Modele de regresie
Curs 5 - Regresie liniară multiplă - Interpretare
1 Interpretarea efectului variabilelor explicative
În acest curs ne propunem să explicăm și să interpretăm modul în care modelul ales și variabilele explicative influențează răspunsul mediu. Pentru aceasta vom considera situația în care covariabilele sunt continue, sunt discrete (categoriale) precum și modul în care acestea interacționează între ele.
1.1 Cazul variabilelor explicative continue
De cele mai multe ori atunci când avem de-a face doar cu variabile predictor continue este necesară ajustarea modelului de regresie astfel încât să se permită și relații/efecte neliniare între răspuns și covariabile. Am văzut în secțiunea Liniaritatea efectelor variabilelor explicative din Cursul 4 că acest lucru este permis în contextul modelului de regresie liniară, iar în această secțiune vom prezenta două abordări pentru obținerea acestui lucru: transformarea covariabilelor și regresia polinomială.
Transformarea variabilelor explicative permite înlăturarea efectelor neliniare în predictori și liniarizarea modelului. Dacă variabila explicativă \(z\) prezintă (aproximativ) un efect neliniar de tipul \(\beta_1\times f(z)\) unde \(f\) este o funcție cunoscută atunci modelul de regresie
\[ y_i = \beta_0 + \beta_1\times f(z_i) + \cdots+\varepsilon_i \]
poate fi transformat într-un model de regresie liniară
\[ y_i = \beta_0 + \beta_1x_i + \cdots+\varepsilon_i \]
unde \(x_i = f(z_i) - \frac{1}{n}\sum_{j = 1}^{n}f(z_j)\). Operația de centrare face ca efectul estimat \(\hat{\beta}_1 x\) să fie automat centrat în zero și permite o mai bună interpretare.
Printre cele mai eficiente transformări se numără transformările de tip puteri (power transformations) care au ca formă generală
\[ x_i = f_{\lambda}(z_i) = \left\{\begin{array}{ll}z_i^{\lambda} &, \lambda\neq 0\\ \log(z_i) &, \lambda = 0\end{array}\right. \]
unde \(\lambda\in\Lambda = \left\{-1, -\frac{1}{2}, -\frac{1}{3}, 0, \frac{1}{3}, \frac{1}{2}, 1\right\}\) (scara puterilor). O inspecție vizuală prin trasarea matricii de diagrame de împrăștiere (scatterplot matrix) între predictori poate sugera ce transformări sunt necesare (Olive 2017).
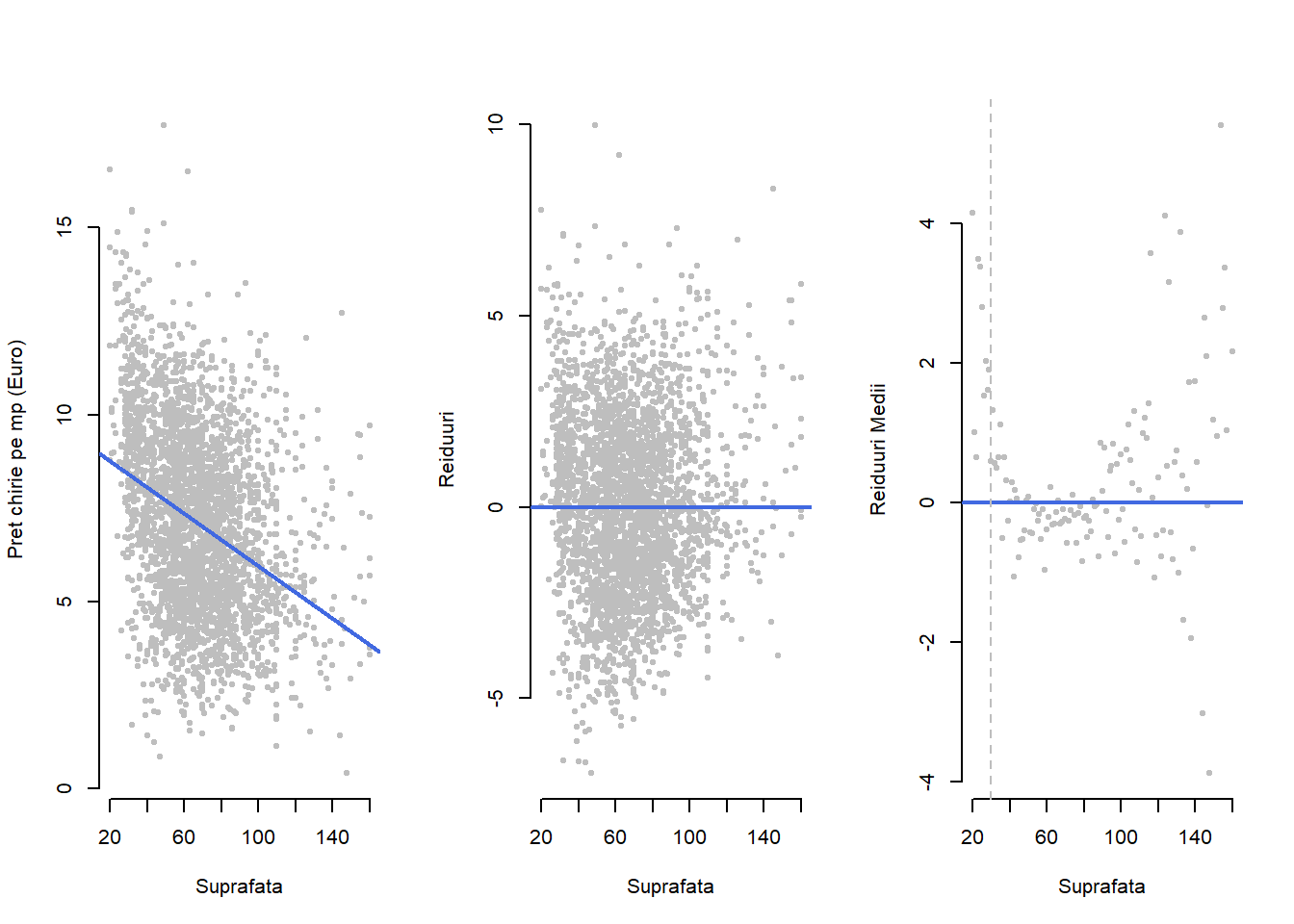
Exemplul 1.1 (Prețul chiriilor în Munchen - transformarea variabilelor) Vom exemplifica efectul asupra răspunsului mediu obținut prin transformarea variabilelor explicative folosind, pentru început, întregul set de date ce face referire la prețul chiriilor în Munchen. Dacă ne uităm la modelul de regresie liniară simplă între prețul net pe metrul pătrat al chiriei (ca variabilă răspuns) în funcție de suprafața locuinței de închiriat (variabila explicativă) găsim următoarea relație
\[ \widehat{pret{\_m^2}_i} = 9.469 -0.035 \times suprafata_i. \]
În Figura 1.1 de mai jos avem ilustrat grafic modelul de regresie astfel: în subfigura din stânga avem diagrama de împrăștiere cu dreapta de regresie, în subfigura din mijloc avem graficul valorilor reziduale iar în subfigura din dreapta avem valorile reziduale medii calculate pentru fiecare valoare a suprafeței de locuit. Observăm că pentru apartamentele cu suprafața mică (suprafața mai mică de 30 metrii pătrați) valorile reziduale sunt predominant pozitive (mai exact peste \(88\%\) dintre acestea au reziduuri pozitive) ceea ce sugerează existența unei relații neliniare între preț pe metru pătrat și suprafață.
Specificarea acestei relații neliniare poate fi făcută, de exemplu, prin transformarea variabilei predictor conducând astfel la un model de regresie de tipul
\[ pret{\_m^2}_i = \beta_0 + \beta_1\times f({suprafata_i}) + \varepsilon_i \]
unde \(f\) este o funcție arbitrară care trebuie aleasă în avans (deterministă) și care nu este estimată de model.
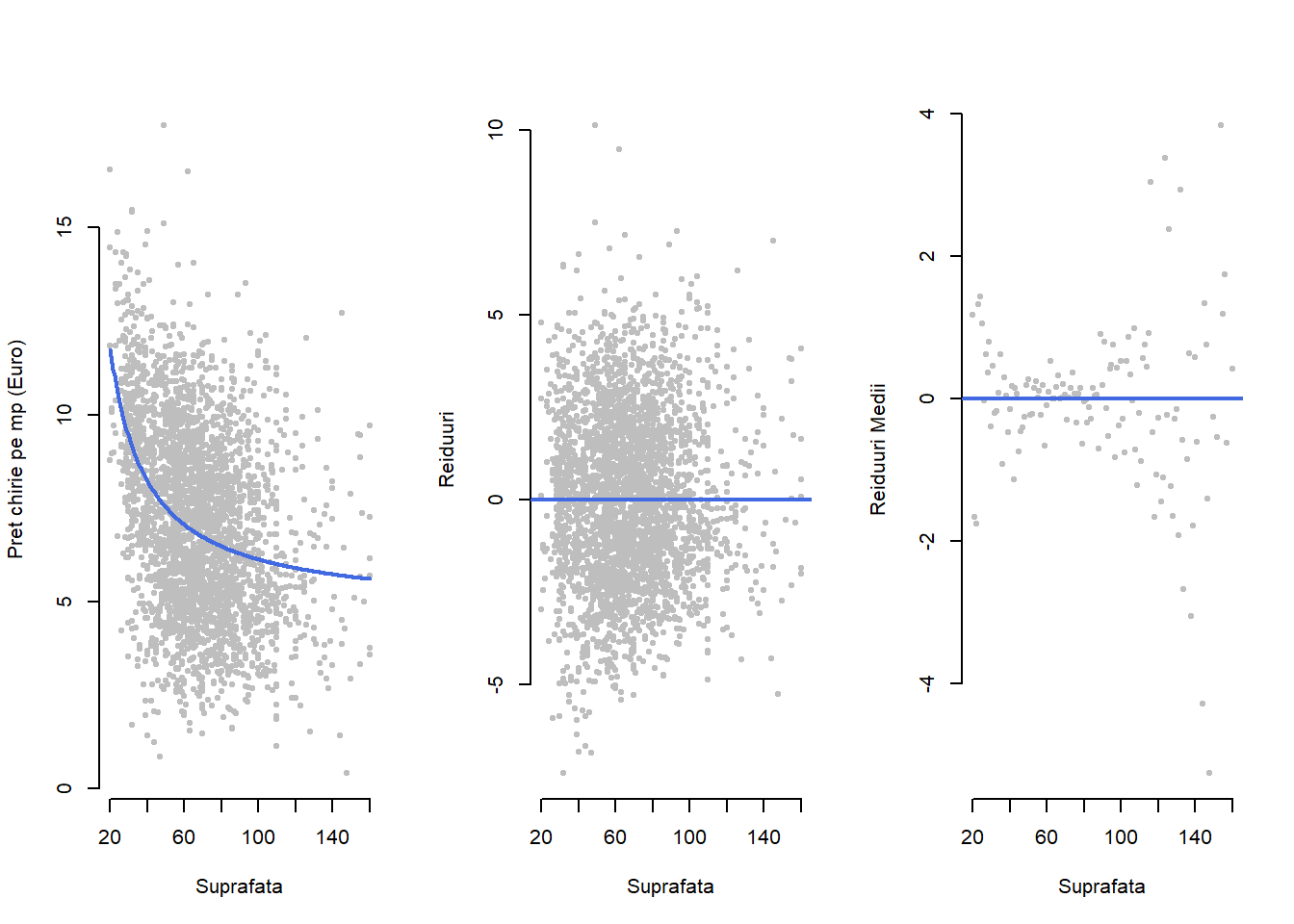
Observăm că modelul de mai sus, chiar dacă reprezintă o generalizare a modelului de regresie liniară simplă considerat anterior, este tot un caz special de regresie liniară în care variabila predictor acum este \(x_i = f({suprafata_i})\). Astfel, presupunând că prețul mediu net pe metrul pătrat variază invers proporțional cu suprafața de locuit atunci o transformare potrivită ar fi \(f({suprafata_i})=\frac{1}{suprafata_i}\) și în această situație modelul ar deveni
\[ pret{\_m^2}_i = \beta_0 + \beta_1 \frac{1}{suprafata_i} + \varepsilon_i. \]
Trebuie menționat că această transformare nu este singura care poate fi luată în calcul, de exemplu am putea considera o transformare logaritmică \(f({suprafata_i})=\log({suprafata_i})\), și în general alegem transformarea potrivită în funcție sau de procesul teoretic care a condus la generarea datelor (atunci când acesta este cunoscut sau se poate determina - experiment fizic) sau prin inspecție vizuală a diagramei de împrăștiere.
În urma estimării prin metoda celor mai mici pătrate (a se vedea secțiunea Metoda celor mai mici pătrate) obținem că prețul mediu net pe metrul pătrat este:
\[ \widehat{pret{\_m^2}_i} = 4.732 + 140.178 \frac{1}{suprafata_i} \]
iar matricea de design \(\symbf X\) pentru acest model
\[ \symbf X = \begin{pmatrix}1 & \frac{1}{suprafata_1}\\1 & \frac{1}{suprafata_2}\\ \vdots & \vdots\\ 1 & \frac{1}{suprafata_{3082}}\end{pmatrix} = \begin{pmatrix}1 & 0.029\\ 1 & 0.01\\ \vdots & \vdots \\ 1 & 0.016\end{pmatrix}. \]
Relația neliniară dintre răspunsul mediu și covariabila suprafața locuinței este ilustrată în Figura 1.2 de mai jos. Se constată că, per total, prețul mediu net al chiriei pe metrul pătrat descrește odată cu creșterea suprafeței de locuit dar această descreștere este mai abruptă pentru apartamentele cu suprafață mică (până în jurul valorii de 40 de \(m^2\)) după care aceasta devine aproape liniară cu o tendință de nivelare în jurul valorii de 100 de \(m^2\). Graficele valorilor reziduale (sau reziduale medii) sugerează o (mai) bună ajustare a modelului neliniar ales la date.
Arată codul R din exemplul de mai sus
#----------------------------------------------------------
# Prețul chiriilor în Munchen - transformarea variabilelor
#----------------------------------------------------------
# Consideram intregul set de date
munich <- read.table("dataIn/Munchen.raw", header = TRUE)
munich_sub <- munich %>% filter(yearc > 1966, location == 1)
# primul model
munich_mod1 <- lm(rentsqm ~ area,
data = munich)
coef_munich_mod1 <- round(coef(munich_mod1), 3)
t <- 30
tab_munich_mod1 <- table(sign(residuals(munich_mod1)[munich$area<t])) /
sum(table(sign(residuals(munich_mod1)[munich$area<t])))
# al doilea model cu variabila transformata
munich_mod2 <- lm(rentsqm ~ I(1/area),
data = munich)
coef_munich_mod2 <- round(coef(munich_mod2), 3)
design_matrix_munich_mod2 <- round(model.matrix(munich_mod2), 3)
# plot modelul 1
par(mfrow = c(1,3))
# fit
plot(munich$area, munich$rentsqm,
pch = 20,
col = "grey",
bty = "n",
xlab = "Suprafata",
ylab = "Pret chirie pe mp (Euro)")
abline(munich_mod1$coefficients, col = "royalblue",
lwd = 2, lty = 1)
# residuals
plot(munich$area, residuals(munich_mod1),
pch = 20,
col = "grey",
bty = "n",
xlab = "Suprafata",
ylab = "Reiduuri")
abline(h = 0, col = "royalblue",
lwd = 2, lty = 1)
# average residuals
avg_munich_mod1 <- data.frame(area = munich$area,
avg_res = residuals(munich_mod1))
avg_munich_mod1 <- avg_munich_mod1 %>%
group_by(area) %>%
summarise(avg_res = mean(avg_res))
plot(avg_munich_mod1$area, avg_munich_mod1$avg_res,
pch = 20,
col = "grey",
bty = "n",
xlab = "Suprafata",
ylab = "Reiduuri Medii")
abline(h = 0, col = "royalblue",
lwd = 2, lty = 1)
abline(v = t, col = "grey",
lty = 2)
# pentru modelul 2
par(mfrow = c(1, 3))
# fit
x_new_munich <- data.frame(area = seq(min(munich$area), max(munich$area),
length.out = 250))
plot(munich$area, munich$rentsqm,
pch = 20,
col = "grey",
bty = "n",
xlab = "Suprafata",
ylab = "Pret chirie pe mp (Euro)")
lines(x_new_munich$area, predict(munich_mod2, x_new_munich),
col = "royalblue",
lwd = 2, lty = 1)
# residuals
plot(munich$area, residuals(munich_mod2),
pch = 20,
col = "grey",
bty = "n",
xlab = "Suprafata",
ylab = "Reiduuri")
abline(h = 0, col = "royalblue",
lwd = 2, lty = 1)
# average residuals
avg_munich_mod2 <- data.frame(area = munich$area,
avg_res = residuals(munich_mod2))
avg_munich_mod2 <- avg_munich_mod2 %>%
group_by(area) %>%
summarise(avg_res = mean(avg_res))
plot(avg_munich_mod2$area, avg_munich_mod2$avg_res,
pch = 20,
col = "grey",
bty = "n",
xlab = "Suprafata",
ylab = "Reiduuri Medii")
abline(h = 0, col = "royalblue",
lwd = 2, lty = 1)Considerăm acum exemplul privind înălțimea arborilor de eucalipt:
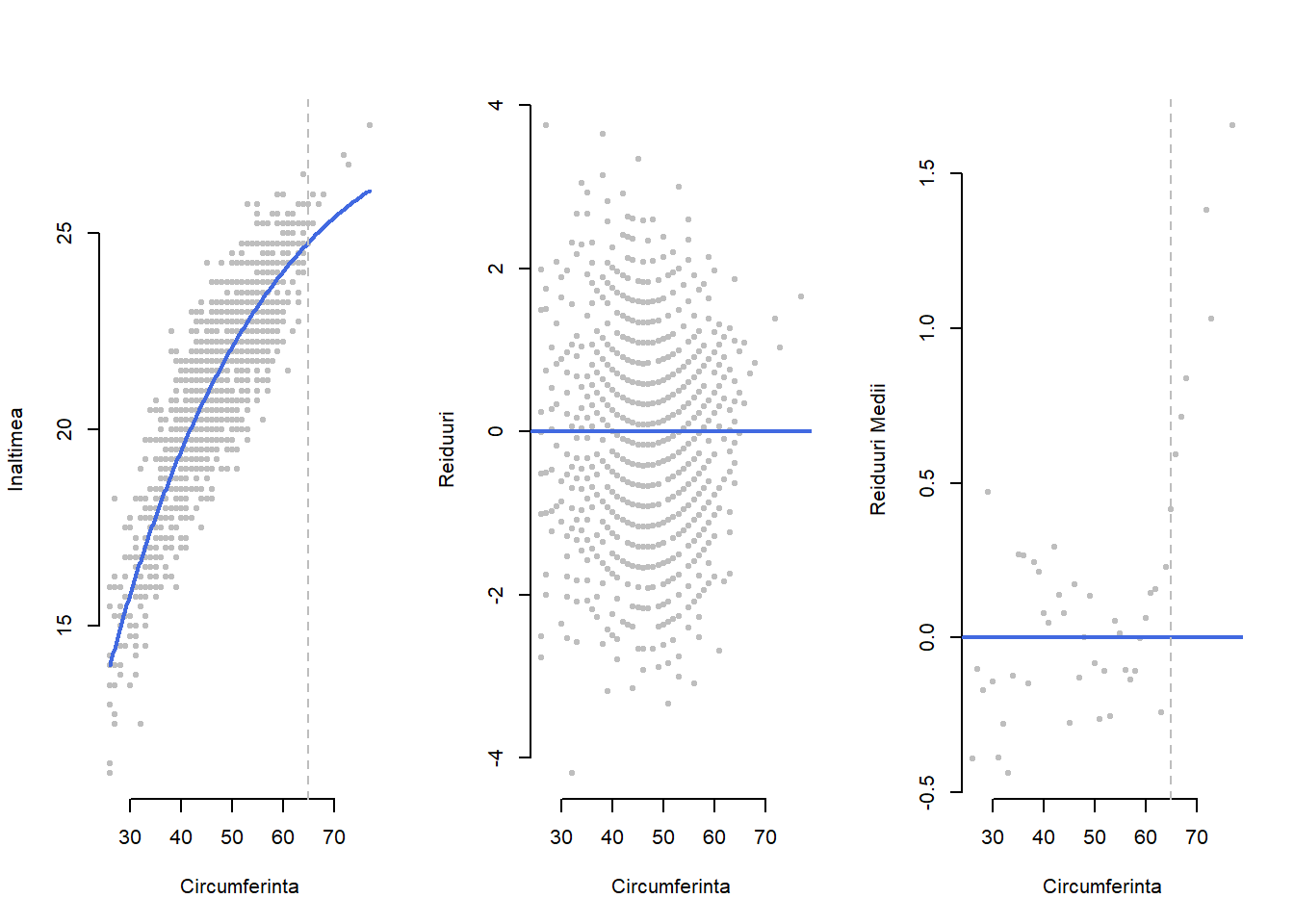
Exemplul 1.2 (Înălțimea arborilor de eucalipt - transformarea variabilelor) În contextul setului de date Eucalypt am văzut că înălțimea (medie) a arborilor de eucalipt poate fi modelată prin intermediul modelului de regresie liniară simplă prin \(\widehat{ht}_i = 9.037 + 0.257 circ_i\) (a se vedea Exemplul 2.1) unde, observând că majoritatea arborilor a căror circumferință avea valori mai mici de 35 cm se aflau sub dreapta de regresie, am dedus că o relație neliniară între înălțime și circumferință ar fi mai potrivită. Inspectând vizual diagrama de împrăștiere (figura de mai jos partea stângă) putem sugera o transformare de tipul \(f(circ_i)=\sqrt{circ_i}\) ceea ce ar conduce, de exemplu, la modelul de regresie
\[ ht_i = \beta_0 + \beta_1\times circ_i + \beta_2\times\sqrt{circ_i} + \varepsilon_i, \quad i =1,\ldots, 1429. \]
Estimând coeficienții din modelul de mai sus găsim că înălțimea medie a arborilor de eucalipt este
\[ \widehat{ht_i} = -24.352 -0.483 \times circ_i + 9.987 \times \sqrt{circ_i} \]
iar în acest caz matricea de design \(\symbf X\) este
\[ \symbf X = \begin{pmatrix}1 & circ_1 & \sqrt{circ_1}\\1 & circ_2 & \sqrt{circ_2}\\ \vdots & \vdots & \vdots\\ 1 & circ_{1429} & \sqrt{circ_{1429}}\end{pmatrix} = \begin{pmatrix}1 & 36 & 6\\ 1 & 42 & 6.481\\ \vdots & \vdots & \vdots\\ 1 & 40 & 6.325\end{pmatrix}. \]
În Figura 1.3 de mai jos avem diagrama de împrăștiere a datelor și curba de regresie care modelează înălțimea medie în funcție de circumferință conform modelului propus, graficul valorilor reziduale precum și graficul valorilor reziduale medii calculate pentru fiecare valoare a circumferinței. Putem observa că modelul propus este ajustat (fitat) mai bine pe date (coeficientul de determinare \(R^2=0.7921904\) este un pic mai mare atât față de cel în care apare doar termenul \(\sqrt{circ_i}\) care este \(R^2=0.7820638\) cât și de modelul de regresie simplă \(R^2=0.7683202\) - acest fenomen fiind absolut normal în contextul modelelor imbricate), în special pentru arbori a căror circumferință este mai mică de 65 cm. Pentru arborii cu circumferințe mai mari modelul sugerează o înălțime medie mai mică decât cea măsurată.
Arată codul R din exemplul de mai sus
#---------------------------------------
# Eucalipt - transformarea variabilelor
#---------------------------------------
# Consideram intregul set de date
eucalipt <- read.table("dataIn/eucalyptus.txt",
header=T,
sep=";")
eucalypt_model1 <- lm(ht ~ circ,
data = eucalipt)
coef_eucalypt_model1 <- round(coef(eucalypt_model1), 3)
eucalypt_model2 <- lm(ht ~ sqrt(circ),
data = eucalipt)
coef_eucalypt_model2 <- round(coef(eucalypt_model2), 3)
# primul model
eucalipt_mod1 <- lm(ht ~ circ + I(sqrt(circ)),
data = eucalipt)
coef_eucalipt_mod1 <- round(coef(eucalipt_mod1), 3)
design_matrix_eucalipt_mod1 <- round(model.matrix(eucalipt_mod1), 3)
# pentru modelul 1
par(mfrow = c(1, 3))
# fit
x_new_eucalipt <- data.frame(circ = seq(min(eucalipt$circ), max(eucalipt$circ),
length.out = 250))
plot(eucalipt$circ, eucalipt$ht,
pch = 20,
col = "grey",
bty = "n",
xlab = "Circumferinta",
ylab = "Inaltimea")
lines(x_new_eucalipt$circ, predict(eucalipt_mod1, x_new_eucalipt),
col = "royalblue",
lwd = 2, lty = 1)
abline(v = 65, lty = 2, col = "grey")
# residuals
plot(eucalipt$circ, residuals(eucalipt_mod1),
pch = 20,
col = "grey",
bty = "n",
xlab = "Circumferinta",
ylab = "Reiduuri")
abline(h = 0, col = "royalblue",
lwd = 2, lty = 1)
# average residuals
avg_eucalipt_mod1 <- data.frame(circ = eucalipt$circ,
avg_res = residuals(eucalipt_mod1))
avg_eucalipt_mod1 <- avg_eucalipt_mod1 %>%
group_by(circ) %>%
summarise(avg_res = mean(avg_res))
plot(avg_eucalipt_mod1$circ, avg_eucalipt_mod1$avg_res,
pch = 20,
col = "grey",
bty = "n",
xlab = "Circumferinta",
ylab = "Reiduuri Medii")
abline(h = 0, col = "royalblue",
lwd = 2, lty = 1)
abline(v = 65, lty = 2, col = "grey")În exemplul următor vom face referire la regresia polinomială care reprezintă o altă modalitate simplă de a specifica un efect neliniar al predictorilor asupra variabilei răspuns. În general, atunci când covariabila continuă \(z\) prezintă un efect neliniar (polinomial) de tipul \(\beta_1 z + \beta_2 z^2 +\cdots + \beta_k z^k\), modelul
\[ y_i = \beta_0 + \beta_1 z_i + \beta_2 z_i^2 +\cdots + \beta_k z_i^k + \varepsilon_i \]
poate fi transformat în modelul de regresie liniară simplă
\[ y_i = \beta_0 + \beta_1 x_{i1} + \beta_2 x_{i2} +\cdots + \beta_k x_{ik} + \varepsilon_i \]
unde \(x_{i1} = z_i\), \(x_{i2} = z_i^2\), …, \(x_{ik} = z_i^k\). Este important de remarcat faptul că pentru a facilita interpretarea este necesară uneori centrarea (și uneori ortogonalizarea) vectorilor \(\symbf X_j = (x_{1j},\ldots,x_{nj})^\intercal\) în \(\symbf X_j - \bar{\symbf X_j}\) unde \(\bar{\symbf X_j} = \left(\bar{x}_j = \frac{\sum_{i = 1}^{n}x_{ij}}{n}, \ldots, \bar{x}_j\right)^\intercal\).
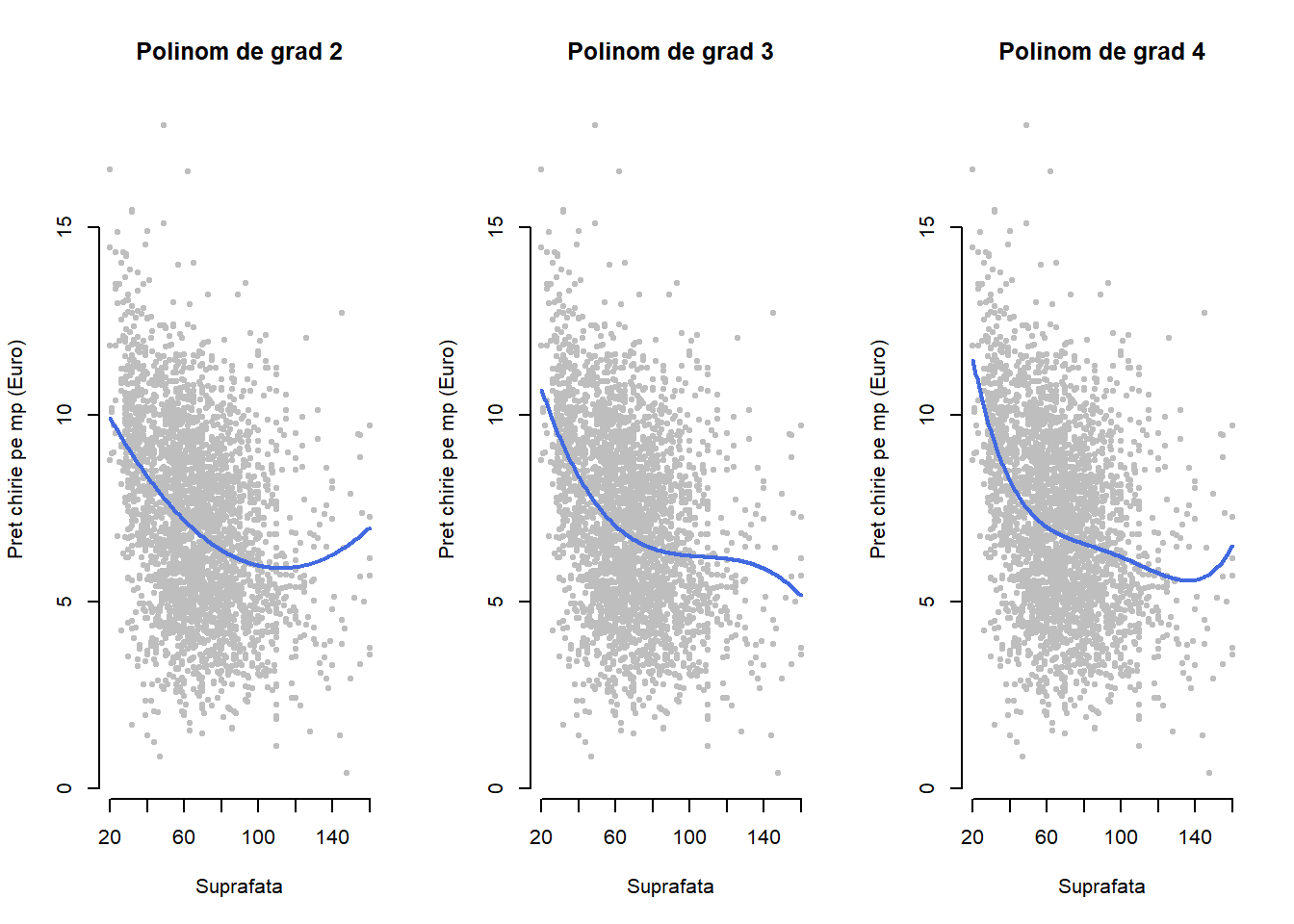
Exemplul 1.3 (Prețul chiriilor în Munchen - regresie polinomială) Vom ilustra modelarea prin regresie polinomială folosind setul de date Munchen. Vom presupune că variabila predictor suprafața de locuit admite un efect polinomial. Pentru un efect polinomial de ordin doi obținem următorul model de regresie:
\[ pret{\_m^2}_i = \beta_0 + \beta_1\times suprafata_i + \beta_2\times suprafata_i^2 + \varepsilon_i \]
iar pentru un efect de ordin trei avem
\[ pret{\_m^2}_i = \beta_0 + \beta_1\times suprafata_i + \beta_2\times suprafata_i^2 + \beta_3\times suprafata_i^3 + \varepsilon_i. \]
Bineînțeles, putem folosi și polinoame de grad superior dar în general preferăm pentru simplitate și interpretabilitate polinoame de grad mai mic. De asemenea, atunci când folosim polinoame de grad mai mare ca 3 observăm că rezultatul devine instabil în special la capetele domeniului covariabilei (a se vedea Figura 1.4 de mai jos dreapta unde folosim un polinom de grad 4). Notând cu \(x_{i1} = suprafata_i\), \(x_{i2} = suprafata_i^2\) și \(x_{i3} = suprafata_i^3\) obținem modelul de regresie liniară
\[ pret{\_m^2}_i = \left\{\begin{array}{ll}\beta_0 + \beta_1x_{i1} + \beta_2x_{i2} + \varepsilon_i, & \text{polinom de grad 2}\\ \beta_0 + \beta_1x_{i1} + \beta_2x_{i2} + \beta_3x_{i3} + \varepsilon_i, & \text{polinom de grad 3}\end{array}\right. \]
Matricile de design corespunzătoare sunt
\[ \symbf X = \begin{pmatrix} 1 & 35 & 35 ^2\\ 1 & 104 & 104 ^2\\ \vdots & \vdots & \vdots\\ 1 & 62 & 62 ^2 \end{pmatrix} = \begin{pmatrix} 1 & 35 & 1225\\ 1 & 104 & 1.0816\times 10^{4}\\ \vdots & \vdots & \vdots\\ 1 & 62 & 3844\\ \end{pmatrix} \]
respectiv
\[ \symbf X = \begin{pmatrix} 1 & 35 & 35 ^2 & 35 ^3\\ 1 & 104 & 104 ^2 & 104 ^3\\ \vdots & \vdots & \vdots & \vdots\\ 1 & 62 & 62 ^2 & 62 ^3 \end{pmatrix} = \begin{pmatrix} 1 & 35 & 1225 & 4.2875\times 10^{4}\\ 1 & 104 & 1.0816\times 10^{4} & 1.124864\times 10^{6}\\ \vdots & \vdots & \vdots & \vdots \\ 1 & 62 & 3844 & 2.38328\times 10^{5}\\ \end{pmatrix} \]
iar curbele de regresie estimate
\[ \widehat{pret{\_m^2}_i} = \left\{\begin{array}{ll}11.83 -0.106\times suprafata_i + 4.7\times 10^{-4}\times suprafata_i^2, & \text{grad 2}\\ 14.28 -0.218\times suprafata_i + 0.002\times suprafata_i^2 -6\times 10^{-6}\times suprafata_i^3, & \text{grad 3}\end{array}\right. \]
Figura 1.4 de mai jos ne prezintă diagramele de împrăștiere împreună curbele de regresie specifice modelelor selectate. Observăm că rezultatele sunt similare cu cele obținute prin transformarea \(f(suprafata_i) = \frac{1}{suprafata_i}\) (modelele polinomiale considerate fiind imbricate conduc la o creștere a coeficientului de determinare ca și în cazul Exemplul 1.2)).
Arată codul R din exemplul de mai sus
#----------------------------------------------------
# Prețul chiriilor în Munchen - regresie polinomială
#----------------------------------------------------
# Modele de regresie polinomiala
# grad 2
munich_mod_pol1 <- lm(rentsqm ~ I(area) + I(area^2),
data = munich)
coef_munich_mod_pol1 <- round(coef(munich_mod_pol1), 4)
design_matrix_munich_pol1 <- round(model.matrix(munich_mod_pol1), 3)
# grad 3
munich_mod_pol2 <- lm(rentsqm ~ I(area) + I(area^2) + I(area^3),
data = munich)
coef_munich_mod_pol2 <- round(coef(munich_mod_pol2), 6)
design_matrix_munich_pol2 <- round(model.matrix(munich_mod_pol2), 3)
# grad 4
munich_mod_pol3 <- lm(rentsqm ~ I(area) + I(area^2) + I(area^3)+ I(area^4),
data = munich)
coef_munich_mod_pol3 <- round(coef(munich_mod_pol3), 6)
design_matrix_munich_pol3 <- round(model.matrix(munich_mod_pol3), 3)
# pentru modelul pol 1, pol 2 si pol 3
par(mfrow = c(1, 3))
# fit
x_new_pol1 <- data.frame(area = seq(min(munich$area), max(munich$area),
length.out = 250))
plot(munich$area, munich$rentsqm,
pch = 20,
col = "grey",
bty = "n",
xlab = "Suprafata",
ylab = "Pret chirie pe mp (Euro)",
main = "Polinom de grad 2")
lines(x_new_pol1$area, predict(munich_mod_pol1, x_new_pol1),
col = "royalblue",
lwd = 2, lty = 1)
# fit 2
x_new_pol2 <- data.frame(area = seq(min(munich$area), max(munich$area),
length.out = 250))
plot(munich$area, munich$rentsqm,
pch = 20,
col = "grey",
bty = "n",
xlab = "Suprafata",
ylab = "Pret chirie pe mp (Euro)",
main = "Polinom de grad 3")
lines(x_new_pol2$area, predict(munich_mod_pol2, x_new_pol2),
col = "royalblue",
lwd = 2, lty = 1)
# fit 3
x_new_pol3 <- data.frame(area = seq(min(munich$area), max(munich$area),
length.out = 250))
plot(munich$area, munich$rentsqm,
pch = 20,
col = "grey",
bty = "n",
xlab = "Suprafata",
ylab = "Pret chirie pe mp (Euro)",
main = "Polinom de grad 4")
lines(x_new_pol3$area, predict(munich_mod_pol3, x_new_pol3),
col = "royalblue",
lwd = 2, lty = 1)Dacă până acum am considerat doar modele în care apărea o singură variabilă explicativă, exemplul de mai jos consideră o generalizare la doi sau mai mulți predictori.
Exemplul 1.4 (Prețul chiriilor în Munchen - model aditiv) În acest exemplu vom modela prețul mediu net al chiriei pe metrul pătrat adăugând pe lângă efectul invers proporțional dat de suprafața de locuit (a se vedea Exemplul 1.1) și efectul dat de anul de construcție al apartamentului (\(an{\_con}\)). Dacă anul construcției prezintă un efect liniar asupra prețului chiriei atunci obținem modelul (denumit modelul 1)
\[ pret{\_m^2}_i = \beta_0 + \beta_1\times f(suprafata_i) + \beta_2\times an{\_con}_{i} + \varepsilon_i \]
unde \(f(suprafata_i) = \frac{1}{suprafata_i}\) și care în urma estimării devine
\[ \widehat{pret{\_m^2}_i} = -65.406 + 119.361\frac{1}{suprafata_i} + 0.036\times an{\_con}_{i}. \]
Alternativ, putem să considerăm că anul construcției locuinței prezintă un efect neliniar asupra prețului chiriei pe metrul pătrat, aspect pe care îl vom modela prin intermediul unui polinom de grad 3 și în acest caz avem modelul (denumit model 2)
\[ \begin{aligned} pret{\_m^2}_i &= \beta_0 + \beta_1\times \frac{1}{suprafata_i} + \beta_2\times an{\_con}_{i} + \\ &\quad+\beta_3\times an{\_con}_{i}^2 + \beta_4\times an{\_con}_{i}^3 + \varepsilon_i. \end{aligned} \]
Modelul estimat (răspunsul mediu estimat) în acest caz este
\[ \begin{aligned} \widehat{pret{\_m^2}_i} &= 2.94193\times 10^{4} + 129.57 \times \frac{1}{suprafata_i} -43.3\times an{\_con}_{i} +\\ &\quad + 0.021\times an{\_con}_{i}^2 -3\times 10^{-6}\times an{\_con}_{i}^3 \end{aligned} \]
În Figura 1.5 de mai jos avem ilustrate diagramele de împrăștiere (3D) împreună cu suprafețele de regresie induse de modelele menționate mai sus. Ca și în cazul regresiei liniare simple, vizualizarea diagramelor de împrăștiere atunci când avem de-a face cu două variabile explicative este un instrument grafic care permite o mai bună înțelegere a relației dintre variabila răspuns și covariabilele implicate. Pentru trasarea în R a diagramelor de împrăștiere am folosit funcția scatter3D din pachetul plot3D.
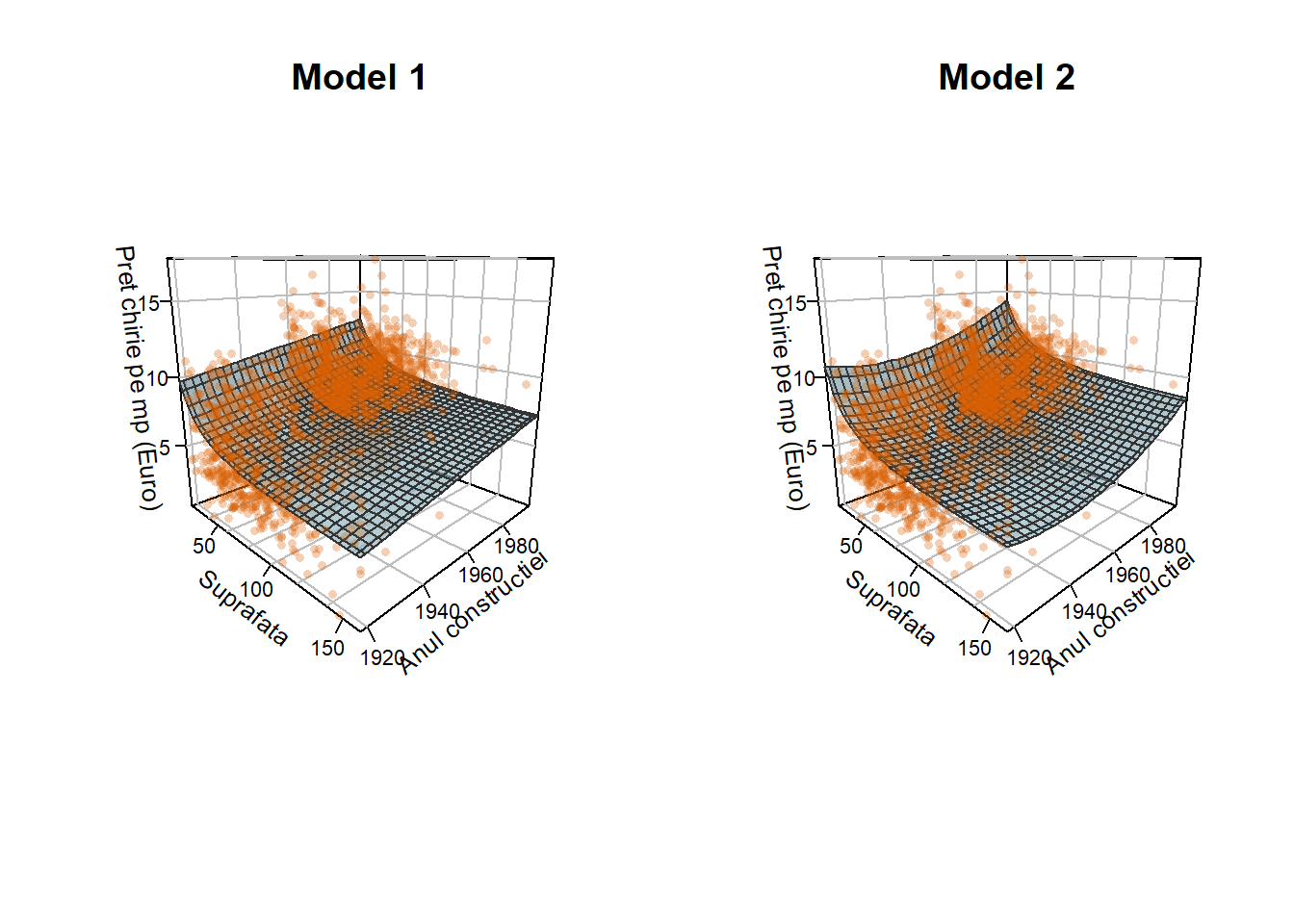
Combinând în modelul 2 efectele variabilelor explicative suprafața de locuit și anul de construcție a locuinței în funcțiile \(f_1\) și respectiv \(f_2\), obținem următorul model
\[ pret{\_m^2}_i = \beta_0 + \underbrace{f_1(suprafata_i)}_{=\beta_1\times \frac{1}{suprafata_i}} + \underbrace{f_2(an{\_con_i})}_{=\beta_2\times an{\_con}_{i} + \beta_3\times an{\_con}_{i}^2 + \beta_4\times an{\_con}_{i}^3} + \varepsilon_i. \]
Funcțiile estimate sunt
\[ \hat{f}_1(suprafata) = 129.57 \times \frac{1}{suprafata} \]
și respectiv
\[ \hat{f}_2(an{\_con}) = -43.3\times an{\_con}_{i} + 0.021\times an{\_con}_{i}^2 -3\times 10^{-6}\times an{\_con}_{i}^3. \]
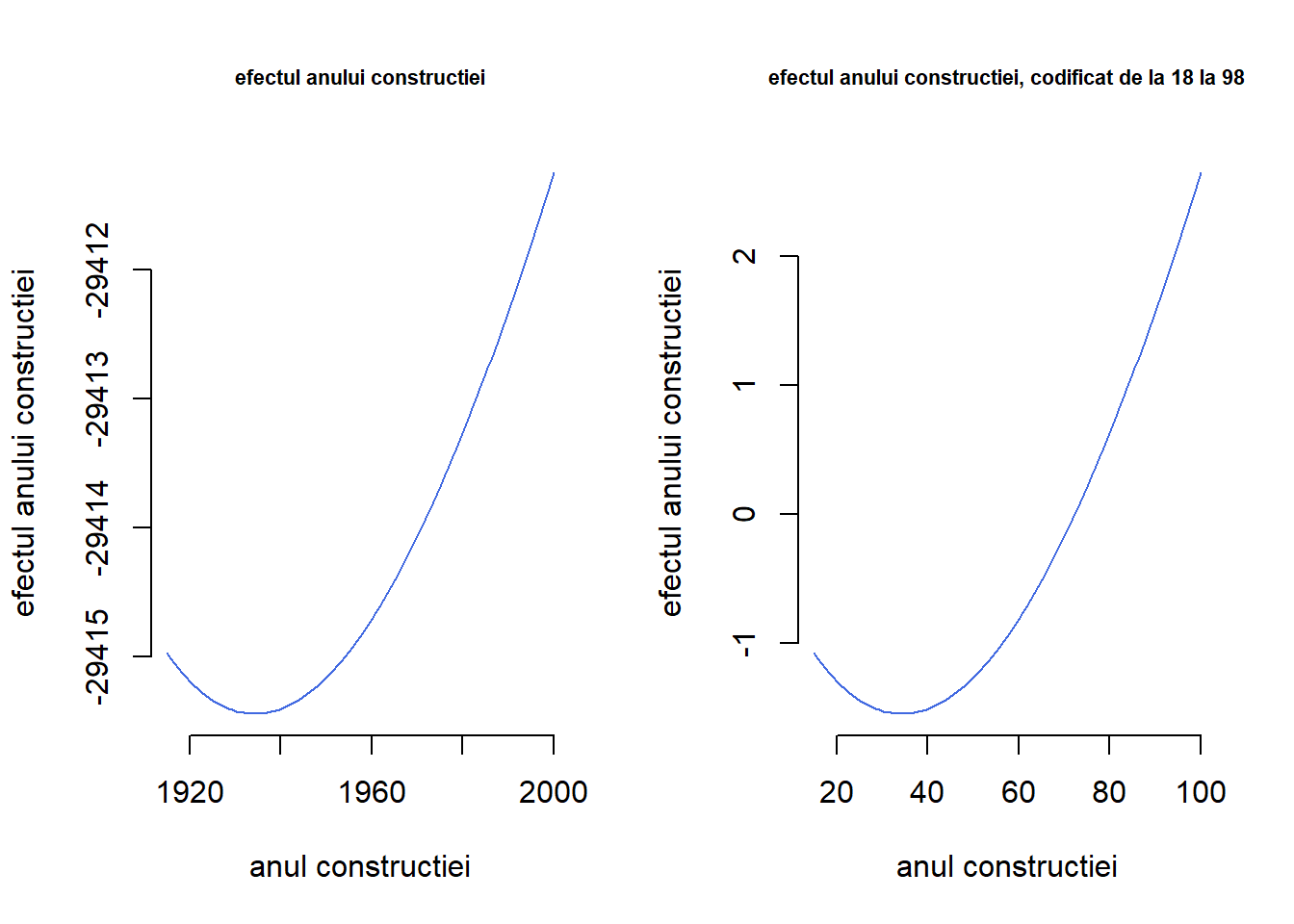
Efectul estimat \(\hat{f}_1(suprafata)\) și \(\hat{f}_2(an{\_con})\) al celor două covariabile poate fi interpretat mai ușor prin intermediul vizualizării. De exemplu, în figura de mai jos este prezentat efectul anului construcției asupra prețului chiriei pe metrul pătrat. Observăm că, datorită scalei covariabilei anul de construcției a locuinței care ia valori între 1918 și 1998, efectul acestei covariabile este între -2.9415^{4} și -2.9411^{4}. Dacă în schimb am specifica anul de construcție ca având valori de la \(18\) la \(98\) (scăzând \(1900\)) atunci am obține modelul
\[ \begin{aligned} \widehat{pret{\_m^2}_i} &= 5.4 + 129.57 \times \frac{1}{suprafata_i} -0.09\times an{\_con}_{i} + \\ &\quad + 0.002\times an{\_con}_{i}^2 -3\times 10^{-6}\times an{\_con}_{i}^3 \end{aligned} \]
Chiar dacă parametrii noului model diferă de cei ai modelului 2, atunci când ne uităm la efectul anului de construcție (Figura 1.6 de mai jos dreapta) vedem că aceasta este doar translatată vertical. Acest fenomen este natural ținând cont de observația că adăugând un termen constant la \(\hat{f}_2\) și scăzând același termen din \(\hat{\beta}_0\) valoarea estimată a răspunsului mediu rămâne neschimbată (nivelul unei funcții neliniare nu este identifiabil).
Observația anterioară, că nivelul unei funcții neliniare poate fi schimbat în mod arbitrar de exemplu prin transformarea variabilei predictor, conduce la recomandarea centrării covariabilelor (sau a funcțiilor de covariabile). Astfel, în cazul modelului propus putem înlocui variabila \(suprafata{\_inv} = \frac{1}{suprafata}\) cu \(suprafata{\_inv} - \overline{suprafata{\_inv}}\) și respectiv variabilele \(an{\_con\_j} = an{\_con}^j\) cu \(an{\_con\_j} - \overline{an{\_con\_j}}\).
În cazul modelării prin intermediul polinoamelor putem să folosim polinoame ortogonale1, unde baza uzuală \(1\), \(x\), \(x^2\), \(x^3\), \(\ldots\) va fi înlocuită de o bază de polinoame ortogonale ceea ce implică centralitatea și ortogonalitatea coloanelor matricei de design corespunzătoare. De asemenea este important de remarcat faptul că folosind o bază de polinoame ortogonale calculul estimatorilor prin metoda celor mai mici pătrate este mai stabil. În R putem construi polinoame ortogonale folosind funcția poly().
Folosind variabilele ortogonale \(an{\_co\_j}\), \(j=1,2,3\) și variabila centrată \(suprafata{\_inv\_cen} = suprafata{\_inv} - \overline{suprafata{\_inv}}\) obținem modelul de regresie liniară
\[ \begin{aligned} \widehat{pret{\_m^2}_i} &= 7.111 + 129.572 \times suprafata{\_inv\_cen} + 43.938\times an{\_co\_1}\\ &\quad + 27.539\times an{\_co\_2} -1.756\times an{\_co\_3} \end{aligned} \]
În Figura 1.7 sunt ilustrate efectele covariabilelor suprafața de locuit și anul de construcție a locuinței, \(\hat{f}_1(suprafata_i)\) și respectiv \(\hat{f}_2(an{\_con}_i)\), împreună cu reziduurile parțiale, definite prin
\[ \hat{\varepsilon}_{suprafata, i} = pret{\_m^2}_i - \hat{\beta}_0 - \hat{f}_2(an{\_con}_i) = \hat{\varepsilon}_i + \hat{f}_1(suprafata_i) \]
și respectiv
\[ \hat{\varepsilon}_{an{\_con}, i} = pret{\_m^2}_i - \hat{\beta}_0 - \hat{f}_1(suprafata_i) = \hat{\varepsilon}_i + \hat{f}_2(an{\_con}_i). \]
Reziduurile parțiale pentru covariabila suprafața de locuit, \(\hat{\varepsilon}_{suprafata, i}\), iau în calcul și variabilitate indusă de suprafața de locuit atunci când toate celelalte efecte sunt înlăturate (în acest caz anul de construcție). În mod similar, pentru reziduurile parțiale asociate anului de construcție a locuinței - \(\hat{\varepsilon}_{an{\_con}, i}\), efectul suprafeței este eliminat dar nu și cel al anului de construcție. Trasând reziduurile parțiale putem investiga dintr-o perspectivă vizuală dacă modelul neliniar ales este potrivit sau nu.
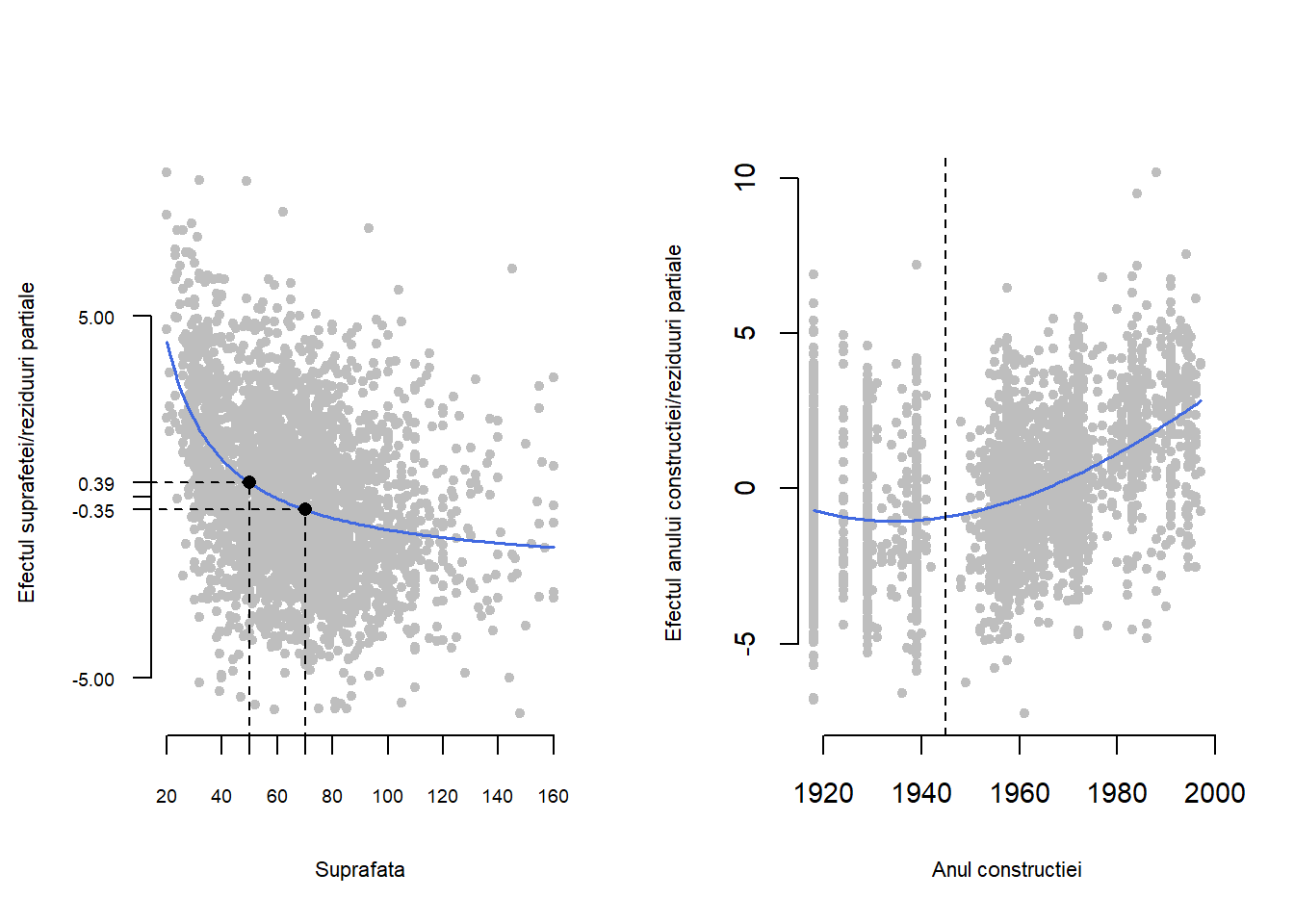
Din punct de vedere al interpretabilității, efectul suprafeței de locuit (figura din stânga) specifică influența acestei covariabile asupra prețului mediu net al chiriei pe metrul pătrat atunci când celelalte covariabile sunt păstrate constante. Astfel pentru apartamentele cu o suprafață de 50 și respectiv 70 metrii pătrați obținem un efect estimat de \(\hat{f}_1(50)\approx 0.39\) și respectiv \(\hat{f}_1(70)\approx -0.35\) euro pe metrul pătrat. Acest fapt implică faptul că în medie prețul chiriei pe metrul pătrat pentru apartamentele de 70 metrii pătrați sunt mai ieftine cu 0.74 euro pe metrul pătrat față de cele cu o suprafață de 50 metrii pătrați, presupunând că ambele au fost construite în același an. De asemenea, dacă ne uităm la apartamentele cu suprafața de 60 și respectiv 80 metrii pătrați atunci diferența este de doar 0.54 euro fapt indicat de efectul aproape constant al covariabilei atunci când locuințele au suprafața mare.
În același mod poate fi interpretat și graficul care prezintă efectul anului de construcție a locuinței. Putem observa (Figura 1.7 de mai sus dreapta) că pentru apartamentele, cu aceeași suprafață, construite înaintea Celui de-al Doilea Război Mondial efectul anului construcției asupra prețului mediu pe metrul pătrat al chiriei este constant pe când pentru apartamentele construite după 1945 tendința este de creștere în mod liniar.
Arată codul R din exemplul de mai sus
#--------------------------------------------
# Prețul chiriilor în Munchen - model aditiv
#--------------------------------------------
# Modele
#---------
# model rentsqm = beta_0 + beta_1*(1/area) + beta_2*yearc + epsilon
munich_ma_mod1 <- lm(rentsqm ~ I(1/area) + yearc,
data = munich)
coef_munich_ma_mod1 <- round(coef(munich_ma_mod1), 3)
# model rentsqm = beta_0 + beta_1*(1/area) + beta_2*yearc + beta_3*yearc^2 + beta_4*yearc^3 + epsilon
munich_ma_mod2 <- lm(rentsqm ~ I(1/area) + yearc + I(yearc^2) + I(yearc^3),
data = munich)
coef_munich_ma_mod2 <- round(coef(munich_ma_mod2), 3)
x <- munich$yearc
eff_ma_mod2 <- coef(munich_ma_mod2)[3]*x + coef(munich_ma_mod2)[4]*x^2 +coef(munich_ma_mod2)[5]*x^3
# model rentsqm = beta_0 + beta_1*(1/area) + beta_2*yearc + beta_3*yearc^2 + beta_4*yearc^3 + epsilon
# unde valoarea 1900 este scazuta din yearc
munich_ma_mod3 <- lm(rentsqm ~ I(1/area) + I(yearc-1900) + I((yearc-1900)^2) + I((yearc-1900)^3),
data = munich)
coef_munich_ma_mod3 <- round(coef(munich_ma_mod3), 3)
# Model ortogonal
# estimarea modelului rentsqm = beta_0 + beta_1*(1/area) + beta_2*yearc + beta_3*yearc^2
# + beta_4*yearc^3 + epsilon
# folosind 1/area centrata si polinoame ortogonale pentru yearc
munich_ma_mod4 <- lm(rentsqm ~ I(1/area - mean(1/area)) + poly(yearc,3),
data = munich)
coef_munich_ma_mod4 <- round(coef(munich_ma_mod4), 3)
# trasează curbele estimate, inclusiv reziduurile parțiale
# type = "terms" in predict arată predicția parțială prin omiterea unui termen din model
# type = "partial" in residual la fel pentru reziduri
munich_ma_mod4_pred <- predict(munich_ma_mod4, type="terms")
# alternativ la munich_ma_mod4_pred[, 2] - effect of year of construction
# predict(munich_ma_mod4) - (1/munich$area - mean(1/munich$area))*coef(munich_ma_mod4)[2]
# - coef(munich_ma_mod4)[1]
munich_ma_mod4_partial_resid <- residuals(munich_ma_mod4, type="partial")
# alternativ pentru reziduurile partiale la yearc
# residuals(munich_ma_mod4) + poly(munich$yearc, 3)[, 1]*coef(munich_ma_mod4)[3]
# + poly(munich$yearc, 3)[, 2]*coef(munich_ma_mod4)[4]
# + poly(munich$yearc, 3)[, 3]*coef(munich_ma_mod4)[5]
# grafic 3d
#------------
x <- munich$area
y <- munich$yearc
z <- munich$rentsqm
grid.lines <- 30
x.pred <- seq(min(x), max(x), length.out = grid.lines)
y.pred <- seq(min(y), max(y), length.out = grid.lines)
xy <- expand.grid(area = x.pred, yearc = y.pred)
z.pred1 <- matrix(predict(munich_ma_mod1, newdata = xy),
nrow = grid.lines, ncol = grid.lines)
z.pred2 <- matrix(predict(munich_ma_mod2, newdata = xy),
nrow = grid.lines, ncol = grid.lines)
par(mfrow = c(1, 2))
# plot model 1
scatter3D(x, y, z, pch = 16, cex = 0.6, colvar = NULL,
theta = 45, phi = 15, ticktype = "detailed",
alpha = 0.3, bty = "b2", col = "#D95F02",
xlab = "Suprafata",
ylab = "Anul constructiei",
zlab = "Pret chirie pe mp (Euro)",
main = "Model 1",
cex.lab = 0.8,
cex.axis = 0.7,
surf = list(x = x.pred,
y = y.pred,
z = z.pred1,
facets = TRUE,
border = "grey20",
alpha = 0.7,
shade = 0.2,
# fit = z.fit,
col = "lightblue"))
# plot model 2
scatter3D(x, y, z, pch = 16, cex = 0.6, colvar = NULL,
theta = 45, phi = 15, ticktype = "detailed",
alpha = 0.3, bty = "b2", col = "#D95F02",
xlab = "Suprafata",
ylab = "Anul constructiei",
zlab = "Pret chirie pe mp (Euro)",
main = "Model 2",
cex.lab = 0.8,
cex.axis = 0.7,
surf = list(x = x.pred,
y = y.pred,
z = z.pred2,
facets = TRUE,
border = "grey20",
alpha = 0.7,
shade = 0.2,
# fit = z.fit,
col = "lightblue"))
# Efectul variabilei yearc
#--------------------------
par(mfrow = c(1, 2))
curve(coef(munich_ma_mod2)[3]*x + coef(munich_ma_mod2)[4]*x^2 +coef(munich_ma_mod2)[5]*x^3 , 1915, 2000,
main = "efectul anului constructiei",
cex.main = 0.7,
xlab = "anul constructiei", ylab = "efectul anului constructiei",
col = "royalblue",
bty = "n")
curve(coef(munich_ma_mod3)[3]*x + coef(munich_ma_mod3)[4]*x^2 +coef(munich_ma_mod3)[5]*x^3 , 15, 100,
main = "efectul anului constructiei, codificat de la 18 la 98",
cex.main = 0.7,
xlab = "anul constructiei", ylab = "efectul anului constructiei",
col = "royalblue",
bty = "n")
# Efectul suprafeței și a anului de construcție asupra prețului chiriei în modelul considerat
xx1 = 50
xx2 = 70
effect_line_area <- data.frame(area = munich$area,
ef_area = munich_ma_mod4_pred[,1])
ef_xx1 = round(unique(effect_line_area$ef_area[which(effect_line_area$area == xx1)]), 2)
ef_xx2 = round(unique(effect_line_area$ef_area[which(effect_line_area$area == xx2)]), 2)
xx12 = 60
xx22 = 80
ef_xx12 = round(unique(effect_line_area$ef_area[which(effect_line_area$area == xx12)]), 2)
ef_xx22 = round(unique(effect_line_area$ef_area[which(effect_line_area$area == xx22)]), 2)
# plot
par(mfrow = c(1, 2))
# effect area
plot(munich$area, munich_ma_mod4_partial_resid[,1],
pch = 20,
col = "grey",
bty = "n",
ylab="Efectul suprafetei/reziduuri partiale",
xlab="Suprafata",
cex.lab = 0.7,
cex.axis = 0.6,
xaxt = "n", # specify that no ticks should be available on x axis
yaxt = "n")
effect_line_area <- data.frame(area = munich$area,
ef_area = munich_ma_mod4_pred[,1])
ord1 <- order(effect_line_area$area)
lines(effect_line_area[ord1,1], effect_line_area[ord1,2],
col = "royalblue",
lwd = 1.5)
xx1 = 50
xx2 = 70
points(c(xx1, xx2),
c(unique(effect_line_area$ef_area[which(effect_line_area$area == xx1)]),
unique(effect_line_area$ef_area[which(effect_line_area$area == xx2)])),
pch = 16)
segments(xx1, min(munich_ma_mod4_partial_resid[,1]) - 5,
xx1, unique(effect_line_area$ef_area[which(effect_line_area$area == xx1)]),
lty = 2)
segments(xx1, unique(effect_line_area$ef_area[which(effect_line_area$area == xx1)]),
min(munich$area)-10, unique(effect_line_area$ef_area[which(effect_line_area$area == xx1)]),
lty = 2)
segments(xx2, min(munich_ma_mod4_partial_resid[,1]) - 5,
xx2, unique(effect_line_area$ef_area[which(effect_line_area$area == xx2)]),
lty = 2)
segments(xx2, unique(effect_line_area$ef_area[which(effect_line_area$area == xx2)]),
min(munich$area)-10, unique(effect_line_area$ef_area[which(effect_line_area$area == xx2)]),
lty = 2)
ticks_x = c(seq(20, 160, by = 20), xx1, xx2)
ticks_x = unique(ticks_x[order(ticks_x)])
ticks_y = c(-5, 0, 5, unique(effect_line_area$ef_area[which(effect_line_area$area == xx1)]),
unique(effect_line_area$ef_area[which(effect_line_area$area == xx2)]))
ticks_y = round(unique(ticks_y[order(ticks_y)]), 2)
axis(side = 1, at = ticks_x,
cex.axis = 0.6)
axis(side = 2, at = ticks_y, las = 1,
cex.axis = 0.6)
# effect yearc
plot(munich$yearc, munich_ma_mod4_partial_resid[,2],
pch = 20,
col = "grey",
bty = "n",
ylab="Efectul anului constructiei/reziduuri partiale",
xlab="Anul constructiei",
cex.lab = 0.7,
cex.axis = 0.9)
effect_line_yearc <- data.frame(yearc = munich$yearc,
ef_yearc = munich_ma_mod4_pred[,2])
ord2 <- order(effect_line_yearc$yearc)
lines(effect_line_yearc[ord2,1], effect_line_yearc[ord2,2],
col = "royalblue",
lwd = 1.5)
abline(v = 1945, lty = 2)1.2 Cazul variabilelor explicative discrete
În secțiunea precedentă am prezentat succint care este efectul indus de o variabilă explicativă continuă asupra variabilei răspuns. În această secțiune vom ilustra cazul variabilelor explicative discrete (categoriale).
Exemplul 1.5 (Prețul chiriilor în Munchen - covariabile categoriale) Pentru prezentarea metodologiei ne plasăm în contextul setului de date Munchen referitor la prețul chiriilor din orașul Munchen și investigăm modul în care locația imobilului (variabila locatie - location) influențează prețul chiriei locuinței. Variabila locatie admite trei categorii: 1 = locație medie, 2 = locație bună și 3 = locație de top.
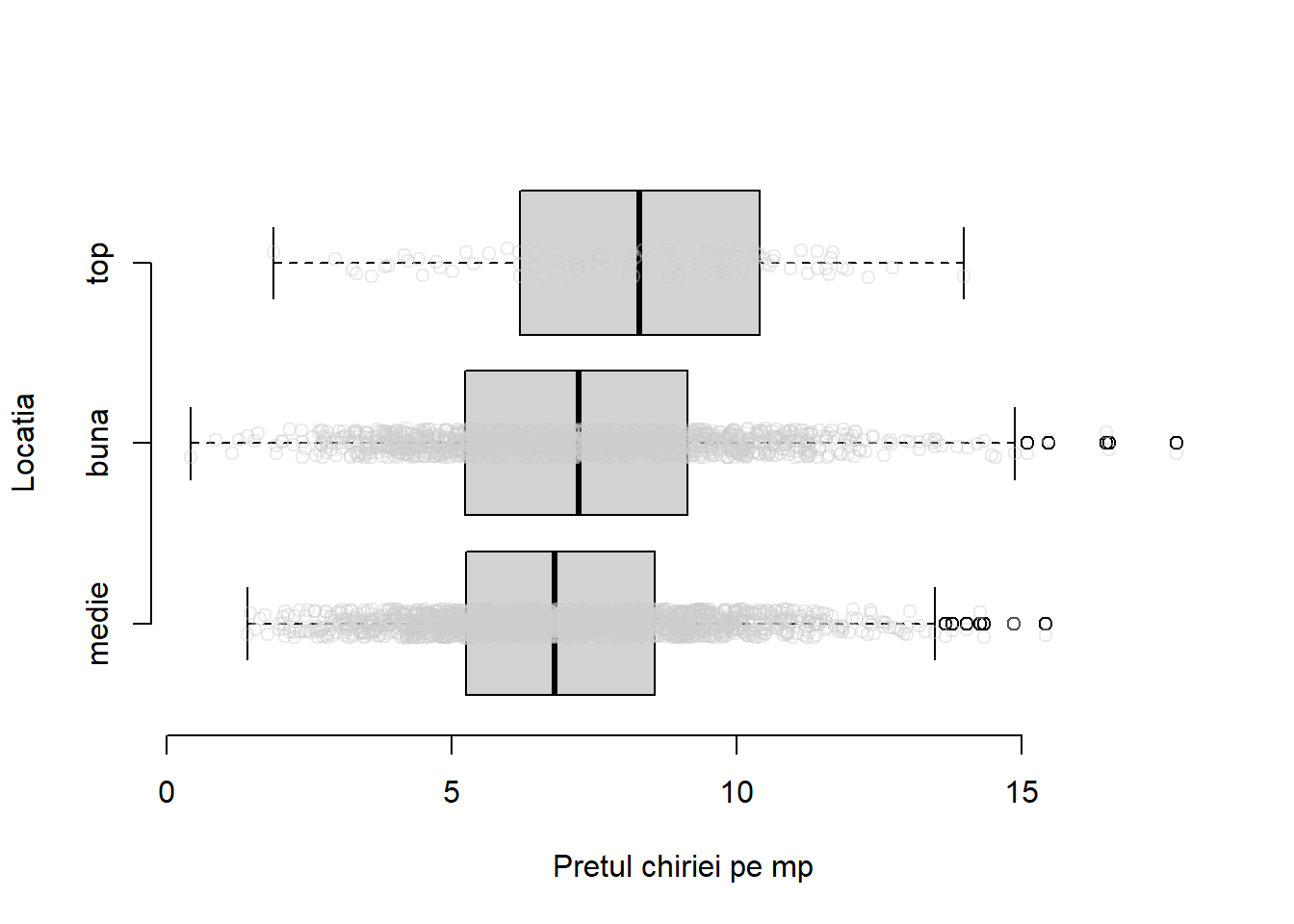
Dacă am modela prețul chiriei pe metrul pătrat în funcție de locație folosind un model de regresie liniară simplă și tratând covariabila locatie ca pe o variabilă continuă am avea
\[ pret{\_m^2}_i = \beta_0 + \beta_1\times locatie_i + \varepsilon_i \]
care în urma estimării ar conduce la
\[ \widehat{pret{\_m^2}_i} = 6.544 + 0.393\times locatie_i. \]
Observăm că, datorită modului în care am ales codificarea variabile locatie, prețul mediu al chiriilor pe metrul pătrat pentru locuințele care se situează într-o locație bună este de două ori mai mare decât al celor care se află într-o locație medie (0.393 Euro față de 0.786 Euro) iar cel al locuințelor dintr-o locație de top este de trei ori mai mare. Bineînțeles că dacă am fi codificat variabila locatie prin 2 = locație medie, 6 = locație bună și 8 = locație de top atunci efectele ar fi fost diferite (apartamentele din locații de top ar fi fost de patru ori mai scumpe, în medie, față de cele din locație medie).
Prin urmare, constatăm că modul în care codificăm covariabila categorială influențează direct rezultatele și modul de interpretare. Problema care apare este că în cazul variabilelor categoriale distanțele dintre categorii nu au întotdeauna aceeași însemnătate, precum nici apartamentele dintr-o locație bună nu sunt de două ori (sau de trei ori) mai bune față de cele situate într-o locație medie. O modalitate de a corecta această problemă constă în introducerea unor noi covariabile, denumite variabile ajutătoare - dummy, care să permită estimarea efectului indus de fiecare categorie a variabilei explicative în cauză. Mai precis, pentru variabila locatie introducem trei noi variabile ajutătoare alotatie, glocatie și tlocatie de tip variabilă indicator după cum locuința se află într-o locație medie (average), bună (good) respectiv de top astfel
\[ \begin{aligned} alocatie &= \left\{\begin{array}{ll}1, & \text{locatie = 1 (locație medie)}\\ 0, & \text{altfel}\end{array}\right.\\ glocatie &= \left\{\begin{array}{ll}1, & \text{locatie = 2 (locație bună)}\\ 0, & \text{altfel}\end{array}\right.\\ tlocatie &= \left\{\begin{array}{ll}1, & \text{locatie = 3 (locație de top)}\\ 0, & \text{altfel}\end{array}\right. \end{aligned} \]
Folosind cele trei variabile ajutătoare pentru modelarea prețului chiriei pe metrul pătrat avem modelul de regresie
\[ pret{\_m^2}_i = \beta_0 + \beta_1\times alocatie_i + \beta_2\times glocatie_i + \beta_3\times tlocatie_i + \varepsilon_i \]
care prezintă acum o nouă problemă, și anume că parametrii acestuia nu sunt identifiabili, deci nu pot fi determinați în mod unic. Acest lucru se poate vedea imediat dacă ne uităm la efectele celor trei covariabile: apartamentele dintr-o locație medie impun un efect asupra prețului mediu al chiriei de \(\beta_0 + \beta_1\) (\(alocatie_i = 1\), \(glocatie_i = 0\) și \(tlocatie_i = 0\)), iar cele care se situează în locații bune și de top prezintă un efect de \(\beta_0 + \beta_2\) și respectiv \(\beta_0 + \beta_3\). Termenul \(\beta_0\) (ordonata la origine) apare în toate cele trei efecte astfel, adăugând o cantitate constantă la \(\beta_0\) și scăzând-o apoi din coeficienții \(\beta_1\), \(\beta_2\) și \(\beta_3\) conduce la același efect asupra variabilei dependente. Același lucru se putea observa și dacă ne uitam la matricea de design \(\symbf X\) care acum nu mai avea rang plin, vectorii coloană nu mai sunt liniar independenți, în fapt primul vector coloană este egal cu suma vectorilor coloană 2, 3 și 4.
Problema identifiabilității se poate rezolva în mai multe moduri dar aici vom considera cazul cel mai uzual și anume eliminarea din model a unei variabile ajutătoare din cele trei nou create. Prin urmare, dacă eliminăm variabila alocatie obținem modelul
\[ pret{\_m^2}_i = \beta_0 + \beta_1\times glocatie_i + \beta_2\times tlocatie_i + \varepsilon_i \]
care în urma estimării devine
\[ \widehat{pret{\_m^2}_i} = 6.957 + 0.316\times glocatie_i + 1.216\times tlocatie_i. \]
Trebuie să avem grijă ca atunci când interpretăm coeficienții modelului de mai sus și efectele induse să ținem seama de categoria (variabila ajutătoare) eliminată - în cazul nostru locație medie. Această categorie se numește categorie de referință. Astfel, pentru apartamentele situate într-o locație medie obținem un efect estimat \(\hat{\beta_0} = 6.957\), pentru cele din locație bună \(\hat{\beta_0} + \hat{\beta_1} = 7.273\) iar pentru cele din locație de top efectul este \(\hat{\beta_0} + \hat{\beta_3} = 8.173\). Constatăm că în comparație cu apartamentele aflate într-o locație medie, prețul mediu al chiriei pe metrul pătrat al apartamentelor situate într-o locație bună este cu \(0.316\) Euro mai mult iar cel al apartamentelor aflate într-o locație de top cu \(1.216\) Euro mai mult.
Arată codul R din exemplul de mai sus
#-------------------------------------------------------
# Prețul chiriilor în Munchen - covariabile categoriale
#-------------------------------------------------------
# fara dummy variables
munich_cat_mod1 <- lm(rentsqm ~ location,
data = munich)
coef_munich_cat_m1 <- round(coef(munich_cat_mod1), 3)
# plot
par(bty = "n")
boxplot(rentsqm ~ location, data = munich,
bty = "n",
names = c("medie", "buna", "top"),
ylab = "Locatia",
xlab = "Pretul chiriei pe mp",
horizontal = TRUE)
points(munich$rentsqm, jitter(munich$location, factor = 0.4),
col = grey(0.8, 0.4))
# dummy coding
munich <- munich %>%
mutate(alocation = ifelse(location == 1, 1, 0),
glocation = ifelse(location == 2, 1, 0),
tlocation = ifelse(location == 3, 1, 0))
munich_cat_mod2 <- lm(rentsqm ~ alocation + tlocation,
data = munich)
coef_munich_cat_m2 <- round(coef(munich_cat_mod2), 3)
munich_cat_mod3 <- lm(rentsqm ~ glocation + tlocation,
data = munich)
coef_munich_cat_m3 <- round(coef(munich_cat_mod3), 3)În general, atunci când vrem să modelăm efectul unei variabile predictor categoriale \(z\) cu \(c\) categorii, \(z\in\{1,2,\ldots,c\}\), fixăm o categorie de referință (de obicei categoria cea mai frecventă sau categoria de control), în acest caz categoria \(c\), și definim \(c-1\) variabile de tip dummy
\[ x_{i1} = \left\{\begin{array}{ll}1, & z_i = 1,\\0, & \text{altfel}\end{array}\right. \quad\cdots\quad x_{i,c-1} = \left\{\begin{array}{ll}1, & z_i = c-1,\\0, & \text{altfel}\end{array}\right. \]
pe care să le includem ca variabile explicative în model
\[ y_i = \beta_0 + \beta_1 x_{i1} + \cdots + \beta_{i,c-1} x_{i, c-1} + \varepsilon_i. \]
Efectele estimate trebuie interpretate în raport cu categoria de referință. Este important de menționat că există mai multe scheme de codificare a variabilelor explicative categoriale (simple coding, deviation sau effect coding, Helmert coding, Orthogonal polynomial coding, etc.), cea de mai sus este cea mai des întâlnită.
Înainte de a încheia această secțiune vom ilustra o serie (patru) de metode prin care putem crea în R variabilele ajutătoate de tip dummy. Vom începe prin crearea efectivă a variabilelor folosind librăria tidyverse (sau funcțiile de bază):
# 1) creare variabilelor alocation, glocation si tlocation
munich <- munich %>%
mutate(alocation = ifelse(location == 1, 1, 0),
glocation = ifelse(location == 2, 1, 0),
tlocation = ifelse(location == 3, 1, 0))
# exemplu
lm(rentsqm ~ alocation + tlocation, data = munich)
lm(rentsqm ~ glocation + tlocation, data = munich)O a doua metodă este de a folosi funcția I() (permite interpretarea aritmetică a expresiei din paranteză) în care specificăm categoria variabilei explicative care vrem să fie inclusă în model. Această metodă ne permite fixarea unei categorii de referință, prin eliminarea ei din model.
# 2) Folosirea functei I()
lm(rentsqm ~ I(location == 1) + I(location == 3), data = munich)
lm(rentsqm ~ I(location == 2) + I(location == 3), data = munich)În al treilea rând putem folosi funcția factor() care asigură programul R că avem de-a face cu o variabilă categorială, fiecare categorie numindu-se nivel (level).
# 3) Folosirea functiei factor
munich$locationf <- factor(munich$location)
lm(rentsqm ~ locationf, data = munich)
# sau echivalent
lm(rentsqm ~ factor(location), data = munich)Ultima funcție este funcția contr.treatment(), care în fapt se folosește în pereche cu funcția contrasts(). Funcția contr.treatment() ne permite specificarea categoriei de referință prin includerea opțiunii base =.
# 4) Folosirea functiei contr.treatment
munich$locationf <- factor(munich$location)
contrasts(munich$locationf) <- contr.treatment(3, base = 2)
# 3 - este numarul de niveluri iar base reprezinta nivelul de referinta
lm(rentsqm ~ locationf, data = munich)
contrasts(munich$locationf) <- contr.treatment(3, base = 1)
lm(rentsqm ~ locationf, data = munich)1.3 Interacția dintre două covariabile
Atunci când pentru fiecare variabilă explicativă efectul ei asupra răspunsului mediu nu depinde de nivelul celorlalte covariabile din model spunem că variabilele predictor au efect aditiv sau nu interacționează unele cu celelalte. În cazul în care efectul unei covariabile depinde de nivelul cel puțin a uneia dintre celelalte covariabile, spunem că există un efect de interacție între ele. Un exemplu simplu de model de regresie liniară neaditiv este
\[ y = \beta_0 + \beta_1 x_1 + \beta_2 x_2 + \beta_3 x_1x_2 + \varepsilon \]
unde termenul \(\beta_3 x_1x_2\) se numește termen de interacție sau interacția dintre \(x_1\) și \(x_2\) (interaction effect). Cum termenii \(\beta_1 x_1\) și \(\beta_2 x_2\) depind doar de covariabilele \(x_1\) și respectiv \(x_2\), se numesc efecte principale (main effects). Evident că modelul de mai sus este un caz particular de model de regresie liniară deoarece putem nota termenul \(x_1x_2\) cu \(x_3\). În general, produsul a două sau mai multe efecte principale diferite reprezintă o interacție.
Pentru a înțelege care este impactul termenului de interacție asupra răspunsului mediu să considerăm că variabila predictor \(x_1\) se modifică prin cantitatea \(\delta = 1\):
\[ \mathbb{E}[y|x_1 + \delta, x_2] - \mathbb{E}[y|x_1, x_2] = \beta_1\delta + \beta_3\delta x_2 = \beta_1 + \beta_3 x_2 \]
ceea ce arată că, în cazul în care \(\beta_3\neq 0\), răspunsul mediu se modifică prin \(\beta_1 + \beta_3 x_2\) unități odată cu creșterea cu o unitate a lui \(x_1\) și păstrarea la nivel constant a lui \(x_2\). Prin urmare dacă efectul indus asupra răspunsului mediu de schimbarea unei variabile explicative depinde de valoarea unei alte variabile explicative atunci avem de-a face cu un efect de interacție. De cele mai multe ori, atunci când semnele coeficienților \(\beta_1\) și \(\beta_2\) sunt la fel (negative sau pozitive) și semnul lui \(\beta_3\) coincide cu acestea spunem că avem un efect de întărire (reinforcement effect) iar când semnul lui \(\beta_3\) este contrar atunci avem efect de intersecție (intersection effect).
Exemplul 1.6 (Prețul chiriilor în Munchen - interacție) În Figura 1.9 avem ilustrat, pentru setul de date Munchen în care am eliminat proprietățile din locații de top, variația prețului mediu pe metrul pătrat în funcție de suprafața de locuit în situația în care apartamentele se găsesc într-o locație bună sau medie și atunci când avem un efect de interacție (figura din dreapta) între cele două covariabile și respectiv când nu avem acest efect (figura din stânga).
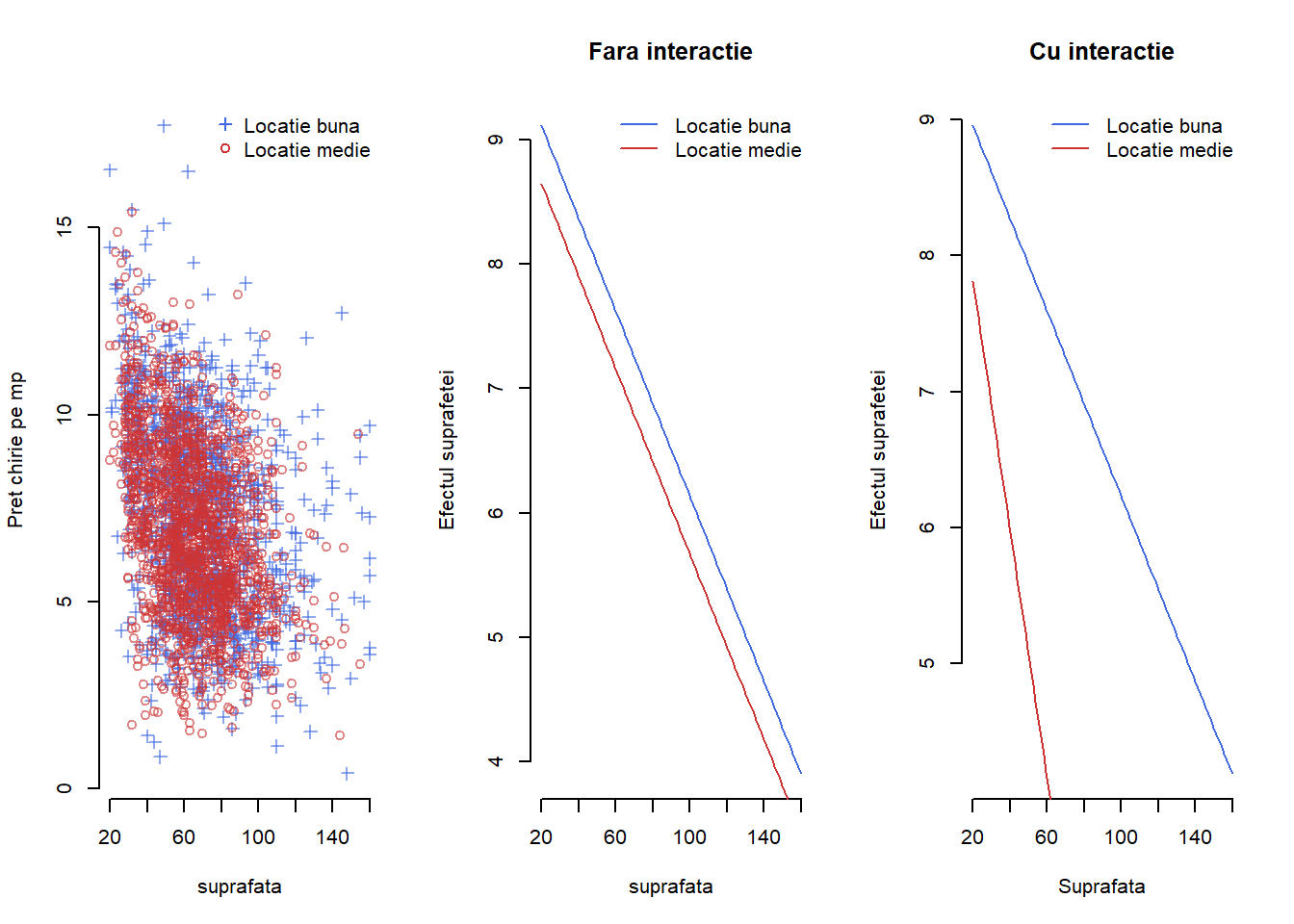
Arată codul R din exemplul de mai sus
#------------------------------------------
# Prețul chiriilor în Munchen - interacție
#------------------------------------------
munich_sub_top <- munich %>%
filter(location != 3) %>% # fara locatii de top
mutate(alocation = ifelse(location == 1, 1, 0),
glocation = ifelse(location == 2, 1, 0))
par(mfrow = c(1,3))
# punctele
munich_sub_top1 <- munich_sub_top %>%
filter(alocation == 1) # average location
munich_sub_top0 <- munich_sub_top %>%
filter(alocation == 0) # good location
plot(munich_sub_top$area, munich_sub_top$rentsqm,
type = "n",
xlab = "suprafata",
ylab = "Pret chirie pe mp",
bty = "n")
points(munich_sub_top0$area, munich_sub_top0$rentsqm,
pch = 3, col = "royalblue")
points(munich_sub_top1$area, munich_sub_top1$rentsqm,
pch = 1, col = "brown3")
legend("topright", legend = c("Locatie buna", "Locatie medie"),
pch = c(3, 1),
col = c("royalblue", "brown3"),
bty = "n")
# fara interactie
mod_int_noint <- lm(rentsqm ~ area + alocation,
data = munich_sub_top)
coef_mod_int_noint <- coef(mod_int_noint)
x_area <- seq(min(munich_sub_top$area), max(munich_sub_top$area), length.out = 100)
plot(x_area, coef_mod_int_noint[1] + coef_mod_int_noint[2]*x_area,
type = "l", lty = 1,
col = "royalblue",
xlab = "suprafata",
ylab = "Efectul suprafetei",
main = "Fara interactie",
bty = "n")
lines(x_area, coef_mod_int_noint[1] + coef_mod_int_noint[2]*x_area + coef_mod_int_noint[3],
lty = 1, col = "brown3")
legend("topright", legend = c("Locatie buna", "Locatie medie"),
lty = c(1, 1),
col = c("royalblue", "brown3"),
bty = "n")
# cu interactie
mod_int_withint <- lm(rentsqm ~ area + alocation + area:alocation,
data = munich_sub_top)
coef_mod_int_withint <- coef(mod_int_withint)
x_area <- seq(min(munich_sub_top$area), max(munich_sub_top$area), length.out = 100)
plot(x_area, coef_mod_int_withint[1] + coef_mod_int_withint[2]*x_area,
type = "l", lty = 1,
col = "royalblue",
xlab = "Suprafata",
ylab = "Efectul suprafetei",
main = "Cu interactie",
bty = "n")
lines(x_area, coef_mod_int_withint[1] + coef_mod_int_withint[2]*x_area + coef_mod_int_withint[3]*x_area,
lty = 1, col = "brown3")
legend("topright", legend = c("Locatie buna", "Locatie medie"),
lty = c(1, 1),
col = c("royalblue", "brown3"),
bty = "n")Ca regulă, în cazul unui model de regresie liniară care conține un termen de interacție sau o putere este recomandat ca acesta să conțină și efectele principale corespunzătoare care au alcătuit termenul de interacție sau putere. De exemplu, dacă în modelul de regresie apar termenii \(x_1^3\) și respectiv \(x_2x_3x_4\) atunci modelul ar trebui să conțină și termenii (efectele principale) \(x_1\), \(x_2\), \(x_3\) și respectiv \(x_4\).
În subsecțiunile care urmează, vom trata separat cazurile în care efectul de interacție apare între două variabile categoriale sau între o variabilă categorială și una continuă.
1.3.1 Interacția dintre două variabile categoriale
În această secțiune vom trata cazul în care în model apar două variabile predictor calitative \(x_1\) și \(x_2\), categoriale, cu \(c\) și respectiv \(m\) categorii și suntem interesați de efectul interacției dintre cele două asupra răspunsului mediu. Cum putem modela efectul fiecărei variabile predictor categoriale prin intermediul a \(c-1\) și respectiv \(m-1\) variabile ajutătoare de tip indicator (dummy) este suficient să ne limităm atenția asupra covariabilelor binare. Într-adevăr, cele două variabile explicative \(x_1\) și \(x_2\) induc în modelul de regresie \(cm-1\) termeni, fiecare fiind o variabilă binară.
Exemplul 1.7 (Prețul chiriilor în Munchen - interacția dintre două covariabile categoriale) În contextul setului de date Munchen să presupunem că vrem să investigăm relația dintre prețul mediu al chiriilor pe metrul pătrat și tipul de baie (0 = standard, 1 = premium), respectiv bucătărie (0 = standard, 1 = premium) cu care este dotat apartamentul. În acest caz, cele două covariabile binare \(x_1 = bucatarie\) și \(x_2 = baie\) conduc la modelul de regresie
\[ pret{\_m^2}_i = \beta_0 + \beta_1\times bucatarie_i + \beta_2\times baie_i + \beta_3\times bucatarie_i\cdot baie_i + \varepsilon_i \]
care în urma estimării devine
\[ \widehat{pret{\_m^2}_i} = 7.024 + 1.419\times bucatarie_i + 0.401\times baie_i + 0.287\times bucatarie_i\cdot baie_i \]
Astfel, coeficientul \(\hat{\beta_1} = 1.419\) măsoară efectul indus de o bucătărie premium asupra prețului mediu al chiriei pe metrul pătrat, \(\hat{\beta_2} = 0.401\) măsoară efectul indus de o baie premium iar \(\hat{\beta_3} = 0.287\) măsoară efectul adițional pentru locuințele care au și baie și bucătărie premium. Observăm că față de un apartament cu dotări standard (baie și bucătărie standard), apartamentele care au doar bucătărie premium sunt mai scumpe în medie cu 1.419 Euro pe metrul pătrat pe când cele care au doar baie premium au un preț mai ridicat cu 0.401 Euro. Având și baie și bucătărie premium face ca prețul mediu al chiriei pe metrul pătrat să crească cu 2.107 Euro.
Dacă ne interesăm acum la efectul interacției dintre covariabila locația apartamentului (\(locatie\) - 1 = medie, 2 = bună, 3 = de top) și covariabila tipul de bucătărie (\(bucatarie\) - 0 = standard sau 1 = premium) asupra prețului chiriei pe metrul pătrat, atunci avem modelul
\[ \begin{aligned} pret{\_m^2}_i &= \beta_0 + \beta_1\times alocatie_i + \beta_2\times glocatie_i + \beta_3\times bucatarie_i + \\ &\quad+\beta_4\times alocatie_i\cdot bucatarie_i + \beta_5\times glocatie_i\cdot bucatarie_i + \varepsilon_i \end{aligned} \]
în care am considerat toate combinațiile posibile între valorile celor două variabile explicative (cu excepția categoriilor de referință - în acest caz locații de top). Efectul variabilei explicative \(locatie\) este explicat prin intermediul a două variabile ajutătoare binare \(alocatie\) și \(glocatie\) folosind ca și categorie de referință locațiile din zone de top. Interpretarea coeficienților este următoarea:
\[ \begin{aligned} \beta_0: & \text{ efectul locație = de top și bucătărie = standard}\\ \beta_0 + \beta_1: & \text{ efectul locatie = medie și bucatarie = standard}\\ \beta_0 + \beta_2: & \text{ efectul locatie = bună și bucatarie = standard}\\ \beta_0 + \beta_3: & \text{ efectul locatie = de top și bucatarie = premium}\\ \beta_0 + \beta_1 + \beta_3 + \beta_4: & \text{ efectul locatie = medie și bucatarie = premium}\\ \beta_0 + \beta_2 + \beta_3 + \beta_5: & \text{ efectul locatie = bună și bucatarie = premium}\\ \end{aligned} \]
Putem observa că, față de un apartament de top cu bucătărie standard, un apartament dintr-o locație medie cu același tip de bucătărie are un preț mediu al chiriei pe metrul pătrat cu \(\hat{\beta_1} = -1.279\) Euro mai mic pe când un apartament dintr-o zonă bună cu o bucătărie premium are un preț mediu cu \(\hat{\beta_2} + \hat{\beta_3} + \hat{\beta_5} = 1.052\) Euro mai mare.
Arată codul R din exemplul de mai sus
#-----------------------------------------------------------------------------
# Prețul chiriilor în Munchen - interacția dintre două covariabile categoriale
#-----------------------------------------------------------------------------
# Model cu interactii 1
munich_int_mod1 <- lm(rentsqm ~ kitchen * bath, data = munich)
coef_munich_int_mod1 <- round(coef(munich_int_mod1), 3)
# Model cu interactii 2
munich_int_mod2 <- lm(rentsqm ~ (alocation + glocation)*kitchen, data = munich)
coef_munich_int_mod2 <- round(coef(munich_int_mod2), 3)1.3.2 Interacția dintre o variabilă categorială și una continuă
Să presupunem că vrem să modelăm efectul pe care îl are interacția dintre o covariabilă continuă \(x\) și una discretă (categorială) \(z\) cu \(c\) categorii asupra răspunsului mediu. Într-o primă etapă pentru a include efectul variabilei explicative \(z\) vom fixa o categorie ca și categorie de referință și vom introduce, ca și până acum, \(c-1\) variabile ajutătoare de tip indicator (dummy). Pentru a simplifica discuția vom considera că variabila categorială \(z\in\{0,1\}\) este o variabilă de tip indicator, binară, și vom presupune că efectele principale și efectele de interacție datorate covariabilelor \(x\) și \(z\) sunt liniare în raport cu răspunsul prin urmare avem un model de tipul
\[ y = \beta_0 + \underbrace{\beta_1 x + \beta_2 z}_{\text{efecte principale}} + \underbrace{\beta_3 xz}_{\text{efect de interacție}} + \cdots + \varepsilon \]
unde prin \(\cdots\) înțelegem că în model ar putea intra și alți termeni care depind de alte covariabile. În general, ar fi trebuit să includem în model toți cei \(2c-1\) termeni: efecte principale \(x, z_1,\ldots,z_{c-1}\) și interacții \(x z_1,\ldots,x z_{c-1}\).
În ceea ce privește interpretarea termenilor modelului, aceasta se poate face atât din perspectiva covariabilei continue cât și din cea a celei discrete. Astfel, în raport cu covariabila \(x\), \(\beta_1 x\) este efectul liniar al covariabilei \(x\) atunci când \(z = 0\) iar \(\beta_2 + (\beta_1 + \beta_3)x\) este efectul liniar indus de \(x\) atunci când \(z = 1\). Alternativ, în raport cu \(z\), \(\beta_2 + \beta_3 x\) reprezintă efectul produs de diferența dintre observațiile pentru care \(z = 1\) și \(z = 0\). Această diferență depinde de valorile covariabilei \(x\), nu este constantă ca și în cazul unui model fără interacții.
Exemplul 1.8 (Prețul chiriilor în Munchen - interacția dintre o covariabilă continuă și una discretă) În acest exemplu vom ilustra efectul de interacție dintre o variabilă explicativă continuă și una discretă folosindu-ne de setul de date Munchen. Ne propunem să modelăm relația dintre prețul net al chiriei unui apartament în funcție de suprafața acestuia și tipul de locație în care se află. În acest context avem de-a face cu o variabilă predictor cu trei categorii (locație de top, bună și respectiv medie) pentru care vom introduce două variabile ajutătoare de tip indicator \(alocatie\) și \(glocatie\), ținând ca nivel de referință categoria locațiilor de top. Presupunând că atât efectele principale cât și cele datorate interacțiilor intră liniar în model, avem
\[ \begin{aligned} pret_i &= \beta_0 + \beta_1\times suprafata_i + \beta_2\times alocatie_i + \beta_3\times glocatie_i + \\ &\quad + \beta_4\times suprafata_i\cdot alocatie_i + \beta_5\times suprafata_i\cdot glocatie_i + \varepsilon_i \end{aligned} \]
unde prin estimare devine
\[ \begin{aligned} \widehat{pret_i} &= 137.924 + 6.22\times suprafata_i + 11.824\times alocatie_i + 1.473\times glocatie_i + \\ &\quad -1.846\times suprafata_i\cdot alocatie_i -1.274\times suprafata_i\cdot glocatie_i. \end{aligned} \]
Putem interpreta efectele după cum urmează (acestea pot fi vizualizate în figura de mai jos):
- \(\beta_1\times suprafata_i = 6.22\times suprafata_i\) - efectul suprafeței de locuit pentru apartamentele situate într-o locație de top asupra prețului mediu net al chiriei (\(alocation = 0\) și \(glocation = 0\))
- \(\beta_2 + (\beta_1+\beta_4)\times suprafata_i = 11.824 + 4.374\times suprafata_i\) - efectul suprafeței de locuit pentru apartamentele situate într-o locație medie
- \(\beta_3 + (\beta_1+\beta_5)\times suprafata_i = 1.473 + 4.946\times suprafata_i\) - efectul suprafeței de locuit pentru apartamentele situate într-o locație bună
- \(\beta_3 + \beta_5\times suprafata_i = 1.473 -1.274\times suprafata_i\) - efectul diferență pentru apartamentele care se află într-o locație bună față de cele care se află într-o locație de top; coeficientul \(\hat{\beta_5} = -1.274\) negativ implică faptul că prețul mediu net al chiriilor pentru apartamentele aflate într-o zonă de top sunt întotdeauna mai mari decât cele dintr-o zonă bună, pentru fiecare metru pătrat adăugat suprafeței de locuit face ca diferența dintre prețul mediu net al chiriei pentru locații bune și să scadă cu 1.274 Euro față de cel al locuințelor situate în locații de top
- \(\beta_2 + \beta_4\times suprafata_i = 11.824 -1.846\times suprafata_i\) - efectul diferență pentru apartamentele care se află într-o locație medie față de cele care se află într-o locație de top
- \(\beta_3 -\beta_2 + (\beta_5 - \beta_4)\times suprafata_i = -10.351 + 0.572\times suprafata_i\) - efectul diferență pentru apartamentele care se află într-o locație bună față de cele care se află într-o locație medie
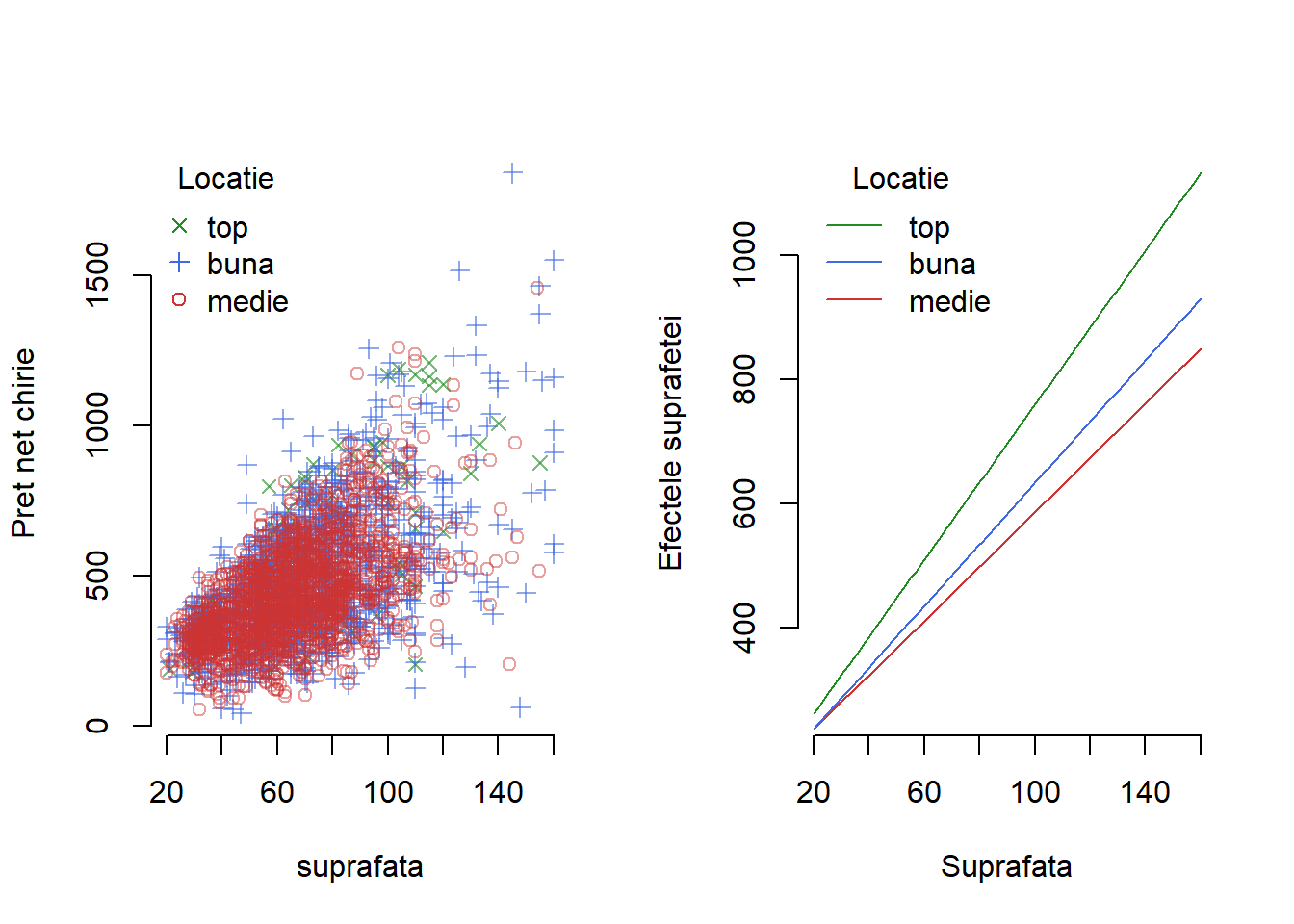
Arată codul R din exemplul de mai sus
#---------------------------------------------------------------
# Prețul chiriilor în Munchen - interacția continuă vs discretă
#---------------------------------------------------------------
# model interactii 3 - cont + discret
munich_int_mod3 <- lm(rent ~ area * (alocation + glocation), data = munich)
coef_munich_int_mod3 <- round(coef(munich_int_mod3), 3)
# Efectul suprafeței asupra prețului chiriei în raport cu locația
par(mfrow = c(1, 2))
# puncte
munich_top <- munich %>%
filter(location == 3) # top location
munich_avg <- munich %>%
filter(location == 1) # average location
munich_good <- munich %>%
filter(location == 2) # good location
plot(munich_sub_top$area, munich_sub_top$rent,
type = "n",
xlab = "suprafata",
ylab = "Pret net chirie",
bty = "n")
points(munich_top$area, munich_top$rent,
pch = 4, col = addTrans("forestgreen", 150))
points(munich_good$area, munich_good$rent,
pch = 3, col = addTrans("royalblue", 150))
points(munich_avg$area, munich_avg$rent,
pch = 1, col = addTrans("brown3", 120))
legend("topleft", legend = c("top", "buna", "medie"),
title = "Locatie",
pch = c(4, 3, 1),
col = c("forestgreen", "royalblue", "brown3"),
bty = "n")
# efect
x_area <- seq(min(munich$area), max(munich$area), length.out = 100)
c_munich_int_mod3 <- coef(munich_int_mod3)
e_munich_int_mod3_top <- c_munich_int_mod3[1] +
c_munich_int_mod3[2]*x_area
e_munich_int_mod3_avg <- c_munich_int_mod3[1] +
c_munich_int_mod3[2]*x_area + c_munich_int_mod3[3] + c_munich_int_mod3[5]*x_area
e_munich_int_mod3_good <- c_munich_int_mod3[1] +
c_munich_int_mod3[2]*x_area + c_munich_int_mod3[4] + c_munich_int_mod3[6]*x_area
plot(x_area, e_munich_int_mod3_top,
type = "l",
xlab = "Suprafata",
ylab = "Efectele suprafetei",
bty = "n",
col = "forestgreen")
lines(x_area, e_munich_int_mod3_avg,
type = "l",
col = "brown3")
lines(x_area, e_munich_int_mod3_good,
type = "l",
col = "royalblue")
legend("topleft",
legend = c("top", "buna", "medie"),
title = "Locatie",
col = c("forestgreen", "royalblue", "brown3"),
lty = c(1,1,1),
bty = "n")În exemplul anterior am presupus că efectul principal indus de covariabila continuă și efectul de interacție dintre covariabila continuă și cea categorială este liniar asupra răspunsului mediu dar putem include în model și efecte neliniare. Să presupunem că efectul principal indus de covariabila \(x\) este \(f_1(x)\) și efectul de interacție este \(f_2(x)z\) (pentru cazul de liniaritate aveam \(f_1(x) = \beta_1 x\) și respectiv \(f_2(x) = \beta_2 x\)) ceea ce conduce la modelul
\[ y = \beta_0 + \beta_1 z + f_1(x) + \underbrace{f_2(x)z}_{\text{efect de interacție}} + \cdots + \varepsilon \]
Ca și în secțiunea Cazul variabilelor explicative continue, neliniaritatea efectelor poate fi dobândită atât prin folosirea de transformări asupra covariabilelor cât și prin intermediul polinoamelor. De exemplu, putem considera că \(f_1(x) = \beta_2 x + \beta_3 \log(x)\) iar \(f_2(x) = \beta_4 x + \beta_5 x^2\) și în acest caz modelul devine
\[ y = \beta_0 + \beta_1 z + \beta_2 x + \beta_3 \log(x) + \beta_4 xz + \beta_5 x^2z + \cdots + \varepsilon. \]
Pentru interpretarea modelului avem:
- \(f_1(x)\) - efectul neliniar indus de covariabila continuă \(x\) atunci când \(z = 0\)
- \(\beta_1 + f_1(x) + f_2(x)\) - efectul neliniar indus de covariabila continuă \(x\) atunci când \(z = 1\); cele două curbe \(f_1(x)\) și \(\beta_1 + f_1(x) + f_2(x)\) prezintă intensitatea interacției, în cazul lipsei acesteia curbele fiind paralele (ar fi o translație cu \(\beta_1\))
- \(\beta_1 + f_2(x)\) - efectul diferență apărut pentru observațiile cu \(z = 1\) în raport cu cele pentru care \(z = 0\)
Pentru a facilita interpretarea, efectul principal \(f_1(x)\) trebuie centrat în zero, același lucru nefiind necesar pentru \(f_2\).
Exemplul 1.9 (Prețul chiriilor în Munchen - interacția dintre o covariabilă continuă și una discretă - efect neliniar) Pentru a ilustra efectul neliniar de interacție dintre o covariabilă continuă și una discretă vom considera, în contextul setului de date Munchen, acele apartamente care se află în locații bune sau locații de tip mediu (vom folosi doar covariabila \(glocation\)). Dorim să modelăm relația dintre prețul chiriei pe metrul pătrat în funcție de suprafața de locuit și tipul de locație și vom folosi ca efect principal pentru suprafață transformarea \(\frac{1}{x}\) ca și în Exemplul 1.1. Presupunând că avem un efect de interacție liniar între suprafață și tipul locației atunci avem modelul
\[ pret{\_m^2}_i = \beta_0 + \beta_1\times glocatie_i + f_1(suprafata_i) + f_2(suprafata_i)\cdot glocatie_i + \varepsilon_i \]
unde \(f_1(suprafata_i) = \beta_1\left(\underbrace{\frac{1}{suprafata_i} - \overline{\frac{1}{suprafata_i}}}_{suprafata{\_inv\_cen}_i}\right)\) iar \(f_2(suprafata_i) = \beta_3\times suprafata_i\). În urma estimării găsim
\[ \widehat{pret{\_m^2}_i} = 6.918 + 0.334\times glocatie_i + 147.152\times suprafata{\_inv\_cen}_i + 0.001suprafata_i\cdot glocatie_i \]
Pentru interpretarea rezultatelor am inclus în Figura 1.11 de mai jos efectul estimat \(\hat{f_1}(suprafata_i)\) a suprafeței de locuit în locații medii (cu roșu) și efectul estimat \(\hat{\beta_1} + \hat{f_1}(suprafata_i) + \hat{f_2}(suprafata_i)\) al suprafeței pentru apartamentele din locații bune (albastru).
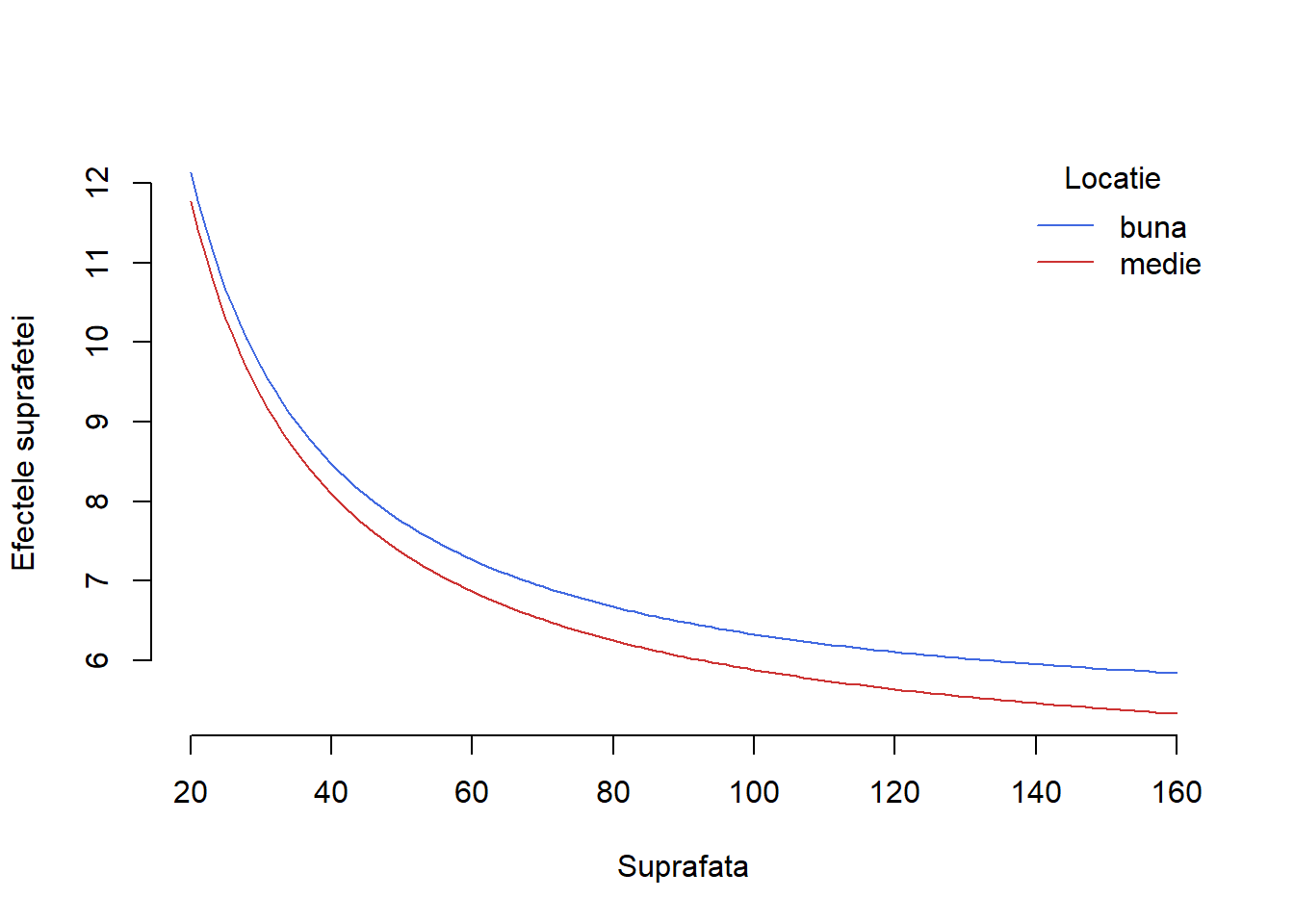
Constatăm că efectele suprafeței pentru apartamentele situate în locații bune și medii sunt similare, chiar dacă cele două curbe nu sunt paralele (ceea ce implică un efect de interacție). Dacă suprafața de locuit crește atunci prețul mediu pe metrul pătrat scade pentru ambele locații. De asemenea, se observă că apartamentele situate în locații bune sunt întotdeauna mai scumpe decât cele din locații medii, indiferent de mărimea acestora. Diferența de preț este mai mică pentru apartamentele cu suprafața mai mică față de cele cu suprafața mai mare ceea ce sugerează că odată cu creșterea în suprafață găsim și o creștere în diferența medie de preț pe metrul pătrat între imobile situare în locații bune și medii, iar această diferență crește liniar.
Arată codul R din exemplul de mai sus
#--------------------------------------------------------------------------
# Prețul chiriilor în Munchen - interacția continuă vs discretă - neliniar
#--------------------------------------------------------------------------
# model interactii 4 - cont + discret
munich_ag <- munich %>% filter(location != 3)
# munich_int_mod4 = lm(rentsqm ~ I(1/area - mean(1/area)) + area* tlocation - area, data = munich_at)
munich_int_mod4 <- lm(rentsqm ~ glocation + I(1/area - mean(1/area)) + area: glocation, data = munich_ag)
coef_munich_int_mod4 <- round(coef(munich_int_mod4), 3)
# Efectul estimat a suprafeței de locuit pentru apartamentele din locații medii (cu roșu) și bune (albastru)
x_area <- munich_ag$area
x_area <- x_area[order(x_area)]
c_munich_int_mod4 <- coef(munich_int_mod4)
e_munich_int_mod4_top <- c_munich_int_mod4[1] +
c_munich_int_mod4[2] + c_munich_int_mod4[3]*(1/x_area - mean(1/x_area)) +
c_munich_int_mod4[4]*x_area
e_munich_int_mod4_avg <- c_munich_int_mod4[1] +
c_munich_int_mod4[3]*(1/x_area - mean(1/x_area))
plot(x_area, e_munich_int_mod4_top,
type = "l",
xlab = "Suprafata",
ylab = "Efectele suprafetei",
bty = "n",
ylim = c(min(e_munich_int_mod4_top, e_munich_int_mod4_avg),
max(e_munich_int_mod4_top, e_munich_int_mod4_avg)),
col = "royalblue")
lines(x_area, e_munich_int_mod4_avg,
type = "l",
col = "brown3")
legend("topright",
legend = c("buna", "medie"),
title = "Locatie",
col = c("royalblue", "brown3"),
lty = c(1,1),
bty = "n")Referințe
Olive, David J. 2017. Linear Regression. Springer.
Note de subsol
Spunem că un sistem de polinoame \(\{p_n(x)\}\), \(n = 0,1,\ldots\) este ortogonal pe intervalul \((a,b)\) dacă \(\int_a^b p_n(x)p_m(x)\,dx = \delta_{nm}\) unde \(\delta_{nm}\) este simbolul lui Kronecker. În general putem avea ortogonalitate în raport cu o funcție de pondere \(w(x)\geq 0\) (continuă sau continuă pe porțiuni) dacă \(\int_a^b p_n(x)p_m(x)w(x)\,dx = \delta_{nm}\).↩︎