Modele de regresie
Curs 3 - Regresie liniară simplă (II)
1 Coeficientul de determinare \(R^2\) și coeficientul de corelație
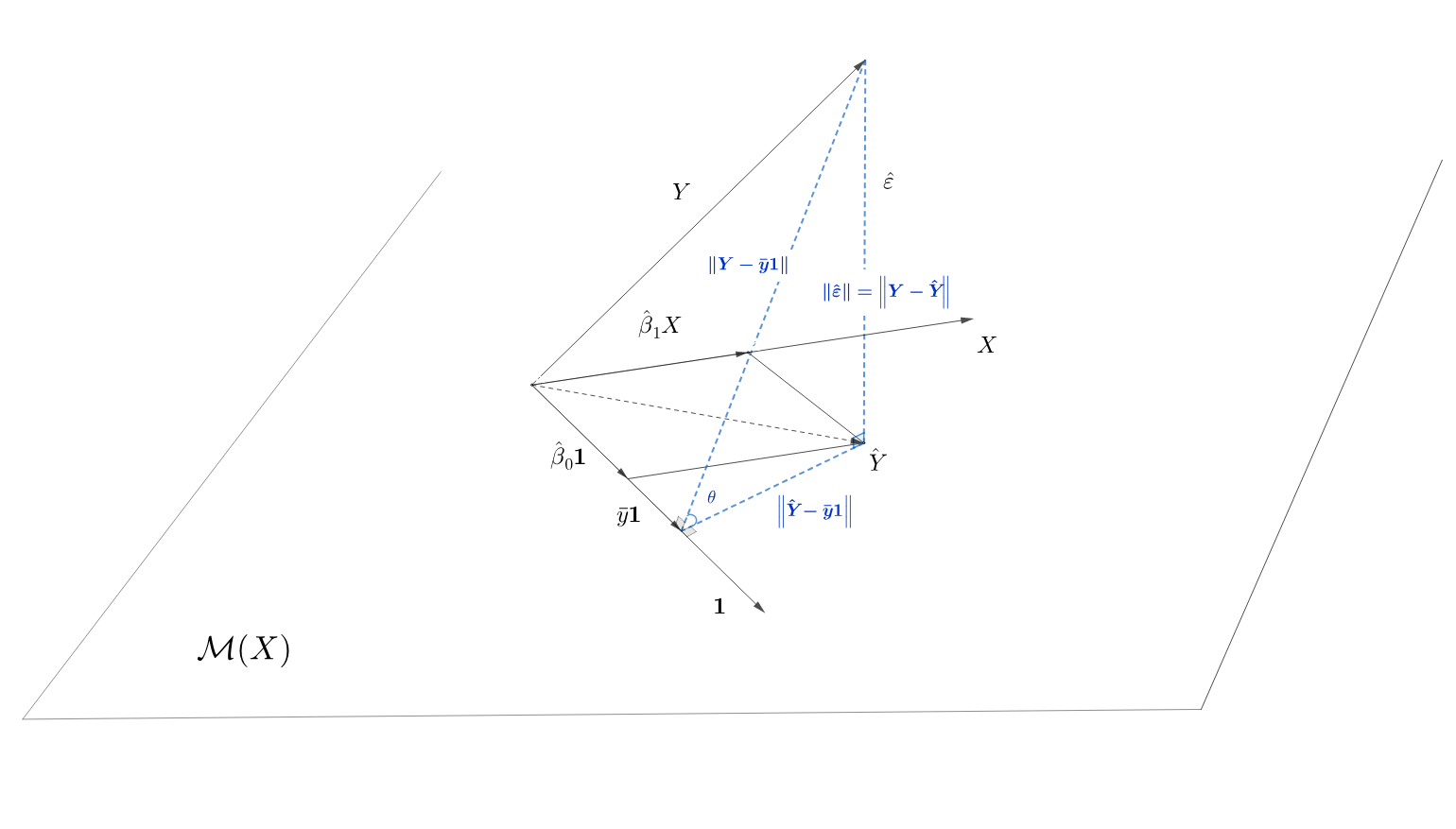
În această secțiune încercăm să abordăm problema de regresie liniară simplă într-un context geometric. Din punct de vedere vectorial dispunem de doi vectori: vectorul \(X = (x_1, x_2, \ldots, x_n)^\intercal\) a celor \(n\) observații ale variabilei explicative și vectorul \(Y = (y_1, y_2, \ldots, y_n)^\intercal\) compus din cele \(n\) observații ale variabilei răspuns, pe care vrem să o explicăm. Cei doi vectori aparțin spațiului \(\mathbb{R}^n\).
Fie \(\mathbf{1} = (1,1,\ldots,1)^\intercal\in\mathbb{R}^n\) și \(\mathcal{M}(X)\) subspațiul liniar din \(\mathbb{R}^n\) de dimensiune \(2\) generat de vectorii \(\{\mathbf{1}, X\}\) (acești vectori nu sunt coliniari deoarece \(X\) conține cel puțin două elemente distincte). Notăm cu \(\hat Y\) proiecția ortogonală a lui \(Y\) pe subspațiul \(\mathcal{M}(X)\) și cum \(\{\mathbf{1}, X\}\) formează o bază în \(\mathcal{M}(X)\) deducem că există \(\hat\beta_0, \hat\beta_1\in \mathbb{R}\) astfel ca \(\hat Y = \hat\beta_0\mathbf{1} + \hat\beta_1 X\). Cum, din definiția proiecției ortogonale, \(\hat Y\) este unicul vector din \(\mathcal{M}(X)\) care minimizează distanța euclidiană (deci și pătratul ei)
\[ \left\lVert Y - \hat Y \right\rVert^2 = \sum_{i = 1}^{n}[y_i - (\hat\beta_0 + \hat \beta_1 x_i)]^2 \]
deducem că \(\hat\beta_0, \hat\beta_1\) coincid cu valorile obținute prin metoda celor mai mici pătrate. Astfel coeficienții \(\hat\beta_0\) și \(\hat\beta_1\) se reprezintă coordonatele proiecției ortogonale a lui \(Y\) pe subspațiul generat de vectorii \(\{\mathbf{1}, X\}\) (a se vedea figura de mai jos).
Observăm că, în general, vectorii \(\{\mathbf{1}, X\}\) nu formează o bază ortogonală în \(\mathcal{M}(X)\) (cu excepția cazului în care \(\langle \mathbf{1}, X\rangle = n\bar x = 0\)) prin urmare \(\hat\beta_0\mathbf{1}\) nu este proiecția ortogonală a lui \(Y\) pe \(\mathbf{1}\) (aceasta este \(\frac{\langle Y, \mathbf{1}\rangle}{\lVert \mathbf{1}\rVert^2}\mathbf{1} = \bar y\mathbf{1}\)) iar \(\hat\beta_1 X\) nu este proiecția ortogonală a lui \(Y\) pe \(X\) (aceasta fiind \(\frac{\langle Y, X\rangle}{\lVert X\rVert^2}X\)).
Fie \(\hat\varepsilon = Y - \hat Y = (\hat\varepsilon_1, \hat\varepsilon_2, \ldots, \hat\varepsilon_n)^\intercal\) vectorul valorilor reziduale. Aplicând Teorema lui Pitagora (în triunghiul albastru din Figura 1.1) rezultă (descompunerea ANOVA pentru regresie) că
\[ \begin{aligned} \left\lVert Y - \bar y \mathbf{1}\right\rVert^2 &= \left\lVert \hat Y - \bar y \mathbf{1}\right\rVert^2 + \left\lVert \underbrace{\hat\varepsilon}_{Y - \hat Y}\right\rVert^2\\ \sum_{i = 1}^{n}(y_i - \bar y)^2 &= \sum_{i = 1}^{n}(\hat y_i - \bar y)^2 + \sum_{i = 1}^{n}(\underbrace{\hat\varepsilon_i}_{y_i - \hat y_i})^2\\ SS_T &= SS_{reg} + RSS \end{aligned} \]
unde \(SS_T = \sum_{i = 1}^{n}(y_i - \bar y)^2\) reprezintă suma abaterilor pătratice totale (Total Sum of Squares), \(SS_{reg} = \sum_{i = 1}^{n}(\hat y_i - \bar y)^2\) reprezintă suma abaterilor pătratice explicate de modelul de regresie (Regression Sum of Squares) iar \(RSS = \sum_{i = 1}^{n}\hat\varepsilon_i^2\) reprezintă suma abaterilor pătratice reziduale (Residual Sum of Squares).
Coeficientul de determinare \(R^2\) este definit prin
\[ R^2 = \frac{SS_{reg}}{SS_T} = \frac{\left\lVert \hat Y - \bar y \mathbf{1}\right\rVert^2}{\left\lVert Y - \bar y \mathbf{1}\right\rVert^2} = 1 - \frac{\left\lVert \hat \varepsilon\right\rVert^2}{\left\lVert Y - \bar y \mathbf{1}\right\rVert^2} \]
și conform figurii de mai sus notăm că \(R^2 = \cos^2(\theta)\). Prin urmare dacă \(R^2 = 1\), atunci \(\theta = 0\) și \(Y\in\mathcal{M}(X)\), deci \(y_i = \beta_0 + \beta_1 x_i\), \(i\in\{1,2,\ldots,n\}\) (punctele eșantionului sunt perfect aliniate) iar dacă \(R^2 = 0\), deducem că \(\sum_{i = 1}^{n}(\hat y_i - \bar y)^2 = 0\), deci \(\hat y_i = \bar y\) (modelul liniar nu este adaptat în acest caz, nu putem explica mai bine decât media).
Propoziția 1.1 (Coeficientul de determinare) În modelul de regresie liniară simplă avem
\[ R^2 = r_{xy}^2 = r_{y\hat y}^2 \]
unde \(r_{xy}\) este coeficientul de corelație empiric dintre \(x\) și \(y\).
Demonstrație (Propoziția 1.1). Din definiția coeficientului de determinare și folosind coeficienții \(\hat\beta_0 = \bar y - \hat\beta_1 \bar x\) și \(\hat\beta_1 = \frac{\sum_{i = 1}^{n}(x_i - \bar x)(y_i - \bar y)}{\sum_{i = 1}^{n}(x_i - \bar x)^2}\) obținuți prin metoda celor mai mici pătrate avem
\[ \begin{aligned} R^2 &= \frac{\left\lVert \hat Y - \bar y \mathbf{1}\right\rVert^2}{\left\lVert Y - \bar y \mathbf{1}\right\rVert^2} = \frac{\sum_{i = 1}^{n}(\hat\beta_0 + \hat\beta_1 x_i - \bar y)^2}{\sum_{i = 1}^{n}(y_i - \bar y)^2} = \frac{\sum_{i = 1}^{n}(\bar y - \hat\beta_1 \bar x + \hat\beta_1 x_i - \bar y)^2}{\sum_{i = 1}^{n}(y_i - \bar y)^2}\\ &= \frac{\hat\beta_1^2\sum_{i = 1}^{n}(x_i - \bar x)^2}{\sum_{i = 1}^{n}(y_i - \bar y)^2} = \left(\frac{\sum_{i = 1}^{n}(x_i - \bar x)(y_i - \bar y)}{\sum_{i = 1}^{n}(x_i - \bar x)^2}\right)^2\frac{\sum_{i = 1}^{n}(x_i - \bar x)^2}{\sum_{i = 1}^{n}(y_i - \bar y)^2}\\ & = \frac{\left[\sum_{i = 1}^{n}(x_i - \bar x)(y_i - \bar y)\right]^2}{\sum_{i = 1}^{n}(x_i - \bar x)^2\sum_{i = 1}^{n}(y_i - \bar y)^2} = r_{xy}^2. \end{aligned} \]
Pentru a verifica a doua parte, \(R^2 = r_{y\hat y}^2\), să observăm că
\[ r_{y\hat y}^2 = \frac{\left[\sum_{i = 1}^{n}(\hat y_i - \bar{\hat y})(y_i - \bar y)\right]^2}{\sum_{i = 1}^{n}(\hat y_i - \bar{\hat y})^2\sum_{i = 1}^{n}(y_i - \bar y)^2} \]
iar \(\bar{\hat y} = \frac{\sum_{i = 1}^{n}\hat y_i}{n} = \hat \beta_0 + \hat\beta_1 \bar x = \bar y\), prin urmare
\[ r_{y\hat y}^2 = \frac{\left[\sum_{i = 1}^{n}(\hat y_i - \bar{y})(y_i - \bar y)\right]^2}{\sum_{i = 1}^{n}(\hat y_i - \bar{y})^2\sum_{i = 1}^{n}(y_i - \bar y)^2}. \]
De asemenea
\[ \begin{aligned} \sum_{i = 1}^{n}(\hat y_i - \bar{y})(y_i - \bar y) &= \sum_{i = 1}^{n}(\hat y_i - \bar{y})(y_i - \hat y_i + \hat y_i - \bar y) \\ &= \sum_{i = 1}^{n}(\hat y_i - \bar{y})(y_i - \hat y_i) + \sum_{i = 1}^{n}(\hat y_i - \bar{y})^2 \end{aligned} \]
și cum
\[ \begin{aligned} \sum_{i = 1}^{n}(\hat y_i - \bar{y})(y_i - \hat y_i) &= \sum_{i = 1}^{n}(\hat \beta_0 + \hat\beta_1 x_i - \bar{y})(y_i - \hat \beta_0 - \hat\beta_1 x_i) \\ &= \sum_{i = 1}^{n}(\bar y - \hat\beta_1 \bar x + \hat\beta_1 x_i - \bar{y})[(y_i - \bar y ) - \hat\beta_1 (x_i - \bar x)]\\ &= \hat\beta_1 \sum_{i = 1}^{n}(x_i - \bar x)(y_i - \bar y) - \hat\beta_1^2 \sum_{i = 1}^{n}(x_i - \bar x)^2 \\ &= \underbrace{\frac{S_{xy}}{S_{xx}}}_{\hat\beta_1}S_{xy} - \frac{S_{xy}^2}{S_{xx}^2}S_{xx} = 0 \end{aligned} \]
deducem că \(r_{y\hat y}^2 = \frac{\sum_{i = 1}^{n}(\hat y_i - \bar{y})^2}{\sum_{i = 1}^{n}(y_i - \bar y)^2} = R^2\).
Exemplul 1.1 (Prețul chiriilor în Munchen) Pentru a vedea dacă modelul de regresie liniară simplă este potrivit în contextul setului de date referitor la prețul chiriilor în Munchen, vom calcula coeficientul de determinare \(R^2\). Astfel obținem că \(R^2 =\) 0.472 ceea ce implică faptul că modelul nostru nu este foarte bine ajustat la date. Trebuie să ținem cont că modelul ales este unul simplu și de asemenea să remarcăm faptul că setul de date nu respectă întru totul ipoteza homoscedasticității erorilor, se observă că variabilitatea în prețul chiriilor crește odată cu creșterea suprafeței de locuit. Această problemă va fi tratată într-o secțiune ulterioară care face referire la validarea ipotezelor modelului propus.
În R putem calcula coeficientul de determinare folosind comanda
summary(model)$r.squared2 Inferență statistică - cazul erorilor gaussiene
Până în acest moment am determinat valorile estimatorilor coeficienților dreptei de regresie și varianțele acestor estimatori dar nu am vorbit despre modul în care aceștia sunt repartizați. Pentru a putea face acest lucru trebuie să adăugăm o ipoteză nouă asupra termenilor eroare \(\varepsilon_i\) ce face referire la modul de repartizare a acestora. Vom presupune că termenii eroare sunt normal repartizați și în acest caz ipotezele \(\mathcal{H}_1\) și \(\mathcal{H}_2\) se scriu sub forma
\[ (\mathcal{H})\left\{\begin{array}{l} \left(\mathcal{H}_{1}\right): \varepsilon_{i} \sim \mathcal{N}\left(0, \sigma^{2}\right) \\ \left(\mathcal{H}_{2}\right): \varepsilon_{i} \text { independente } \end{array}\right. \]
Prin urmare modelul de regresie liniară simplă devine un model parametric guvernat de parametrul \(\theta = (\beta_0, \beta_1, \sigma^2)\) care ia valori în \(\theta\in\Theta = \mathbb{R}\times\mathbb{R}\times\mathbb{R}_+^*\). Cum cunoaștem repartițiile termenilor eroare putem determina și repartițiile variabilelor răspuns \(y_i\),
\[ \forall i \in\{1, \ldots, n\} \quad y_{i} \sim \mathcal{N}\left(\beta_{1}+\beta_{2} x_{i}, \sigma^{2}\right), \]
iar \(y_i\) sunt independente pentru că \(\varepsilon_i\) sunt. Astfel putem calcula funcția de verosimilitate și estimatorii de verosimilitate maximă pentru \(\theta\). Funcția de verosimilitate se scrie
\[ \begin{aligned} L_n\left(\beta_{0}, \beta_{1}, \sigma^{2}\right) &=\left(\frac{1}{\sqrt{2 \pi \sigma^{2}}}\right)^{n} \exp \left[-\frac{1}{2 \sigma^{2}} \sum_{i=1}^{n}\left(y_{i}-\beta_{0}-\beta_{1} x_{i}\right)^{2}\right] \\ &=\left(\frac{1}{\sqrt{2 \pi \sigma^{2}}}\right)^{n} \exp \left[-\frac{1}{2 \sigma^{2}} RSS\left(\beta_{0}, \beta_{1}\right)\right] \end{aligned} \]
iar logaritmul acesteia devine
\[ \ell_n(\beta_{0}, \beta_{1}, \sigma^{2}) = \log L_n\left(\beta_{0}, \beta_{1}, \sigma^{2}\right) = -\frac{n}{2} \log \left(2 \pi \sigma^{2}\right)-\frac{1}{2 \sigma^{2}} RSS\left(\beta_{0}, \beta_{1}\right). \]
Pentru a determina parametrii \((\beta_{0}, \beta_{1}, \sigma^{2})\) care maximizează funcția \(\ell_n(\beta_{0}, \beta_{1}, \sigma^{2})\) să observăm pentru început că \((\beta_{0}, \beta_{1})\) intervin doar termenul \(RSS\left(\beta_{0}, \beta_{1}\right)\) care trebuie astfel minimizat (apare cu semn negativ în expresia lui \(\ell\)). Cum valorile \((\beta_{0}, \beta_{1})\) care minimizează funcția \(RSS\left(\beta_{0}, \beta_{1}\right)\) sunt date de valorile obținute prin metoda celor mai mici pătrate (vezi Propoziția 2.1 din Cursul 2) deducem că estimatorii de verosimilitate maximă pentru \((\beta_{0}, \beta_{1})\) sunt \(\left(\hat \beta_{0}, \hat \beta_{1}\right)\). Pentru a determina estimatorul de verosimilitate maximă pentru \(\sigma^2\) rămâne să găsim valoarea maximă a lui \(L\left(\hat \beta_{0}, \hat \beta_{1}, \sigma^{2}\right)\) în raport cu \(\sigma^2\). Prin derivare obținem
\[ \frac{\partial \log L_n\left(\hat{\beta}_{0}, \hat{\beta}_{1}, \sigma^{2}\right)}{\partial \sigma^{2}}=-\frac{n}{2 \sigma^{2}}+\frac{1}{2 \sigma^{4}} RSS\left(\hat{\beta}_{0}, \hat{\beta}_{1}\right)=-\frac{n}{2 \sigma^{2}}+\frac{1}{2 \sigma^{4}} \sum_{i=1}^{n}\left(y_{i}-\hat{\beta}_{0}-\hat{\beta}_{1} x_{i}\right)^{2} \]
și rezolvând ecuația \(\frac{\partial \log L_n\left(\hat{\beta}_{0}, \hat{\beta}_{1}, \sigma^{2}\right)}{\partial \sigma^{2}}= 0\) găsim
\[ \sigma^2_{MLE} = \frac{1}{n} \sum_{i=1}^{n} \hat{\varepsilon}_{i}^{2}. \]
Observăm că estimatorul de verosimilitate maximă pentru \(\sigma^2\) este deplasat, \(\mathbb{E}\left[\sigma^2_{MLE}\right] = \frac{n-2}{n}\sigma^2\), și diferă de estimatorul \(\hat\sigma^2\) văzut anterior (cf. Propoziția 2.6 din Secțiunea Valori reziduale).
Pentru o mai bună înțelegere a conceptelor și a noțiunilor ce urmează a fi prezentate în cadrul acestei secțiuni puteți consulta Anexele.
2.1 Repartițiile estimatorilor și regiuni de încredere
Pentru a ușura scrierea rezultatelor din această secțiune vom folosi următoarele notații (a se vedea Propoziția 2.3 din Secțiunea Metoda celor mai mici pătrate):
\[ \begin{aligned} \sigma_{\hat{\beta}_{0}}^{2} &=\sigma^{2}\left(\frac{\sum x_{i}^{2}}{n \sum\left(x_{i}-\bar{x}\right)^{2}}\right), & \hat{\sigma}_{\hat{\beta}_{0}}^{2}=\hat{\sigma}^{2}\left(\frac{\sum x_{i}^{2}}{n \sum\left(x_{i}-\bar{x}\right)^{2}}\right) \\ \sigma_{\hat{\beta}_{1}}^{2} &=\frac{\sigma^{2}}{\sum\left(x_{i}-\bar{x}\right)^{2}}, & \hat{\sigma}_{\hat{\beta}_{1}}^{2}=\frac{\hat{\sigma}^{2}}{\sum\left(x_{i}-\bar{x}\right)^{2}} \end{aligned} \]
unde \(\hat{\sigma}^{2}=\frac{1}{n-2} \sum_{i = 1}^n \hat{\varepsilon}_{i}^{2}\). Observăm că \(\sigma_{\hat{\beta}_{0}}^{2}, \sigma_{\hat{\beta}_{1}}^{2}\) sunt varianțele (teoretice) estimatorilor obținuți prin metoda celor mai mici pătrate iar \(\hat{\sigma}_{\hat{\beta}_{0}}^{2}, \hat{\sigma}_{\hat{\beta}_{1}}^{2}\) sunt estimatorii acestora obținuți prin înlocuirea lui \(\sigma^2\) cu estimatorul său nedeplasat \(\hat \sigma^2\).
Propoziția 2.1 (Repartițiile estimatorilor când varianța este cunoscută) Repartițiile estimatorilor obținuți prin metoda celor mai mici pătrate atunci când varianța \(\sigma^2\) este cunoscută sunt:
- \(\hat{\beta}_{j} \sim \mathcal{N}\left(\beta_{j}, \sigma_{\hat{\beta}_{j}}^{2}\right)\) pentru \(j=0,1\)
- \(\hat{\beta}=\left(\begin{array}{c}\hat{\beta}_{0} \\ \hat{\beta}_{1}\end{array}\right) \sim \mathcal{N}\left(\beta, \sigma^{2} V\right), \beta=\left(\begin{array}{c}\beta_{0} \\ \beta_{1}\end{array}\right)\) și \(V=\frac{1}{\sum\left(x_{i}-\bar{x}\right)^{2}}\left(\begin{array}{cc}\sum x_{i}^{2} / n & -\bar{x} \\ -\bar{x} & 1\end{array}\right)\)
- \(\frac{(n-2)}{\sigma^{2}} \hat{\sigma}^{2}\) este repartizată \(\chi^{2}\) cu \(n-2\) grade de libertate, i.e. \(\frac{(n-2)}{\sigma^{2}} \hat{\sigma}^{2} \sim \chi_{n-2}^{2}\)
- \(\left(\hat{\beta}_{0}, \hat{\beta}_{1}\right)\) și \(\hat{\sigma}^{2}\) sunt independente.
Demonstrație (Propoziția 2.1). Demonstrația acestui rezultat și a celor din Propoziția 2.2 și Propoziția 2.3 se vor face în contextul general al regresiei liniare multiple și vor fi omise acum.
Cum, în general, nu cunoaștem valoarea lui \(\sigma^2\) aceasta va fi estimată prin intermediul lui \(\hat\sigma^2\). În acest context repartițiile estimatorilor obținuți prin metoda celor mai mici pătrate se vor modifica astfel:
Propoziția 2.2 (Repartițiile estimatorilor când varianța este necunoscută) Repartițiile estimatorilor obținuți prin metoda celor mai mici pătrate atunci când varianța \(\sigma^2\) nu este cunoscută verifică:
\[ \frac{\hat\beta_j - \beta_j}{\hat\sigma_{\hat \beta_j}}\sim t_{n-2}, \]
pentru \(j=0,1\), unde \(t_{n - 2}\) este repartiția Student cu \(n-2\) grade de libertate și respectiv
\[ \frac{1}{2 \hat{\sigma}^{2}}(\hat{\beta}-\beta)^{\intercal} V^{-1}(\hat{\beta}-\beta) \sim F_{2, n-2}, \]
unde \(F_{2, n-2}\) este repartiția Fisher-Snedecor cu \(2\) grade de libertate la numărător și \(n-2\) grade de libertate la numitor.
Acest rezultat ne permite să construim intervale și regiuni de încredere pentru estimatorii noștri. Următoarea propoziție prezintă intervalele și regiunile de încredere la un nivel de semnificație \(1-\alpha\):
Propoziția 2.3 (Intervale și regiuni de încredere pentru coeficienți) Avem următoarele intervale și regiuni de încredere pentru estimatorii obținuți prin metoda celor mai mici pătrate. Un interval de încredere bilateral de nivel \(1-\alpha\) pentru \(\beta_j\), \(j=0,1\) este
\[ \left[\hat{\beta}_{j}-t_{n-2}(1-\alpha / 2) \hat{\sigma}_{\hat{\beta}_{j}}, \hat{\beta}_{j}+t_{n-2}(1-\alpha / 2) \hat{\sigma}_{\hat{\beta}_{j}}\right] \]
unde \(t_{n-2}(1-\alpha / 2)\) este cuantila de ordin \(1-\alpha/2\) a repartiției Student \(t_{n-2}\).
O regiune de încredere de nivel \(1-\alpha\) pentru parametrii \(\beta\) este dată de
\[ \begin{aligned} RC(\beta_0, \beta_1) &= \left\{\frac{1}{2 \hat{\sigma}^{2}}\left[n\left(\hat{\beta}_{0}-\beta_{0}\right)^{2}+2 n \bar{x}\left(\hat{\beta}_{0}-\beta_{0}\right)\left(\hat{\beta}_{1}-\beta_{1}\right)+\right.\right. \\ &\quad \left.\left. +\sum x_{i}^{2}\left(\hat{\beta}_{1}-\beta_{1}\right)^{2}\right] \leq f_{(2, n-2)}(1-\alpha)\right\} \end{aligned} \] unde \(f_{(2, n-2)}(1-\alpha)\) este cuantila de ordin \(1-\alpha\) din repartiția Fisher-Snedecor \(F_{2, n-2}\).
Un interval de încredere de nivel \(1-\alpha\) pentru \(\sigma^2\) este
\[ \left[\frac{(n-2) \hat{\sigma}^{2}}{\chi^2_{n-2}(1-\alpha / 2)}, \frac{(n-2) \hat{\sigma}^{2}}{\chi^2_{n-2}(\alpha / 2)}\right] \]
unde \(\chi^2_{n-2}(\alpha)\) este cuantila de ordin \(\alpha\) a repartiției \(\chi^2_{n-2}\).
Regiunea de încredere din propoziția anterioară este o elipsă și face referire la parametrii de regresie \(\beta = (\beta_0, \beta_1)^\intercal\) simultan luând în calcul și corelația dintre aceștia, spre deosebire de intervalele de încredere corespunzătoare.
Exemplul 2.1 (Prețul chiriilor în Munchen) Raportându-ne la setul de date referitor la prețul chiriilor în Munchen avem următoarele intervale de încredere:
- pentru \(\hat\beta_0\)
\[ \left[\hat{\beta}_{0}-t_{n-2}(1-\alpha / 2) \hat{\sigma}_{\hat{\beta}_{0}}, \hat{\beta}_{0}+t_{n-2}(1-\alpha / 2) \hat{\sigma}_{\hat{\beta}_{0}}\right] = [102.221,\, 158.887] \]
Observăm că intervalul de încredere pentru \(\hat{\beta}_{0}\) este destul de larg (lungime 56.665), ceea ce este justificat dat fiind variabilitatea erorilor (\(\hat\sigma =\) 123.455) dar în special pentru că suprafețele sunt mai mari de zero.
- pentru \(\hat \beta_1\)
\[ \left[\hat{\beta}_{1}-t_{n-2}(1-\alpha / 2) \hat{\sigma}_{\hat{\beta}_{1}}, \hat{\beta}_{1}+t_{n-2}(1-\alpha / 2) \hat{\sigma}_{\hat{\beta}_{1}}\right] = [5.153,\, 5.999] \]
Pentru \(\hat \beta_1\) intervalul de încredere este mult mai mic ceea ce arată că avem un efect al suprafeței asupra prețului net al apartamentelor. În R putem determina intervalele de încredere folosind funcția confint():
confint(model)Referitor la regiunea de încredere \(RC(\beta_0, \beta_1)\) în figura de mai jos (realizată prin intermediul pachetului ellipse sau a pachetului car) este ilustrată regiunea \(RC(\beta_0, \beta_1)\) împreună cu intervalele de încredere asociate pentru fiecare parametru:
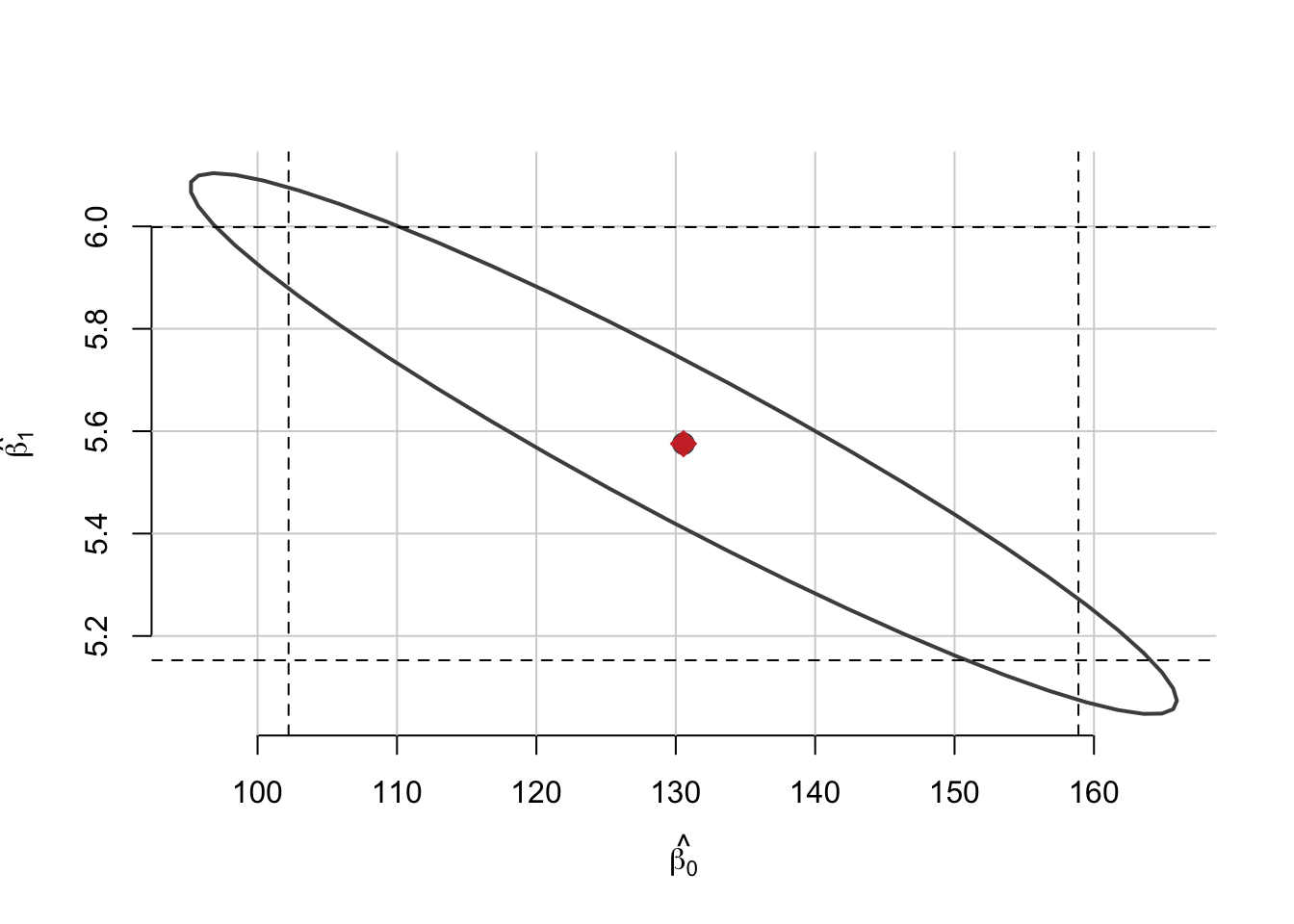
Se poate observa că regiunea de încredere \(RC(\beta_0, \beta_1)\) evidențiază corelația dintre cei doi parametrii.
Arată codul R din exemplul de mai sus
#-----------------------------
# Prețul chiriilor în Munchen
#-----------------------------
munich <- read.table("dataIn/rent99.raw", header = TRUE)
munich_sub <- munich %>%
filter(yearc > 1966, location == 1)
munich_sub_model1 <- lm(rent ~ area,
data = munich_sub)
# confidence intervals
cfint_munich <- confint(munich_sub_model1)
par(bty = "n")
# trasam regiunea de incredere
confidenceEllipse(munich_sub_model1,
xlab = expression(hat(beta[0])),
ylab = expression(hat(beta[1])),
col = "grey30")
points(coef(munich_sub_model1)[1], coef(munich_sub_model1)[2],
pch = 18, col = "brown3",
cex = 2)
# trasam intervalele de incredere
abline(v = confint(munich_sub_model1)[1,], lty = 2)
abline(h = confint(munich_sub_model1)[2,], lty = 2)2.2 Predicție
Vom începe prin a da intervalul de încredere pentru răspunsul mediu care reiese din prima parte din Propoziția 2.7:
Propoziția 2.4 (Interval de încredere pentru răspunsul mediu) Intervalul de încredere pentru \(\mathbb{E}[y_i | x_i] = \beta_0 + \beta_1 x_i\) este
\[ \left[\hat{y}_{i} - t_{n-2}(1-\alpha / 2) \hat{\sigma} \sqrt{\frac{1}{n}+\frac{\left(x_{i}-\bar{x}\right)^{2}}{\sum\left(x_{j}-\bar{x}\right)^{2}}}, \hat{y}_{i} + t_{n-2}(1-\alpha / 2) \hat{\sigma} \sqrt{\frac{1}{n}+\frac{\left(x_{i}-\bar{x}\right)^{2}}{\sum\left(x_{j}-\bar{x}\right)^{2}}}\right] \]
unde \(t_{n-2}(1-\alpha / 2)\) este cuantila de ordin \(1-\alpha/2\) a repartiției Student \(t_{n-2}\).
Atunci când vorbim de predicție vom dori să determinăm un interval de predicție pentru valoarea rezultată din model. Se numește interval de predicție de nivel \(1-\alpha\) pentru o variabilă aleatoare neobservată \(Y\) date fiind datele \(X\) intervalul aleator \(\left[A(X), B(X)\right]\) care verifică
\[ \mathbb{P}_{\theta}\left(A(X)\leq Y\leq B(X)\right)\geq 1-\alpha, \quad\forall \theta. \]
Se observă similaritatea dintre un interval de predicție și un interval de încredere, diferența fiind dată de faptul că un interval de predicție este un interval pentru o variabilă aleatoare și nu pentru un parametru (care este o constantă). Având în vedere variabilitatea v.a. \(Y\) este de așteptat ca intervalul de predicție să fie mai mare decât cel de încredere la același nivel de încredere.
În cazul modelului gaussian (termenii eroare sunt repartizați normal), observăm, ținând cont de liniaritatea lui \(\hat y_{n+1}\) în \(\hat\beta_0\), \(\hat\beta_1\) și \(\varepsilon_{n+1}\), că
\[ y_{n+1}-\hat{y}_{n+1} \sim \mathcal{N}\left(0, \sigma^{2}\left(1+\frac{1}{n}+\frac{\left(x_{n+1}-\bar{x}\right)^{2}}{\sum\left(x_{i}-\bar{x}\right)^{2}}\right)\right) \]
și cum varianța \(\sigma^2\) nu este cunoscută în general aceasta este estimată prin \(\hat\sigma^2\). De asemenea, notând că variabilele aleatoare \(y_{n+1}-\hat{y}_{n+1}\) și \(\frac{(n-2)\hat\sigma^2}{\sigma^2}\) sunt independente avem următorul rezultat referitor la intervalul de predicție.
Propoziția 2.5 (Interval de predicție) Avem că \[ \frac{y_{n+1}-\hat{y}_{n+1}}{\hat{\sigma} \sqrt{1+\frac{1}{n}+\frac{\left(x_{n+1}-\bar{x}\right)^{2}}{\sum\left(x_{i}-\bar{x}\right)^{2}}}} \sim t_{n-2} \]
ceea ce conduce la un interval de predicție de nivel \(1-\alpha\) pentru \(y_{n+1}\)
\[ \left[\hat{y}_{n+1} \pm t_{n-2}(1-\alpha / 2) \hat{\sigma} \sqrt{1+\frac{1}{n}+\frac{\left(x_{n+1}-\bar{x}\right)^{2}}{\sum\left(x_{i}-\bar{x}\right)^{2}}}\right], \]
unde \(t_{n-2}(1-\alpha / 2)\) este cuantila de ordin \(1-\alpha/2\) a repartiției Student \(t_{n-2}\).
Observăm că pe măsură ce punctul de prezis admite o abscisă \(x_{n+1}\) mai depărtată de media \(\bar x\) cu atât intervalul de predicție este mai mare. Mai mult, putem constata că atunci când \(x_{n+1}\) variază, curba descrisă de capetele intervalului este o hiperbolă de axe \(x = \bar x\) și \(y = \hat\beta_0 + \hat\beta_1 x\). Pentru a observa acest lucru putem face schimbarea de variabile \(u = x - \bar x\) și \(v = y - \hat\beta_0 + \hat\beta_1 x)\) de unde concluzionăm că un punct de coordonate \((u,v)\) se află în regiunea de mai sus dacă
\[ \frac{u^2}{a^2} - \frac{v^2}{b^2}\leq 1 \]
unde \(a^2 = \left(1+\frac{1}{n}\right) \sum\left(x_{i}-\bar{x}\right)^{2}\) și \(b^2 = \left(1+\frac{1}{n}\right)\left(t_{n-2}(1-\alpha / 2) \hat{\sigma}\right)^{2}\). În mod similar se poate arăta și că forma curbei descrisă de capetele intervalului de încredere a răspunsului mediu este tot o hiperbolă.
De asemenea, sunt multe circumstanțele în care am dori să avem intervalele de încredere pentru răspunsul mediu respectiv intervalele de predicție în mai mult de un punct, prin urmare ne aflăm în cadrul unei probleme de inferență simultană. O soluție la această problemă, în cazul în care avem \(m\) puncte, este dată de inegalitatea lui Bonferroni (\(\mathbb{P}\left(\cup_{i=1}^n A_i\right)\leq \sum_{i=1}^{n}\mathbb{P}(A_i)\)) care conduce la marginea
\[ \hat{y}_{i} - t_{n-2}\left(1-\frac{\alpha}{2m}\right) \hat{\sigma} \sqrt{\frac{1}{n}+\frac{\left(x_{i}-\bar{x}\right)^{2}}{\sum\left(x_{j}-\bar{x}\right)^{2}}} \leq \beta_0 + \beta_1 x_{i}\leq \hat{y}_{i} + t_{n-2}\left(1-\frac{\alpha}{2m}\right) \hat{\sigma} \sqrt{\frac{1}{n}+\frac{\left(x_{i}-\bar{x}\right)^{2}}{\sum\left(x_{j}-\bar{x}\right)^{2}}} \]
pentru răspunsul mediu \(\mathbb{E}[y_{i}|x_{i}] = \beta_0 + \beta_1 x_{i}\), \(i\in\{n+1,\ldots, n+m\}\), iar
\[ \hat{y}_{i} - t_{n-2}\left(1-\frac{\alpha}{2m}\right) \hat{\sigma} \sqrt{1 + \frac{1}{n}+\frac{\left(x_{i}-\bar{x}\right)^{2}}{\sum\left(x_{j}-\bar{x}\right)^{2}}} \leq y_{i}\leq \hat{y}_{i} + t_{n-2}\left(1-\frac{\alpha}{2m}\right) \hat{\sigma} \sqrt{1 + \frac{1}{n}+\frac{\left(x_{i}-\bar{x}\right)^{2}}{\sum\left(x_{j}-\bar{x}\right)^{2}}} \]
pentru valoarea prezisă \(y_i\), \(i\in\{n+1,\ldots, n+m\}\) conform modelului, unde \(t_{n-2}(1-\alpha / {2m})\) este cuantila de ordin \(1-\alpha/{2m}\) a repartiției Student \(t_{n-2}\). Marginea de mai sus este adevărată pentru \(m\) puncte dar dacă am dori să găsim o relație similară pentru orice \(x\) atunci această metodă nu ar mai putea fi aplicată. Scheffe a propus următoarea margine numită și banda lui Scheffe (o demonstrație a acestui rezultat se poate găsi de exemplu în (Casella and Berger 2001)):
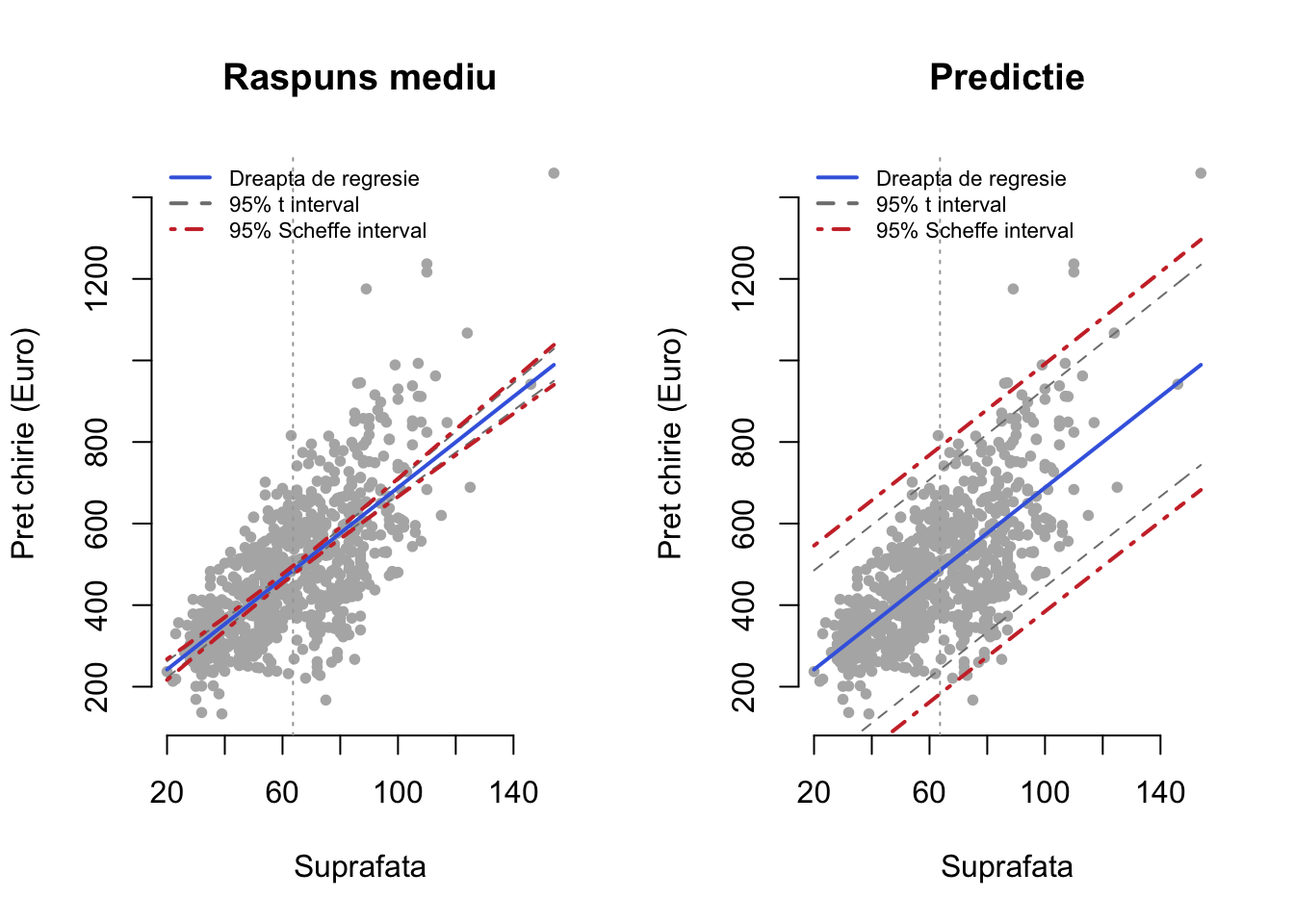
Propoziția 2.6 (Banda lui Scheffe) În contextul problemei de regresie liniare simple cu erori repartizare gaussian are loc următoarea relație, pentru răspunsul mediu
\[ \mathbb{P}\left(\hat{y} - M_{\alpha} \hat{\sigma} \sqrt{\frac{1}{n}+\frac{\left(x-\bar{x}\right)^{2}}{\sum\left(x_{j}-\bar{x}\right)^{2}}} \leq \beta_0 + \beta_1 x\leq \hat{y} + M_{\alpha} \hat{\sigma} \sqrt{\frac{1}{n}+\frac{\left(x-\bar{x}\right)^{2}}{\sum\left(x_{j}-\bar{x}\right)^{2}}}, \quad \forall x\right) \geq 1-\alpha \]
și pentru valorile prezise
\[ \mathbb{P}\left(\hat{y} - M_{\alpha} \hat{\sigma} \sqrt{1+\frac{1}{n}+\frac{\left(x-\bar{x}\right)^{2}}{\sum\left(x_{j}-\bar{x}\right)^{2}}} \leq y\leq \hat{y} + M_{\alpha} \hat{\sigma} \sqrt{1+\frac{1}{n}+\frac{\left(x-\bar{x}\right)^{2}}{\sum\left(x_{j}-\bar{x}\right)^{2}}}, \quad \forall x\right) \geq 1-\alpha \]
unde \(M_{\alpha} = \sqrt{2F_{2, n-2}(1-\alpha)}\) iar \(F_{2, n-2}(1-\alpha)\) este cuantila de ordin \(1-\alpha\) a repartiției Fisher-Snedecor \(F_{2, n-2}\).
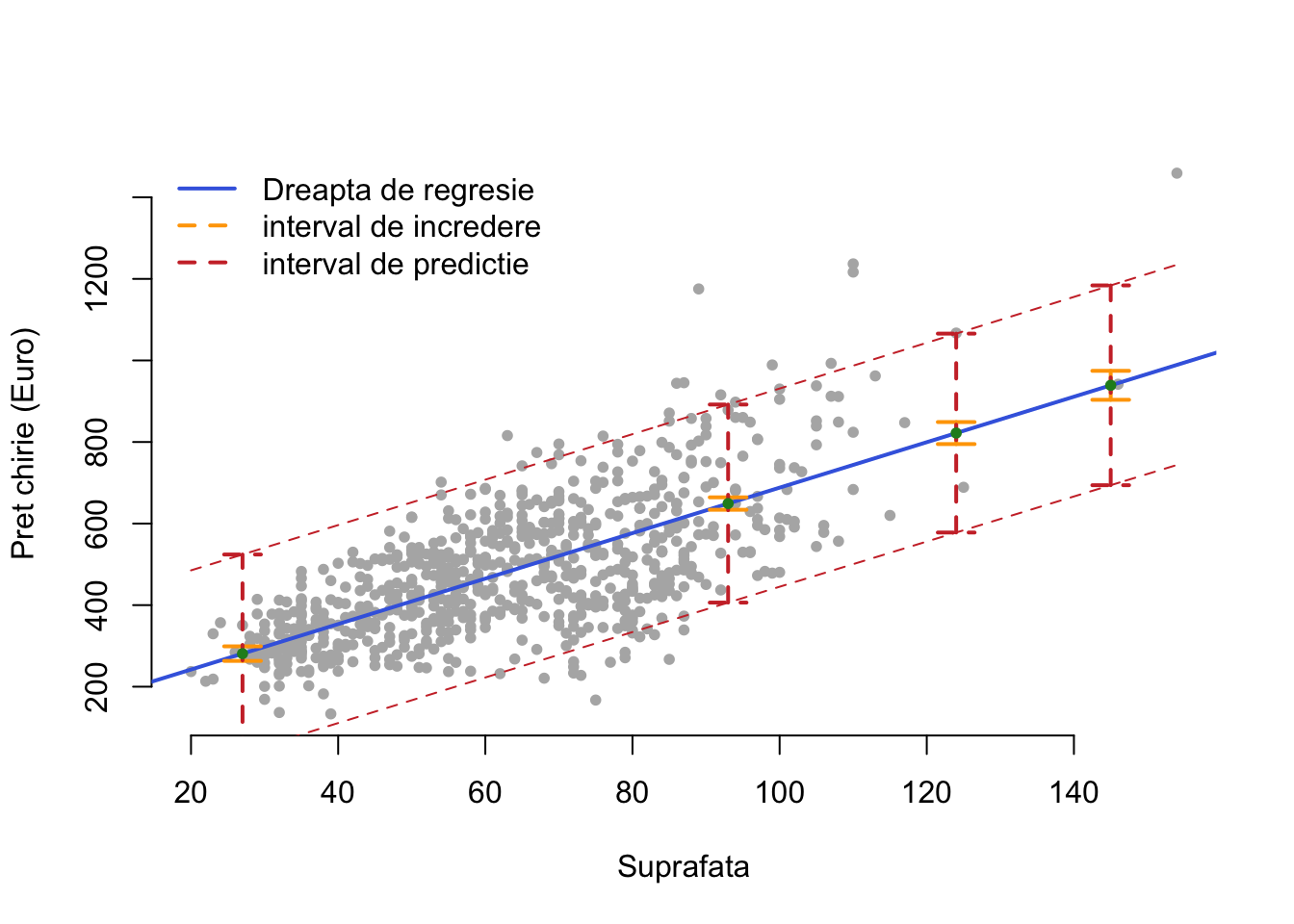
Exemplul 2.2 (Prețul chiriilor în Munchen) Revenind la exemplul modelului de regresie liniară simplă introdus pe setul de date Munchen să presupunem că ne interesăm la prețul de închiriere al apartamentelor care au suprafața de \(27\), \(93\), \(124\) și respectiv \(145\) de metrii pătrați. Tabelul 2.1 de mai jos prezintă valorile prezise și intervalele de încredere (stânga) respectiv de predicție (dreapta) pentru noile suprafețe. Pentru calcularea în R a acestor intervale se utilizează funcția predict() cu opțiunea interval = "confidence" pentru intervalul de încredere și respectiv interval = "prediction" pentru intervalul de predicție.
| Suprafata | Valori prezise | CI_Inf | CI_Sup | Pred_Inf | Pred_Sup |
|---|---|---|---|---|---|
| 27 | 281.09 | 263.25 | 298.94 | 38.08 | 524.11 |
| 93 | 649.08 | 633.84 | 664.32 | 406.24 | 891.92 |
| 124 | 821.92 | 794.91 | 848.94 | 578.06 | 1065.78 |
| 145 | 939.01 | 903.48 | 974.54 | 694.06 | 1183.96 |
În figura de mai jos avem ilustrate intervalele de încredere pentru răspunsul mediu (cu portacaliu) și respectiv intervalele de predicție (cu roșu) pentru cele patru valori ale variabilei explicative. Se poate observa diferența mare între incertitudinea dată de cele două intervale.
Dacă facem referire la răspunsul mediu și respectiv la valorile prezise atunci putem trasa banda de încredere corespunzătoare intervalelor de încredere din Propoziția 2.4 și Propoziția 2.5, respectiv banda lui Scheffe din Propoziția 2.6:
Arată codul R din exemplul de mai sus
#-----------------------------
# Prețul chiriilor în Munchen
#-----------------------------
alpha <- 0.05
area0 <- c(27, 93, 124, 145)
p.conf <- predict(munich_sub_model1,
data.frame(area = area0), se = T,
interval = "confidence")
tab1 <- cbind(area0, p.conf$fit)
p.pred <- predict(munich_sub_model1,
data.frame(area = area0), se = T,
interval = "prediction")
tab2 <- cbind(tab1, p.pred$fit[,2:3]) %>%
round(., 2)
# Intervalele de încredere pentru răspunsul mediu și intervalele de predicție pentru cele patru valori ale variabilei explicative
alpha <- 0.05
area0 <- c(27, 93, 124, 145)
p.conf <- predict(munich_sub_model1,
data.frame(area = area0), se = T,
interval = "confidence")
p.pred <- predict(munich_sub_model1,
data.frame(area = area0), se = T,
interval = "prediction")
area_p <- seq(min(munich_sub$area), max(munich_sub$area), 0.5)
p.pred_h <- predict(munich_sub_model1,
data.frame(area = area_p),
se = T,
interval = "prediction")
# diagrama de imprastiesre
plot(munich_sub$area, munich_sub$rent,
col = "grey70", pch = 20,
xlab = "Suprafata",
ylab = "Pret chirie (Euro)",
bty = "n")
lines(area_p, p.pred_h$fit[,2],
col = "brown3",
lty = 2)
lines(area_p, p.pred_h$fit[,3],
col = "brown3",
lty = 2)
# dreapta de regresie
abline(munich_sub_model1$coefficients, col = "royalblue", lwd = 2)
#intervalele de incredere
segments(x0 = area0, y0 = p.conf$fit[,2], x1 = area0, y1 = p.conf$fit[,3],
col = "orange", lty = 1, lwd = 2)
segments(x0 = area0-2.5, y0 = p.conf$fit[,2], x1 = area0+2.5, y1 = p.conf$fit[,2],
col = "orange", lty = 1, lwd = 2)
segments(x0 = area0-2.5, y0 = p.conf$fit[,3], x1 = area0+2.5, y1 = p.conf$fit[,3],
col = "orange", lty = 1, lwd = 2)
#intervalele de predictie
segments(x0 = area0, y0 = p.pred$fit[,2], x1 = area0, y1 = p.pred$fit[,3],
col = "brown3", lty = 2, lwd = 2)
segments(x0 = area0-2.5, y0 = p.pred$fit[,2], x1 = area0+2.5, y1 = p.pred$fit[,2],
col = "brown3", lty = 2, lwd = 2)
segments(x0 = area0-2.5, y0 = p.pred$fit[,3], x1 = area0+2.5, y1 = p.pred$fit[,3],
col = "brown3", lty = 2, lwd = 2)
# valoarea prezisa
points(area0, p.conf$fit[,1],
col = "forestgreen",
pch = 20)
legend("topleft",
legend = c("Dreapta de regresie",
"interval de incredere",
"interval de predictie"),
lwd = c(2, 2, 2),
col = c("royalblue", "orange", "brown3"),
lty = c(1, 2, 2),
bty = "n")
# Banda de încredere și banda lui Scheffe pentru răspunsul mediu
alpha <- 0.05
n <- length(munich_sub$area)
g <- seq(min(munich_sub$area), max(munich_sub$area), 0.5)
p <- predict(munich_sub_model1, data.frame(area = g), se = T, interval = "confidence")
p.pred <- predict(munich_sub_model1, data.frame(area = g), se = T, interval = "prediction")
par(mfrow = c(1, 2))
# Plot 1: raspuns mediu
plot(munich_sub$area, munich_sub$rent,
col = "grey70", pch = 20,
xlab = "Suprafata",
ylab = "Pret chirie (Euro)",
main = "Raspuns mediu",
bty = "n")
matlines(g, p$fit, type = "l", lty = c(1,2,2),
lwd = c(2,1,1),
col = c("royalblue", "grey50", "grey50"))
abline(v = mean(munich_sub$area), lty = 3, col = "grey65")
# Scheffe's bounds
M <- sqrt(2*qf(1-alpha, 2, n - 2))
beta <- coefficients(munich_sub_model1)
sigma_hat <- sigmaHat(munich_sub_model1)
s_xx <- (n-1)*var(munich_sub$area)
lw_scheffe <- beta[1] + beta[2]*g - M*sigma_hat*sqrt(1/n+(g-mean(munich_sub$area))^2/s_xx)
up_scheffe <- beta[1] + beta[2]*g + M*sigma_hat*sqrt(1/n+(g-mean(munich_sub$area))^2/s_xx)
lines(g, lw_scheffe,
lty = 4,
lwd = 2,
col = "brown3")
lines(g, up_scheffe,
lty = 4,
lwd = 2,
col = "brown3")
legend("topleft", legend = c("Dreapta de regresie", "95% t interval",
"95% Scheffe interval"),
lwd = c(2, 2, 2),
col = c("royalblue", "grey50", "brown3"),
lty = c(1, 2, 4),
bty = "n", cex = 0.7)
# Plot 2: predictie
plot(munich_sub$area, munich_sub$rent,
col = "grey70", pch = 20,
xlab = "Suprafata",
ylab = "Pret chirie (Euro)",
main = "Predictie",
bty = "n")
matlines(g, p.pred$fit, type = "l", lty = c(1,2,2),
lwd = c(2,1,1),
col = c("royalblue", "grey50", "grey50"))
abline(v = mean(munich_sub$area), lty = 3, col = "grey65")
# Scheffe's bounds
M <- sqrt(2*qf(1-alpha, 2, n - 2))
beta <- coefficients(munich_sub_model1)
sigma_hat <- sigmaHat(munich_sub_model1)
s_xx <- (n-1)*var(munich_sub$area)
lw_scheffe2 <- beta[1] + beta[2]*g - M*sigma_hat*sqrt(1 + 1/n+(g-mean(munich_sub$area))^2/s_xx)
up_scheffe2 <- beta[1] + beta[2]*g + M*sigma_hat*sqrt(1 + 1/n+(g-mean(munich_sub$area))^2/s_xx)
lines(g, lw_scheffe2,
lty = 4,
lwd = 2,
col = "brown3")
lines(g, up_scheffe2,
lty = 4,
lwd = 2,
col = "brown3")
legend("topleft", legend = c("Dreapta de regresie", "95% t interval",
"95% Scheffe interval"),
lwd = c(2, 2, 2),
col = c("royalblue", "grey50", "brown3"),
lty = c(1, 2, 4),
bty = "n", cex = 0.7)3 Exerciții
Exercițiul 3.1 Scrieți codul R care să permită trasarea figurilor de mai sus pentru exemplul care face referire la înălțimea arborilor de eucalipt.
Exercițiul 3.2 (Înălțimea arborilor) Dorim să exprimăm înălțimea \(y\) (măsurată în picioare) a unui arbore în funcție de diametrul său \(x\) (exprimat în centimetri) la înălțimea de 1m și jumătate de la sol. Pentru aceasta dispunem de 20 de măsurători \((x_i,y_i)=\)(diametru, înălțime) și în urma calculelor am obținut rezultatele următoare: \(\bar x = 4.53\), \(\bar y = 8.65\) și
\[ \frac{1}{20}\sum_{i = 1}^{20}(x_i - \bar x)^2 = 10.97 \quad \frac{1}{20}\sum_{i = 1}^{20}(y_i - \bar y)^2 = 2.24 \quad \frac{1}{20}\sum_{i = 1}^{20}(x_i - \bar x)(y_i - \bar y) = 3.77. \]
Notăm cu \(y = \hat \beta_0 + \hat \beta_1 x\) dreapta de regresie. Calculați coeficienții \(\hat \beta_0\) și \(\hat \beta_1\).
Dați și calculați o măsură care descrie calitatea concordanței datelor cu modelul propus.
Să presupunem că abaterile standard pentru estimatorii \(\hat \beta_0\) și \(\hat \beta_1\) sunt \(\hat \sigma_0 = 1.62\) și respectiv \(\hat \sigma_1 = 0.05\). Presupunem că erorile \(\varepsilon_i\) sunt variabile aleatoare independente repartizare normal de medie \(0\) și varianțe egale. Vrem să testăm ipotezele \(H_0:\, \beta_j = 0\) versus \(H_1:\, \beta_j \neq 0\) pentru \(j = 0,1\). De ce acest test este interesant în contextul problemei noastre?
Exercițiul 3.3 (Intervale/Regiuni de încredere) Se ia în considerare modelul de regresie liniară simplă \(y=\beta_{0}+\beta_{1} x+\epsilon\). Fie un eșantion \(\left(x_{i}, y_{i}\right)_{1 \leq i \leq 100}\) și considerăm valorile statisticilor
\[ \sum_{i=1}^{100} x_{i}=0, \quad \sum_{i=1}^{100} x_{i}^{2}=400, \quad \sum_{i=1}^{100} x_{i} y_{i}=100, \quad \sum_{i=1}^{100} y_{i}=100, \quad \hat{\sigma}^{2}=1 . \]
Exprimați intervalele de încredere de nivel de încredere de \(95\%\) pentru \(\beta_{0}\) și \(\beta_{1}\).
Dați ecuația regiunii de încredere de nivel de încredere de \(95\%\) pentru \(\left(\beta_{0}, \beta_{1}\right)\). (Reamintim: mulțimea punctelor \((x, y)\) astfel încât \(\frac{\left(x-x_{0}\right)^{2}}{a^{2}}+\frac{\left(y-y_{0}\right)^{2}}{b^{2}} \leq 1\) este interiorul unei elipse cu centrul în \(\left(x_{0}, y_{0}\right)\), ale cărei axe sunt paralele cu cele ale absciselor și ordonatelor, și cu vârfurile \((x_{0} \pm a, y_0)\) și \(\left(x_0, y_{0} \pm b\right)\).)
Reprezentați rezultatele obținute pe același grafic.
Exercițiul 3.4 (Regresie liniară simplă II) Să presupunem că observațiile \((x_i,Y_i)\), \(i=1,\ldots,n\) sunt făcute după modelul \(Y_i = \alpha + \beta x_i + \varepsilon_i\), unde \(x_1,\ldots,x_n\) sunt constante iar erorile \(\varepsilon_i\) sunt variabile aleatoare centrate, necorelate și de varianță \(\sigma^2\). Presupunem că \(\varepsilon_1,\ldots,\varepsilon_n\) sunt i.i.d. repartizate \(\mathcal{N}(0,\sigma^2)\) și că modelul este apoi reparametrizat astfel
\[ Y_i = \alpha' + \beta' (x_i-\bar{x}) + \varepsilon_i. \]
Arătați că \(\hat{\beta}' = \hat{\beta}\) și că \(\hat{\alpha}' \neq \hat{\alpha}\) unde \(\hat{\alpha}\) și \(\hat{\beta}\) estimatorii de verosimilate maximă a lui \(\alpha\) și \(\beta\), iar \(\hat{\alpha}'\) și \(\hat{\beta}'\) estimatorii de verosimilitate maximă a lui \(\alpha'\) și \(\beta'\).
Arătați că \(\hat{\alpha}'\) și \(\hat{\beta}'\) sunt necorelate, prin urmare sub ipoteza de normalitate sunt independente.
Exercițiul 3.5 (Regresie liniară simplă III) Se consideră următorul model
\[ Y_{i}=a+b t_{i}+\varepsilon_{i}, \quad 1 \leq i \leq n, \]
unde variabilele aleatoare \(\varepsilon_{i}\) sunt i.i.d. \(\mathcal{N}\left(0, \sigma^{2}\right)\), numerele reale \(\left(t_{i}\right)_{1 \leq i \leq n}\) sunt cunoscute și \(a, b, \sigma^{2}\) sunt trei parametri reali necunoscuți. Presupunem că \(\sum_{i=1}^{n} t_{i}=0\) și notăm
\[ \bar{Y}=\frac{1}{n} \sum_{i=1}^{n} Y_{i}, \quad v_{t}=\frac{1}{n} \sum_{i=1}^{n} t_{i}^{2}>0, \quad v_{Y}=\frac{1}{n} \sum_{i=1}^{n} Y_{i}^{2}-\bar{Y}^{2} \quad \text { și } \quad \rho=\frac{1}{n} \sum_{i=1}^{n} Y_{i} t_{i} . \]
Precizați condițiile de identifiabilitate ale modelului.
Calculați estimatorii celor mai mici pătrate \(\widehat{a}\), \(\widehat{b}\) și \(\widehat{\sigma}^{2}\) pentru \(a\), \(b\) și \(\sigma^{2}\) în funcție de \(\bar{Y}\), \(v_{t}\), \(v_{Y}\) și \(\rho\). Care este repartiția lor comună?
Fie \(\alpha \in(0,1)\). Dați un interval de încredere de nivel \(1-\alpha\) pentru fiecare dintre parametrii \(a\) și \(b\). Deduceți un dreptunghi de încredere de nivel \(95\%\) pentru parametrul \((a, b)\).
Construiți o elipsă de încredere \(\mathcal{E}\) de nivel \(95\%\) pentru parametrul \((a, b)\).
Dați un interval de încredere pentru \(5a-8b\), de nivel \(95\%\), când \(n=18\).
Testați ipoteza \(H_{0}:\,a=b\) împotriva \(H_{1}:\,a \neq b\) la un nivel de \(1\%\) când \(n=22\).
Notăm \(\Theta_{0}=\left\{(a, b) \in \mathbb{R}^{2}: a=b\right\}\). Demonstrați că testul care constă în respingerea lui \(H_{0}\) dacă \(\Theta_{0} \cap \mathcal{E}=\emptyset\) este de nivel \(\alpha \in (0,1)\) atunci când \(\mathcal{E}\) este o elipsă de încredere de nivel \(1-\alpha\). Comparați acest test cu cel din întrebarea anterioară.
Se ia în considerare o nouă valoare \(t^{\prime}=2\). Care este valoarea prevăzută \(\widehat{Y}^{(p)}\) pentru răspunsul asociat \(Y\)? Dați un interval de previziune de nivel \(98\%\) pentru \(Y\).
Exercițiul 3.6 (Model gaussian) Se consideră modelul
\[ Y_{i}=m+\sigma \varepsilon_{i}, \quad 1 \leq i \leq n \]
unde v.a. \(\varepsilon_{i}\) sunt i.i.d. cu repartiție comună \(\mathcal{N}(0,1)\), pentru parametrii \(m \in \mathbb{R}\) și \(\sigma>0\). Notăm \(\bar{Y}_{n}= n^{-1} \sum_{i=1}^{n} Y_{i}\).
Se presupune că \(\sigma\) este cunoscut.
- Determinați un interval de încredere simetric pentru \(m\) de nivel \(1-\alpha\), \(\alpha \in (0,1)\).
- Pentru \(\sigma=3\), câte observații trebuie să avem pentru ca lungimea intervalului de încredere de nivel \(95\%\) să fie mai mică de \(2\)? Dați forma acestui interval la nivelul de încredere de \(95\%\) pentru \(\sigma=3\), \(n=25\) și \(\bar{y}_{25}=\bar{Y}_{25}(\omega)=20\). Indicație: \(\Phi^{-1}(0,975) \approx 2\).
- Propuneți un test de nivel \(\alpha\) pentru ipoteza \(H_{0}: m=m_{0}\) împotriva \(H_{1}: m \neq m_{0}\). Pentru \(\sigma=3\), \(n=25\), \(\bar{y}_{25}=\bar{Y}_{25}(\omega)=20\) și \(m_{0}=18.9\), care este valoarea \(p\) a acestui test? Se poate accepta ipoteza \(H_{0}\) la nivelurile \(1\%\), \(5\%\) și \(10\%\)? Indicație: \(\Phi\left(\frac{5.5}{3}\right) \simeq \Phi(1.83) \simeq 0.97\).
Nu mai presupunem că \(\sigma\) este cunoscut. Se consideră \(\widehat{\sigma}_{n}=\sqrt{\frac{1}{n-1} \sum_{i=1}^{n}\left(Y_{i}-\bar{Y}_{n}\right)^{2}}\).
- Scrieți modelul de regresie asociat ipotezelor enunțate mai sus și dați estimatorul celor mai mici pătrate pentru \(m\).
- Enunțați teorema lui Cochran în acest caz.
- Demonstrați că \(\widehat{\sigma}_{n}^{2}\) este un estimator nedeplasat și consistent al lui \(\sigma^{2}\).
- Testați ipoteza \(H_{0}: \sigma^{2}=3\) împotriva \(H_{1}: \sigma^{2} \neq 3\) la nivelul \(\alpha\).
- Determinați repartiția lui \(\sqrt{n} \frac{\bar{Y}_{n}-m}{\widehat{\sigma}_{n}}\).
- Determinați un interval de încredere de nivel \(1-\alpha\) pentru \(m\). Deduceți un test pentru ipoteza \(H_{0}: m=m_{0}\) împotriva \(H_{1}: m \neq m_{0}\) la nivelul \(\alpha\).
- Testați acum \(H_{0}: m \geq m_{0}\) împotriva \(H_{1}: m<m_{0}\) la nivelul \(\alpha\). Calculați valoarea \(p\) când \(m_{0}=12.5\), \(n=25\), \(\bar{y}_{25}=\bar{Y}_{25}(\omega)=12\) și \(\widehat{\sigma}_{n}^{2}(\omega)=1.69\) ? Se poate accepta ipoteza \(H_{0}\) la nivelul de \(5\%\)? Indicație: \(F_{\mathcal{T}(24)}(-1.92) \simeq 0.03\).
Referințe
Casella, George, and Roger L. Berger. 2001. Statistical Inference. 2nd ed. Duxbury Press.