Modele de regresie
Curs 4 - Regresie liniară multiplă - Modelare
1 Introducere
Principiul problemei de regresie este de a modela relația dintre o variabilă \(y\), numită variabilă răspuns sau variabilă dependentă (cea pe care vrem să o explicăm), cu ajutorul unei funcții care depinde de un anumit număr de variabile \(\mathbf x = (x_1,\ldots, x_p)^\intercal\), numite variabile explicative, covariabile, predictori sau încă variabile independente (vom folosi în general primele trei denumiri)
\[ y\approx g(\mathbf x) = g(x_1,\ldots, x_p). \]
În realitate, relația de mai sus nu este exactă (i.e. \(\approx\)) deoarece se află sub influența unei erori aleatoare \(\varepsilon\). Presupunând că erorile sunt aditive avem o relație de tipul
\[ y = g(x_1,\ldots, x_p) + \varepsilon. \]
Astfel având dat un eșantion de talie \(n\) de \((p+1)\)-upluri \((\symbf x_i, y_i)\) cu \(\symbf x_i = (x_{i1},\ldots,x_{ip})^\intercal\), \(i \in\{1,\ldots,n\}\), \(n>p\), ne propunem să determinăm \(g\), i.e. să separăm componenta sistematică \(g\) (influența covariabilelor asupra răspunsului mediu) de termenul eroare \(\varepsilon\) (incertitudinea modelului). Aproximarea, \(\approx\), din relația anterioară se poate descrie matematic sub forma
\[ g = \underset{f\in\mathcal{F}}{\arg\min}\sum_{i = 1}^{n}L\left(y_i - f(\symbf x_i)\right) \]
unde \(L(\cdot)\) se numește funcție de cost sau de pierdere (loss function) iar \(\mathcal{F}\) este o clasă de funcții dată.
În general funcția de cost poate lua multe forme dar de cele mai multe ori vom întâlni două: funcția de cost absolut \(L(u) = |u|\) sau funcția de cost pătratic \(L(u) = u^2\).
În ceea ce privește clasa de funcții \(\mathcal{F}\) ce descriu componenta sistematică a modelului, în contextul modelului liniar vom considera clasa de funcții liniare (i.e. componenta sistematică este o combinație liniară de covariabile)
\[ \mathcal{F} = \left\{f:\mathbb{R}^p\to \mathbb{R}\,|\, f(\symbf x) = \begin{pmatrix}1 & \symbf x\end{pmatrix} \symbf \beta = \beta_0 + \beta_1 x_1 +\cdots + \beta_p x_p\right\}. \]
Este important de menționat că atunci când vorbim de regresie liniară ne referim la liniaritatea în parametrii modelului \(\beta_j\) și nu în variabilele explicative.
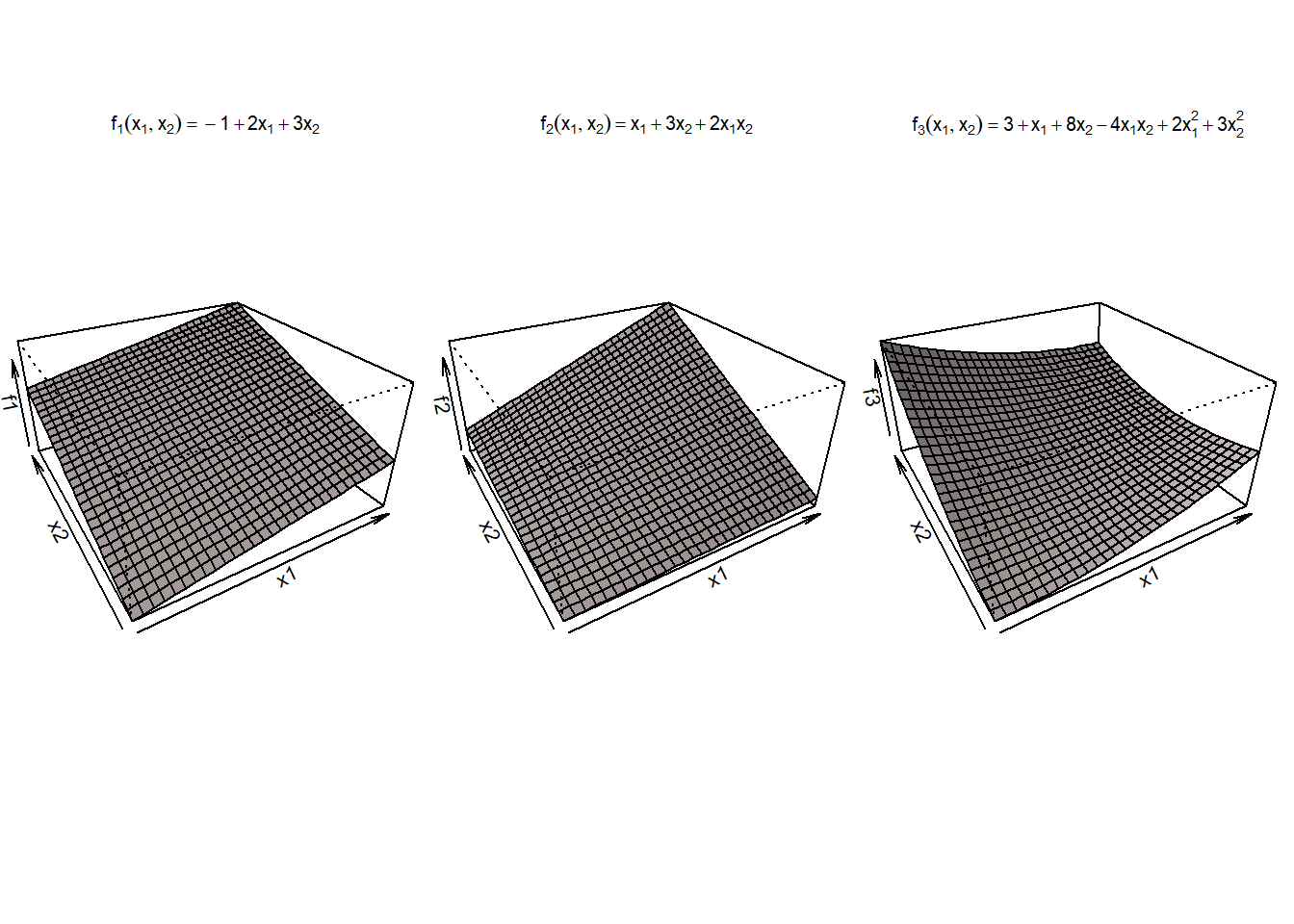
De exemplu, în contextul modelului de regresie liniară simplă, următoarele modele \(y = \beta_0 + \beta_1 x^2 + \varepsilon\), \(y = \beta_0 + \beta_1 \log(x) + \varepsilon\) și \(y = \beta_0 + \beta_1 \left(x^3 - \cos(x)^2 + e^x\right) + \varepsilon\) sunt liniare chiar dacă variabila predictor \(x\) poate prezenta un efect neliniar asupra răspunsului mediu. Pe de altă parte, modelul \(y = \beta_0 + \beta_1 x^{\beta_2} + \varepsilon\) nu este un model liniar.
De asemenea, \(f_1(x_1,x_2) = \beta_0 + \beta_1 x_1 + \beta_2 x_2\), \(f_2(x_1, x_2) = \beta_0 + \beta_1 x_1 + \beta_2 x_2 + \beta_3 \underbrace{x_1 x_2}_{x_3}\) sau \(f_3(x_1, x_2) = \beta_0 + \beta_1 x_1 + \beta_2 x_2 + \beta_3 \underbrace{x_1 x_2}_{x_3}+ \beta_4 \underbrace{x_1^2}_{x_4}+ \beta_5 \underbrace{x_2^3}_{x_5}\) sunt toate funcții liniare în \(\symbf\beta\).
2 Modelare
Modelul de regresie liniară multiplă reprezintă o extensie a modelului de regresie liniară simplă atunci când numărul variabilelor explicative este finit (pentru mai multe detalii privind analiza de regresie se pot consulta monografiile (Seber and Lee 2003), (Rencher and Schaalje 2008), (Weisberg 2014) sau (Faraway 2015)).
Pentru a estima parametrii necunoscuți \(\symbf\beta\), colectăm datele \((y_i, \symbf x_i)\) și presupunem că acestea verifică modelul
\[ y_i = \beta_0 + \beta_1 x_{i1} + \cdots + \beta_p x_{ip} + \varepsilon_i, \quad i = 1,2,\ldots,n \] unde
\(x_{ij}\) sunt valori cunoscute și nu sunt aleatoare
parametrii \(\beta_j\) sunt necunoscuți și nu sunt aleatori
\(\varepsilon_i\) sunt variabile aleatoare necunoscute
Scris sub formă compactă (matriceală) modelul devine
\[ \symbf Y = \symbf X\symbf \beta + \symbf \varepsilon \]
unde
- \(\mathbf{X}\) se numește matricea de design
\[ \mathbf{X}=\begin{pmatrix} 1 & x_{11} & \cdots & x_{1p}\\ \vdots & \vdots & \ddots & \vdots\\ 1 & x_{n1} & \cdots & x_{np} \end{pmatrix}_{n\times(p+1)} \]
- \(\mathbf{Y}\) este vectorul răspuns și este un vector aleator, \(\symbf\beta\) este vectorul parametrilor sau coeficienților și este necunoscut iar \(\symbf\varepsilon\) este vectorul erorilor și este un vector aleator
\[ \mathbf{Y}=\begin{pmatrix} y_1 \\ \vdots \\ y_n \end{pmatrix}_{n\times 1},\quad\symbf\beta=\begin{pmatrix} \beta_0 \\ \beta_1 \\ \vdots \\ \beta_p \end{pmatrix}_{(p+1)\times 1}\text{ și }\quad \symbf\varepsilon=\begin{pmatrix} \varepsilon_1 \\ \vdots \\ \varepsilon_n \end{pmatrix}_{n\times 1}. \]
Coloana cu termeni de \(1\) din matricea de design \(\symbf X\) corespunde termenului liber (ordonatei la origine - intercept). Un model foarte simplu, numit și modelul nul este cel în care nu apar variabile explicative \(\symbf Y = \symbf \mu + \symbf \varepsilon\):
\[ \begin{pmatrix} y_1 \\ \vdots \\ y_n \end{pmatrix}_{n\times 1} = \begin{pmatrix} \mu_1 \\ \vdots \\ \mu_n \end{pmatrix}_{n\times 1} + \begin{pmatrix} \varepsilon_1 \\ \vdots \\ \varepsilon_n \end{pmatrix}_{n\times 1}. \]
În cele ce urmează vom presupune că matricea de design \(\symbf X\) are rangul \(rang(\symbf X) = p+1\) acest fapt implicând că vectorii coloană sunt liniar independenți. O condiție necesară pentru această ipoteză este ca talia eșantionului \(n\) să fie mai mare decât numărul de covariabile din model. Această presupunere este necesară pentru a estima în mod unic coeficienții modelului. În cazul în care matricea de design nu este de rang \(p+1\) atunci ne confruntăm cu o problemă de identifiabilitate a modelului.
Definiția 2.1 Un model de regresie liniară multiplă este definit de relația
\[ \symbf Y = \symbf X\symbf \beta + \symbf \varepsilon \]
unde
- \(\symbf Y\) este un vector aleator de dimensiune \(n\)
- \(\symbf X\) este o matrice de dimensiune \(n\times(p+1)\) numită matrice de design
- \(\symbf\beta\) este un vector de dimensiune \(p+1\) de parametrii necunoscuți ai modelului
- \(\symbf\varepsilon\) este vectorul aleator centrat al erorilor
Pentru a specifica în totalitate modelul clasic de regresie liniară trebuie să facem următoarele ipoteze referitoare la componenta sistematică a modelului și la vectorul eroare. În primul rând, dacă ne raportăm la tipul variabilelor explicative sau la tipul de experiment care a condus la observarea datelor (e.g. experiment planificat), putem distinge între două situații: covariabilele sunt deterministe, cum este cazul unui plan de experiență planificat, sau sunt aleatoare atunci când avem de-a face cu date observaționale. În cel de-al doilea caz, când regresorii sunt aleatori, datele trebuie înțelese ca realizări ale unui vector aleator iar modelul trebuie văzut ca unul condiționat (la matricea de design \(\symbf X = x\)), a se vedea Cursul 1.
În al doilea rând, dacă facem referire la termenii eroare \(\varepsilon_i\) (cei care descriu incertitudinea modelului) aceștia trebuie să fie de medie \(0\), \(\mathbb{E}[\varepsilon_i] = 0\) sau sub formă matriceală \(\mathbb{E}[\symbf \varepsilon] = 0\), să aibă varianță constantă (homoscedasticitate) \(Var(\varepsilon_i) = \sigma^2\) și să fie necorelate \(Cov(\varepsilon_i, \varepsilon_j) = 0\) pentru \(i\neq j\). Ipoteza de homoscedasticitate și necorelare poate fi scrisă sub forma matriceală \(Cov(\symbf\varepsilon) = Var(\symbf\varepsilon) = \mathbb{E}[\symbf\varepsilon\symbf\varepsilon^\intercal] = \sigma^2 I_n\). Să remarcăm că în contextul modelului condiționat aceste ipoteze se scriu sub forma \(\mathbb{E}[\symbf\varepsilon|\symbf X] = 0\) și respectiv \(Cov(\symbf\varepsilon|\symbf X) = \sigma^2 I_n\) dar pentru ușurință vom elimina condiționarea din notație aceasta fiind subînțeleasă din context.
Sumarizând, ipotezele modelului de regresie liniară multiplă sunt:
\[ (\mathcal{H})\left\{\begin{array}{ll} \mathcal{H}_1: \, rang(\symbf X) = p+1\\ \mathcal{H}_2: \, \mathbb{E}[\symbf \varepsilon] = 0,\, Var(\symbf \varepsilon) = \sigma^2 I_n \end{array}\right. \]
Prima ipoteză ne spune că matricea de design \(\symbf X\) are coloanele liniar independente iar a doua ipoteză se referă la centralitatea erorilor (medie nulă), homoscedasticitatea (aceeași varianță) și necorelarea acestora.
Înainte de a trece la o discuție asupra ipotezelor modelului de regresie liniară multiplă vom introduce o serie de notații utile în cele ce vor urma. Pentru a face distincția dintre parametrii modelului \(\symbf\beta\) și \(\sigma^2\) și estimatorii lor vom folosi, ca de obicei, notația cu căciulă, respectiv \(\hat{\symbf\beta}\) și \(\hat\sigma^2\), în general fiind imposibil să determinăm valorile adevărate ale parametrilor. Folosind \(\hat{\symbf\beta}\) ca estimator al lui \(\symbf\beta\) putem determina cu ușurință estimatorul \(\widehat{\mathbb{E}[y_i\mid \symbf x_i]}\) al mediei lui \(y_i\) condiționate la \(\symbf x_i\),
\[ \widehat{\mathbb{E}[y_i\mid \symbf x_i]} = \hat{\beta}_0 + \hat{\beta}_1 x_{i1} + \cdots + \hat{\beta}_p x_{ip} = \symbf x_i^\intercal\hat{\symbf\beta}, \]
unde am considerat \(\symbf x_i^\intercal=(1,x_{i1},\ldots,x_{ip})\). Acest estimator, numit și valoare ajustată, se mai notează și cu \(\hat y_i\), i.e. \(\hat y_i = \widehat{\mathbb{E}[y_i\mid \symbf x_i]}\) iar eroare estimată, adică diferența dintre valoarea reală \(y_i\) și cea estimată \(\hat y_i\), se numește valoare reziduală și se notează cu \(\hat\varepsilon_i = y_i - \hat y_i = y_i - \symbf x_i^\intercal\hat{\symbf\beta}\). Este important de notat că valorile reziduale (reziduurile) \(\hat\varepsilon_i\) nu sunt identice cu termenii eroare \(\varepsilon_i\), ele pot fi interpretate ca estimări (sau mai precis predicții) ai acestora, care, ca și vectorul de parametrii \(\symbf\beta\), sunt necunoscuți. Reziduurile conțin variabilitatea din date (incertitudinea modelului) care nu poate fi explicată prin intermediul variabilelor explicative.
2.1 Liniaritatea efectelor variabilelor explicative
Chiar dacă într-o primă etapă ipoteza de liniaritate a efectelor covariabilelor pare o ipoteză restrictivă, am văzut că modelul de regresie liniară permite și relații neliniare. Spre exemplu, dacă luăm în considerare următorul model de regresie în care covariabila \(z_i\) admite un efect logaritmic,
\[ y_i = \beta_0 + \beta_1 \log(z_i) + \varepsilon_i \]
atunci definind variabila \(x_i=\log(z_i)\) regăsim un model de regresie liniară simplă \(y_i = \beta_0 + \beta_1 x_i + \varepsilon_i\). Trebuie menționat că într-un model de regresie liniară putem avea relații neliniare între variabila răspuns și predictori atât timp cât este păstrată liniaritatea în parametrii modelului. Pentru modelarea relațiilor neliniare vom prezenta în secțiunea Interpretarea efectului variabilelor explicative din Cursul 5 două abordări: una bazată pe transformarea variabilelor explicative și cealaltă prin intermediul polinoamelor.
Exemplul 2.1 (Înălțimea arborilor de eucalipt) În acest exemplu facem referire la setul de date Eucalypt (care poate fi descărcat de aici) și dorim să modelăm relația dintre înălțimea (medie) arborilor de eucalipt și circumferința acestora. Modelul de regresie liniară simplă este dat de
\[ ht_i = \beta_0 + \beta_1 circ_i + \varepsilon_i, \quad i =1,\ldots, 1429 \]
care, prin aplicarea metodei celor mai mici pătrate, conduce la estimatorii \(\hat\beta_0 =9.037\) și respectiv \(\hat\beta_1 =0.257\) pentru coeficienții modelului și astfel
\[ \widehat{ht}_i = 9.037 + 0.257 circ_i, \quad i =1,\ldots, 1429. \]
Observăm că pentru o creștere în circumferință de un \(1\) cm avem o creștere medie în înălțime de 25.7 cm. De asemenea putem remarca din figura de mai jos imaginea din stânga, că pentru valori mici ale circumferinței arborilor acestea se regăsesc sub dreapta de regresie ceea ce sugerează o relație neliniară între înălțime și circumferință. Astfel, putem considera un model simplu de tipul
\[ ht_i = \beta_0 + \beta_1 \sqrt{circ_i} + \varepsilon_i, \]
care ar conduce la o mai bună ajustare pe date (coeficientul de determinare \(R^2=0.7820638\) este un pic mai mare față de cel din modelul de regresie simplă \(R^2=0.7683202\)) și la estimatorii \(\hat\beta_0 =-2.73\) și respectiv \(\hat\beta_1 =3.494\),
\[ \widehat{ht}_i = -2.73 + 3.494 \sqrt{circ_i}, \quad i =1,\ldots, 1429. \]
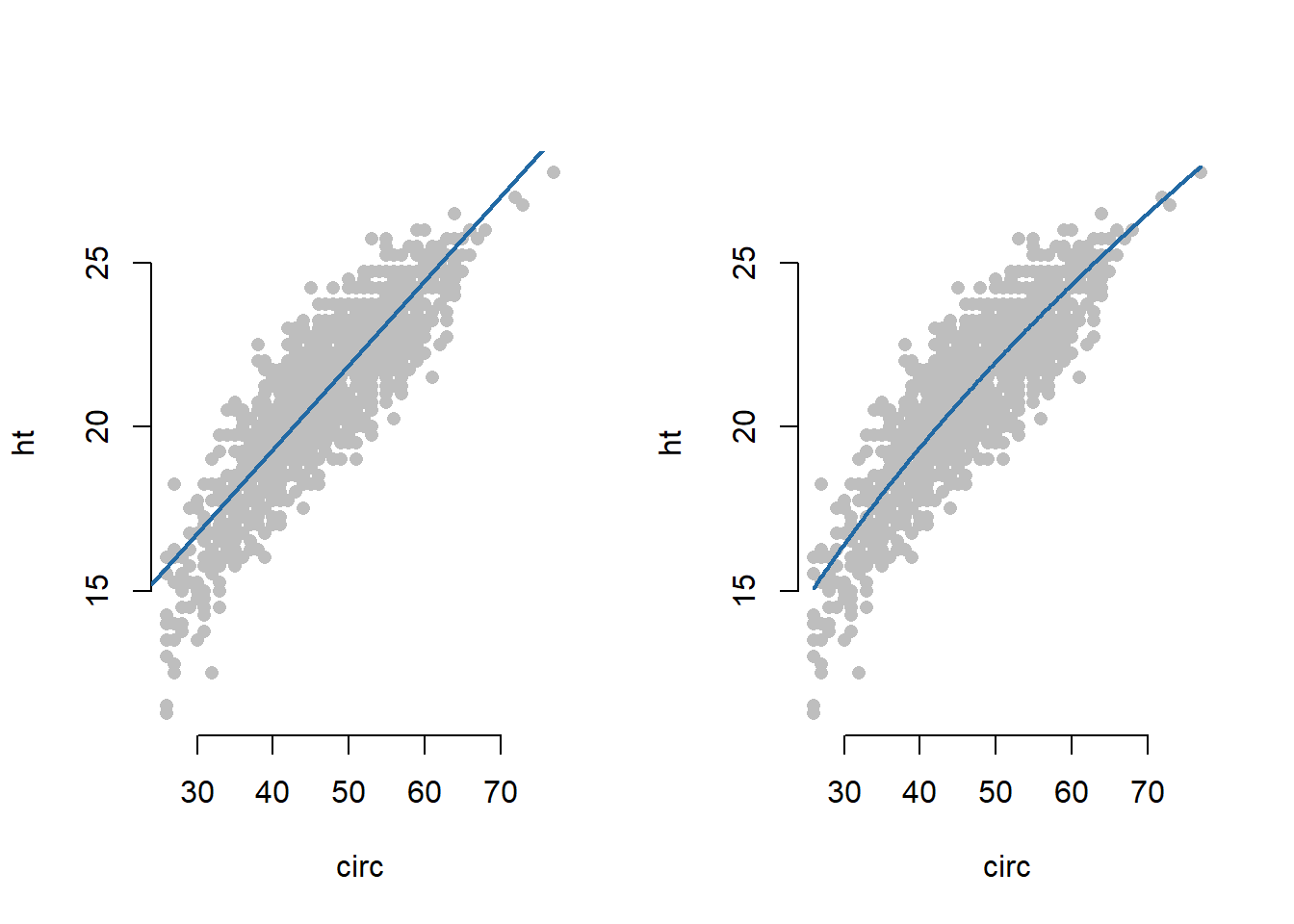
Arată codul R din exemplul de mai sus
#----------------------------------
# Înălțimea arborilor de eucalipt
#----------------------------------
eucalypt <- read.table("dataIn/eucalyptus.txt",
header=T,
sep=";")
eucalypt_model1 <- lm(ht ~ circ,
data = eucalypt)
coef_eucalypt_model1 <- round(coef(eucalypt_model1), 3)
eucalypt_model2 <- lm(ht ~ sqrt(circ),
data = eucalypt)
coef_eucalypt_model2 <- round(coef(eucalypt_model2), 3)
# Ilustrarea celor două modele de regresie pentru înălțimea arborilor de eucalip
par(mfrow = c(1,2))
plot(ht~circ,
data=eucalypt,
pch = 16,
col = "grey",
xlab="circ",
ylab="ht", bty = "n")
abline(eucalypt_model1$coefficients, col = myblue,
lwd = 2, lty = 1)
x_new <- data.frame(circ = seq(min(eucalypt$circ), max(eucalypt$circ),
length.out = 250))
plot(ht~circ,
data=eucalypt,
pch = 16,
col = "grey",
xlab="circ",
ylab="ht", bty = "n")
lines(x_new$circ, predict(eucalypt_model2, x_new), col = myblue,
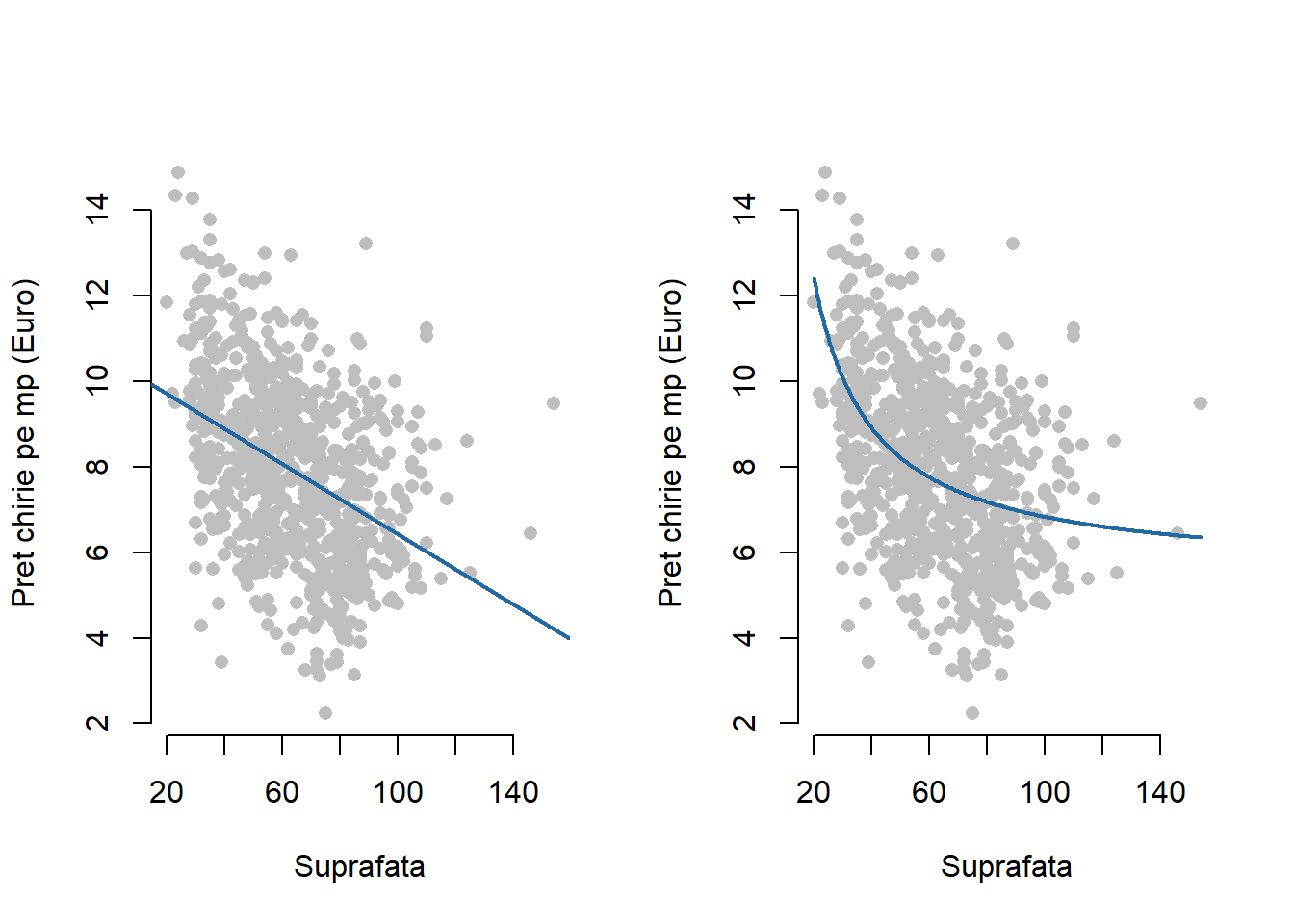
lwd = 2, lty = 1)Exemplul 2.2 (Prețul chiriilor în Munchen) Raportându-ne la setul de date referitor la prețul chiriilor în Munchen pentru apartamentele dintr-o locație medie, construite după anul 1966 (date ce pot fi descărcate de aici) observăm că modelul de regresie liniară simplă dintre prețul chiriilor pe metru pătrat și suprafață
\[ pret{\_m^2}_i = \beta_0 + \beta_1 suprafata_i + \varepsilon_i \]
devine în urma estimării
\[ pret{\_m^2}_i = 10.52 - 0.041 suprafata_i + \varepsilon_i \]
ceea ce ar sugera că o relație neliniară între variabila răspuns și variabila explicativă ar fi mai potrivită (același lucru se observă și din imaginea din stânga a figurii de mai jos). O mai bună ajustare pe date se poate obține definind variabila explicativă \(x = \frac{1}{suprafata}\) care ar conduce la modelul de regresie
\[ pret{\_m^2}_i = \beta_0 + \beta_1 \frac{1}{suprafata_i} + \varepsilon_i. \]
Aplicând metoda celor mai mici pătrate obținem
\[ \widehat{pret{\_m^2}_i} = \hat\beta_0 + \hat\beta_1 \frac{1}{suprafata_i} = 5.438 + 139.269 \frac{1}{suprafata_i} \]
ceea ce arată că prețul mediu pe \(m^2\) scade neliniar odată cu creșterea suprafeței apartamentului (a se vedea imaginea din dreapta din figura de mai jos în care putem constata o mai bună ajustare a modelului pe date). De exemplu, diferența în medie dintre prețul pe \(m^2\) al unui apartament de \(35\,m^2\) față de unul de \(36\,m^2\) este
\[ \widehat{pret{\_m^2}}(35) - \widehat{pret{\_m^2}}(36) = \frac{139.269}{35} - \frac{139.269}{36} \approx 0.110531 \,\,Euro \]
Arată codul R din exemplul de mai sus
#--------------------------------
# Prețul chiriilor în Munchen
#--------------------------------
munich <- read.table("dataIn/Munchen.raw", header = TRUE)
munich_sub <- munich %>% filter(yearc > 1966, location == 1)
munich_sub_model1 <- lm(rentsqm ~ area,
data = munich_sub)
coef_munich_model1 <- round(coef(munich_sub_model1), 3)
munich_sub_model2 <- lm(rentsqm ~ 1 + I(1/area),
data = munich_sub)
coef_munich_model2 <- round(coef(munich_sub_model2), 3)
# Ilustrarea celor două modele de regresie pentru prețul chiriilor din Munchen
par(mfrow = c(1,2))
plot(munich_sub$area, munich_sub$rentsqm,
pch = 16,
col = "grey",
bty = "n",
xlab = "Suprafata",
ylab = "Pret chirie pe mp (Euro)")
abline(munich_sub_model1$coefficients, col = myblue,
lwd = 2, lty = 1)
x_new_munich = data.frame(area = seq(min(munich_sub$area), max(munich_sub$area),
length.out = 250))
plot(munich_sub$area, munich_sub$rentsqm,
pch = 16,
col = "grey",
bty = "n",
xlab = "Suprafata",
ylab = "Pret chirie pe mp (Euro)")
lines(x_new_munich$area, predict(munich_sub_model2, x_new_munich),
col = myblue,
lwd = 2, lty = 1)2.2 Homoscedasticitatea termenilor eroare
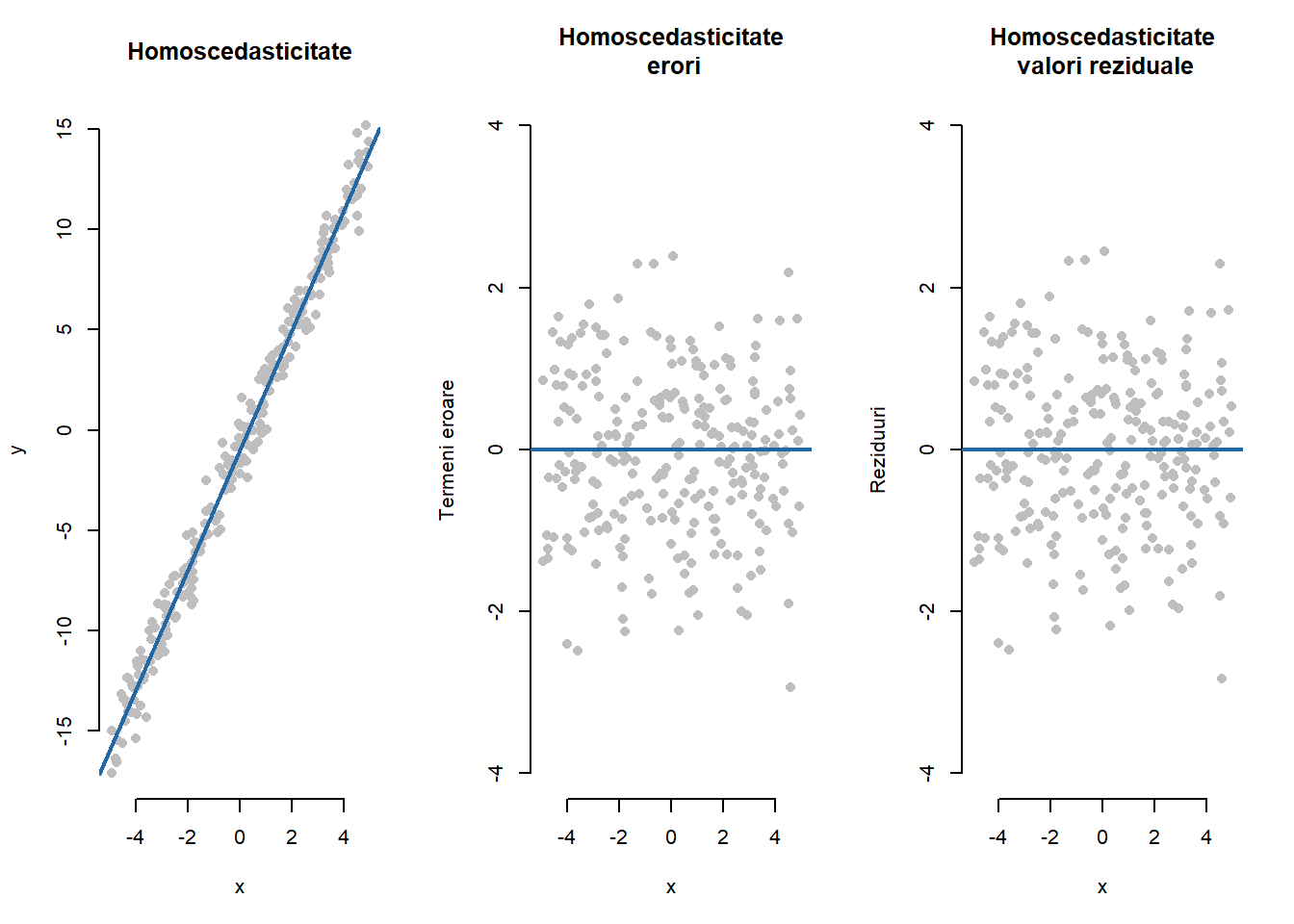
Proprietatea de homoscedasticitate a erorilor (ipoteza \(\mathcal{H}_2\)) presupune că varianța lui \(\varepsilon_i\) nu variază în mod sistematic odată cu creșterea sau descreșterea valorilor variabilelor explicative. În Figura 2.3 de mai jos avem ilustrat un model simulat homoscedastic după relația \(y_i\sim\mathcal{N}(-1 + 3x_i, 1)\) unde \(x_i\sim\mathcal{U}[-5, 5]\) împreună cu dreapta de regresie (figura din stânga). Se poate constata că observațiile fluctuează constant în jurul dreptei de regresie (mediei), aceeași concluzie putând fi trasă și din examinarea graficului în care apar termenii eroare (figura din mijloc). Cum datele sunt simulate și cunoaștem adevăratul model (cunoaștem adevăratele valori ale coeficienților), termenii eroare sunt \(\varepsilon_i = y_i - \symbf x_i^\intercal\symbf\beta\) și se cunosc. În general, vom folosi valorile reziduale pentru a estima termenii eroare \(\hat\varepsilon_i = y_i - \symbf x_i^\intercal\hat{\symbf\beta}\) și pentru a verifica proprietatea de homoscedasticitate a erorilor (figura din dreapta). Vom vedea, că atât termenii eroare cât și valorile reziduale au medie zero dar spre deosebire de termenii eroare, reziduurile pot avea varianțe diferite și în plus sunt corelate.
Arată codul R pentru figura de mai sus
#-----------------------------------------------
# Ilustrarea proprietății de homoscedasticitate
#-----------------------------------------------
# model 1
n <- 250
# x = seq(-5, 5, length.out = 250)
# y = -1 + 3*sapply(x, function(x){rnorm(1, mean = x, sd = 1)})
x <- -5 + 10*runif(n)
y <- -1 + 3*x + rnorm(length(x))
data_dum1 <- data.frame(x = x, y = y)
model_dum1 <- lm(y~x, data = data_dum1)
par(mfrow = c(1,3))
plot(x, y,
main = "Homoscedasticitate",
pch = 16,
col = "grey",
bty = "n",
xlab = "x",
ylab = "y",
xlim = c(-5, 5))
abline(model_dum1$coefficients, col = myblue,
lwd = 2, lty = 1)
err_model_dum1 = y - (-1 + 3*x)
plot(x, err_model_dum1,
main = "Homoscedasticitate\n erori",
pch = 16,
col = "grey",
bty = "n",
xlab = "x",
ylab = "Termeni eroare",
ylim = c(-4, 4),
xlim = c(-5, 5))
abline(h = 0,
col = myblue,
lwd = 2, lty = 1)
plot(x, model_dum1$residuals,
main = "Homoscedasticitate\n valori reziduale",
pch = 16,
col = "grey",
bty = "n",
xlab = "x",
ylab = "Reziduuri",
ylim = c(-4, 4),
xlim = c(-5, 5))
abline(h = 0,
col = myblue,
lwd = 2, lty = 1)Un exemplu, des întâlnit în practică, de situație în care termenii eroare sunt heteroscedastici este ilustrat în figura următoare. Modelul folosit pentru generarea observațiilor este \(y_i\sim\mathcal{N}\left(-1 + 3x_i, \left(1.2 + 0.5(x_i + 1)\right)^2\right)\) unde \(x_i\sim\mathcal{U}[-5, 5]\). Se poate constata că pe măsură ce \(x\) crește, variabilitatea observațiilor în jurul dreptei de regresie crește de asemenea (figura din stânga). Acest fenomen (de pâlnie) se poate observa cu mai mare ușurință atunci când trasăm graficul erorilor (respectiv valorilor reziduale).
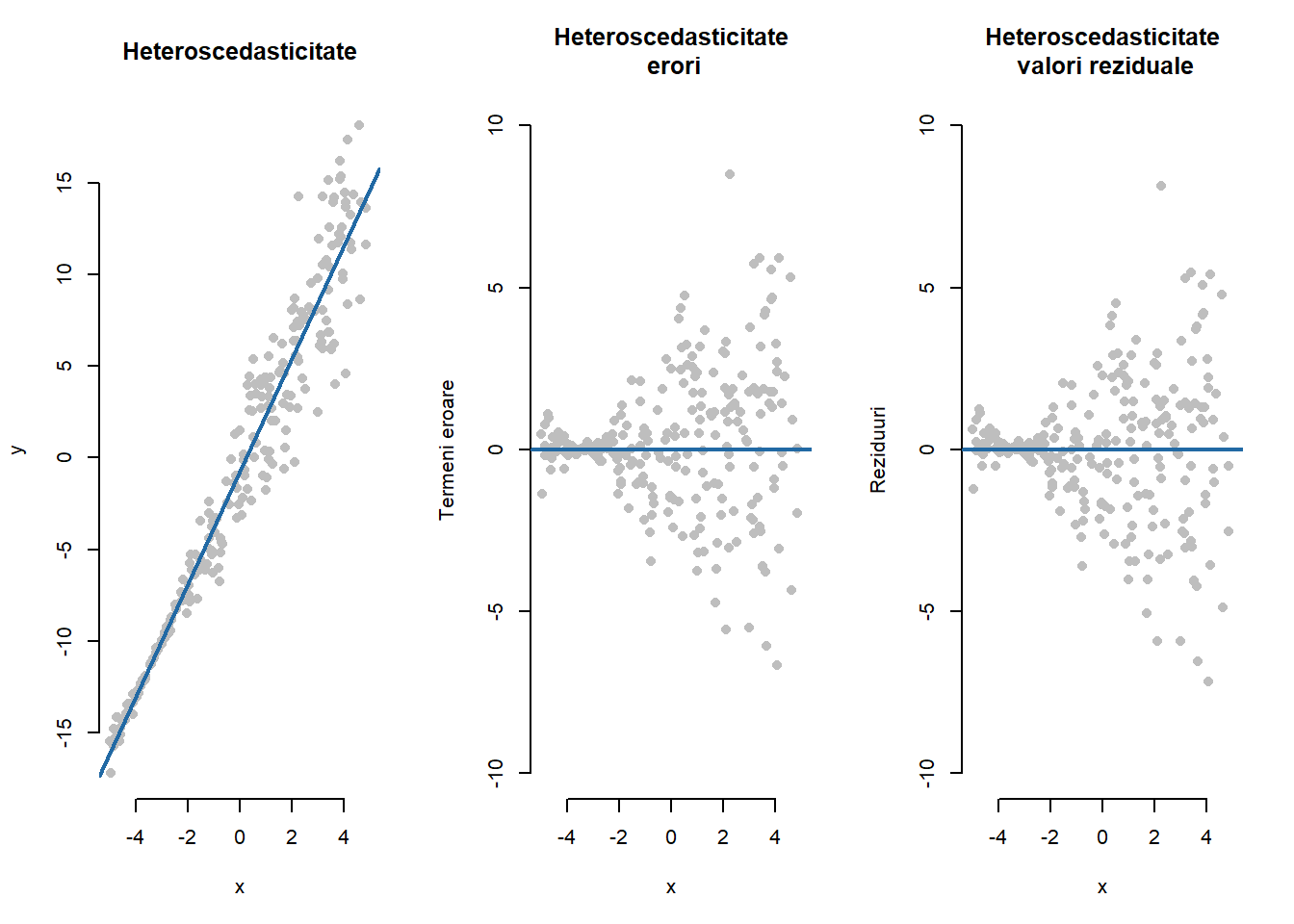
Arată codul R pentru figura de mai sus
#---------------------------------------------------------
# Ilustrarea efectului de pâlnie într-un model de regresie
#---------------------------------------------------------
# model 2
n <- 250
x <- -5 + 10*runif(n)
y <- -1 + 3*x + (1.2 + 0.5*(x + 1))*rnorm(length(x))
data_dum2 <- data.frame(x = x, y = y)
model_dum2 <- lm(y~x, data = data_dum2)
par(mfrow = c(1,3))
plot(x, y,
main = "Heteroscedasticitate",
pch = 16,
col = "grey",
bty = "n",
xlab = "x",
ylab = "y",
xlim = c(-5, 5))
abline(model_dum2$coefficients, col = myblue,
lwd = 2, lty = 1)
err_model_dum2 = y - (-1 + 3*x)
plot(x, err_model_dum2,
main = "Heteroscedasticitate\n erori",
pch = 16,
col = "grey",
bty = "n",
xlab = "x",
ylab = "Termeni eroare",
ylim = c(-10, 10),
xlim = c(-5, 5))
abline(h = 0,
col = myblue,
lwd = 2, lty = 1)
plot(x, model_dum2$residuals,
main = "Heteroscedasticitate\n valori reziduale",
pch = 16,
col = "grey",
bty = "n",
xlab = "x",
ylab = "Reziduuri",
ylim = c(-10, 10),
xlim = c(-5, 5))
abline(h = 0,
col = myblue,
lwd = 2, lty = 1)Conform teoriei, dacă modelul de regresie este corect (componenta sistematică a modelului este cea reală) și ipotezele modelului sunt verificate atunci toate graficele care implică valorile reziduale (\(\hat\varepsilon\)) versus orice funcție ce depinde de covariabile (sau de o combinație liniară a acestora) ar trebui să ilustreze o variație simetrică și constantă pe verticală (\(\hat\varepsilon\)), prin urmare este recomandată inspectarea a cât mai multor astfel de grafice. Cele mai uzuale grafice de reziduuri (residual plots) sunt cele care implică valorile reziduale \(\hat\varepsilon_i\) și variabilele explicative \(x_i\) care sunt incluse în modelul propus (sau nu - în acest caz orice structură observată în grafic poate sugera includerea covariabilei în model) respectiv valorile ajustate \(\hat y_i\). Acest din urmă grafic de diagnostic (\(\hat\varepsilon_i\) vs \(\hat y_i\)) este și cel mai des folosit în practică deoarece conține informații de la toate covariabilele incluse în model (Faraway 2015). Aceste grafice permit de asemenea detectarea neliniarității în componenta sistematică, de structură, a modelului.
Este important de menționat că sunt multe situațiile (i.e. atunci când avem de-a face cu un model neliniar) în care nu putem trage o concluzie asupra ipotezelor modelului doar privind comportamentul valorilor reziduale. De cele mai multe ori trebuie să avem grijă ca modelul specificat să fie corect. Următorul exemplu sugerează acest fapt:
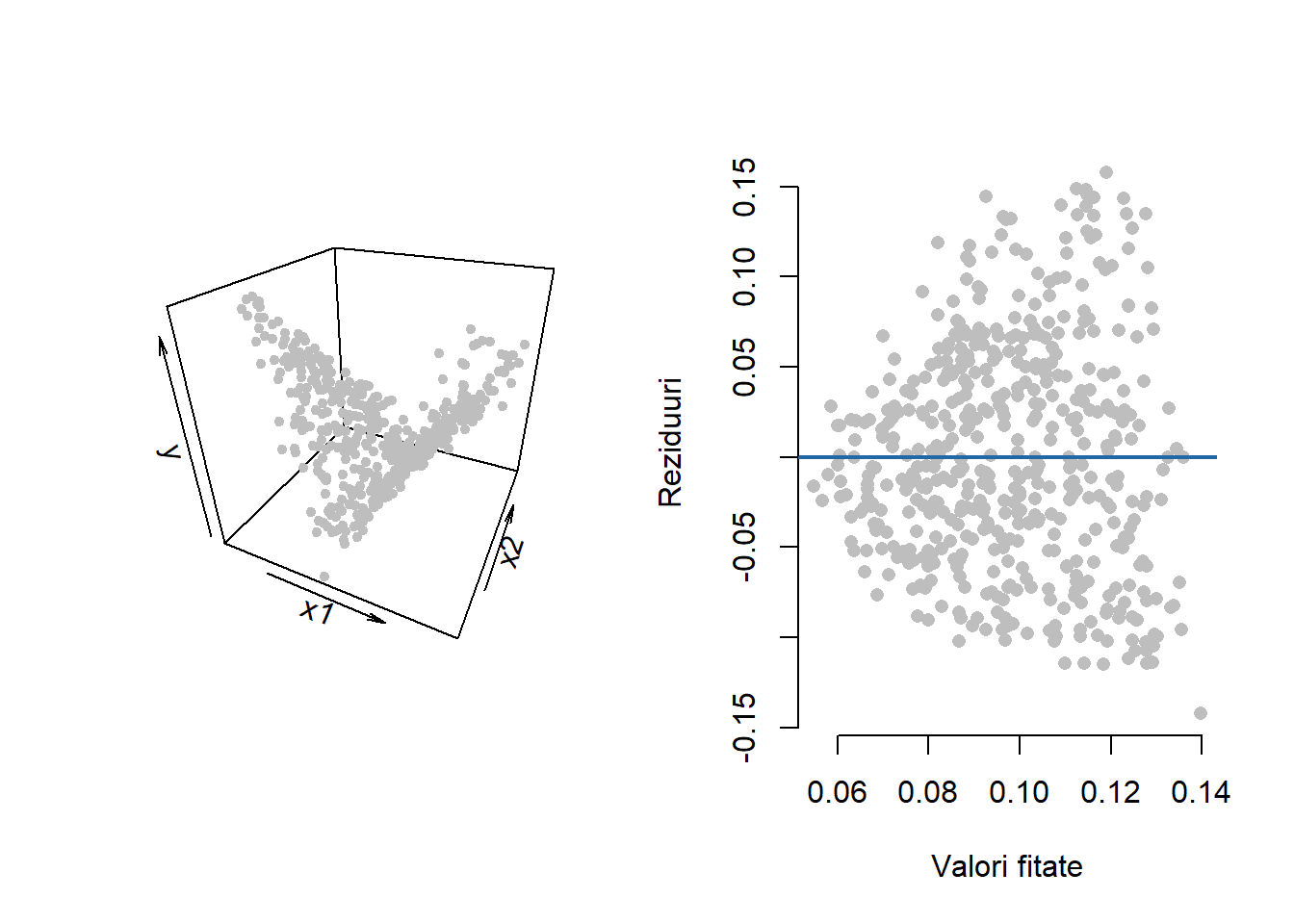
Exemplul 2.3 (Importanța corectitudinii modelului - date simulate) Acest exemplu este preluat din (Cook and Weisberg 1999) și evidențiază importanța corectitudinii modelului atunci când este evaluat un grafic al reziduurilor. În Figura 2.5 de mai jos avem ilustrat grafic diagrama de împrăștiere a punctelor precum și evoluția valorilor reziduale în raport cu valorile ajustate pentru modelul de regresie liniară multiplă:
\[ y_i = \beta_0 + \beta_1 x_{i1} + \beta_2 x_{i2} + \varepsilon_i \]
unde observațiile au fost simulate artificial (\(n = 500\)). Efectul de pâlnie al reziduurilor (figura din dreapta) sugerează heteroscedasticitatea termenilor eroare în modelul propus, atât timp cât acest model este valid.
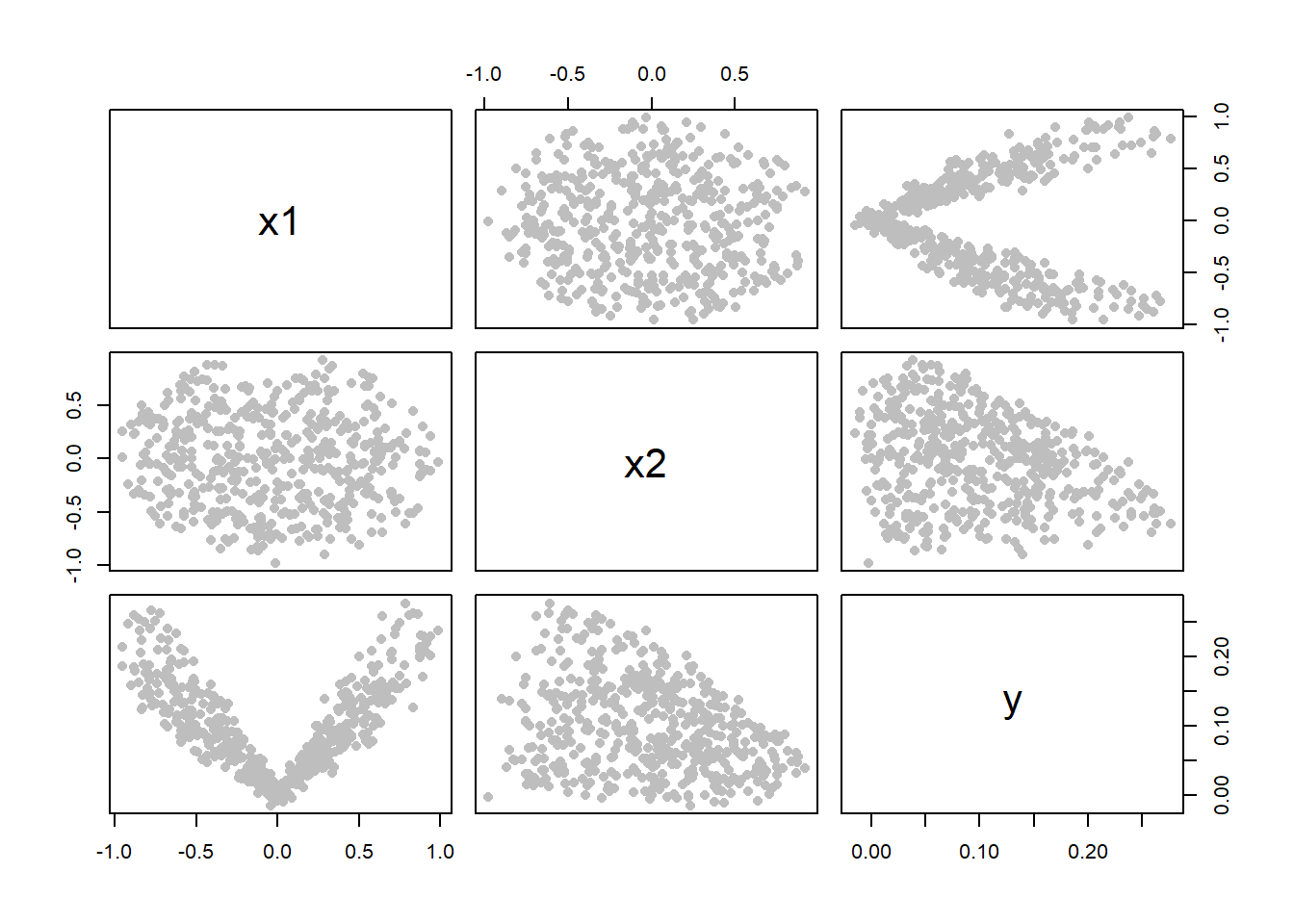
Dacă ne uităm la diagramele de împrăștiere pentru fiecare variabilă în parte (matricea diagramelor de împrăștiere - scatterplot matrix) observăm că variabilele predictor \(x_1\) și \(x_2\) sunt necorelate (coeficientul de corelație este 0.086) și sunt generate sferic (mai exact repartiția comună a predictorilor face parte din clasa repartițiilor eliptice simetrice - \(\mathbb{E}[x_i|x_j]\approx \alpha_0 + \alpha_1 x_j\)).
Problema care apare este că modelul de regresie este specificat greșit, componenta sistematică a modelului nu este liniară sau o funcție care să depindă de o combinație liniară de covariabile (i.e. \(g(\symbf x^\intercal \symbf\beta)\)), chiar dacă din graficul valorilor reziduale am crede că avem o problemă cu heteroscedasticitatea erorii. În acest exemplu particular, în care avem doar doi predictori, se putea observa, prin trasarea diagramei de împrăștiere în trei dimensiuni (Figura 2.5 - stânga), că răspunsul mediu nu depinde liniar de \(x_1\) și \(x_2\) (în general există metode mai complexe de tipul sliced inverse regression). Acest lucru putea fi remarcat și prin trasarea valorilor reziduale în raport cu fiecare variabilă explicativă în parte.
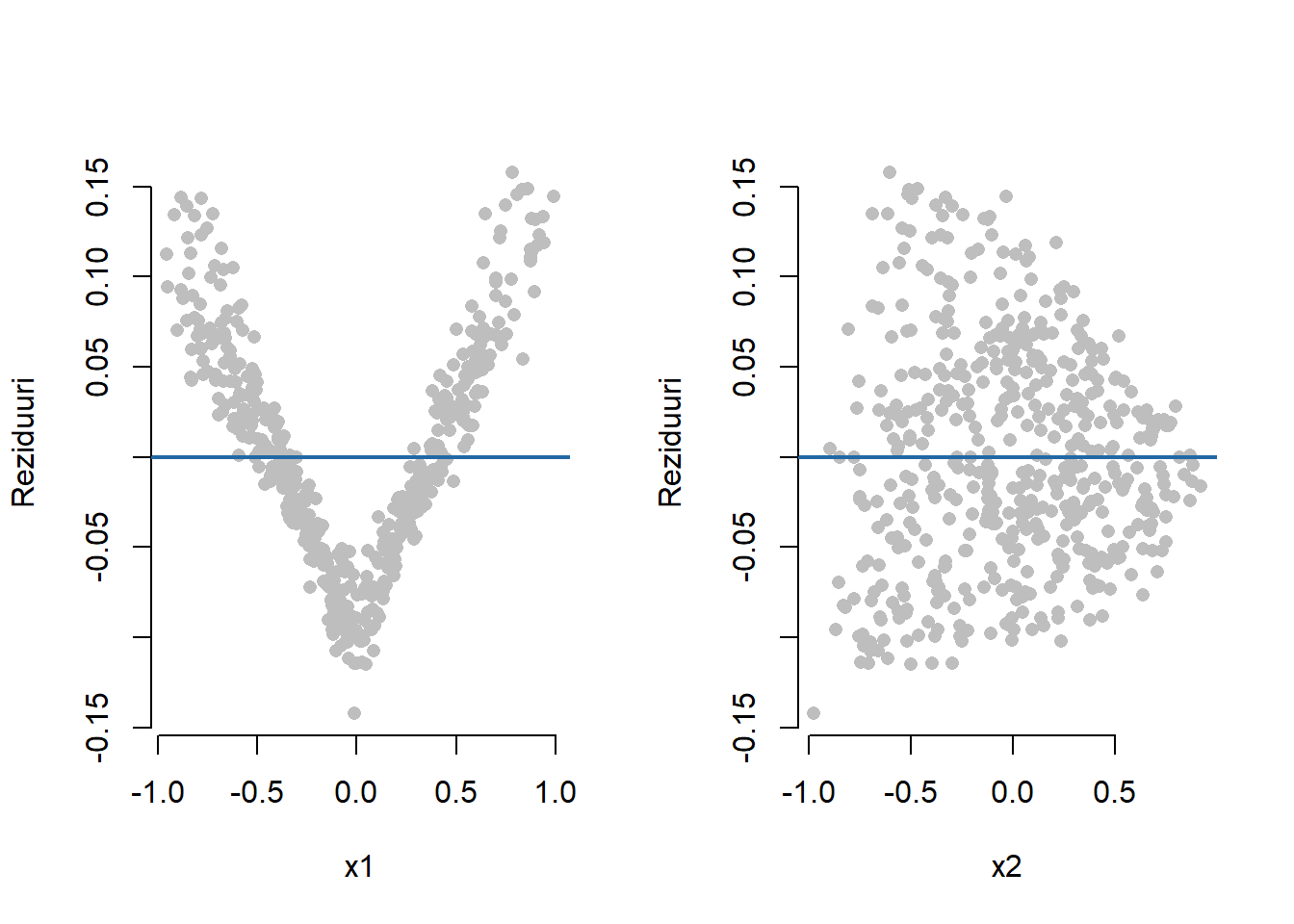
Trebuie menționat că datele au fost generate după următorul model:
\[ y = \underbrace{\frac{|x_1|}{2 + (1.5 + x_2)^2}}_{=\mathbb{E}[y|x_1, x_2]} + \varepsilon \]
unde termenul eroare \(\varepsilon\sim\mathcal{N}(0, 0.01^2)\) are varianță constantă iar predictorii \((x_1, x_2)\) au fost simulați dintr-o repartiție eliptică Pearson de tip II pe discul unitate în \(\mathbb{R}^2\) ((Johnson 2013)) având densitatea comună dată de
\[ f_P(x_1,x_2) = \frac{\Gamma(m+2)}{\Gamma(m+1)\pi\sqrt{2}}(1 - x_1^2 - x_2^2)^m \]
unde \(m>-1\) este un parametru de formă (pentru simulare am folosit \(m = 0.5\)). În Figura 2.8 de mai jos este ilustrată densitatea Pearson de tip II pentru mai multe valori ale parametrului de formă.
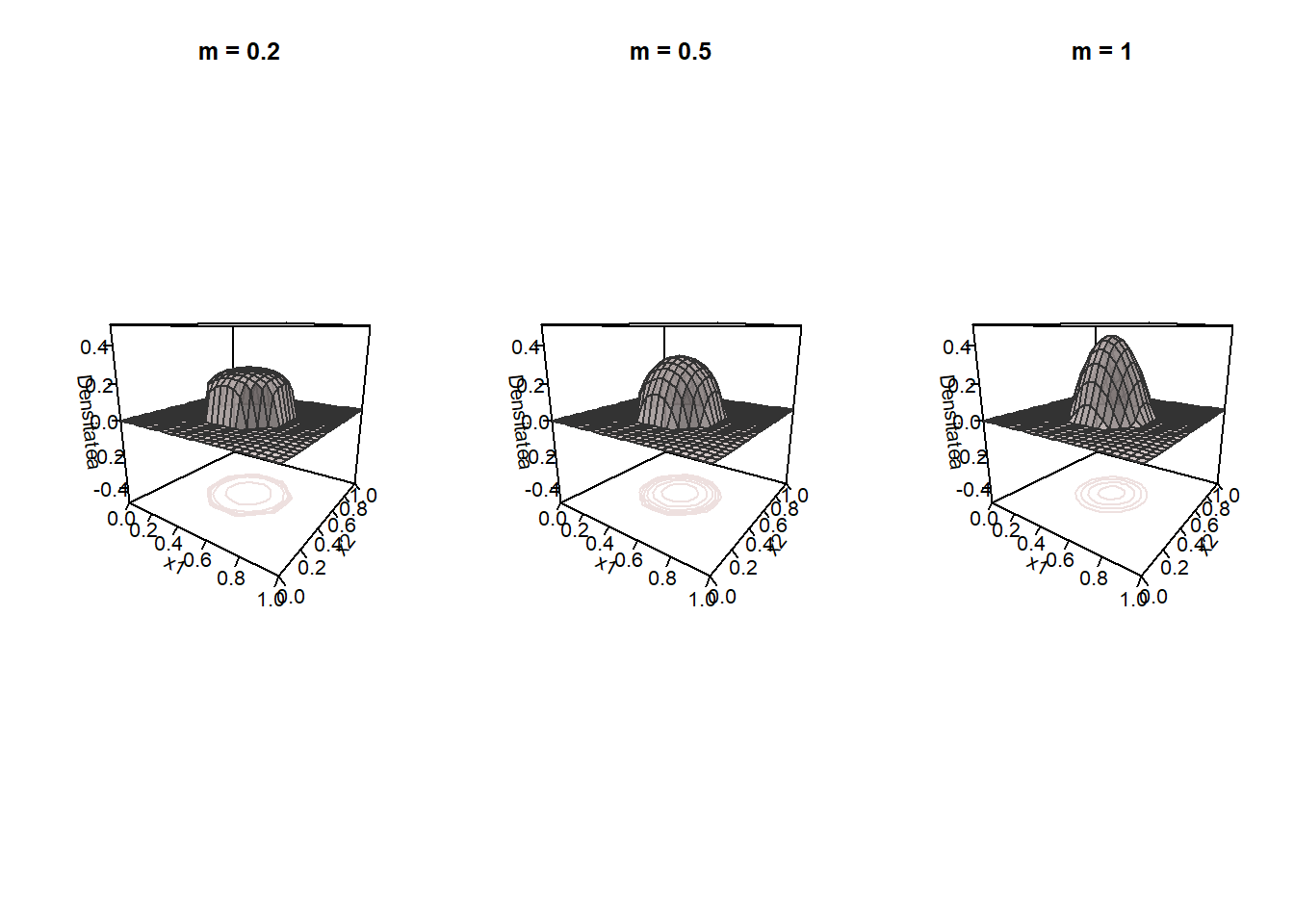
Arată codul R din exemplul de mai sus
#-------------------------------------
# Importanța corectitudinii modelului
#-------------------------------------
# Model cu doi predictori - Weisberg sect. 8.1.5
# x1, x2 - Pearson type II distribution - vz cartea lui Johnson 1987 Multivariate statistical simulation pag 111
n <- 500
# alg de generare conform Johnson
m <- 0.5
p <- 2
x1 <- rbeta(n, 0.5, m + p/2 + 0.5)
x1 <- (-1 + 2*rbinom(n, 1, 0.5))*sqrt(x1)
v2 <- rbeta(n, 0.5, m + p/2)
x2 <- (-1 + 2*rbinom(n, 1, 0.5))*sqrt(v2*(1 - x1^2))
y <- abs(x1)/(2 + (1.5 + x2)^2) + rnorm(n, mean = 0, sd = 0.01)
data_dum3 <- data.frame(x1 = x1, x2 = x2, y = y)
model_dum3 <- lm(y ~ x1 + x2, data = data_dum3)
# plot
par(mfrow = c(1,2))
scatter3D(x1, x2, y,
colvar = NULL,
theta = 25, phi = 30,
col = "grey",
pch = 20,
xlab = "x1", ylab = "x2", zlab = "y")
plot(fitted(model_dum3), residuals(model_dum3),
# main = "Heteroscedasticitate\n valori reziduale",
pch = 16,
col = "grey",
bty = "n",
xlab = "Valori fitate",
ylab = "Reziduuri")
abline(h = 0,
col = myblue,
lwd = 2, lty = 1)
# Matricea diagramelor de împrăștiere pentru modelul simulat
pairs(data_dum3,
col = "grey",
pch = 16)
# Ilustrarea valorilor reziduale în raport cu fiecare covariabilă pentru modelul simulat
par(mfrow = c(1, 2))
plot(x1, residuals(model_dum3),
# main = "Heteroscedasticitate\n valori reziduale",
pch = 16,
col = "grey",
bty = "n",
xlab = "x1",
ylab = "Reziduuri")
abline(h = 0,
col = myblue,
lwd = 2, lty = 1)
plot(x2, residuals(model_dum3),
# main = "Heteroscedasticitate\n valori reziduale",
pch = 16,
col = "grey",
bty = "n",
xlab = "x2",
ylab = "Reziduuri")
abline(h = 0,
col = myblue,
lwd = 2, lty = 1)
# Densitatea Pearson de tip II pentru mai multe valori ale parametrului de formă
x1 <- seq(-2, 2, length.out = 26)
x2 <- seq(-2, 2, length.out = 26)
f_pearson <- function(x1, x2, m = 0.5){
k <- (gamma(m+2))/(gamma(m+1)*pi*sqrt(2))
return(ifelse(x1^2 + x2^2 <= 1, k*(1 - x1^2 - x2^2)^m, 0))
}
par(mfrow = c(1, 3))
m <- 0.2
z1 <- outer(x1, x2, f_pearson, m = m)
persp3D(z = z1,
# colvar = NULL,
main = paste0("m = ", m),
xlab = "x1",
ylab = "x2",
zlab = "Densitatea",
col = "#eee0df",
facets = TRUE,
border = "grey20",
shade = 0.2,
alpha = 0.7,
theta = 35, phi = 15,
# expand = 0.75,
ticktype = "detailed",
zlim = c(-0.5, 0.5),
contour = list(nlevels = 5, col = "#eee0df"))
m <- 0.5
z2 <- outer(x1, x2, f_pearson, m = m)
persp3D(z = z2,
# colvar = NULL,
main = paste0("m = ", m),
xlab = "x1",
ylab = "x2",
zlab = "Densitatea",
col = "#eee0df",
facets = TRUE,
border = "grey20",
shade = 0.2,
alpha = 0.7,
theta = 35, phi = 15,
# expand = 0.75,
ticktype = "detailed",
zlim = c(-0.5, 0.5),
contour = list(nlevels = 5, col = "#eee0df"))
m <- 1
z3 <- outer(x1, x2, f_pearson, m = m)
persp3D(z = z3,
# colvar = NULL,
main = paste0("m = ", m),
xlab = "x1",
ylab = "x2",
zlab = "Densitatea",
col = "#eee0df",
facets = TRUE,
border = "grey20",
shade = 0.2,
alpha = 0.7,
theta = 35, phi = 15,
# expand = 0.75,
ticktype = "detailed",
zlim = c(-0.5, 0.5),
contour = list(nlevels = 5, col = "#eee0df"))Exemplul 2.4 (Prețul chiriilor în Munchen) În cazul setului de date ce face referire la prețul chiriilor din Munchen, dacă ne referim la relația dintre prețul net al chiriilor și suprafața de locuit (figura din stânga) constatăm o tendință de creștere a erorilor odată cu creșterea în suprafață a locuințelor (figura din stânga). Astfel, găsim că pentru suprafețe mai mari avem o plajă mai largă de valori ale prețurilor chiriilor.
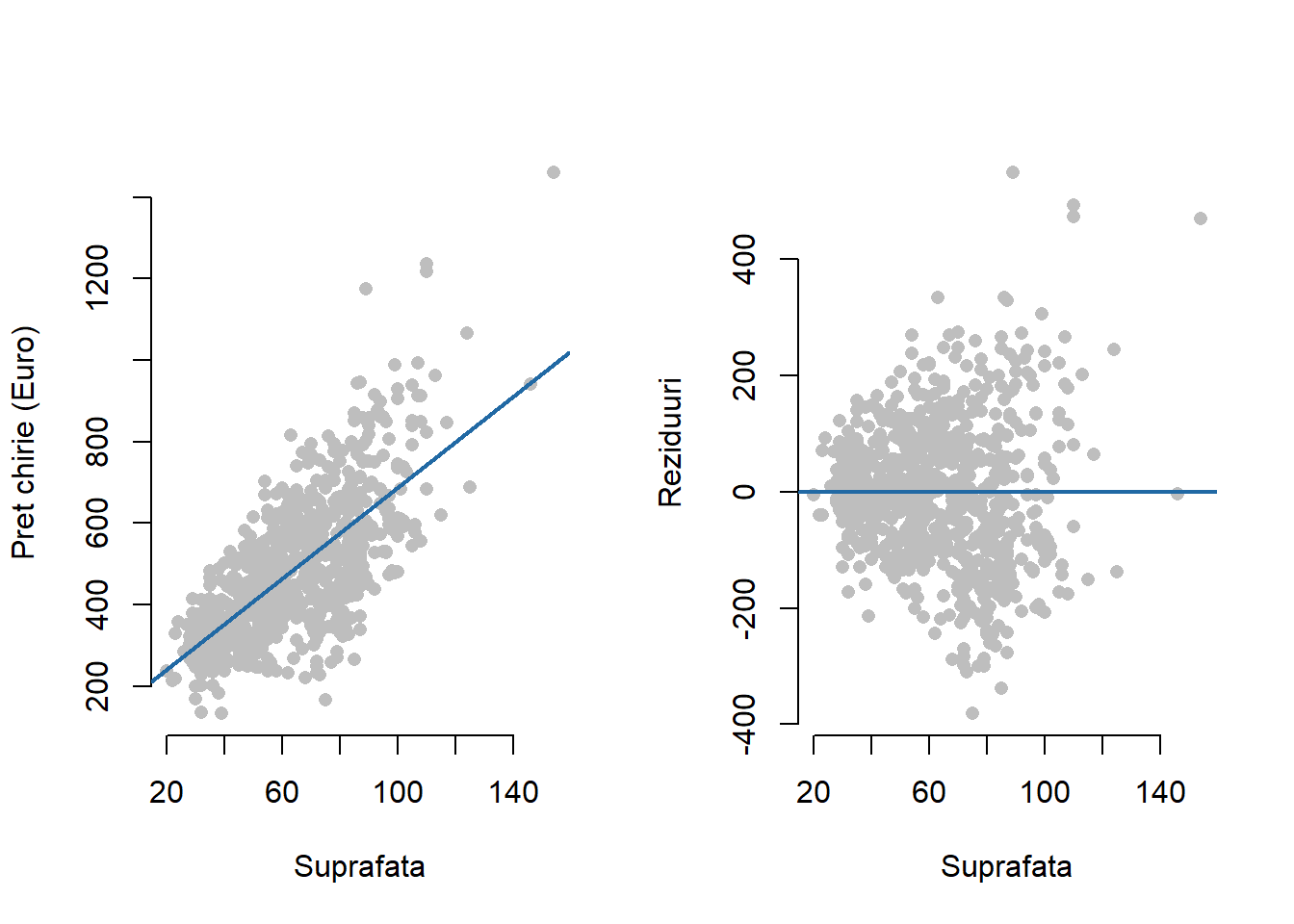
Arată codul R din exemplul de mai sus
#-----------------------------
# Prețul chiriilor în Munchen
#-----------------------------
par(mfrow = c(1,2))
munich_sub_model_rent1 <- lm(rent~area, data = munich_sub)
# munich_sub_model_rent1b = lm(rent~log(area), data = munich_sub)
plot(munich_sub$area, munich_sub$rent,
pch = 16,
col = "grey",
bty = "n",
xlab = "Suprafata",
ylab = "Pret chirie (Euro)")
abline(munich_sub_model_rent1$coefficients, col = myblue,
lwd = 2, lty = 1)
plot(munich_sub$area, munich_sub_model_rent1$residuals,
pch = 16,
col = "grey",
bty = "n",
xlab = "Suprafata",
ylab = "Reziduuri")
abline(h = 0,
col = myblue,
lwd = 2, lty = 1)2.3 Necorelarea termenilor eroare
Ipoteza \(\mathcal{H}_2\) presupune pe lângă homoscedasticitatea termenilor eroare și că aceștia sunt necorelați, i.e. \(Cov(\varepsilon_i, \varepsilon_j)=0\) pentru \(i\neq j\). Această ipoteză poate să nu fie conformă cu realitatea în special atunci când avem de-a face cu serii de timp sau date longitudinale (date care presupun eșantionarea acelorași unități de eșantionare la momente diferite de timp, e.g urmărirea și eșantionarea lunară a unor caracteristici de interes - viremia - pentru o serie de pacienți cu o boală gravă în vederea caracterizării stării imunității acestora). În aceste situații se observă o autocorelare a termenilor eroare. De exemplu, o autocorelare de ordin unu a termenilor eroare implică o relație liniară între eroarea la momentul \(i\) și eroarea la momentul \(i-1\), e.g. \(\varepsilon_i = \rho \varepsilon_{i-1} + u_i\) unde \(u_i\) sunt variabile aleatoare independente și indentic repartizate iar o autocorelare de ordin \(k\) se scrie sub forma \(\varepsilon_i = \sum_{t = 1}^{k}\rho_t\varepsilon_{i-t} + u_i\).
În Figura 2.10 de mai jos avem ilustrat un exemplu de model de regresie liniară simplă în care erorile prezintă o autocorelare (pozitivă) de ordinul 1. Modelul a fost generat după relația \(y_i = -1 + 3x_i + \varepsilon_i\) unde \(x_i\sim\mathcal{U}[-5,5]\) iar \(\varepsilon_i = 0.9\varepsilon_{i-1} + u_i\) cu \(u_i\sim\mathcal{N}(0, 0.5^2)\). Se observă că autocorelarea termenilor eroare este pozitivă deoarece un termen eroare pozitiv (negativ) este mai probabil să fie urmat tot de un termen pozitiv (negativ) - figura din dreapta.
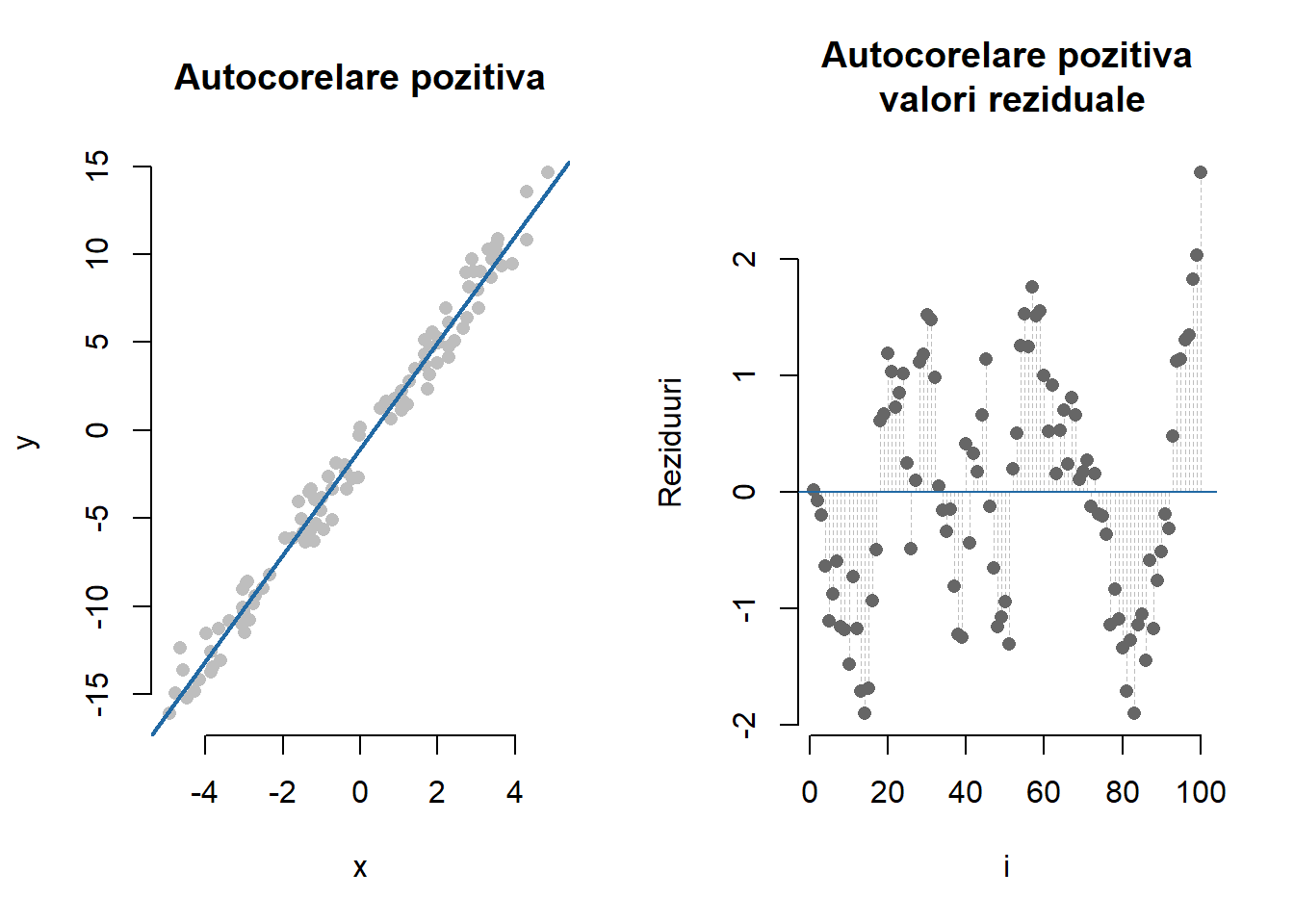
Arată codul R pentru figura de mai sus
#--------------------------------------------------
# Ilustrarea proprietății de autocorelare pozitivă
#--------------------------------------------------
# model 1 - autocorelare pozitiva
n <- 100
# x = seq(-5, 5, length.out = n)
x <- -5 + 10*runif(n)
u <- rnorm(n-1, 0, 0.5)
e <- numeric(n)
for (i in 2:n){
e[i] <- 0.9*e[i-1] + u[i-1]
}
y <- -1 + 3*x + e
data_dum_auto1 <- data.frame(x = x, y = y)
model_dum_auto1 <- lm(y~x, data = data_dum_auto1)
par(mfrow = c(1,2))
plot(x, y,
main = "Autocorelare pozitiva",
pch = 16,
col = "grey",
bty = "n",
xlab = "x",
ylab = "y",
xlim = c(-5, 5))
abline(model_dum_auto1$coefficients, col = myblue,
lwd = 2, lty = 1)
plot(1:n, model_dum_auto1$residuals,
main = "Autocorelare pozitiva\n valori reziduale",
# pch = 16,
type = "h",
col = "grey",
lwd = 0.5, lty = 2,
bty = "n",
xlab = "i",
ylab = "Reziduuri")
points(1:n, model_dum_auto1$residuals,
pch = 16,
col = "grey40")
abline(h = 0,
col = myblue,
lwd = 1, lty = 1)Următoarea figură ilustrează un exemplu clasic de autocorelare negativă a termenilor eroare. În această situație, termenii eroare pozitivi (negativi) sunt urmați cu precădere de termeni eroare negativi (pozitivi), prin urmare observăm frecvent o alternare a semnelor termenilor eroare. Modelul din figură este generat după relația \(y_i = -1 + 3x_i + \varepsilon_i\) unde \(x_i\sim\mathcal{U}[-5,5]\) iar \(\varepsilon_i = -0.9\varepsilon_{i-1} + u_i\) cu \(u_i\sim\mathcal{N}(0, 0.5^2)\).
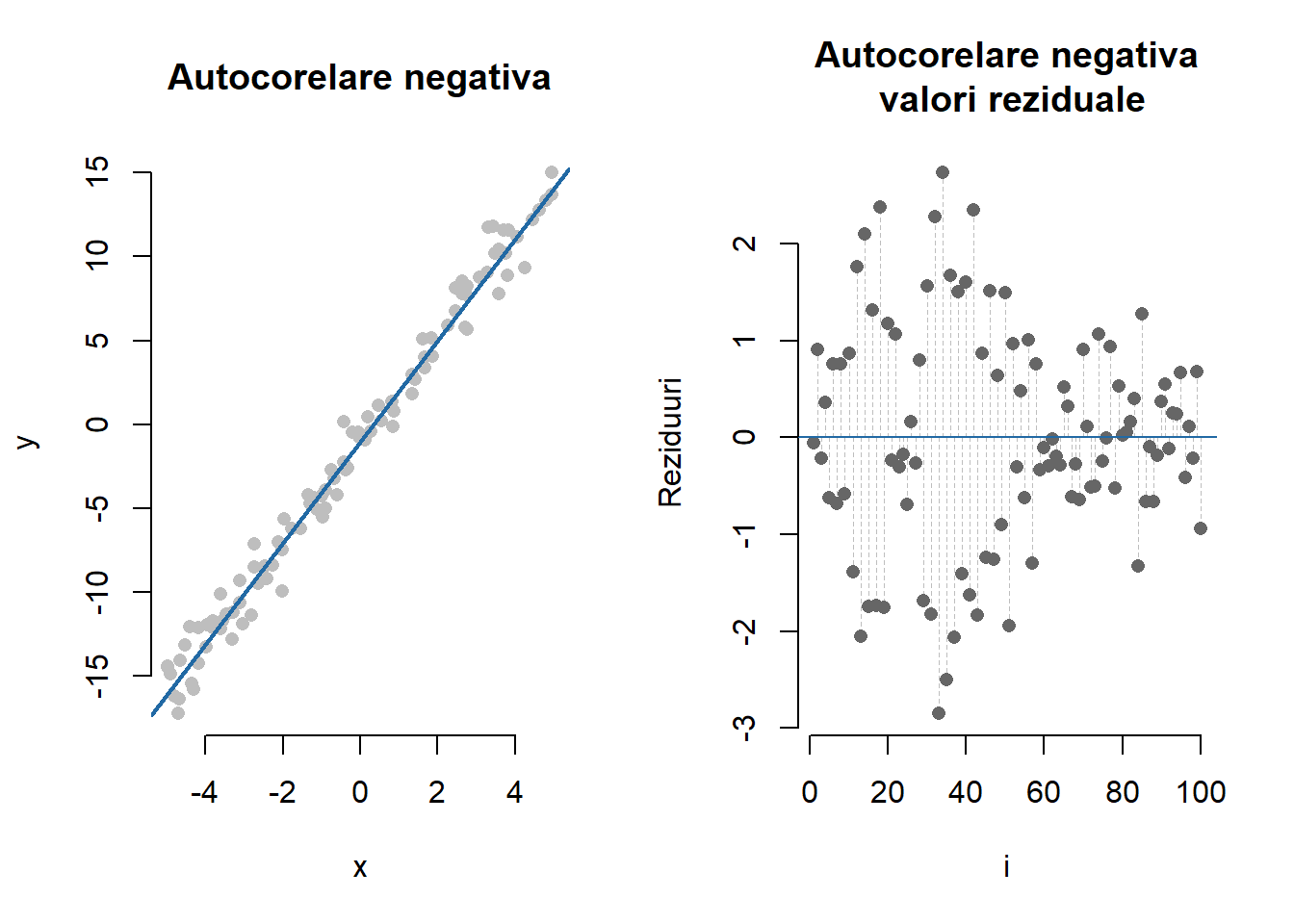
Arată codul R pentru figura de mai sus
#--------------------------------------------------
# Ilustrarea proprietății de autocorelare negativă
#--------------------------------------------------
# model 2 - autocorelare negativa
n <- 100
x <- -5 + 10*runif(n)
u <- rnorm(n-1, 0, 0.5)
e <- numeric(n)
for (i in 2:n){
e[i] <- -0.9*e[i-1] + u[i-1]
}
y <- -1 + 3*x + e
data_dum_auto2 <- data.frame(x = x, y = y)
model_dum_auto2 <- lm(y~x, data = data_dum_auto2)
par(mfrow = c(1,2))
plot(x, y,
main = "Autocorelare negativa",
pch = 16,
col = "grey",
bty = "n",
xlab = "x",
ylab = "y",
xlim = c(-5, 5))
abline(model_dum_auto1$coefficients, col = myblue,
lwd = 2, lty = 1)
plot(1:n, model_dum_auto2$residuals,
main = "Autocorelare negativa\n valori reziduale",
# pch = 16,
type = "h",
col = "grey",
lwd = 0.5, lty = 2,
bty = "n",
xlab = "i",
ylab = "Reziduuri")
points(1:n, model_dum_auto2$residuals,
pch = 16,
col = "grey40")
abline(h = 0,
col = myblue,
lwd = 1, lty = 1)Dacă termenii eroare nu ar fi corelați ne-am aștepta ca graficul valorilor reziduale să prezinte o variație aleatoare în jurul dreptei orizontale \(\varepsilon = 0\). O abordare alternativă de a investiga dacă erorile sunt corelate este de a trasa un grafic pentru perechile \((\hat\varepsilon_{i}, \hat\varepsilon_{i+1})\).
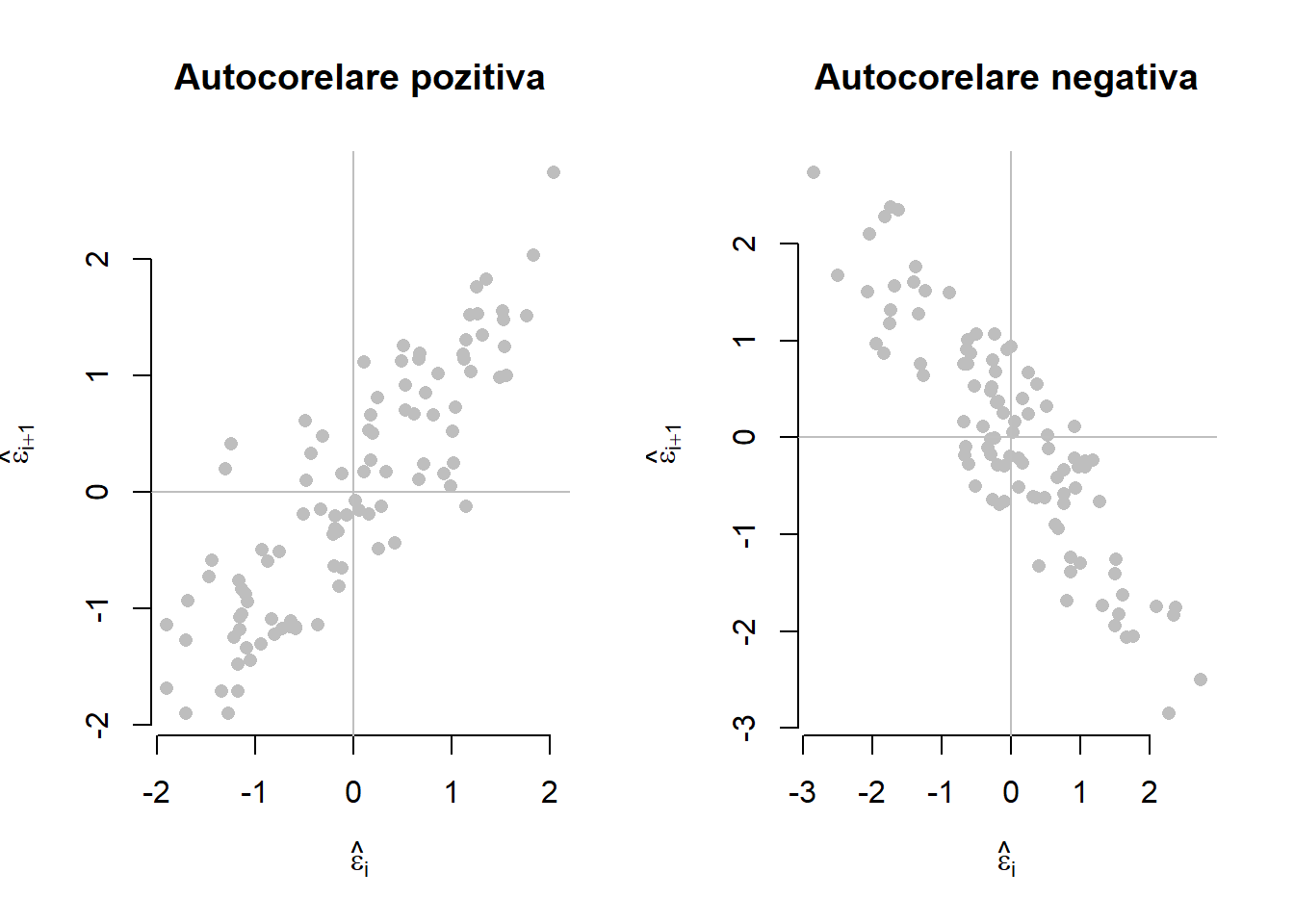
Arată codul R pentru figura de mai sus
#-----------------------------------------
# Ilustrarea proprietății de autocorelare
#-----------------------------------------
par(mfrow = c(1,2))
n <- length(residuals(model_dum_auto1))
plot(tail(residuals(model_dum_auto1),n-1) ~ head(residuals(model_dum_auto1),n-1),
pch =16,
col = "grey",
bty = "n",
xlab=expression(hat(epsilon)[i]),
ylab=expression(hat(epsilon)[i+1]),
main = "Autocorelare pozitiva")
abline(h=0,v=0,col=grey(0.75))
plot(tail(residuals(model_dum_auto2),n-1) ~ head(residuals(model_dum_auto2),n-1),
pch =16,
col = "grey",
bty = "n",
xlab=expression(hat(epsilon)[i]),
ylab=expression(hat(epsilon)[i+1]),
main = "Autocorelare negativa")
abline(h=0,v=0,col=grey(0.75))Autocorelarea erorilor apare de cele mai multe ori atunci când modelul de regresie nu este specificat corespunzător, spre exemplu atunci când lipsește o variabilă explicativă din model sau efectul unei covariabile continue este neliniar. Cu toate acestea, sunt multe situațiile în care anumite variabile explicative care ar putea fi relevante pentru răspuns nu pot fi incluse în model deoarece nu au putut fi observate și în cazul în care acestea prezintă un caracter temporal ele pot induce o corelare a termenilor eroare. Vom ilustra acest fenomen printr-un exemplu simulat.
Exemplul 2.5 (Autocorelarea erorilor - date simulate) În Figura 2.13 de mai jos sunt ilustrate diagramele de împrăștiere a variabilelor explicative \(x_1\) (stânga) și respectiv \(x_2\) (mijloc) unde se poate observa că prima covariabilă prezintă un caracter temporal (\(x_{i1} = \sum_{k = 1}^{i}a_k \sin(b_k)\) cu \(a_k\sim\mathcal{N}(0, 0.7^2)\), \(b_k\sim\mathcal{N}(0, 0.2^2)\) i.i.d și independente între ele) iar a doua fluctuează în jurul lui \(0\) (\(x_2\sim\mathcal{N}(0, 9)\)). Variabila răspuns este generată după modelul \(y_i = -1 + x_1 - 0.6x_2 + \varepsilon_i\) unde \(\varepsilon_i\sim\mathcal{N}(0, 0.5^2)\) care verifică ipotezele unui model clasic de regresie liniară.
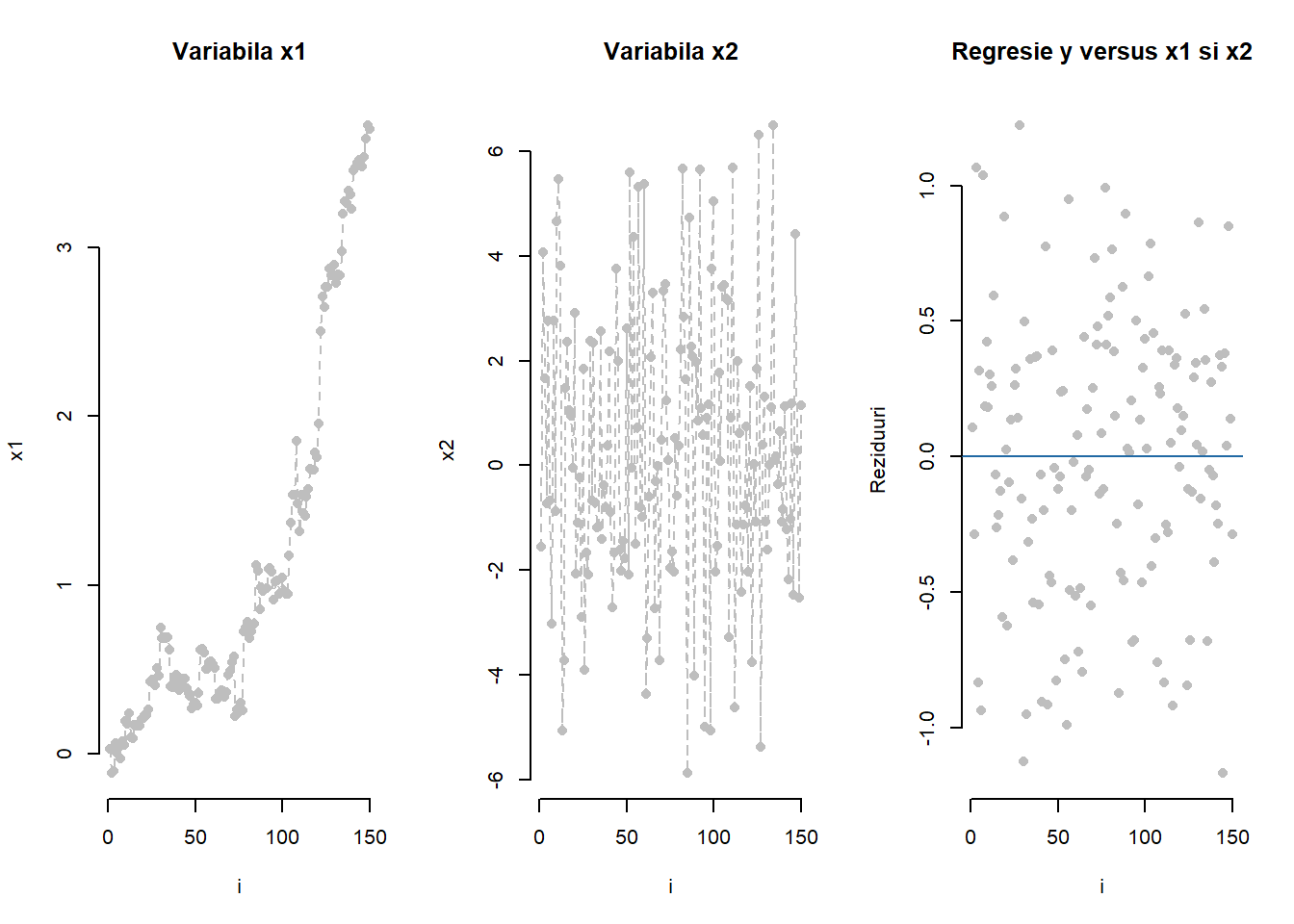
Modelul estimat obținut prin metoda celor mai mici pătrate este \(\hat y_i = -0.997 + 1.031 x_1 -0.638 x_2\) iar graficul valorilor reziduale (figura de mai sus dreapta) nu prezintă niciun indiciu asupra autocorelării termenilor eroare.
Dacă presupunem că variabila predictor \(x_2\) nu a fost observată atunci modelul de regresie liniară simplă estimat devine \(\hat y_i = -1.237 + 1.064 x_1\) iar graficul valorilor reziduale este ilustrat în figura de mai jos (stânga). Chiar dacă variabila \(x_2\) lipsește din model, coeficienții modelului ajustat (redus) sunt apropiați de valorile adevărate care au fost folosite pentru generarea datelor iar graficul valorilor reziduale prezintă același caracter aleator al erorilor.
În cazul în care variabila predictor \(x_1\) nu a fost observată atunci modelul ajutat devine \(\hat y_i = 0.179 -0.646 x_1\) dar în acest caz graficul reziduurilor prezintă o autocorelare a erorilor (figura din dreapta). Motivul pentru care apare acest fenomen este că variabila explicativă \(x_1\) prezenta un caracter temporal pe când covariabila \(x_2\) nu iar efectele acestora, \(\beta_1 x_1\) respectiv \(\beta_2 x_2\), au fost absorbite în termenul eroare. Mai exact, dacă variabila explicativă \(x_1\) (respectiv \(x_2\)) este omisă din model atunci termenul eroare devine \(\tilde\varepsilon = \beta_1 x_1 + \varepsilon\) (respectiv \(\tilde\varepsilon = \beta_2 x_2 + \varepsilon\)). Cum covariabila \(x_2\) nu prezintă un trend temporal, efectul ei păstrează necorelarea termenului eroare. Pe de altă parte, atunci când efectul covariabilei \(x_1\), care prezintă un trend temporal, este absorbit în termenul eroare acest fapt este reflectat în autocorelarea valorilor reziduale.
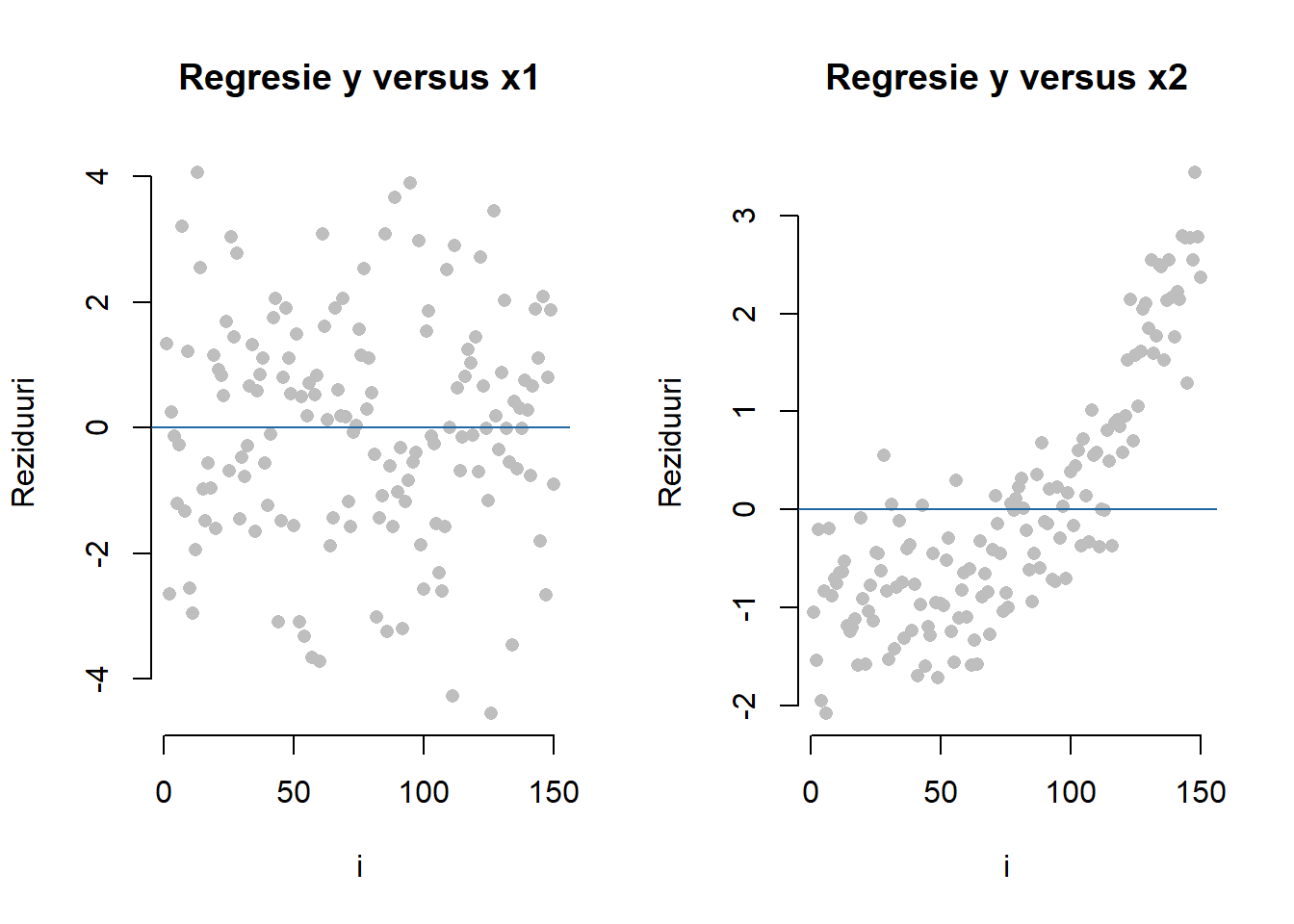
Arată codul R din exemplul de mai sus
#----------------------------------------
# Autocorelarea erorilor - date simulate
#----------------------------------------
# model autocorelated errors
par(mfrow = c(1,3))
set.seed(2999)
n <- 150
x1 <- rnorm(n, sd = 0.7)*sin(rnorm(n, sd = 0.2))
x1 <- cumsum(x1)
plot(1:n, x1,
main = "Variabila x1",
pch = 16,
col = "grey",
lwd = 0.5, lty = 2,
bty = "n",
xlab = "i",
ylab = "x1")
lines(1:n, x1,
lty = 2, col = "grey")
x2 <- rnorm(n, sd = 3)
plot(1:n, x2,
main = "Variabila x2",
pch = 16,
col = "grey",
lwd = 0.5, lty = 2,
bty = "n",
xlab = "i",
ylab = "x2")
lines(1:n, x2,
lty = 2, col = "grey")
y <- -1 + x1 - 0.6*x2 + rnorm(n, sd = 0.5)
data_exp_auto1 <- data.frame(x1 = x1, x2 = x2, y = y)
model_exp_auto1 <- lm(y ~ x1 + x2, data = data_exp_auto1)
coef_model_exp_auto1 <- round(coef(model_exp_auto1), 3)
plot(1:n, model_exp_auto1$residuals,
main = "Regresie y versus x1 si x2",
pch = 16,
col = "grey",
lwd = 0.5, lty = 2,
bty = "n",
xlab = "i",
ylab = "Reziduuri")
abline(h = 0,
col = myblue,
lwd = 1, lty = 1)
model_exp_auto_x1 <- lm(y ~ x1, data = data_exp_auto1)
coef_auto_x1 <- round(coef(model_exp_auto_x1), 3)
model_exp_auto_x2 <- lm(y ~ x2, data = data_exp_auto1)
coef_auto_x2 <- round(coef(model_exp_auto_x2), 3)
# Efectul temporal al covariabilei $x_1$ și respectiv caracterul netemporal al covariabilei $x_2$ asupra valorilor reziduale pentru modelul simulat
par(mfrow = c(1,2))
plot(1:n, model_exp_auto_x1$residuals,
main = "Regresie y versus x1",
pch = 16,
col = "grey",
lwd = 0.5, lty = 2,
bty = "n",
xlab = "i",
ylab = "Reziduuri")
abline(h = 0,
col = myblue,
lwd = 1, lty = 1)
plot(1:n, model_exp_auto_x2$residuals,
main = "Regresie y versus x2",
pch = 16,
col = "grey",
lwd = 0.5, lty = 2,
bty = "n",
xlab = "i",
ylab = "Reziduuri")
abline(h = 0,
col = myblue,
lwd = 1, lty = 1)Referințe
Cook, R. Dennis, and Sanford Weisberg. 1999. “Graphs in Statistical Analysis: Is the Medium the Message?” The American Statistician 53 (1): 29–37. https://doi.org/10.1080/00031305.1999.10474426.
Faraway, Julian. 2015. Linear Models with r. 2nd ed. CRC Press.
Johnson, Mark E. 2013. Multivariate Statistical Simulation: A Guide to Selecting and Generating Continuous Multivariate Distributions. John Wiley & Sons.
Rencher, Alvin C, and G Bruce Schaalje. 2008. Linear Models in Statistics. John Wiley & Sons.
Seber, George, and Alan Lee. 2003. Linear Regression Analysis. 2nd ed. Wiley.
Weisberg, Sanford. 2014. Applied Linear Regression. 4th ed. Wiley.