\]
în care componenta sistematică \(\beta_0 + \beta_1 x\) este liniară și \(\varepsilon\) este eroarea aleatoare.
De manieră informală, un model explicativ este un model prin care o variabilă \(y\) este exprimată ca o funcție de una sau mai multe variabile, numite în cele ce urmează explicative. De manieră formală, încercăm să modelăm efectul unei variabile sau a mai multor variabile explicative \(x_1,\ldots, x_p\) asupra variabilei de interes \(y\). Variabila \(y\) se numește variabilă răspuns sau variabilă dependentă iar variabilele explicative se mai numesc și covariabile, variabile independente (termen pe care nu îl vom folosi), factori sau încă regresori. Într-un model de regresie, căutăm, de cele mai multe ori, să determinăm modul în care variabila răspuns evoluează, în medie, în funcție de variabilele explicative. O caracteristică principală a modelelor de regresie este că relația dintre \(y\) și covariabile nu se exprimă ca o funcție deterministă \(f(x_1,\ldots,x_p)\) ci prezintă erori aleatoare ceea ce sugerează că variabila răspuns este o variabilă aleatoare a cărei repartiție depinde de valorile variabilelor explicative. De exemplu, în cazul problemei lui Galton, chiar dacă știam cu exactitate care este înălțimea părinților nu puteam prezice exact înălțimea copiilor, ceea ce puteam face era să estimăm înălțimea medie a acestora și gradul de împrăștiere.
De manieră generală, modelul de regresie poate fi scris sub forma
unde, membrul stâng arată dependența variabilei răspuns de variabilele explicative \(y(x_1,\ldots,x_p)\) iar membrul drept este compus din doi termeni: componenta sistematică a modelului \(f(x_1,\ldots,x_p)\) care prezintă influența covariabilelor asupra valorii medii a variabilei dependente (\(\mathbb{E}[y(x_1,\ldots,x_p)] = f(x_1,\ldots,x_p)\)) și componenta aleatoare, \(\varepsilon(x_1,\ldots, x_p)\), numită și termen eroare (sau zgomot aleator) care prezintă incertitudinea modelului. Cum \(\mathbb{E}[y(x_1,\ldots,x_p)] = f(x_1,\ldots,x_p)\) avem că \(\mathbb{E}[\varepsilon(x_1,\ldots, x_p)] = 0\). În modelul clasic de regresie vom presupune că termenul eroare (zgomotul aleator) nu depinde de covariabile, prin urmare \(\varepsilon(x_1,\ldots, x_p) = \varepsilon\) și modelul se va rescrie sub forma
\[
y = f(x_1,\ldots,x_p) + \varepsilon.
\]
În funcție de modul în care sunt efectuate observațiile, covariabilele pot fi deterministe sau aleatoare. Pentru prima situație putem presupune că ne aflăm în contextul unui plan de experiență planificat, în care valorile covariabilelor sunt fixate înaintea derulării experimentului. De exemplu, să considerăm că ne aflăm în contextul unui experiment prin care un inginer agronom dorește să investigheze influența pe care o are cantitatea de îngrășământ (covariabilă măsurată în kg/hectar) asupra randamentului unei culturi de cereale (variabilă răspuns măsurată în tone/hectar). În acest context, suprafața cultivată se parcelează și pentru fiecare parcelă inginerul atribuie o anumită cantitate de îngrășământ prestabilită: \(x_1,\ldots,x_n\)2 Randamentul culturii de pe fiecare parcelă poate fi văzut ca o variabilă aleatoare care depinde de mai mulți factori, alții decât nivelul de îngrășământ (e.g. dăunători, umiditate în sol). Valorile observate \(y_1,\ldots, y_n\) sunt văzute ca realizări ale unor variabile aleatoare \(Y_1,\ldots,Y_n\), unde \(Y_i\) reprezintă randamentul pentru nivelul de îngrășământ \(x_i\) și \(\mathbb{E}[Y_i]=f(x_i)\). De cele mai multe ori, în schimb, nu ne aflăm în condițiile unui plan de experiență planificat ci în contextul unui experiment în care valorile covariabilelor nu sunt cunoscute înaintea efectuării experimentului. Să presupunem, spre exemplu, că ne aflăm în contextul unui sondaj efectuat pentru a investiga cum variază venitul (variabila răspuns) în funcție de vârsta populației (variabila explicativă). Astfel, unui individ ales la întâmplare din grupul țintă îi corespunde un cuplu de variabile aleatoare \((X,Y)\) unde \(X\) este vârsta iar \(Y\) este valoarea venitului. În acest context, valorile observate pentru \(n\) indivizi sunt considerate ca realizări de variabile aleatoare și obiectivul este de a studia cum variază în medie venitul în funcție de vârstă, altfel spus, funcția de regresie \(f(x)\) (numită și curba de regresie) este media condiționată a lui \(Y\) la valoare lui \(X = x\), \(\mathbb{E}[Y|X = x] = f(x)\).
Prin urmare în cazul modelului de regresie condiționat, componenta sistematică este dată de media condiționată la nivelul covariabilelor iar forma generală a modelului de regresie devine
\[
y = \mathbb{E}[y|x_1,\ldots,x_p] + \varepsilon = f(x_1,\ldots,x_p) + \varepsilon.
\] Înainte de a vorbi de clasificarea modelelor de regresie, vom arăta că într-adevăr funcția de regresie \(f(x) = \mathbb{E}[Y|X = x]\) este predictorul optimal din punct de vedere al erorii pătratice medii. Să presupunem, pentru început, că vrem să prezicem valoarea unei variabile aleatoare \(Y\) prin intermediul unei valori reale \(m\in\mathbb{R}\). Din perspectiva erorii pătratice medii, am vrea să determinăm \(m\) care minimizează
observăm că valoarea lui \(m\) care minimizează eroarea pătratică medie este \(m^*=\mathbb{E}[Y]\).
Pe de altă parte, dacă acum avem o nouă variabilă aleatoare \(X\) pe care o cunoaștem și vrem să folosim această informație pentru a îmbunătăți estimarea noastră cu privire la \(Y\), atunci predicția noastră ar fi o funcție de \(x\), să zicem \(f(x)\). Am dori să determinăm \(f\) astfel ca \(\mathbb{E}\left[(Y-f(X))^2\right]\) să fie cât de mic posibil, i.e.
\[
f = \underset{g}{\mathrm{argmin}}\, \mathbb{E}\left[(Y-g(X))^2\right].
\]
Următorul rezultat ne spune că media condiționată este cel mai bun predictor din perspectiva erorii pătratice medii:
Propoziția 1.1 (Curba de regresie) Pentru orice funcție \(g(x)\) avem descompunerea
Dar cum \(\mathbb{E}\left[Y-\mu(x)\mid X=x\right] = \mathbb{E}\left[Y\mid X=x\right]-\mu(x) = 0\) iar \(\operatorname{Var}(Y \mid X = x)=\mathbb{E}\left[(Y-\mu(x))^2\mid X=x\right]\), găsim că
prin urmare variabila aleatoare care minimizează \(\mathbb{E}\left[(Y-g(X))^2\right]\) este \(\mathbb{E}[Y \mid X]\) iar valoarea minimă este \(\mathbb{E}[\operatorname{Var}(Y \mid X)]\).
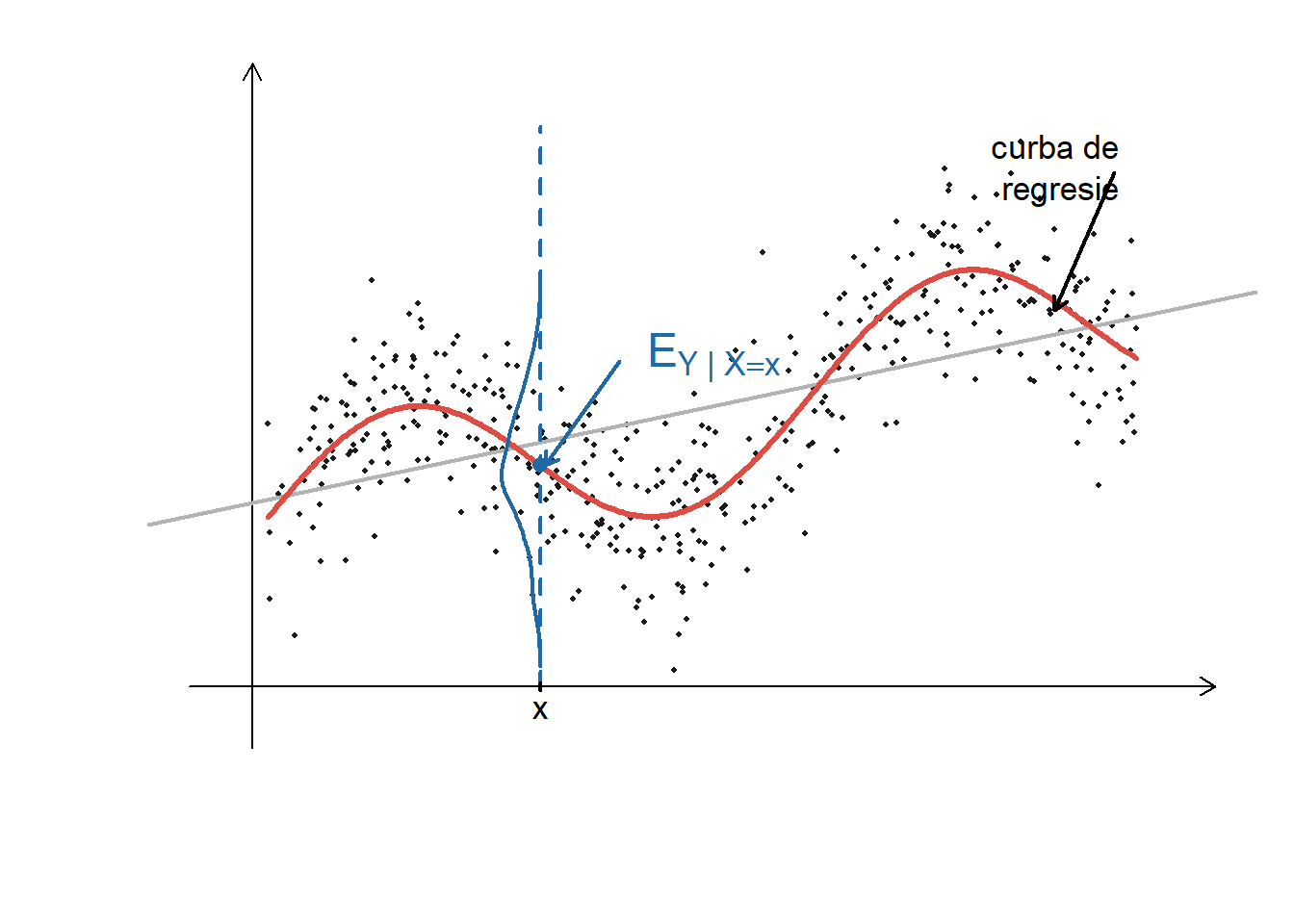
Următoarea figură ilustrează curba de regresie pentru un model simulat:
Arată codul R
set.seed(1)## Exemplu de date n <-450x <-sort(runif(n, 0, 10))f <-function(x) 0.25*x +sin(x)# curba "adevărată"y <-f(x) +rnorm(n, sd =0.6)x0 <-3.2# poziția (x din desen)h <-0.5# jumătate din fereastra |x-x0|<=h folosită pt densitate## Fit-uri pentru curbefit_loess <-loess(y ~ x, span =0.25)fit_lm <-lm(y ~ x)# yhat0 <- predict(fit_loess, newdata = data.frame(x = x0))yhat0 <-f(x0)## Setări plotxr <-range(x); yr <-range(y)padx <-0.9; pady <-0.9par(mar =c(4,4,1,1))plot(x, y, pch =16, cex =0.45, col ="grey10",axes =FALSE, xlab ="", ylab ="",xlim =c(xr[1]-padx, xr[2]+padx),ylim =c(yr[1]-pady, yr[2]+pady))## Axe cu săgețiarrows(xr[1]-padx, yr[1]-0.2*pady, xr[2]+padx, yr[1]-0.2*pady,length =0.10, lwd =1)arrows(xr[1]-0.2*padx, yr[1]-pady, xr[1]-0.2*padx, yr[2]+pady,length =0.10, lwd =1)## Linia gri (regresie liniară) + curba roșie (regresie neliniară)abline(fit_lm, col ="grey70", lwd =2)xx <-seq(xr[1], xr[2], length.out =400)lines(xx, f(xx),col = myred, lwd =3)## Linia verticală punctată la x0segments(x0, yr[1]-0.2*pady, x0, yr[2]+0.2*pady,col = myblue, lty =2, lwd =2)## densitatea lui Y pentru X aproape de x0idx <-abs(x - x0) <= hd <-density(y[idx], n =200)scale <-0.75# lățimea violinului (în unități de x)x_left <- x0 - d$y*scalelines(x_left, d$x, col = myblue, lwd =2)## Punctul E[Y|X=x0] pe curba roșie + săgeată + etichetăpoints(x0, yhat0, pch =16, col = myblue, cex =1.1)arrows(x0 +0.9, yhat0 +1.2, x0 +0.05, yhat0,col = myblue, lwd =2, length =0.08)text(x0 +1.0, yhat0 +1.2,bquote(E[Y~"|"~X==x]),col = myblue, pos =4, cex =1.5)## Marcaj “x” pe axa Oxsegments(x0, yr[1]-0.25*pady, x0, yr[1]-0.15*pady, lwd =2)text(x0, yr[1]-0.5*pady, "x", cex =1.1)## Etichetă “curba de regresie” cu săgeată spre curba roșiex_lab <-as.numeric(quantile(x, 0.9))y_lab <-predict(fit_loess, newdata =data.frame(x = x_lab))text(xr[2]-0.2, yr[2]+0.1, "curba de\nregresie", adj =c(1,1), cex =1.1)arrows(xr[2]-0.25, yr[2]-0.35, x_lab, y_lab, length =0.08, lwd =2)
Figura 1.2: Ilustrarea funcției de regresie.
Modelele de regresie se pot clasifica, în funcție de forma variabilei răspuns, în modele univariate, atunci când aceasta este o variabilă aleatoare și respectiv multivariate, atunci când aceasta este un vector aleator iar în raport cu numărul de predictori în modele simple atunci când avem un singur predictor sau modele multiple atunci când intervin mai multe variabile explicative. Raportându-ne la forma componentei sistematice, putem avea modele liniare, în care parametrii care descriu forma lui \(f\) intră liniar (e.g. \(f(x) = \beta_0 + \beta_1 x\), \(f(x) = \beta_0 + \beta_1 x + \beta_2 x^2\) sau \(f(x) = \beta_0 + \beta_1 \log(x) + \beta_2 \cos(x)\)), sau modele neliniare, în care parametrii nu apar liniar (e.g. \(f(x) = \beta_0 + \beta_1 e^{\beta_3 x}\)). De reținut: în statistică, de cele mai multe ori, liniar se referă la liniar în parametrii nu liniar în covariabile.
Scopul analizei de regresie este de a utiliza observațiile, datele, \(y_i,x_{i1},\ldots,x_{ip}\), \(i = 1,\ldots,n\) în vederea estimării (aproximării) componentei sistematice \(f\) a modelului și de a o separa pe aceasta de componenta aleatoare \(\varepsilon\). Problema matematică se scrie sub forma
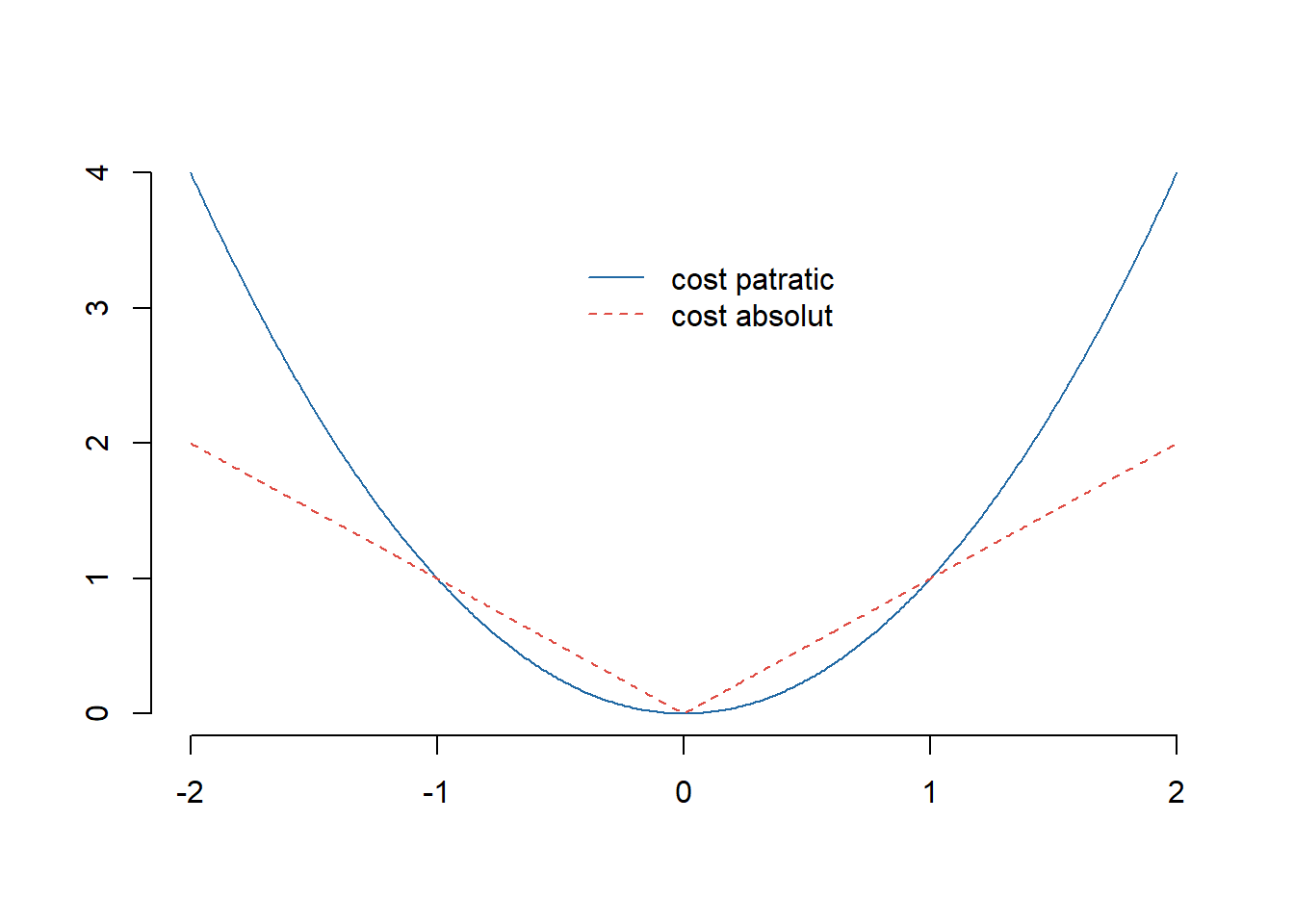
unde \(L\) se numește funcție de cost sau de pierdere (loss) iar \(\mathcal{F}\) este clasa de funcții în care presupunem că se regăsește adevărata componentă sistematică \(f\), altfel spus, dorim să determinăm acea funcție din clasa de funcții \(\mathcal{F}\) care minimizează costul. Cele mai des utilizate funcții de cost sunt costul pătratic, \(L(u) = u^2\), și respectiv costul absolut \(L(u) = |u|\).
Arată codul R
t <-seq(-2, 2, by =0.01)c_q <- t^2c_a <-abs(t)plot(t, c_q, type ="l", bty ="n", col = myblue, xlab ="", ylab ="")lines(t, c_a, lty =2, col = myred)legend(x =-0.5, y =3.5, legend =c("cost patratic", "cost absolut"), lty =c(1, 2), col =c(myblue, myred), bty ="n")
Figura 1.3: Ilustrarea funcțiilor de cost.
În acest curs vom studia modelul clasic de regresie liniară în care componenta sistematică \(f\) face parte din clasa de funcții liniare \(\mathcal{F} = \{f\,|\, f(x_1,\ldots,x_p) = \beta_0 + \beta_1 x_1 +\cdots+\beta_p x_p\}\), prin urmare media (condiționată) a lui \(y\) este o combinație liniară de covariabile iar variabila răspuns este continuă:
cu parametrii necunoscuți (sau coeficienții de regresie) \(\beta_0,\ldots,\beta_p\).
În acest punct, o întrebare naturală ar fi: de ce studiem modelele de regresie liniară dacă multe probleme reale pot avea structuri neliniare? O serie de motive ar fi:
modelele de regresie liniară sunt puncte de plecare simple, dar nu banale pentru procesul de modelare și învățare; multe dintre modelele mai flexibile sunt extensii sau generalizări ale modelelor de regresie liniară
modelele de regresie liniară pot oferi informații utile, deoarece putem deriva formule explicite bazate pe elemente de algebră liniară și geometrie
modelele de regresie liniară pot gestiona neliniaritatea prin incorporarea termenilor neliniari în model: transformarea atât a covariabilelor cât și/sau a răspunsului
modelele de regresie liniară pot fi aproximări bune ale proceselor neliniare care au generat datele
modelele de regresie liniară sunt mai simple decât modelele neliniare, dar nu au neapărat performanțe mai slabe decât modelele neliniare mai complicate
2 Seturi de date folosite în curs
În secțiunile care urmează vom prezenta o serie de seturi de date care vor fi utilizate pe parcursul acestor note pentru a ilustra noțiunile descrise.
2.1 Înălțimea arborilor de eucalipt
Setul de date Eucalypt (care poate fi descărcat de aici) face referire la înălțimea și circumferința (măsurată la 1m 30cm de sol) a 1429 arbori de eucalipt plantați într-o regiune experimentală din Franța. Cele două caracteristici sunt măsurate la vârsta de maturitate a arborilor, anume la 6 ani. O imagine a primelor observații din setul de date este dată de tabelul de mai jos:
Tabelul 2.1: Primele observații din setul de date Eucalypt
individ
ht
circ
1
18.25
36
2
19.75
42
3
16.50
33
4
18.25
39
5
19.50
43
6
16.25
34
Pentru a avea o imagine de ansamblu asupra datelor putem folosi funcția summary și aceasta întoarce:
Tabelul 2.2: Statisticile de bază privind variabilele din setul de date Eucalypt
ht
circ
Min. :11.25
Min. :26.00
1st Qu.:19.75
1st Qu.:42.00
Median :21.75
Median :48.00
Mean :21.21
Mean :47.35
3rd Qu.:23.00
3rd Qu.:54.00
Max. :27.75
Max. :77.00
Scopul este de a găsi o relație între înălțimea arborilor și circumferința acestora în vederea estimării volumului de lemn din zona studiată (volum calculat după o formulă de tip trunchi de con). Reprezentarea setului de date este ilustrată în figura de mai jos:
Figura 2.1: Diagrama de împrăștiere a variabilelor circ și ht din setul de date Eucalypt.
Codul R folosit pentru trasarea diagramei de împrăștiere este:
Arată codul R
# incarcati setul de date din locatia corespunzatoareeucalypt <-read.table("dataIn/eucalyptus.txt", header=T,sep=";")plot(ht~circ,data=eucalypt,pch =16,col ="grey",xlab="circ",ylab="ht", bty ="n")
2.2 Prețul chiriei locuințelor în Munchen
Setul de date Munchen (care poate fi descărcat de aici) face referire la prețul net și respectiv prețul net pe metrul pătrat al chiriei unei locuințe din orașul Munchen, Germania pentru anul 1999. Setul de date prezintă prețurile a mai multe de 3000 de apartamente împreună cu o serie de variabile explicative precum suprafața de locuit, anul de construcție a imobilului, etc. Aceste informații pot fi găsite în tabelul de mai jos:
Tabelul 2.3: Variabilele din setul de date Munchen.
Variabila
Descriere
Media/Frecvența
Abaterea standard
Min/Max
rent
Prețul lunar net al chiriei (în Euro)
459.44
195.66
40.51/1843.38
rentsqm
Prețul lunar net al chiriei pe \(m^2\) (în Euro)
7.11
2.44
0.41/17.72
area
Suprafața de locuit în \(m^2\)
67.37
23.72
20/160
yearc
Anul de construcție
1956
22.31
1918/1997
location
Calitatea locației: 1 - medie, 2- bună și 3- de top
58.91%, 39.26%, 2.53%
bath
Calitatea băilor: 0 - standard, 1 - premium
93.8%, 6.2%
kitchen
Calitatea bucătăriei: 0 - standard, 1 - premium
95.75%, 4.25%
cheating
Încălzire centralizată: 0 - fără încălzire, 1 - cu încălzire
10.42%, 89.58%
3 Primii pași
Înainte de a începe analiza de regresie (sau orice altă analiză) este bine să înțelegem mai bine variabilele din setul de date cu care lucrăm. Pentru a realiza acest lucru, un prim pas constă în sumarizarea variabilelor atât prin statistici descriptive (calcularea mediilor, medianelor, a abaterilor standard, a valorilor minime și maxime, etc.) cât și prin tehnici de vizualizare (histograme, diagrame cu bare, boxplot, etc.). Atunci când lucrăm cu variabile cantitative, statisticile descriptive se rezumă la măsuri de locație (media, mediana, modul) și variație (abaterea standard, minimul, maximul) iar în cazul variabilelor calitative putem include frecvența de apariție a fiecărei categorie.
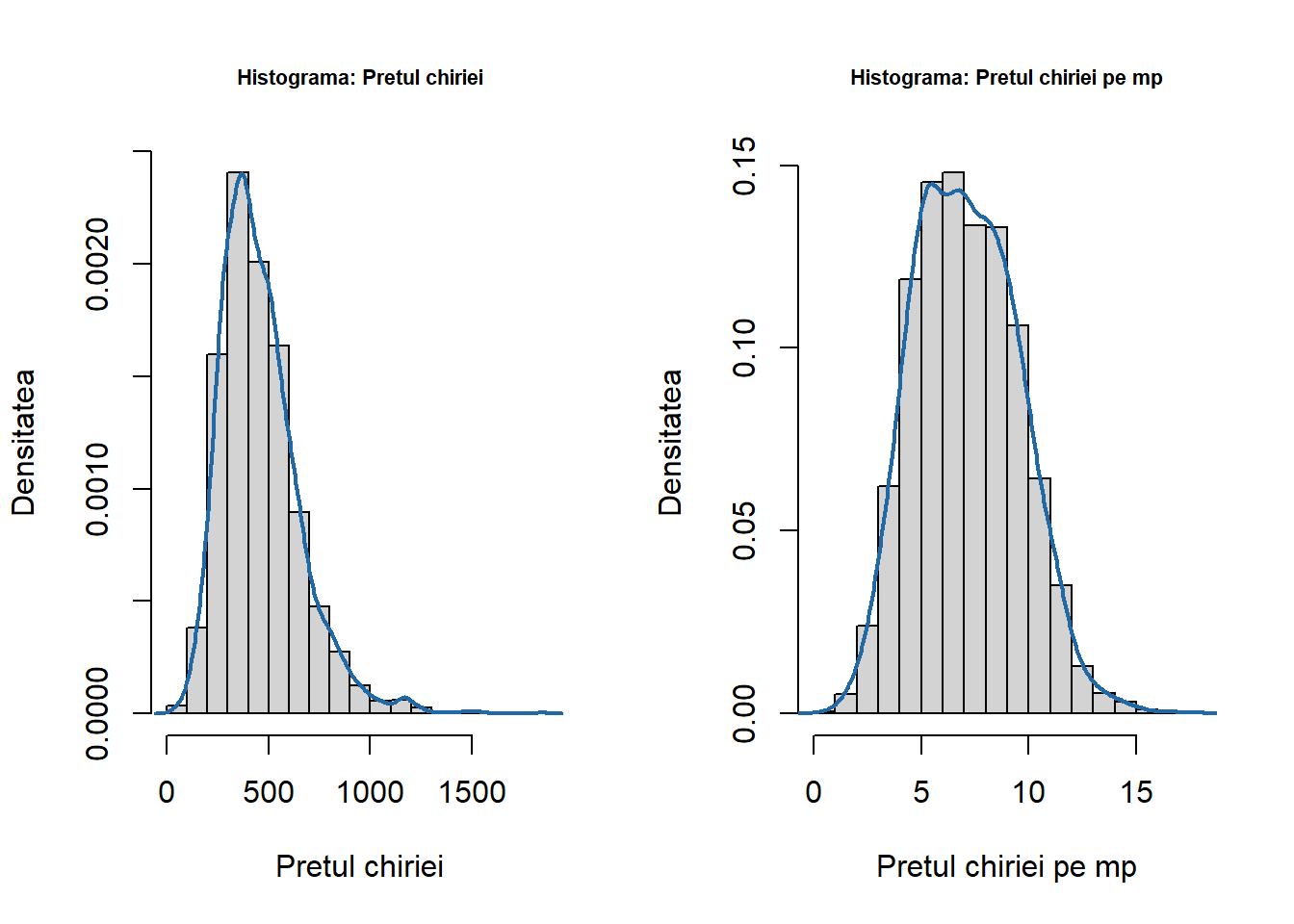
Dacă facem referire la setul de date a indicilor prețului chiriei în Munchen, atunci observăm că prețul net lunar variază între 40 și 1843 de Euro având o medie de 459 de Euro. Figura de mai jos arată cum este repartizat prețul net lunar și respectiv prețul net lunar pe \(m^2\) și constatăm că pentru majoritatea apartamentelor acesta variază între 50 și 1200 de Euro:
Figura 3.1: Repartiția prețului chiriei și a prețului chiriei pe metrul pătrat.
Figura anterioară a fost generată prin intermediul următorului cod:
Arată codul R
munich <-read.table("dataIn/rent99.raw", header =TRUE)par(mfrow =c(1,2))hist(munich$rent, probability =TRUE, main ="Histograma: Pretul chiriei",cex.main =0.7,xlab ="Pretul chiriei",ylab ="Densitatea")lines(density(munich$rent))hist(munich$rentsqm, probability =TRUE, main ="Histograma: Pretul chiriei pe mp", cex.main =0.7,xlab ="Pretul chiriei pe mp",ylab ="Densitatea")lines(density(munich$rentsqm))
În cazul în care ne interesăm asupra relației dintre variabila răspuns și variabila explicativă putem folosi ca metodă grafică diagrama de împrăștiere (scatterplot) în situația în care covariabila este continuă sau boxplot-ul în situația în care covariabila este categorică.
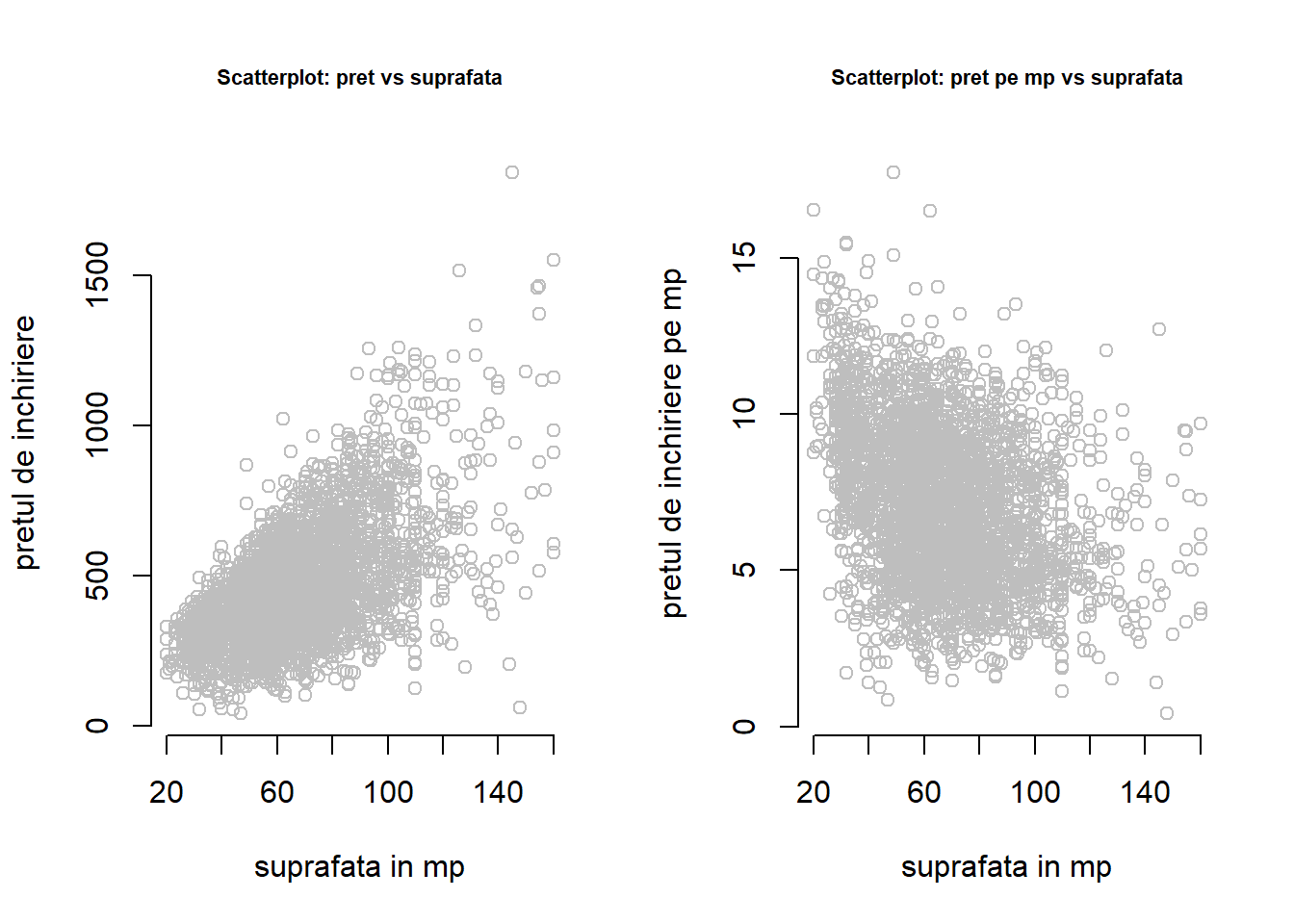
De exemplu, Figura 3.1 prezintă diagrama de împrăștiere dintre prețul lunar net sau prețul lunar net pe \(m^2\) și suprafața de locuit. Dat fiind numărul mare de observații graficul este aglomerat și nu foarte informativ. Cu toate acestea constatăm o oarecare relație liniară între prețul lunar net și suprafața de locuit precum și că variabilitatea prețului crește odată cu suprafața.
Figura 3.2: Diagramele de împrăștiere a suprafeței apartamentelor în funcție de prețul chiriei și de prețul chiriei pe metrul pătrat.
Arată codul R
par(mfrow =c(1,2))plot(rent~area,data = munich,main ="Scatterplot: pret vs suprafata",cex.main =0.7,col ="grey",xlab ="suprafata in mp",ylab ="pretul de inchiriere", bty ="n")plot(rentsqm~area,data = munich,main ="Scatterplot: pret pe mp vs suprafata",cex.main =0.7,col ="grey",xlab ="suprafata in mp",ylab ="pretul de inchiriere pe mp", bty ="n")
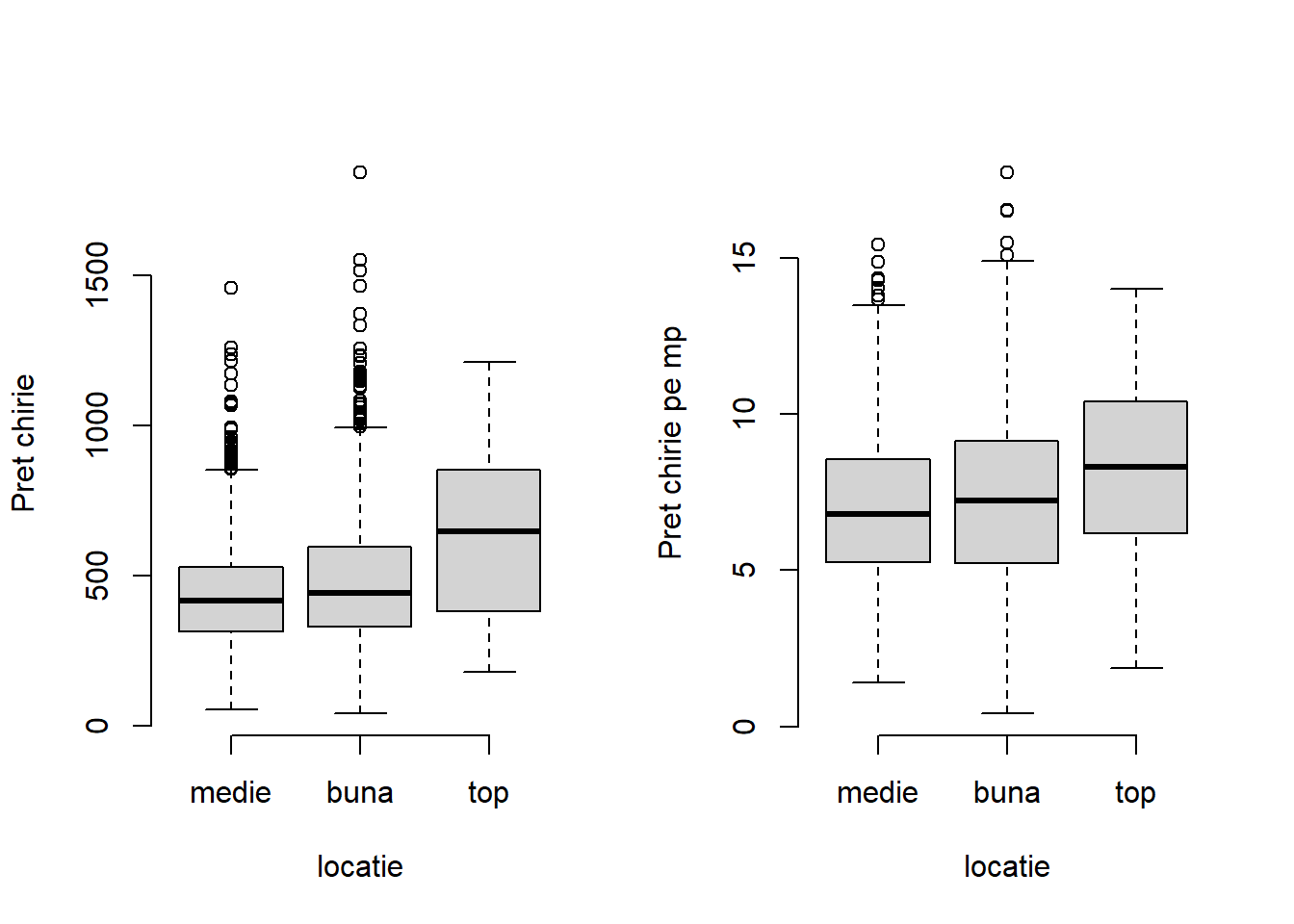
Atunci când variabila explicativă este categorială este de preferat utilizarea boxplot-ului (diagramei cu mustăți). Astfel, în figura următoare se poate observa că valoarea mediană a prețului lunar net al chiriei crește odată cu calitatea locației apartamentului.
Figura 3.3: Variația prețului chiriei și respectiv a prețului chiriei pe metrul pătrat în funcție de locație.
Trasarea diagramelor cu mustăți din Figura 3.2 s-a efectuat folosind funcția boxplot(). Pentru mai multe detalii privind folosirea acestei funcții dar și a altor elemente grafice se pot consulta notițele de laborator: Introducere în R.
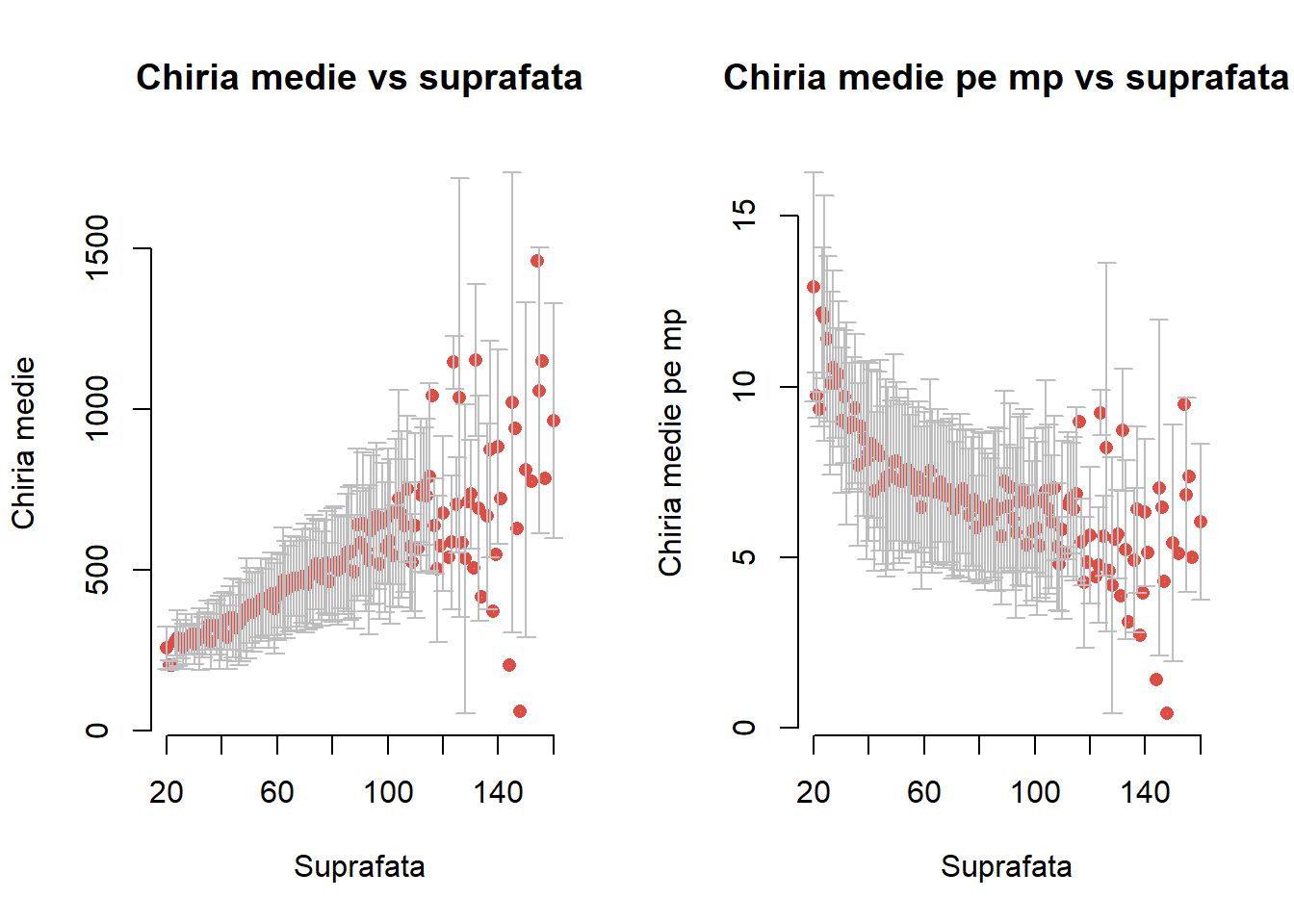
Numărul mare de observații din setul de date face dificilă interpretarea diagramei de împrăștiere și în această situație o reprezentare grafică pe grupuri (clustere) de date este de preferat. De exemplu dacă numărul valorilor unice ale variabilei explicative este mic în raport cu numărul observațiilor atunci o idee ar fi să sumarizăm variabila răspuns pentru fiecare nivel (medie, medie - abatere standard, medie + abatere standard) și să ilustrăm doar datele sumarizate.
Figura 3.4: Chiria medie în funcție de suprafață.
Arată codul R
munich_rent_area <- munich %>%group_by(area) %>%summarise(mean_rent =mean(rent, na.rm =TRUE), median_rent =median(rent, na.rm =TRUE), n =n(),sd_rent =ifelse(n>1, sd(rent, na.rm =TRUE), mean_rent), low_rent =ifelse(n>1, mean_rent - sd_rent, mean_rent),up_rent =ifelse(n>1, mean_rent + sd_rent, mean_rent))munich_rentsqm_area <- munich %>%group_by(area) %>%summarise(mean_rent =mean(rentsqm, na.rm =TRUE), median_rent =median(rentsqm, na.rm =TRUE), n =n(),sd_rent =ifelse(n>1, sd(rentsqm, na.rm =TRUE), mean_rent), low_rent =ifelse(n>1, mean_rent - sd_rent, mean_rent),up_rent =ifelse(n>1, mean_rent + sd_rent, mean_rent))# plotpar(mfrow =c(1,2))plot.with.errorbars(munich_rent_area$area, munich_rent_area$mean_rent, munich_rent_area$low_rent, munich_rent_area$up_rent, main ="Chiria medie vs suprafata", xlab ="Suprafata",ylab ="Chiria medie")plot.with.errorbars(munich_rentsqm_area$area, munich_rentsqm_area$mean_rent, munich_rentsqm_area$low_rent, munich_rentsqm_area$up_rent, main ="Chiria medie pe mp vs suprafata", xlab ="Suprafata",ylab ="Chiria medie pe mp")
Funcția care permite trasarea pentru fiecare nivel a valorii medii, a mediei - abatere standard, respectiv a mediei + abatere standard din graficul anterior este:
Arată codul R
plot.with.errorbars <-function(x, y, err_low, err_up, ...) { ylim <-c(min(err_low), max(err_up))plot(x, y, ylim=ylim, pch=16,bty ="n",col = myred, ...)arrows(x, err_low, x, err_up, length=0.05, angle=90, code=3, col ="grey")}
4 Exerciții
Exercițiul 4.1 Ilustrați prin intermediul unei histograme (hist()) cum este repartizată suprafața de locuit (variabila area) și respectiv anul de construcție a imobilului (variabila yearc).
Exercițiul 4.2 Ilustrați prin intermediul unei diagrame de împrăștiere relația dintre prețul lunar net sau prețul lunar net pe \(m^2\) și anul de construcție a imobilului iar prin intermediul unei diagrame de tip boxplot relația dintre prețul lunar net sau prețul lunar net pe \(m^2\) și calitatea băii sau a bucătăriei.
Note de subsol
Setul de date folosit în Figura 1.1 poate fi descărcat de aici↩︎
Aici trebuie avut grijă să nu se confunde valorile \(x_1,\ldots,x_n\) care corespund unei singure covariabile cu \(n\) covariabile.↩︎