Modele de regresie
Curs 6 - Regresie liniară multiplă - Estimare
1 Estimarea parametrilor
În acest curs vom prezenta estimatorii parametrilor modelului de regresie liniară, \(\symbf\beta\) și \(\sigma^2\), precum și o serie de proprietăți statistice ale acestora fără a face ipoteze suplimentare asupra distribuției răspunsului. Înainte de a începe, vom reaminti că modelul de regresie liniară multiplă se poate scrie sub forma matriceală \(\symbf Y = \symbf X\symbf \beta + \symbf \varepsilon\), unde \(\symbf Y\), \(\symbf X\), \(\symbf\beta\), și \(\symbf\varepsilon\) sunt în conformitate cu Definiția 2.1 din Cursul 4. Ipotezele făcute asupra modelului sunt cele menționate în secțiunea Modelare și anume:
\[ \left\{\begin{array}{ll} \mathcal{H}_1: \, rang(\symbf X) = p+1,\, (n>p+1) \\ \mathcal{H}_2: \, \mathbb{E}[\symbf \varepsilon] = 0,\, Var(\symbf \varepsilon) = \sigma^2 I_n. \end{array}\right. \]
1.1 Estimarea coeficienților de regresie prin metoda celor mai mici pătrate
În conformitate cu metoda celor mai mici pătrate (ordinary least squares), coeficienții (necunoscuți) modelului de regresie \(\symbf\beta\) se estimează prin minimizarea costului total
\[ \underset{\symbf\beta\in\mathbb{R}^{p+1}}{\arg\min}\sum_{i = 1}^{n}L\left(y_i - \underbrace{\left(\beta_0 + \beta_1 x_{i1} + \cdots + \beta_p x_{ip}\right)}_{f(\symbf x_i)}\right) \]
unde funcția de \(L\) este funcția de cost pătratic \(L(u) = u^2\). Prin urmarea, estimatorul \(\hat{\symbf \beta}\) obținut prin metoda celor mai mici pătrate este definit prin
\[ \begin{aligned} \hat{\symbf \beta} &= \underset{\symbf\beta\in\mathbb{R}^{p+1}}{\arg\min}\sum_{i = 1}^{n}\left[y_i - \left(\beta_0 + \beta_1 x_{i1} + \cdots + \beta_p x_{ip}\right)\right]^2 = \underset{\symbf\beta\in\mathbb{R}^{p+1}}{\arg\min}\sum_{i = 1}^{n}\left(y_i - \sum_{j= 0}^{p}\beta_j x_{ij}\right)^2 \\ &= \underset{\symbf\beta\in\mathbb{R}^{p+1}}{\arg\min}\left\lVert \symbf Y - \symbf X \symbf\beta\right\rVert^2 \end{aligned} \]
unde am folosit convenția \(x_{i0} = 1\), \(i = 1,2,\ldots,n\).
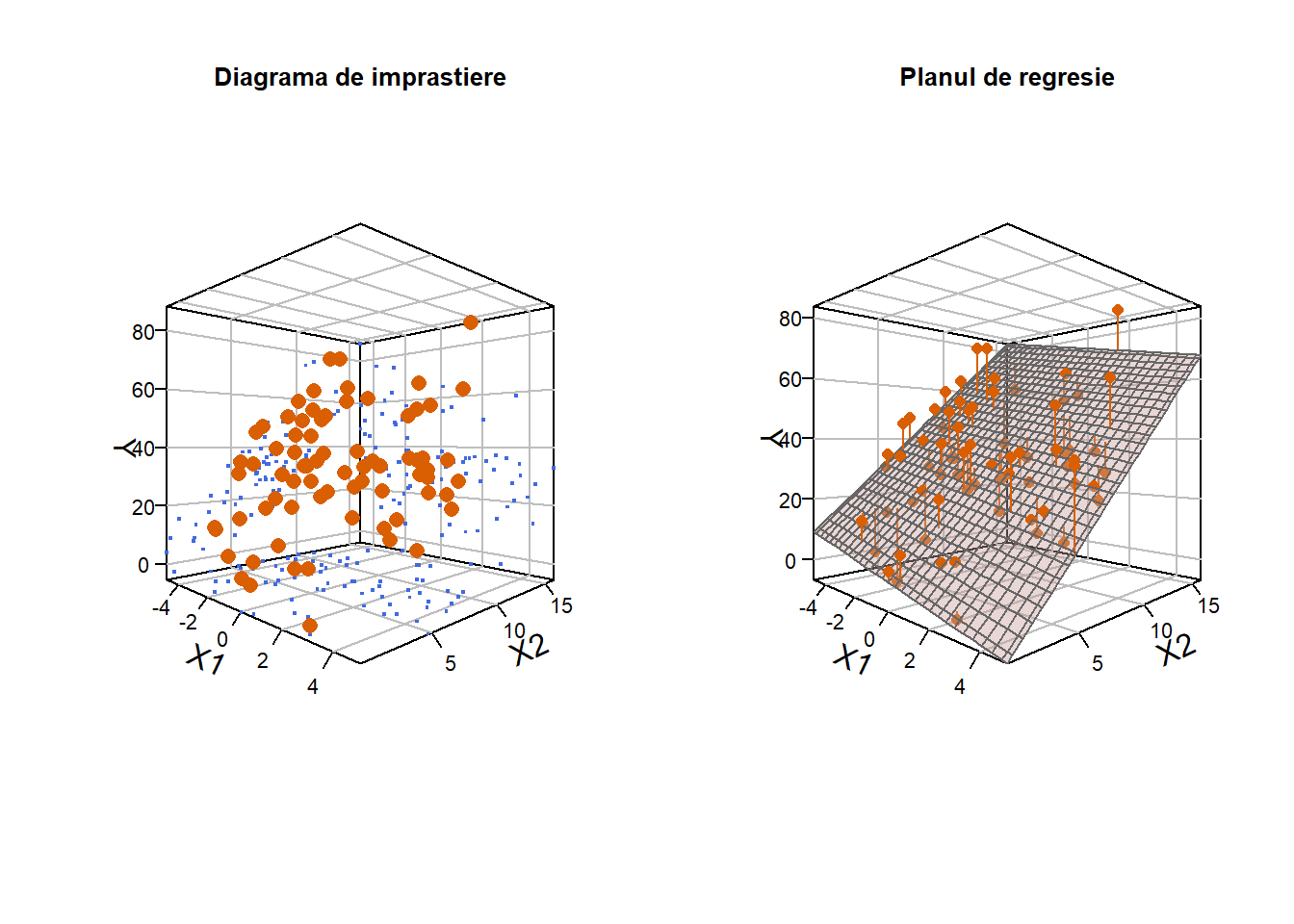
De exemplu, în cazul în care \(p=2\), în care avem doar două variabile explicative și putem afișa observațiile într-un cadru trei dimensional, Figura 1.1 de mai jos ilustrează, pentru un set de date simulat, diagrama de împrăștiere (cu proiecțiile pe fiecare plan - albastru) împreună cu planul de regresie obținut prin metoda celor mai mici pătrate (acel plan pentru care suma pătratelor distanțelor verticale până la plan este minimă).
În propoziția următoare prezentăm forma estimatorului coeficienților de regresie obținut prin metoda celor mai mici pătrate:
Propoziția 1.1 (Metoda celor mai mici pătrate) Dacă ipoteza \(\mathcal{H}_1\) este adevărată atunci estimatorul \(\hat{\symbf \beta}\) obținut prin metoda celor mai mici pătrate este
\[ \hat{\symbf \beta} = (\symbf{X}^\intercal \symbf X)^{-1}\symbf{X}^\intercal \symbf Y \]
Demonstrație (Propoziția 1.1). Ne propunem să prezentăm mai multe metode de calcul pentru estimatorul \(\hat{\symbf \beta}\).
- Metoda geometrică
Din punct de vedere geometric, ne plasăm în spațiul variabilelor \(\mathbb{R}^n\) (am presupus că \(n>p\))). Vectorul variabilelor răspuns \(\symbf Y\in \mathbb{R}^n\) iar matricea de design \(\symbf{X}\) poate fi văzută ca fiind formată din \(p+1\) vectori coloană, \(\symbf{X} = \left[\underbrace{\symbf X_0}_{\mathbf{1} = (1,\cdots,1)}|\symbf X_1|\cdots|\symbf X_p\right]\).
Începem prin a reaminti câteva noțiuni de algebră liniară, pentru mai multe detalii se poate consulta monografia (Ornea and Turtoi 2000). Fiind dată matricea (de design) \(\symbf{X}\in\mathcal{M}_{n,p+1}(\mathbb{R})\) putem defini nucleul matricii
\[ \ker(\symbf{X}) = \left\{\symbf u\in\mathbb{R}^{p+1}\,|\, \symbf{X}\symbf u = 0\right\} \]
ca fiind subspațiul lui \(\mathbb{R}^{p+1}\) care conține vectorii ortogonali pe liniile din matricea \(\symbf{X}\). De asemenea, imaginea matricii \(\symbf{X}\) este subspațiul vectorilor din \(\mathbb{R}^n\) care se pot scrie ca o combinație liniară de coloanele matricii \(\symbf{X}\) și este definit prin
\[ \mathrm{Im}(\symbf{X}) = \left\{\symbf v\in\mathbb{R}^{n}\,|\,\exists \symbf u\in\mathbb{R}^{p+1} \text{ a.î. } \symbf{X}\symbf u = \symbf v\right\}. \]
Se poate arăta (a se vedea (Ornea and Turtoi 2000, Capitolul 1)) că \(\dim \ker(\symbf{X}) = p + 1 - \mathrm{rang}(\symbf{X})\) și că \(\dim \mathrm{Im}(\symbf{X}) = \mathrm{rang}(\symbf{X})\) ceea ce conduce la \(\dim \ker(\symbf{X}) + \dim \mathrm{Im}(\symbf{X}) = p+1\) (caz particular al teoremei lui Grassman).
Reamintim că doi vectori \(\symbf u\) și \(\symbf v\) sunt ortogonali dacă \(\langle \symbf u, \symbf v\rangle = 0\), iar în acest caz scriem \(\symbf u \perp \symbf v\), și că două subspații \(V\) și \(W\) sunt ortogonale dacă \(\forall \symbf v \in V\) și respectiv \(\forall \symbf w \in W\) avem \(\symbf v\perp \symbf w\) și notăm \(V\perp W\). De asemenea, spațiul ortogonal al lui \(V\) este spațiul \(V^{\perp}\) care conține toți vectorii ortogonali pe \(V\) și are ca proprietăți: \(V\cap V^{\perp} = \{0\}\) și \(\left(V^{\perp}\right)^\perp = V\). Se poate arăta cu ușurință că dacă \(V\) este un subspațiu a lui \(W\subset\mathbb{R}^n\) atunci pentru orice vector \(\symbf w\in W\) avem că \(\symbf w = \symbf v + \symbf v^\perp\) unde \(\symbf v\in V\) și \(\symbf v^\perp\in V^\perp\) iar descompunerea se face în mod unic (acest rezultat se mai scrie și sub forma \(W = V\oplus V^\perp\)). Se numește proiecție ortogonală1 a lui \(\symbf w\) pe \(V\) de-a lungul lui \(V^\perp\) endomorfismul \(p_V: W\to W\) definit prin \(p_V(\symbf w) = \symbf v\). Se poate arăta cu ușurință că dacă \(V\) este un subspațiu vectorial al lui \(W\) atunci au loc următoarele proprietăți:
pentru orice \(\symbf w\in W\) avem: \(\symbf w = p_V(\symbf w) + p_{V^\perp}(\symbf w)\), \(\lVert p_V(\symbf w)\rVert \leq \lVert \symbf w\rVert\) iar \(\symbf w - p_{V}(\symbf w) \perp \symbf v\), \(\forall \symbf v \in V\)
pentru orice \(\symbf w\in W\) are loc \(\lVert \symbf w - p_V(\symbf w)\rVert = \inf_{\symbf v\in V}\lVert \symbf w - \symbf v\rVert\)
dacă \(p\) este o proiecție ortogonală atunci \(p\circ p = p\)
dacă \(p\) este un endomorfism care verifică \(p\circ p = p\) și în plus \(\textrm{Im}(p)\perp \ker(p)\) atunci \(p\) este proiecția ortogonală pe \(\textrm{Im}(p)\) de-a lungul lui \(\ker(p)\)
dacă \(\{\symbf e_1, \symbf e_2, \ldots, \symbf e_k\}\) este o bază ortonormală în \(V\) atunci \(p_V(\symbf w) = \sum_{i = 1}^{k}\langle \symbf w, \symbf e_i\rangle \symbf e_i\)
Spunem că o matrice pătratică \(P\in\mathcal{M}_{n}(\mathbb{R})\) este o matrice de proiecție dacă este idempotentă \(P^2 = P\) (numele vine de la faptul că pentru \(\symbf x\in\mathbb{R}^n\) aplicația liniară \(P\symbf x\) este proiecția lui \(\symbf x\) pe \(\mathrm{Im}(P)\) de-a lungul lui \(\ker(P)\) - a se vedea (Ornea and Turtoi 2000, Capitolul 1, Secțiunea 5.2) sau (Yanai et al. 2011, Capitolul 2)). Dacă în plus matricea \(P\) este simetrică, i.e. \(P = P^\intercal\), atunci \(P\symbf x\) este proiecția ortogonală a lui \(\symbf x\) pe \(V = \mathrm{Im}(P)\) de-a lungul lui \(V^\perp = \ker(P)\), cu alte cuvinte în descompunerea \(\symbf x = P\symbf x + (I - P)\symbf x\) vectorii \(P\symbf x\) și respectiv \((I - P)\symbf x\) sunt ortogonali (Yanai et al. 2011, Capitolul 2, Secțiunea 2.2). Prin urmare matricea \(P\) este o matrice de proiecție ortogonală dacă are loc relația \(\symbf v\perp \symbf v - P\symbf v\) adică \(\langle\symbf v, \symbf v - P\symbf v\rangle = 0\) pentru toți \(\symbf v\).
Dacă \(\symbf{X}\in\mathcal{M}_{m,k}(\mathbb{R})\) este o matrice de \(\mathrm{rang}(\symbf{X}) = k\) (\(m\geq k\)), deci \(\symbf{X}^\intercal\symbf{X}\) este inversabilă, atunci pentru a determina matricea de proiecție ortogonală \(P_X\) pe subspațiul imagine \(\mathrm{Im}(\symbf{X})\) să observăm că dacă \(\symbf v\in \textrm{Im}(\symbf X)\) atunci \(\symbf v = \symbf X \symbf \alpha\) și cum \(P_X \symbf v = \symbf v\) deducem că \(P_X \symbf v = \symbf{X}\underbrace{\left(\symbf{X}^\intercal\symbf{X}\right)^{-1}\symbf{X}^\intercal \symbf v}_{= \symbf \alpha}\). În plus dacă \(\symbf v^\perp\in \textrm{Im}(\symbf X)^\perp = \ker(\symbf X^\intercal)\) atunci \(\symbf X^\intercal\symbf v^\perp = 0\) prin urmare \(\symbf{X}\left(\symbf{X}^\intercal\symbf{X}\right)^{-1}\symbf{X}^\intercal \symbf v^\perp = 0\) și astfel, pentru \(\symbf w = \symbf v + \symbf v^\perp\) arbitrar, avem \(P_{X}\symbf w = \symbf{X}\left(\symbf{X}^\intercal\symbf{X}\right)^{-1}\symbf{X}^\intercal\symbf w\) de unde găsim că
\[ P_{X} = \symbf{X}\left(\symbf{X}^\intercal\symbf{X}\right)^{-1}\symbf{X}^\intercal. \]
În mod similar se arată că matricea de proiecție ortogonală pe \(\ker(\symbf{X})\) este \(P_{X\perp} = I - P_{X}\). Nu este dificil de văzut că cele două matrice, \(P_{X}\) și respectiv \(P_{X\perp}\), sunt idempotente. De asemenea, ținând seama că valorile proprii ale unei matrice idempotente sunt \(0\) sau \(1\) concluzionăm că \(\mathrm{rang}(P_X) = \mathrm{Tr}(P_X)\).
În cazul particular în care \(\symbf{X} = \symbf{v}\) avem
\[ P_v = \symbf{v}\left(\symbf{v}^\intercal\symbf{v}\right)^{-1}\symbf{v}^\intercal = \frac{\symbf{v}\symbf{v}^\intercal}{\lVert\symbf{v}\rVert^2} \]
prin urmare proiecția vectorului \(\symbf{u}\) pe \(\symbf{v}\) este \(P_v\symbf{u} = \frac{\symbf{v}\symbf{v}^\intercal}{\lVert\symbf{v}\rVert^2}\symbf{u} = \frac{\langle\symbf{u}, \symbf{v}\rangle}{\lVert\symbf{v}\rVert^2}\symbf{v}\).
Pentru problema noastră, notăm cu \(\mathcal{M}(X) = \mathrm{Im}(\symbf{X})\) subspațiul imagine și conform ipotezei \(\mathcal{H}_1\) avem că \(\mathrm{rang}(\symbf{X}) = p+1\), deci \(\dim \mathcal{M}(X) = p+1\). Din definiția spațiului imagine avem că toți vectorii din \(\mathcal{M}(X)\) sunt de forma \(\symbf X \symbf\alpha\), cu \(\symbf \alpha = (\alpha_0, \alpha_1,\ldots, \alpha_p)\in\mathbb{R}^{p+1}\)
\[ \symbf X \symbf\alpha = \sum_{i = 0}^{p}\alpha_i \symbf X_i. \]
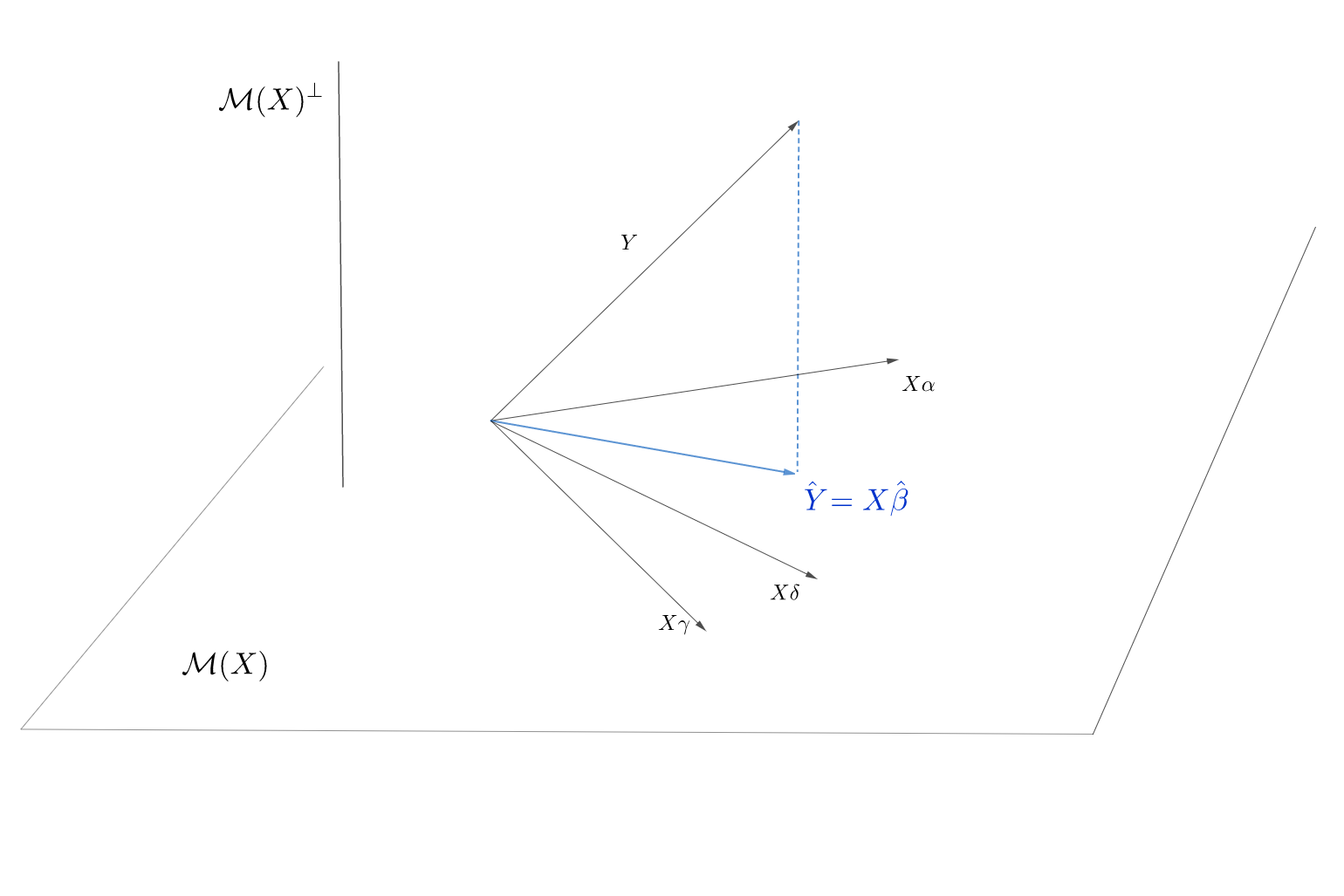
Conform modelului de regresie, \(\symbf Y = \symbf X\symbf \beta + \symbf \varepsilon\), vectorul răspuns \(\symbf Y\) este suma dintre un element din \(\mathcal{M}(X)\) și un element din \(\mathbb{R}^n\) care nu are niciun motiv să aparțină tot lui \(\mathcal{M}(X)\). Astfel, problema minimizării funcției \(S(\symbf \beta) = \left\lVert \symbf Y - \symbf X \symbf\beta\right\rVert^2\) revine la a găsi acel vector din \(\mathcal{M}(X)\) care este cel mai aproape de \(\symbf Y\) în sensul distanței euclidiene, cu alte cuvinte de a determina vectorul proiecției ortogonale a lui \(\symbf Y\) pe \(\mathcal{M}(X)\) (a se vedea figura de mai jos).
Proiecția ortogonală a lui \(\symbf Y\) pe \(\mathcal{M}(X)\) se notează cu \(\hat{\symbf Y} = P_X \symbf Y\), unde \(P_X\) este matricea de proiecție ortogonală pe \(\mathcal{M}(X)\), iar spațiul ortogonal \(\mathcal{M}(X)^\perp\) se mai numește și spațiul reziduurilor și are dimensiunea \(\dim \mathcal{M}(X)^\perp = n - (p+1)\) (teorema lui Grassman). Să remarcăm că \(\hat{\symbf Y}\in\mathcal{M}(X)\) deci putem scrie \(\hat{\symbf Y} = \symbf X\hat{\symbf \beta}\) unde \(\hat{\symbf \beta}\) reprezintă estimatorul obținut prin metoda celor mai mici pătrate iar elementele lui \(\hat{\symbf \beta}\) sunt coordonatele vectorului \(\hat{\symbf Y}\) în baza \(\{\symbf X_0, \symbf X_1,\ldots, \symbf X_p\}\) a spațiului \(\mathcal{M}(X)\). Cum reperul \(\{\symbf X_0, \symbf X_1,\ldots, \symbf X_p\}\) nu este neapărat ortogonal, elementele \(\hat{\beta_j}\) nu sunt neapărat coordonatele proiecției lui \(\symbf Y\) pe \(\symbf X_j\), aceasta din urmă fiind dată de
\[\begin{align*} P_{X_j}\symbf Y &= P_{X_j}P_X \symbf Y = P_{X_j}\sum_{i = 0}^{p} \hat{\beta_i}\symbf X_i\\ &= \sum_{i = 0}^{p}\hat{\beta_i} P_{X_j}\symbf X_i = \hat{\beta_j} \symbf X_j + \sum_{i \neq j}\hat{\beta_i} P_{X_j}\symbf X_i \end{align*}\]
În cazul în care \(\symbf X_j\) este ortogonal pe \(\symbf X_i\), \(i\neq j\), atunci \(P_{X_j}\symbf Y = \hat{\beta_j} \symbf X_j\) iar dacă \(\langle\symbf X_i, \symbf X_j\rangle = 0\) pentru toți \(i\neq j\) atunci matricea \(\symbf X^\intercal\symbf X = \mathrm{diag}\left(\lVert\symbf X_0\rVert^2, \lVert\symbf X_1\rVert^2, \ldots, \lVert\symbf X_p\rVert^2\right)\).
O altă metodă (tot prin proiecții) de a arăta că \(\hat{\symbf \beta} = (\symbf{X}^\intercal \symbf X)^{-1}\symbf{X}^\intercal \symbf Y\) se bazează pe observația că proiecția ortogonală \(\hat{\symbf Y} = \symbf X\hat{\symbf \beta}\) este definită ca fiind unicul vector pentru care \(\symbf Y - \hat{\symbf Y}\) este ortogonal pe \(\mathcal{M}(X)\). Cum \(\mathcal{M}(X)\) este generat de \(\{\symbf X_0, \symbf X_1,\ldots, \symbf X_p\}\) putem spune că \(\symbf Y - \hat{\symbf Y}\) este ortogonal pe fiecare \(\symbf X_i\):
\[ \left\{\begin{array}{lll} \langle \symbf X_0, \symbf Y - \hat{\symbf Y}\rangle = 0\\ \langle \symbf X_1, \symbf Y - \hat{\symbf Y}\rangle = 0\\ \vdots\\ \langle \symbf X_p, \symbf Y - \hat{\symbf Y}\rangle = 0 \end{array}\right. \iff \left\{\begin{array}{lll} \langle \symbf X_0, \symbf Y - \symbf X\hat{\symbf \beta}\rangle = 0\\ \langle \symbf X_1, \symbf Y - \symbf X\hat{\symbf \beta}\rangle = 0\\ \vdots\\ \langle \symbf X_p, \symbf Y - \symbf X\hat{\symbf \beta}\rangle = 0 \end{array}\right. \iff \symbf X^\intercal \left(\symbf Y - \symbf X\hat{\symbf \beta}\right) = 0 \]
de unde găsim sistemul de ecuații normale
\[ \symbf X^\intercal\symbf X\hat{\symbf \beta} = \symbf X^\intercal\symbf Y \]
care, atunci când ipoteza \(\mathcal{H}_1\) este adevărată - matricea \(\symbf X^\intercal \symbf X\) este inversabilă, revine la
\[ \hat{\symbf \beta} = (\symbf X^\intercal \symbf X)^{-1} \symbf X^\intercal \symbf Y. \]
Notând cu \(P_{X^\perp} = I_n - P_X\) matricea de proiecție ortogonală pe \(\mathcal{M}^\perp(X)\), unde \(P_X = \symbf X(\symbf X^\intercal \symbf X)^{-1} \symbf X^\intercal\) este matricea de proiecție ortogonală pe \(\mathcal{M}(X)\), observăm că descompunerea
\[ \symbf Y = \hat{\symbf Y} + \left(\symbf Y - \hat{\symbf Y}\right) = P_X\symbf Y + (I - P_X)\symbf Y = P_X\symbf Y + P_{X^\perp}\symbf Y \]
nu este altceva decât descompunerea ortogonală a lui \(\symbf Y\) pe \(\mathcal{M}(X)\) și respectiv \(\mathcal{M}^\perp(X)\). De asemenea este de remarcat faptul că în ceea ce privește notația folosită în literatura de statistică de specialitate, matricea de proiecție ortogonală \(P_X\) se mai notează și cu \(H\) (care vine de la hat, \(\hat{\symbf Y} = H\symbf Y\)).
- Metoda analitică
O a doua metodă este metoda analitică. Problema noastră cere să căutăm vectorul \(\symbf \beta\in\mathbb{R}^{p+1}\) care minimizează funcția
\[\begin{align*} S(\symbf \beta) &= \left\lVert \symbf Y - \symbf X \symbf\beta\right\rVert^2 = \left(\symbf Y - \symbf X \symbf\beta\right)^\intercal\left(\symbf Y - \symbf X \symbf\beta\right) = \symbf Y^\intercal \symbf Y - \symbf Y^\intercal \symbf X \symbf\beta - \symbf \beta^\intercal \symbf X^\intercal \symbf Y + \symbf \beta^\intercal \symbf X^\intercal \symbf X \symbf\beta \\ & = \symbf \beta^\intercal \symbf X^\intercal \symbf X \symbf\beta - 2 \symbf Y^\intercal \symbf X \symbf\beta + \lVert \symbf Y \rVert^2 \end{align*}\]
unde am folosit faptul că \(\symbf Y^\intercal \symbf X \symbf\beta = \left(\symbf Y^\intercal \symbf X \symbf\beta\right)^\intercal = \symbf \beta^\intercal \symbf X^\intercal \symbf Y\) (sunt elemente de dimensiune \(1\times 1\)). Pentru aceasta trebuie să rezolvăm ecuația \(\nabla S(\symbf \beta) = 0\) și să verificăm că soluția este într-adevăr punct de minim.
Reamintim că dacă \(f:\mathbb{R}^k\to\mathbb{R}\) atunci
\[ \nabla f = \frac{\partial f}{\partial \symbf x^\intercal} = \begin{pmatrix}\frac{\partial f}{\partial x_1} & \frac{\partial f}{\partial x_2} & \cdots & \frac{\partial f}{\partial x_k}\end{pmatrix}. \]
În particular, pentru \(f(\symbf x) = \symbf a^\intercal \symbf x\) (formă liniară) avem
\[ \nabla f = \frac{\partial \symbf a^\intercal \symbf x}{\partial \symbf x^\intercal} = \begin{pmatrix}\frac{\partial \sum_{i=1}^{k}a_i x_i}{\partial x_1} & \frac{\partial \sum_{i=1}^{k}a_i x_i}{\partial x_2} & \cdots & \frac{\partial \sum_{i=1}^{k}a_i x_i}{\partial x_k}\end{pmatrix} = \symbf a^\intercal \]
iar \(\frac{\partial \symbf a^\intercal \symbf x}{\partial \symbf x} = \symbf a\).
În cazul în care \(f\) este o aplicație liniară, \(f(\symbf x) = A \symbf x\) unde \(A\in\mathcal{M}_{m,k}(\mathbb{R})\), atunci
\[ A \symbf x = \begin{pmatrix}\sum_{j=1}^{k}a_{1j} x_j\\ \sum_{j=1}^{k}a_{2j} x_j\\ \vdots\\ \sum_{j=1}^{k}a_{mj} x_j\end{pmatrix}, \qquad \frac{\partial A \symbf x}{\partial x_j} = \begin{pmatrix}a_{1j}\\ a_{2j}\\ \vdots\\ a_{mj}\end{pmatrix} \]
și
\[ \frac{\partial A \symbf x}{\partial \symbf x^\intercal} = \begin{pmatrix}\begin{pmatrix}a_{11}\\ a_{21}\\ \vdots\\ a_{m1}\end{pmatrix}, \ldots, \begin{pmatrix}a_{1j}\\ a_{2j}\\ \vdots\\ a_{mj}\end{pmatrix}, \ldots, \begin{pmatrix}a_{1k}\\ a_{2k}\\ \vdots\\ a_{mk}\end{pmatrix}\end{pmatrix} = \begin{pmatrix}a_{11} & \cdots & a_{1j} & \cdots & a_{1k}\\ \vdots & \ddots & \vdots & \ddots & \vdots\\ a_{i1} & \cdots & a_{ij} & \cdots & a_{ik}\\ \vdots & \ddots & \vdots & \ddots & \vdots\\ a_{m1} & \cdots & a_{mj} & \cdots & a_{mk} \end{pmatrix} = A. \]
În mod similar se poate verifica și relația \(\frac{\partial \symbf x^\intercal A^\intercal}{\partial \symbf x} = A^\intercal\).
Dacă \(f\) este o formă pătratică \(f(\symbf x) = \symbf x^\intercal A \symbf x\) cu \(A\in\mathcal{M}_{k}(\mathbb{R})\) (matrice pătratică de ordin \(k\)), atunci
\[ \symbf x^\intercal A \symbf x = \sum_{i = 1}^{k}\sum_{j = 1}^{k}a_{ij}x_ix_j = \sum_{i = 1}^{k}a_{ii}x_i^2 + \sum_{i = 1}^{k}\sum_{\substack{j = 1\\ j\neq i}}^{k}a_{ij}x_ix_j \]
de unde
\[ \frac{\partial \symbf x^\intercal A \symbf x}{\partial x_r} = 2 a_{rr}x_r + \sum_{j\neq r}a_{rj}x_j + \sum_{i\neq r}a_{ir}x_i = \sum_{j = 1}^{k}a_{rj}x_j + \sum_{i = 1}^{k}a_{ir}x_i \]
prin urmare
\[ \frac{\partial \symbf x^\intercal A \symbf x}{\partial \symbf x} = \begin{pmatrix}\frac{\partial \symbf x^\intercal A \symbf x}{\partial x_1}\\ \vdots\\ \frac{\partial \symbf x^\intercal A \symbf x}{\partial x_k}\end{pmatrix} = \begin{pmatrix}\sum_{j = 1}^{k}a_{1j}x_j + \sum_{i = 1}^{k}a_{i1}x_i\\ \vdots\\ \sum_{j = 1}^{k}a_{kj}x_j + \sum_{i = 1}^{k}a_{ik}x_i\end{pmatrix} = A\symbf x + A^\intercal \symbf x. \]
De asemenea putem observa că \(\frac{\partial \symbf x^\intercal A \symbf x}{\partial \symbf x^\intercal} = \left(A\symbf x + A^\intercal \symbf x\right)^\intercal = \symbf x^\intercal A^\intercal + \symbf x^\intercal A\).
În plus, dacă \(A\in\mathcal{M}_{k}(\mathbb{R})\) este o matrice simetrică (\(A^\intercal = A\)) atunci
\[ \frac{\partial \symbf x^\intercal A \symbf x}{\partial \symbf x} = 2A\symbf x, \quad \frac{\partial \symbf x^\intercal A \symbf x}{\partial \symbf x^\intercal} = 2\symbf x^\intercal A^\intercal. \]
Revenind la problema noastră observăm că \(S(\symbf \beta)\) este pătratică în \(\symbf \beta\) iar matricea \(\symbf X^\intercal \symbf X\) este simetrică, prin urmare
\[ \nabla S(\symbf \beta) = \frac{\partial S(\symbf \beta)}{\partial \symbf \beta^\intercal} = \frac{\partial }{\partial \symbf \beta^\intercal}\left(\symbf \beta^\intercal \symbf X^\intercal \symbf X \symbf\beta - 2 \symbf Y^\intercal \symbf X \symbf\beta + \lVert \symbf Y \rVert^2\right) = 2 \symbf \beta^\intercal (\symbf X^\intercal \symbf X) - 2 \symbf Y^\intercal \symbf X = 0 \]
este echivalentă cu sistem de ecuații normale (prin trecerea la transpusă)
\[ (\symbf X^\intercal \symbf X)\symbf \beta = \symbf X^\intercal\symbf Y \]
care atunci când ipoteza \(\mathcal{H}_1\) este adevărată, ceea ce conduce la inversabilitatea matricii \(\symbf X^\intercal \symbf X\) (are valori proprii nenule), revine la
\[ \hat{\symbf \beta} = (\symbf X^\intercal \symbf X)^{-1} \symbf X^\intercal \symbf Y. \]
Pentru a arăta că \(\hat{\symbf \beta}\) este într-adevăr un punct de minim pentru \(S(\symbf \beta)\) trebuie să arătăm că matricea hessiană este pozitiv definită. Matricea hessiană, ținând cont de simetria matricii \(\symbf X^\intercal \symbf X\), este
\[ \frac{\partial^2 S(\symbf \beta)}{\partial \symbf \beta\partial \symbf \beta^\intercal} = \frac{\partial}{\partial \symbf \beta}\left(\frac{\partial S(\symbf \beta)}{\partial \symbf \beta^\intercal}\right) = \frac{\partial}{\partial \symbf \beta}\left(2 \symbf \beta^\intercal (\symbf X^\intercal \symbf X) - 2 \symbf Y^\intercal \symbf X\right) = 2 \symbf X^\intercal \symbf X \]
iar pentru \(\symbf u\in\mathbb{R}^{p+1}\backslash\{0\}\) avem
\[ \symbf u^\intercal \frac{\partial^2 S(\symbf \beta)}{\partial \symbf \beta\partial \symbf \beta^\intercal} \symbf u = \symbf u^\intercal \left(2 \symbf X^\intercal \symbf X\right) \symbf u = \langle \symbf X\symbf u, \symbf X\symbf u\rangle = 2\lVert \symbf X\symbf u\rVert^2 > 0 \]
deci \(\symbf X^\intercal \symbf X\) este pozitiv definită prin urmare și \(\frac{\partial^2 S(\symbf \beta)}{\partial \symbf \beta\partial \symbf \beta^\intercal}\) este pozitiv definită.
În cele ce urmează vom prezenta două cazuri particulare ale modelului de regresie liniară: modelul nul și respectiv modelul de regresie liniară simplă.
Exemplul 1.1 (Modelul nul) În acest exemplu considerăm că modelul de regresie liniară nu conține niciun predictor ci doar termenul constant \(\mu\), prin urmare modelul se scrie
\[ y_i = \mu + \varepsilon_i, \quad i = 1,2,\ldots,n. \]
Acesta este un caz particular în care \(p = 0\), \(\symbf X = \symbf 1\) iar \(\symbf \beta = \mu\). Cum \(\symbf X^\intercal \symbf X = \symbf 1^\intercal\symbf 1 = n\) găsim că estimatorul coeficientului de regresie obținut prin metoda celor mai mici pătrate este
\[ \hat\beta = (\symbf{X}^\intercal \symbf X)^{-1}\symbf{X}^\intercal \symbf Y = \frac{1}{n}\symbf 1^\intercal \symbf Y = \bar y \]
Exemplul 1.2 (Modelul de regresie liniară simplă) În contextul modelului de regresie liniară simplă
\[ y_i = \beta_0 + \beta_1 x_i + \varepsilon_i, \quad i = 1,2,\ldots, n \]
avem \(\symbf Y = \begin{pmatrix}y_1\\ y_2\\ \vdots \\ y_n\end{pmatrix}\), \(\symbf X = \begin{pmatrix}1 & x_1\\ 1 & x_2\\ \vdots & \vdots \\ 1 & x_n\end{pmatrix}\) iar \(\symbf\beta = \begin{pmatrix}\beta_0\\ \beta_1\end{pmatrix}\). Astfel găsim că
\[ \symbf{X}^\intercal \symbf X = \begin{pmatrix}n & \sum x_i\\ \sum x_i & \sum x_i^2\end{pmatrix}, \quad \symbf{X}^\intercal \symbf Y = \begin{pmatrix}\sum y_i\\ \sum x_iy_i\end{pmatrix} \]
iar \((\symbf{X}^\intercal \symbf X)^{-1} = \frac{1}{n\sum x_i^2 - \left(\sum x_i\right)^2}\begin{pmatrix}\sum x_i^2 & -\sum x_i\\ -\sum x_i & n\end{pmatrix}\) ceea ce conduce la estimatorul
\[ \hat{\symbf\beta} = (\symbf{X}^\intercal \symbf X)^{-1}\symbf{X}^\intercal \symbf Y = \frac{1}{n\sum x_i^2 - \left(\sum x_i\right)^2}\begin{pmatrix}\left(\sum x_i^2\right)\left(\sum y_i\right) -\left(\sum x_i\right)\left(\sum x_iy_i\right)\\ -\left(\sum x_i\right)\left(\sum y_i\right) + n\sum x_iy_i\end{pmatrix} \]
care coincide (după mici manipulări algebrice) cu cel găsit anterior.
1.2 Proprietăți ale estimatorilor obținuți prin metoda celor mai mici pătrate
În această subsecțiune vom prezenta o serie de proprietăți statistice ale estimatorilor coeficienților de regresie obținuți prin metoda celor mai mici pătrate fără a face ipoteze suplimentare asupra distribuției răspunsului.
Propoziția 1.2 (Matricea de varianță-covarianță) În ipotezele \(\mathcal{H}_1\) și \(\mathcal{H}_2\), estimatorul \(\hat{\symbf \beta}\) obținut prin metoda celor mai mici pătrate este nedeplasat, i.e. \(\mathbb{E}[\hat{\symbf \beta}] = \symbf \beta\) iar matricea de varianță-covarianță \(Var\left(\hat{\symbf \beta}\right)\) este
\[ Var\left(\hat{\symbf \beta}\right) = \sigma^2 \left(\symbf X^\intercal\symbf X\right)^{-1}. \]
Pentru început, deoarece vorbim de operații cu vectori aleatori sau matrice aleatoare, vom reaminti câteva proprietăți de calcul a acestora (acestea generalizează noțiunile corespunzătoare din cazul variabilelor aleatoare). Reamintim că fiind dată matricea \(\symbf Z = \left(Z_{ij}\right)_{i,j}\) unde \(Z_{ij}\), \(1\leq i\leq m\), \(1\leq j\leq k\) sunt variabile aleatoare de medie \(\mathbb{E}[Z_{ij}]\), media matricii \(\mathbb{E}[\symbf Z]\) este definită ca matricea mediilor \(\left(\mathbb{E}[Z_{ij}]\right)_{i,j}\). În plus dacă \(\symbf A\in\mathcal{M}_{l,m}(\mathbb{R})\), \(\symbf B\in\mathcal{M}_{k,q}(\mathbb{R})\) și \(\symbf C\in\mathcal{M}_{l,q}(\mathbb{R})\) sunt trei matrice cu coeficienți constanți atunci
\[ \mathbb{E}\left[\symbf A\symbf Z\symbf B + \symbf C\right] = \symbf A\mathbb{E}[\symbf Z]\symbf B + \symbf C. \]
În mod similar, dacă \(\symbf Z\) și \(\symbf T\) sunt doi vectori aleatori de dimensiune \(m\times 1\) și respectiv \(k\times 1\) atunci covarianța acestora este definită prin \(Cov(\symbf Z, \symbf T) = \left(Cov(Z_i, T_j)\right)_{i,j}\) și se poate verifica relația
\[ Cov(\symbf Z, \symbf T) = \mathbb{E}\left[\left(\symbf Z - \mathbb{E}[\symbf Z]\right)\left(\symbf T - \mathbb{E}[\symbf T]\right)^\intercal\right] = \mathbb{E}\left[\symbf Z\symbf T^\intercal\right] - \mathbb{E}\left[\symbf Z\right]\mathbb{E}\left[\symbf T\right]^\intercal = Cov(\symbf T, \symbf Z)^\intercal. \]
În particular pentru \(\symbf T = \symbf Z\) avem matricea de varianță-covarianță \(Var(\symbf Z) = Cov(\symbf Z, \symbf Z)\) care, în conformitate cu relația de mai sus, este egală cu
\[ Var(\symbf Z) = \mathbb{E}\left[\left(\symbf Z - \mathbb{E}[\symbf Z]\right)\left(\symbf Z - \mathbb{E}[\symbf Z]\right)^\intercal\right] = \mathbb{E}\left[\symbf Z\symbf Z^\intercal\right] - \mathbb{E}\left[\symbf Z\right]\mathbb{E}\left[\symbf Z\right]^\intercal. \]
Un calcul direct arată că dacă \(\symbf A\in\mathcal{M}_{l,m}(\mathbb{R})\) și \(\symbf B\in\mathcal{M}_{q, k}(\mathbb{R})\) sunt două matrice cu coeficienți constanți atunci
\[ Cov\left(\symbf A\symbf Z, \symbf B\symbf T\right) = \symbf A Cov\left(\symbf Z, \symbf T\right)\symbf B^\intercal \]
iar atunci când \(\symbf T = \symbf Z\) și \(\symbf A = \symbf B\) găsim că \(Var(\symbf A\symbf Z) = \symbf A Var(\symbf Z)\symbf A^\intercal\). De asemenea, dacă \(\symbf Z\), \(\symbf T\), \(\symbf U\) și \(\symbf V\) sunt vectori aleatori de dimensiune \(m\times 1\) iar \(a,b,c,d\in\mathbb{R}\) sunt constante reale atunci
\[ Cov(a\symbf Z + b\symbf T, c\symbf U + d\symbf V) = ac Cov(\symbf Z, \symbf U) + ad Cov(\symbf Z, \symbf V) + bc Cov(\symbf T, \symbf U) + bd Cov(\symbf T, \symbf V) \]
și respectiv
\[ Var(a\symbf Z + b\symbf T) = a^2 Var(\symbf Z) + ab\left(Cov(\symbf Z, \symbf T) + Cov(\symbf T, \symbf Z)\right) + b^2 Var(\symbf T). \]
Demonstrație (Propoziția 1.2). Pentru a verifica nedeplasarea estimatorului \(\hat{\symbf \beta}\) obținut prin metoda celor mai mici pătrate să notăm că, în contextul ipotezei \(\mathcal{H}_1\), acesta este \(\hat{\symbf \beta} = (\symbf X^\intercal \symbf X)^{-1} \symbf X^\intercal \symbf Y\). Astfel putem scrie
\[ \mathbb{E}[\hat{\symbf \beta}] = \mathbb{E}\left[(\symbf X^\intercal \symbf X)^{-1} \symbf X^\intercal \symbf Y\right] = (\symbf X^\intercal \symbf X)^{-1} \symbf X^\intercal \mathbb{E}[\symbf Y] = (\symbf X^\intercal \symbf X)^{-1} \symbf X^\intercal \mathbb{E}[\symbf X\symbf \beta + \symbf \varepsilon] \]
și cum \(\mathbb{E}[\symbf \varepsilon] = 0\) conform \(\mathcal{H}_2\) deducem că
\[ \mathbb{E}[\hat{\symbf \beta}] = \underbrace{(\symbf X^\intercal \symbf X)^{-1} \symbf X^\intercal \symbf X}_{ = I_{p+1}}\symbf \beta + \underbrace{\mathbb{E}[\symbf \varepsilon]}_{=0} = \symbf \beta. \]
Pentru matricea de varianță-covarianță avem
\[ \begin{aligned} Var(\hat{\symbf \beta}) &= Var\left((\symbf X^\intercal \symbf X)^{-1} \symbf X^\intercal \symbf Y\right) = (\symbf X^\intercal \symbf X)^{-1} \symbf X^\intercal Var\left(\symbf Y\right) \left((\symbf X^\intercal \symbf X)^{-1} \symbf X^\intercal\right)^\intercal \\ &= (\symbf X^\intercal \symbf X)^{-1} \symbf X^\intercal Var\left(\symbf Y\right) \symbf X (\symbf X^\intercal \symbf X)^{-1} \end{aligned} \]
unde în ultima egalitate am ținut cont de simetria matricii \(\symbf X^\intercal \symbf X\): \(\left((\symbf X^\intercal \symbf X)^{-1}\right)^\intercal = (\symbf X^\intercal \symbf X)^{-1}\). Din modelul de regresie avem că \(Var\left(\symbf Y\right) = Var\left(\symbf X\symbf \beta + \symbf\varepsilon\right) = Var(\symbf\varepsilon)\) și din ipoteza \(\mathcal{H}_2\) avem \(Var(\symbf\varepsilon) = \sigma^2 I_n\) prin urmare
\[ \begin{aligned} Var(\hat{\symbf \beta}) &= (\symbf X^\intercal \symbf X)^{-1} \symbf X^\intercal \underbrace{Var\left(\symbf Y\right)}_{= \sigma^2 I_n} \symbf X (\symbf X^\intercal \symbf X)^{-1} = \sigma^2 \underbrace{(\symbf X^\intercal \symbf X)^{-1} \symbf X^\intercal \symbf X}_{= I_{p+1}} (\symbf X^\intercal \symbf X)^{-1} \\ &= \sigma^2 (\symbf X^\intercal \symbf X)^{-1}. \end{aligned} \]
Trebuie remarcat că atunci când variabilele explicative sunt ortogonale două câte două (și prin urmare și coloanele matricii de design), componentele vectorului \(\symbf\beta\) sunt necorelate deoarece matricea simetrică \(\symbf X^\intercal \symbf X\) este o matrice diagonală.
Următoarea propoziție ne spune că estimatorul obținut prin metoda celor mai mici pătrate este optimal într-o anumită clasă de estimatori.
Propoziția 1.3 (Teorema Gauss-Markov) Estimatorul \(\hat{\symbf \beta}\) obținut prin metoda celor mai mici pătrate este estimatorul liniar, nedeplasat de varianță minimală (BLUE).
Demonstrație (Propoziția 1.3). Rezultatul acestei propoziții este cunoscut și sub denumirea de Teorema Gauss-Markov (a se vedea de exemplu (Faraway 2015, Capitolul 2)). Pentru a putea demonstra acest rezultat trebuie pentru început să remarcăm câteva aspecte: în primul rând, liniaritatea estimatorului se referă la liniaritatea în raport cu \(\symbf Y\), adică vorbim de clasa estimatorilor de forma \(\symbf A\symbf Y\) unde \(\symbf A\in\mathcal{M}_{p+1, n}(\mathbb{R})\); în al doilea rând pentru a determina varianța minimală avem nevoie de o relație parțială de ordine pe mulțimea matricilor simetrice, ori o asemenea relație există și spune că \(\symbf S_1\leq \symbf S_2\) atunci când \(\symbf S = \symbf S_2 - \symbf S_1\) este pozitiv semidefinită (valorile proprii ale lui \(\symbf S\) sunt \(\geq 0\)), cu alte cuvinte \(\symbf S_1\leq \symbf S_2\) dacă \(\symbf x^\intercal\symbf S_1\symbf x\leq \symbf x^\intercal\symbf S_2\symbf x\) pentru orice \(\symbf x\).
În acest context, cum \(\hat{\symbf \beta}\) este un estimator nedeplasat (conform rezultatului anterior) și liniar deoarece \(\hat{\symbf \beta} = \underbrace{(\symbf X^\intercal \symbf X)^{-1} \symbf X^\intercal}_{A} \symbf Y\), considerând \(\tilde{\symbf \beta}\) un alt estimator liniar și nedeplasat pentru \(\symbf \beta\) vrem să arătăm că \(Var(\tilde{\symbf \beta})\geq Var(\hat{\symbf \beta})\). Avem, conform proprietăților matricei de varianță-covarianță de mai sus, descompunerea
\[ Var(\tilde{\symbf \beta}) = Var(\tilde{\symbf \beta} - \hat{\symbf \beta} + \hat{\symbf \beta}) = Var(\tilde{\symbf \beta} - \hat{\symbf \beta}) + Var(\hat{\symbf \beta}) + Cov(\tilde{\symbf \beta} - \hat{\symbf \beta}, \hat{\symbf \beta}) + Cov(\hat{\symbf \beta}, \tilde{\symbf \beta} - \hat{\symbf \beta}). \]
Cum matricile de varianță-covarianță sunt pozitiv semidefinite (pentru \(\symbf a\in\mathbb{R}^{p+1}\) avem \(\symbf a^\intercal Var(\tilde{\symbf \beta})\symbf a = Var(\symbf a^\intercal\tilde{\symbf \beta})\geq 0\), deoarece varianța este pozitivă) este suficient să arătăm că \(Cov(\tilde{\symbf \beta} - \hat{\symbf \beta}, \hat{\symbf \beta}) = 0\). Liniaritatea estimatorului \(\tilde{\symbf \beta}\) implică \(\tilde{\symbf \beta} = \symbf A\symbf Y\) iar nedeplasarea acestuia, \(\mathbb{E}[\tilde{\symbf \beta}] = \symbf \beta\) pentru orice \(\symbf \beta\), conduce la \(\mathbb{E}[\symbf A\symbf Y] = \symbf A\symbf X\symbf \beta = \symbf \beta\) pentru orice \(\symbf \beta\) de unde \(\symbf A\symbf X = I_{p+1}\).
În final avem
\[ \begin{aligned} Cov(\tilde{\symbf \beta} - \hat{\symbf \beta}, \hat{\symbf \beta}) &= Cov(\tilde{\symbf \beta}, \hat{\symbf \beta}) - Var(\hat{\symbf \beta}) = Cov\left(\symbf A\symbf Y, (\symbf X^\intercal \symbf X)^{-1} \symbf X^\intercal \symbf Y\right) - Var(\hat{\symbf \beta})\\ &= \symbf A Cov\left(\symbf Y, \symbf Y\right) \left((\symbf X^\intercal \symbf X)^{-1} \symbf X^\intercal\right)^\intercal - Var(\hat{\symbf \beta}) \\ &= \symbf A \underbrace{Var\left(\symbf Y\right)}_{=\sigma^2 I_n}\symbf X (\symbf X^\intercal \symbf X)^{-1} - \underbrace{Var(\hat{\symbf \beta})}_{=\sigma^2 (\symbf X^\intercal \symbf X)^{-1}}\\ &= \sigma^2\underbrace{\symbf A \symbf X}_{= I_{p+1}} (\symbf X^\intercal \symbf X)^{-1} - \sigma^2 (\symbf X^\intercal \symbf X)^{-1} = 0. \end{aligned} \]
Trebuie remarcat că teorema Gauss-Markov poate fi extinsă la o combinație liniară \(b_0\beta_0+\cdots+b_{p}\beta_p = \symbf b^\intercal\symbf\beta\) a lui \(\symbf\beta\), mai precis putem afirma că cel mai bun estimator liniar, nedeplasat și de varianță minimală pentru \(\symbf b^\intercal\symbf\beta\) este \(\symbf b^\intercal\hat{\symbf\beta}\) unde \(\hat{\symbf\beta}\) este estimatorul obținut prin metode celor mai mici pătrate.
O altă proprietate interesantă a lui \(\hat{\symbf\beta}\) este că valorile ajustate \(\hat{\symbf Y} = \symbf X\hat{\symbf\beta}\) (media (condiționată) a lui \(\symbf Y\), \(\widehat{\mathbb{E}[\symbf Y]}\)) sunt invariante la simple schimbări liniare de scală a covariabilelor. Cu alte cuvinte, se poate arăta că dacă \(\symbf Z_j = c_j \symbf X_j\), \(j = 1,2,\ldots, p\) și \(c_j\) sunt coeficienți constanți, atunci \(\hat{\symbf Y} = \symbf X\hat{\symbf\beta} = \symbf Z\hat{\symbf\beta}_Z\) unde \(\hat{\symbf\beta}_Z\) este estimatorul obținut prin metoda celor mai mici pătrate în modelul de regresie \(\symbf Y = \symbf Z\symbf\beta_Z + \symbf\varepsilon\). Acest rezultat poate fi extins la o clasă mai largă de transformări liniare (Rencher and Schaalje 2008).
1.3 Reziduuri și varianța reziduală
Am văzut (în metoda geometrică de determinare a lui \(\symbf\beta\) din Propoziția 1.1 că plecând de la estimatorul obținut prin metoda celor mai mici pătrate pentru coeficienții modelului de regresie liniară, putem estima media (condiționată) a vectorului răspuns \(\symbf Y\) prin
\[ \widehat{\mathbb{E}[\symbf Y]} = \hat{\symbf{Y}} = \symbf X\hat{\symbf{\beta}} \]
ceea ce conduce la \(\hat{\symbf{Y}} = \symbf X\hat{\symbf{\beta}} = \underbrace{\symbf X\left(\symbf X^\intercal\symbf X\right)^{-1}\symbf X^\intercal}_{P_X \,(\text{sau }H)}\symbf Y\). Prin intermediul matricii de proiecție \(P_X\) putem exprima vectorul valorilor reziduale \(\varepsilon_i = y_i - \hat{y}_i\) prin
\[ \symbf\varepsilon = \symbf Y - \hat{\symbf Y} = (I - P_X)\symbf Y. \]
Vectorul valorilor reziduale verifică următoarele proprietăți:
Propoziția 1.4 (Proprietăți ale valorilor reziduale) Fie \(\hat{\symbf \varepsilon} = \symbf Y - \hat{\symbf Y}\) vectorul valorilor reziduale. Atunci sub ipotezele \(\mathcal{H}_1\) și \(\mathcal{H}_2\) au loc relațiile
- \(\mathbb{E}[\hat{\symbf \varepsilon}] = 0\) și \(Var(\hat{\symbf \varepsilon}) = \sigma^2 P_{X^\perp}\)
- \(\mathbb{E}[\hat{\symbf Y}] = \symbf X \symbf\beta\) și \(Var(\hat{\symbf Y}) = \sigma^2 P_{X}\)
- \(Cov(\hat{\symbf \varepsilon}, \hat{\symbf Y}) = 0\)
Demonstrație (Propoziția 1.4). Avem
- Am văzut că \(\hat{\symbf Y} = P_X\symbf Y\) prin urmare ținând cont de modelul de regresie \(\symbf Y = \symbf X\symbf \beta + \symbf \varepsilon\) găsim că
\[ \hat{\symbf \varepsilon} = (\hat{\varepsilon}_1,\ldots, \hat{\varepsilon}_n)^\intercal = \symbf Y - \hat{\symbf Y} = (I - P_X)\symbf Y = P_{X^\perp}\symbf Y = P_{X^\perp}(\symbf X\symbf\beta + \symbf\varepsilon) = P_{X^\perp} \symbf\varepsilon \]
deoarece \(\symbf X\symbf\beta\in\mathcal{M}(X)\), deci \(P_{X^\perp}\symbf X\symbf\beta = 0\). Astfel \(\hat{\symbf \varepsilon}\in\mathcal{M}(X)^\perp\) și
\[ \mathbb{E}[\hat{\symbf \varepsilon}] = \mathbb{E}[P_{X^\perp} \symbf\varepsilon] = P_{X^\perp} \mathbb{E}[\symbf\varepsilon] = 0 \]
iar, ținând seama de proprietatea de simetrie \(P_{X^\perp}^\intercal = P_{X^\perp}\) și idempotență \(P_{X^\perp}^2 = P_{X^\perp}\) a matricii de proiecție,
\[ Var(\hat{\symbf \varepsilon}) = Var(P_{X^\perp} \symbf\varepsilon) = P_{X^\perp} Var(\symbf\varepsilon) P_{X^\perp}^\intercal = P_{X^\perp} \underbrace{Var(\symbf\varepsilon)}_{=\sigma^2 I_n} P_{X^\perp} = \sigma^2 P_{X^\perp}^2 = \sigma^2 P_{X^\perp}. \]
- Din nedeplasarea lui \(\hat{\symbf\beta}\) și definiția lui \(\hat{\symbf Y} = \symbf X\hat{\symbf \beta}\) avem
\[ \mathbb{E}[\hat{\symbf Y}] = \mathbb{E}[\symbf X\hat{\symbf \beta}] = \symbf X\mathbb{E}[\hat{\symbf \beta}] = \symbf X\symbf \beta. \]
În mod similar
\[ Var(\hat{\symbf Y}) = Var(\symbf X\hat{\symbf \beta}) = \symbf X \underbrace{Var(\hat{\symbf \beta})}_{=\sigma^2 (\symbf X^\intercal \symbf X)^{-1}}\symbf X^\intercal = \sigma^2\underbrace{\symbf X(\symbf X^\intercal \symbf X)^{-1}\symbf X^\intercal}_{=P_X} = \sigma^2 P_X. \]
- Pentru a calcula \(Cov(\hat{\symbf \varepsilon}, \hat{\symbf Y})\) folosim \(Var(\hat{\symbf \varepsilon}) = \sigma^2 P_{X^\perp}\) și \(Var(\symbf Y) = Var(\symbf \varepsilon) = \sigma^2 I_n\) și avem
\[ \begin{aligned} Cov(\hat{\symbf \varepsilon}, \hat{\symbf Y}) &= Cov(\hat{\symbf \varepsilon}, \symbf Y - \hat{\symbf \varepsilon}) = Cov(\hat{\symbf \varepsilon}, \symbf Y) - Var(\hat{\symbf \varepsilon}) = Cov(P_{X^\perp} \symbf Y, \symbf Y) - \sigma^2 P_{X^\perp} \\ &= P_{X^\perp}Var(\symbf Y) - \sigma^2 P_{X^\perp} = \sigma^2 P_{X^\perp} - \sigma^2 P_{X^\perp} = 0. \end{aligned} \]
Ținând cont de faptul că matricea de design \(\symbf X\) are coloanele ortogonale pe vectorul valorilor reziduale \(\hat{\symbf\varepsilon}\),
\[ \symbf X^\intercal\hat{\symbf \varepsilon} = \symbf X^\intercal\left(I - P_X\right)\symbf Y = \symbf X^\intercal\symbf Y - \symbf X^\intercal\underbrace{\symbf X\left(\symbf X^\intercal\symbf X\right)^{-1}\symbf X^\intercal}_{P_X}\symbf Y = \symbf X^\intercal\symbf Y - \symbf X^\intercal\symbf Y = \symbf 0, \]
apar o serie de proprietăți interesante. Ca și în cazul modelului de regresie liniară simplă, se poate verifica cu ușurință că suma valorilor reziduale este nulă
\[ \sum_{i = 1}^{n}\hat{\varepsilon}_i = \symbf 1^\intercal \hat{\symbf\varepsilon} = 0, \]
unde în ultima egalitate am ținut cont că \(\symbf 1\in\mathcal{M}(X)\) iar \(\hat{\symbf\varepsilon}\in\mathcal{M}(X)^\perp\), ceea ce implică la rândul ei că media eșantionului valorilor ajustate este egală cu media eșantionului răspunsului observat, \(\frac{1}{n}\sum_{i = 1}^{n}\hat{y}_i = \bar{y}\). Aceasta din urmă observație conduce la rezultatul similar regresiei liniare simple, și anume că hiperplanul de regresie trece prin mijlocul norului de puncte, i.e. punctul \((\bar{x}_1,\ldots,\bar{x}_p,\bar{y})\), mai exact avem (prin sumare)
\[ \bar{y} = \hat{\beta}_0 + \hat{\beta}_1\bar{x}_1 + \cdots + \hat{\beta}_p\bar{x}_p. \]
Următorul exemplu arată cum putem crea o matrice de design ortogonal, procedeul fiind cunoscut sub numele de procedeul Gram-Schmidt:
Exemplul 1.3 (Ortogonalizarea matricei de design) O matrice de design ortogonală implică, pe lângă alte proprietăți, că variabilele explicative sunt necorelate prin urmare ortogonalizarea matricii de design se dovedește foarte utilă, de exemplu atunci când construim polinoame ortogonale (a se vedea Exemplul 1.4 din Cursul 5).
Fie \(\symbf X\) matricea de design și \(\symbf X_j\) coloana \(j\) a acesteia. Scopul este de a crea o nouă matrice \(\tilde{\symbf X}\) ale cărei coloane \(\tilde{\symbf X}_j\) sunt ortogonale. Astfel pentru fiecare \(j = 2, \ldots, p+1\) considerăm transformarea
\[ \tilde{\symbf X}_j = \symbf X_j - \tilde{\symbf Z}_j\left(\tilde{\symbf Z}_j^\intercal\tilde{\symbf Z}_j\right)^{-1}\tilde{\symbf Z}_j^\intercal\symbf X_j, \]
unde \(\tilde{\symbf Z}_j\) este matricea care conține primele \(j-1\) coloane transformate \(\tilde{\symbf X}_1,\ldots, \tilde{\symbf X}_{j-1}\), \(\tilde{\symbf Z}_j = \symbf 1\). Prima coloană a matricii de design \(\symbf X\) rămâne netransformată prin urmare \(\tilde{\symbf X}_2\) nu este altceva decât \(\symbf X_2\) centrat. Putem observa că vectorul coloană transformat \(\tilde{\symbf X}_j\) poate fi interpretat ca vectorul valorilor reziduale din modelul de regresie care consideră ca variabilă răspuns pe \(\symbf X_j\) și ca variabile predictor pe \(\symbf 1, \tilde{\symbf X}_1, \ldots, \tilde{\symbf X}_{j-1}\). Datorită ortogonalității dintre valorile reziduale și coloanele matricii de design, găsim că \(\tilde{\symbf X}_j\) este ortogonal pe \(\tilde{\symbf X}_i\), \(i = 1,\ldots, j-1\).
Rezultatul următoarei propoziții ne spune că în cazul în care variabilele explicative sunt ortogonale, a efectua o regresie multiplă revine la a efectua \(p\) regresii simple.
Propoziția 1.5 (Ortogonalizarea covariabilelor) Considerăm modelul de regresie liniară
\[ \symbf Y = \symbf X\symbf \beta + \symbf\varepsilon \]
unde \(\symbf Y\in\mathbb{R}^n\), \(\symbf X \in\mathcal{M}_{n, p}(\mathbb{R})\) este o matrice compusă din \(p\) vectori ortogonali, \(\symbf \beta\in\mathbb{R}^{p}\) iar \(\symbf \varepsilon\in\mathbb{R}^n\). Fie \(\symbf Z\) matricea formată din primele \(q\) coloane ale lui \(\symbf X\) și \(\symbf U\) matricea formată din ultimele \(p-q\) coloane ale lui \(\symbf X\). Prin metoda celor mai mici pătrate obținem
\[ \begin{aligned} \hat{\symbf Y}_X &= \hat{\beta}_1^X \symbf X_1 + \cdots + \hat{\beta}_p^X \symbf X_p\\ \hat{\symbf Y}_Z &= \hat{\beta}_1^Z \symbf X_1 + \cdots + \hat{\beta}_q^Z \symbf X_q\\ \hat{\symbf Y}_U &= \hat{\beta}_{q+1}^U \symbf X_{q+1} + \cdots + \hat{\beta}_p^U \symbf X_p \end{aligned} \]
- Atunci \(\lVert P_X\symbf Y\rVert^2 = \lVert P_Z\symbf Y\rVert^2 + \lVert P_U\symbf Y\rVert^2\).
- Pentru \(i\in\{1,2,\ldots,p\}\) dat, avem că \(\hat{\beta}_i^X = \hat{\beta}_i^Z\) dacă \(i\leq q\) și \(\hat{\beta}_i^X = \hat{\beta}_i^U\) altfel.
Demonstrație (Propoziția 1.5). Avem
- Cum \(P_Z + P_{Z^\perp} = I\) putem scrie
\[ \hat{\symbf Y}_X = P_X\symbf Y = (P_Z + P_{Z^\perp})P_X\symbf Y = P_ZP_X\symbf Y + P_{Z^\perp}P_X\symbf Y, \]
și din \(P_ZP_X = P_{Z\cap X} = P_Z\) găsim că \(\hat{\symbf Y}_X = P_Z\symbf Y + P_{Z^\perp}P_X\symbf Y\). De asemenea, să notăm că \(P_{Z^\perp}P_X = P_{Z^\perp\cap X}\) și ținând cont de faptul că matricea \(\symbf X\) are coloanele ortogonale avem \(P_{Z^\perp\cap X} = P_U\) (în fapt ortogonalitatea coloanelor lui \(\symbf X\) implică \(\mathcal{M}(X) = \mathcal{M}(Z)\overset{\perp}{\oplus}\mathcal{M}(U)\), sumă directă de spații ortogonale). Prin urmare obținem descompunerea ortogonală
\[ \hat{\symbf Y}_X = P_Z\symbf Y + P_U\symbf Y = \hat{\symbf Y}_Z + \hat{\symbf Y}_U \]
și din Teorema lui Pitagora avem
\[ \lVert P_X\symbf Y\rVert^2 = \lVert P_Z\symbf Y\rVert^2 + \lVert P_U\symbf Y\rVert^2. \]
- Vom arăta relația pentru \(i\leq q\), cazul general fiind analog. Din formula generală avem că \(\hat{\symbf\beta}^X\) este
\[ \hat{\symbf\beta}^X = \left(\symbf X^\intercal \symbf X\right)^{-1}\symbf X^\intercal\symbf Y \]
și cum coloanele lui \(\symbf X\) sunt ortogonale deducem că matricea \(\symbf X^\intercal\symbf X\) este o matrice diagonală, \(\symbf X^\intercal\symbf X = \mathrm{diag}\left(\lVert\symbf X_1\rVert^2, \ldots, \lVert\symbf X_p\rVert^2\right)\). Notând de asemenea că \(\symbf X^\intercal\symbf Y\) este un vector coloană cu elemente de tipul \(\langle\symbf X_i, \symbf Y\rangle\), deducem că
\[ \hat{\symbf\beta}^X = \begin{pmatrix}\frac{\langle\symbf X_1, \symbf Y\rangle}{\lVert\symbf X_1\rVert^2} & \cdots & \frac{\langle\symbf X_p, \symbf Y\rangle}{\lVert\symbf X_p\rVert^2}\end{pmatrix}^\intercal, \]
prin urmare \(\hat{\symbf\beta}_i^X = \frac{\langle\symbf X_i, \symbf Y\rangle}{\lVert\symbf X_i\rVert^2}\). Pentru \(i\leq q\), coloana \(i\) a matricei \(\symbf Z\) este \(\symbf Z_i = \symbf X_i\) și aplicând raționamentul anterior găsim că
\[ \hat{\symbf\beta}_i^Z = \frac{\langle\symbf Z_i, \symbf Y\rangle}{\lVert\symbf Z_i\rVert^2} = \frac{\langle\symbf X_i, \symbf Y\rangle}{\lVert\symbf X_i\rVert^2} = \hat{\symbf\beta}_i^X. \]
Ca și în cazul modelului de regresie liniară simplă, un estimator natural al varianței reziduale \(\sigma^2\) ar fi
\[ \frac{1}{n}\sum_{i = 1}^{n}(y_i - \hat{y}_i)^2 = \frac{1}{n}\sum_{i = 1}^{n}\hat{\varepsilon}_i^2 = \frac{\hat{\symbf\varepsilon}^\intercal \hat{\symbf\varepsilon}}{n} = \frac{1}{n}\lVert\hat{\symbf \varepsilon}\rVert^2, \]
care se dovedește a coincide cu estimatorul de verosimilitate maximă (a se vedea Propoziția 1.1 din Cursul 8). Chiar dacă acest estimator este deplasat putem determina cu ușurință unul nedeplasat după cum arată și rezultatul următor.
Propoziția 1.6 (Estimator nedeplasat pentru \(\hat{\sigma}^2\)) Statistica \(\hat{\sigma}^2 = \frac{\lVert\hat{\symbf \varepsilon}\rVert^2}{n-(p+1)}\) este un estimator nedeplasat pentru \(\sigma^2\).
Demonstrație (Propoziția 1.6). Ca să arătăm că \(\hat{\sigma}^2 = \frac{\lVert\hat{\symbf \varepsilon}\rVert^2}{n-(p+1)}\) este un estimator nedeplasat pentru \(\sigma^2\) trebuie să calculăm \(\mathbb{E}\left[\lVert\hat{\symbf \varepsilon}\rVert^2\right]\). Cum \(\lVert\hat{\symbf \varepsilon}\rVert^2\) este un scalar atunci \(\lVert\hat{\symbf \varepsilon}\rVert^2 = \mathrm{Tr}(\lVert\hat{\symbf \varepsilon}\rVert^2)\) (este egal cu urma sa) prin urmare
\[ \mathbb{E}\left[\lVert\hat{\symbf \varepsilon}\rVert^2\right] = \mathbb{E}\left[\mathrm{Tr}\left(\lVert\hat{\symbf \varepsilon}\rVert^2\right)\right] = \mathbb{E}\left[\mathrm{Tr}\left(\hat{\symbf \varepsilon}^\intercal \hat{\symbf \varepsilon}\right)\right] \]
și cum pentru orice matrice \(\symbf A\) urma verifică \(\mathrm{Tr}(\symbf A^\intercal \symbf A) = \mathrm{Tr}(\symbf A\symbf A^\intercal) = \sum_{i,j}a_{ij}^2\) avem (\(\mathbb{E}\left[\hat{\symbf \varepsilon}\right] = 0\))
\[\begin{align*} \mathbb{E}\left[\lVert\hat{\symbf \varepsilon}\rVert^2\right] &= \mathbb{E}\left[\mathrm{Tr}\left(\hat{\symbf \varepsilon}^\intercal \hat{\symbf \varepsilon}\right)\right] = \mathbb{E}\left[\mathrm{Tr}\left(\hat{\symbf \varepsilon} \hat{\symbf \varepsilon}^\intercal\right)\right] = \mathrm{Tr}\left(\mathbb{E}\left[\hat{\symbf \varepsilon} \hat{\symbf \varepsilon}^\intercal\right]\right) = \mathrm{Tr}\left(\mathbb{E}\left[\hat{\symbf \varepsilon} \hat{\symbf \varepsilon}^\intercal\right] - \mathbb{E}\left[\hat{\symbf \varepsilon}\right]\mathbb{E}\left[\hat{\symbf \varepsilon}\right]^\intercal\right) \\ &= \mathrm{Tr}\left(Var(\hat{\symbf \varepsilon})\right) = \mathrm{Tr}\left(\sigma^2 P_{X^\perp}\right) = \sigma^2 \mathrm{Tr}\left( P_{X^\perp}\right). \end{align*}\]
Cum \(P_{X^\perp} = I - P_{X}\) este matrice de proiecție avem că \(\mathrm{Tr}\left( P_{X^\perp}\right) = \textrm{rang}\left( P_{X^\perp}\right) = n - (p+1)\) (urma matricii de proiecție este egală cu dimensiunea spațiului pe care proiectăm) prin urmare
\[ \mathbb{E}\left[\lVert\hat{\symbf \varepsilon}\rVert^2\right] = \sigma^2 \left[n - (p+1)\right] \]
de unde \(\mathbb{E}\left[\hat{\sigma}^2\right] = \mathbb{E}\left[\frac{\lVert\hat{\symbf \varepsilon}\rVert^2}{n-(p+1)}\right] = \sigma^2\).
Trebuie menționat că estimatorul nedeplasat \(\hat{\sigma}^2\) pentru \(\sigma^2\) coincide, în cazul modelului (condiționat) normal (a se vedea secțiunea Modelul (condiționat) normal), cu estimatorul de verosimilitate maximă restrâns (REML - restricted maximum likelihood estimator) care este definit ca
\[ \underset{\sigma^2}{\arg\max}{\,L(\sigma^2;\symbf Y)}, \]
unde \(L(\sigma^2;\symbf Y)=\int L(\symbf\beta, \sigma^2;\symbf Y)\,d\symbf\beta\). În general acest estimator este mai puțin deplasat față de estimatorul de verosimilitate maximă și prin urmare este de preferat în practică.
Folosind estimatorul \(\hat{\sigma}^2\) pentru \(\sigma^2\) putem construi un estimator \(\hat{\sigma}_{\hat{\symbf\beta}}^2\) pentru varianța \(Var(\hat{\symbf\beta}) = \sigma^2 (\symbf X^\intercal \symbf X)^{-1}\):
\[ \hat{\sigma}_{\hat{\symbf\beta}}^2 = \hat{\sigma}^2(\symbf X^\intercal \symbf X)^{-1} = \frac{\lVert\hat{\symbf \varepsilon}\rVert^2}{n-(p+1)}(\symbf X^\intercal \symbf X)^{-1}. \]
În particular, un estimator pentru abaterea standard a estimatorului coeficientului \(\beta_j\), \(\hat{\beta}_j\), este dat de elementul \(j+1\) de pe diagonala matricii \((\symbf X^\intercal \symbf X)^{-1}\):
\[ \hat{\sigma}_{\hat{\beta}_j} = \hat{\sigma}\sqrt{\left[(\symbf X^\intercal \symbf X)^{-1}\right]_{j+1,j+1}},\quad j = 0,1,\ldots,p. \]
În exemplul următor vom ilustra numeric aceste rezultate:
Exemplul 1.4 (Prețul chiriilor în Munchen) Să considerăm modelul propus în Exemplul din Cursul 5 prin care exprimăm prețul mediu al chiriei pe metrul pătrat pentru locuințele din orașul Munchen în funcție de efectul invers proporțional dat de suprafața de locuit și de anul de construcție a apartamentului:
\[ pret{\_m^2}_i = \beta_0 + \beta_1\times \frac{1}{suprafata_i} + \beta_2\times an{\_con}_{i} + \varepsilon_i. \]
Matricea de design este
\[ \symbf X = \begin{pmatrix}1 & \frac{1}{suprafata_1} & an{\_con}_1\\ 1 & \frac{1}{suprafata_2} & an{\_con}_2 \\ \vdots & \vdots & \vdots\\ 1 & \frac{1}{suprafata_{3082}} & an{\_con}_{3082}\end{pmatrix} = \begin{pmatrix}1 & 0.029 & 1939\\1 & 0.01 & 1939\\ \vdots & \vdots & \vdots\\ 1 & 0.016 & 1953\end{pmatrix} \]
iar estimatorul coeficienților de regresie obținut prin metoda celor mai mici pătrate este
\[ \hat{\symbf \beta} = (\symbf{X}^\intercal \symbf X)^{-1}\symbf{X}^\intercal \symbf Y = \begin{pmatrix}-65.406 \\ 119.361 \\ 0.036\end{pmatrix}. \]
Varianța reziduală estimată \(\hat{\sigma}^2\) este \(\hat{\sigma}^2 = \frac{\lVert\hat{\symbf \varepsilon}\rVert^2}{n-(p+1)} = 4.3993026\) iar estimatorul matricei de varianță-covarianță \(Var(\hat{\symbf\beta}) = \sigma^2(\symbf X^\intercal \symbf X)^{-1}\) devine
\[ \hat{\sigma}_{\hat{\symbf\beta}}^2 = \hat{\sigma}^2(\symbf X^\intercal \symbf X)^{-1} = \begin{pmatrix}11.23 & 2.808 & -0.006\\ 2.808 & 31.767 & -0.002 \\ -0.006 & -0.002 & 0\end{pmatrix}. \]
Astfel găsim că estimatorii pentru abaterile standard ale coeficienților de regresie sunt \(\hat{\sigma}_{\hat{\beta}_0} = 3.3511\), \(\hat{\sigma}_{\hat{\beta}_1} = 5.6362\) și respectiv \(\hat{\sigma}_{\hat{\beta}_2} = 0.0017\).
Arată codul R din exemplul de mai sus
# Model 1
munich <- read.table("dataIn/Munchen.raw", header = TRUE)
munich_sub <- munich %>% filter(yearc > 1966, location == 1)
# model rentsqm = beta_0 + beta_1*(1/area) + beta_2*yearc + epsilon
munich_ma_mod1 <- lm(rentsqm ~ I(1/area) + yearc,
data = munich)
coef_munich_ma_mod1 <- round(coef(munich_ma_mod1), 3)
n_ma_mod1 <- length(munich$rentsqm)
# alternative
ma_mod1_X <- model.matrix(munich_ma_mod1)
munich_ma_mod1_X <- round(ma_mod1_X, 3)
ma_mod1_XtXi <- solve(t(ma_mod1_X) %*% ma_mod1_X)
ma_mod1_beta <- solve(crossprod(ma_mod1_X, ma_mod1_X), crossprod(ma_mod1_X, munich$rentsqm))
# sigma
W_ma_mod1 <- round(vcov(munich_ma_mod1), 3)
sum_ma_mod1 <- summary(munich_ma_mod1)
sigma_ma_mod1 <- sum_ma_mod1$sigma
sigma_coef_ma_mod1 <- round(sum_ma_mod1$coef[,2], 4)1.4 Predicție
Unul dintre scopurile aplicării unui model de regresie este acela de a prezice valoarea variabilei răspuns atunci când avem de-a face cu un set nou de valori pentru variabilele explicative considerate în model. Să presupunem că \((x_{n+1,1}, \ldots, x_{n+1,p})\) sunt valori ale variabilelor explicative ce corespund unei noi observații și dorim să prezicem \(y_{n+1}\) conform modelului de regresie liniară
\[ y_{n+1} = \beta_0 + \beta_1 x_{n+1,1} + \cdots + \beta_p x_{n+1,p} + \varepsilon_{n+1} \]
pentru care \(\mathbb{E}[\varepsilon_{n+1}] = 0\), \(Var(\varepsilon_{n+1}) = \sigma^2\) și \(Cov(\varepsilon_{n+1}, \varepsilon_i)=0\) pentru \(i = 1,\ldots,n\). Metoda naturală, este de a prezice valoarea corespunzătoare prin intermediul valorii ajustate \(\hat{y}_{n+1} = \symbf x_{n+1}^\intercal\hat{\symbf \beta}\) unde \(\symbf x_{n+1}^\intercal = (1, x_{n+1,1}, \ldots, x_{n+1,p})\) și în acest caz eroarea de predicție este \(\hat{\varepsilon}_{n+1} = y_{n+1} - \hat{y}_{n+1}\).
Trebuie remarcat că atunci când vorbim de predicție putem să ne referim sau la predicție asupra răspunsului mediu sau la predicție asupra unei noi valori. În prima situație ne referim la valoarea ajustată \(x_{n+1}^\intercal\hat{\symbf \beta}\) în care doar varianța lui \(\hat{\symbf\beta}\) este luată în calcul atunci când vorbim de variabilitatea predicției. Plasându-ne în contextul setului de date referitor la prețul chiriilor din orașul Munchen, acest caz revine la a răspunde la întrebarea: Cu cât se va închiria, în medie, un apartament al cărui caracteristici sunt \((x_{n+1,1}, \ldots, x_{n+1,p})\) (suprafață, an de construcție, etc.)? A doua situație se referă la prețul de închiriere \(x_{n+1}^\intercal\symbf \beta + \varepsilon_{n+1}\) al unui nou apartament cu particularitățile \((x_{n+1,1}, \ldots, x_{n+1,p})\). În acest caz, variabilitatea predicției vine din două surse: varianța lui \(\hat{\symbf \beta}\) și respectiv a termenului eroare \(\varepsilon_{n+1}\).
Rezultatul următor descrie varianța erorii de predicție.
Propoziția 1.7 (Proprietățile erorii de predicție) Fie \((x_{n+1,1}, \ldots, x_{n+1,p})\) o nouă observație și considerăm \(\symbf x_{n+1}^\intercal = (1, x_{n+1,1}, \ldots, x_{n+1,p})\). Ne propunem să prezicem valoarea \(y_{n+1}\) conform modelului
\[ y_{n+1} = \symbf x_{n+1}^\intercal\symbf \beta + \varepsilon_{n+1} \]
cu \(\mathbb{E}[\varepsilon_{n+1}] = 0\), \(Var(\varepsilon_{n+1}) = \sigma^2\) și \(Cov(\varepsilon_{n+1}, \varepsilon_i)=0\) pentru \(i = 1,\ldots,n\).
Atunci eroarea de predicție \(\hat{\varepsilon}_{n+1} = y_{n+1} - \hat{y}_{n+1}\) verifică proprietățile
- \(\mathbb{E}[\hat{\varepsilon}_{n+1}] = 0\)
- \(Var(\hat{\varepsilon}_{n+1}) = \sigma^2\left(1 + \symbf x_{n+1}^\intercal(\symbf X^\intercal \symbf X)^{-1}\symbf x_{n+1}\right)\)
Demonstrație (Propoziția 1.7). Avem
- Cum \(\mathbb{E}[\varepsilon_{n+1}] = 0\) și ținând cont de nedeplasarea estimatorului \(\hat{\symbf \beta}\) avem
\[ \mathbb{E}[\hat{\varepsilon}_{n+1}] = \mathbb{E}[ y_{n+1} - \hat{y}_{n+1}] = \mathbb{E}\left[\underbrace{\symbf x_{n+1}^\intercal \symbf \beta + \varepsilon_{n+1}}_{y_{n+1}} - \underbrace{\symbf x_{n+1}^\intercal\hat{\symbf \beta}}_{\hat{y}_{n+1}}\right] \]
de unde \(\mathbb{E}[\hat{\varepsilon}_{n+1}] = \symbf x_{n+1}^\intercal\left(\symbf \beta - \mathbb{E}[\hat{\symbf \beta}]\right) + \mathbb{E}[\varepsilon_{n+1}] = 0\).
Cum \(\hat{\symbf \beta}\) depinde doar de variabilele \(\{\varepsilon_1,\ldots,\varepsilon_n\}\) iar \(Cov(\varepsilon_{n+1}, \varepsilon_i)=0\) pentru \(i = 1,\ldots,n\) deducem că
\[ \begin{aligned} Var(\hat{\varepsilon}_{n+1}) &= Var\left(y_{n+1} - \hat{y}_{n+1}\right) = Var\left(\symbf x_{n+1}^\intercal\left(\symbf \beta - \hat{\symbf \beta}\right) + \varepsilon_{n+1}\right) \\ &= Var\left(\symbf x_{n+1}^\intercal\left(\symbf \beta - \hat{\symbf \beta}\right)\right) + Var(\varepsilon_{n+1}) = \symbf x_{n+1}^\intercal Var(\symbf \beta - \hat{\symbf \beta}) \symbf x_{n+1} + \sigma^2\\ &= \symbf x_{n+1}^\intercal Var(\hat{\symbf \beta}) \symbf x_{n+1} + \sigma^2 = \symbf x_{n+1}^\intercal \sigma^2(\symbf X^\intercal \symbf X)^{-1} \symbf x_{n+1} + \sigma^2\\ &= \sigma^2\left(1 + \symbf x_{n+1}^\intercal(\symbf X^\intercal \symbf X)^{-1}\symbf x_{n+1}\right). \end{aligned} \]
Observăm astfel că incertitudinea erorii de predicție este egală cu suma incertitudinii datorate lui \(\symbf \beta\), \(\sigma^2(\symbf X^\intercal \symbf X)^{-1}\), și cea datorate lui \(\varepsilon_{n+1}\), \(\sigma^2\).
Rezultatul următor generalizează rezultatul similar din cadrul modelului de regresie liniară simplă.
Propoziția 1.8 (Varianța erorii de predicție) Fie modelul de regresie \(\symbf Y = \symbf X\symbf \beta + \symbf \varepsilon\) unde matricea de design se scrie
\[ \symbf {X}=\begin{pmatrix} 1 & x_{11} & \cdots & x_{1p}\\ \vdots & \vdots & \ddots & \vdots\\ 1 & x_{n1} & \cdots & x_{np} \end{pmatrix}_{n\times(p+1)} = \left[\underbrace{\symbf X_0}_{\mathbf{1} = (1,\cdots,1)}|\symbf X_1|\cdots|\symbf X_p\right] = \left[\mathbf{1}|\symbf Z\right] \]
cu \(\symbf Z\) matricea de dimensiune \(n\times p\) formată din coloanele \(\{\symbf X_1,\ldots,\symbf X_p\}\). În contextul propoziției precedente, fie \(\symbf z_{n+1}^\intercal = (x_{n+1,1}, \ldots, x_{n+1,p})\) o nouă observație și considerăm \(\symbf x_{n+1}^\intercal = (1, \symbf z_{n+1}^\intercal)\). Atunci varianța erorii de predicție este
\[ Var(\hat{\varepsilon}_{n+1}) = \sigma^2\left[1 + \frac{1}{n} + \frac{1}{n}(\symbf z_{n+1} - \bar{\symbf x})^\intercal \symbf \Gamma^{-1}(\symbf z_{n+1} - \bar{\symbf x})\right] \]
unde \(\symbf \Gamma = \frac{1}{n}\symbf Z^\intercal \symbf Z - \bar{\symbf x}\bar{\symbf x}^\intercal\) este o matrice simetrică și pozitiv definită atunci când \(\symbf X^\intercal \symbf X\) este inversabilă iar \(\bar{\symbf x}^\intercal = (\bar{\symbf x}_1, \ldots, \bar{\symbf x}_p)\) cu \(\bar{\symbf x}_j = \frac{1}{n}\sum_{i = 1}^{n}x_{ij}\).
Demonstrație (Propoziția 1.8). Pentru început să observăm că matricea \(\symbf X^\intercal \symbf X\) se scrie sub forma
\[ \begin{aligned} \symbf X^\intercal \symbf X &= \begin{bmatrix}\mathbf{1}^\intercal \\ \symbf X_1^\intercal \\ \vdots \\ \symbf X_p^\intercal\end{bmatrix}\begin{bmatrix}\mathbf{1} & \symbf X_1 & \cdots &\symbf X_p\end{bmatrix} = \begin{pmatrix}\underbrace{\mathbf{1}^\intercal\mathbf{1}}_{=n} & \underbrace{\mathbf{1}^\intercal\symbf X_1}_{=n\bar{\symbf x}_1} & \cdots & \underbrace{\mathbf{1}^\intercal\symbf X_p}_{=n\bar{\symbf x}_p}\\ \symbf X_1^\intercal\mathbf{1} & \symbf X_1^\intercal\symbf X_1 & \cdots & \symbf X_1^\intercal \symbf X_p\\ \cdots & \cdots & \cdots & \cdots \\ \symbf X_p^\intercal\mathbf{1} & \symbf X_p^\intercal\symbf X_1 & \cdots & \symbf X_p^\intercal \symbf X_p\end{pmatrix} \\ &= \begin{pmatrix}n & n\bar{\symbf x}_1 & \cdots & n\bar{\symbf x}_p\\ n\bar{\symbf x}_1 & \symbf X_1^\intercal\symbf X_1 & \cdots & \symbf X_1^\intercal \symbf X_p\\ \cdots & \cdots & \cdots & \cdots\\ n\bar{\symbf x}_p & \symbf X_p^\intercal\symbf X_1 & \cdots & \symbf X_p^\intercal \symbf X_p\end{pmatrix} = \begin{pmatrix}n & n\bar{\symbf x}^\intercal\\ n\bar{\symbf x} & \symbf Z^\intercal \symbf Z\end{pmatrix} = n\begin{pmatrix}1 & \bar{\symbf x}^\intercal\\ \bar{\symbf x} & \frac{1}{n}\symbf Z^\intercal \symbf Z\end{pmatrix}. \end{aligned} \]
Reamintim, e.g. (Henderson and Searle 1981) sau (Rencher and Schaalje 2008, Capitolul 2), că dacă \(\symbf F\) este o matrice pătrată inversabilă care se scrie sub formă de bloc de patru submatrice
\[ \symbf F = \begin{pmatrix}\symbf A & \symbf B\\ \symbf C & \symbf D\end{pmatrix} \]
cu \(\symbf A\) inversabilă atunci matricea \(\symbf Q = \symbf D - \symbf C \symbf A^{-1}\symbf B\) este inversabilă iar inversa matricii \(\symbf F\) este
\[ \symbf F^{-1} = \begin{pmatrix}\symbf A^{-1} + \symbf A^{-1}\symbf B \symbf Q\symbf C\symbf A^{-1} & -\symbf A^{-1}\symbf B\symbf Q\\ -\symbf Q\symbf C\symbf A^{-1} & \symbf Q^{-1}\end{pmatrix}. \]
În cazul problemei noastre avem \(\symbf A = 1\), \(\symbf B = \bar{\symbf x}^\intercal\), \(\symbf C = \bar{\symbf x}\) și \(\symbf D = \frac{1}{n}\symbf Z^\intercal\symbf Z\) prin urmare
\[ \symbf Q = \symbf D - \symbf C \symbf A^{-1}\symbf B = \frac{1}{n}\symbf Z^\intercal\symbf Z - \bar{\symbf x}\bar{\symbf x}^\intercal = \symbf \Gamma \]
iar
\[ \left(\symbf X^\intercal \symbf X\right)^{-1} = \frac{1}{n}\begin{pmatrix}1 & \bar{\symbf x}^\intercal\\ \bar{\symbf x} & \frac{1}{n}\symbf Z^\intercal \symbf Z\end{pmatrix}^{-1} = \frac{1}{n}\begin{pmatrix}1 + \bar{\symbf x}^\intercal\symbf \Gamma^{-1}\bar{\symbf x} & -\bar{\symbf x}^\intercal\symbf \Gamma^{-1}\\ -\symbf \Gamma^{-1}\bar{\symbf x} & \symbf \Gamma^{-1}\end{pmatrix}. \]
Dat fiind \(\symbf x_{n+1}^\intercal = (1, \symbf z_{n+1}^\intercal)\) am văzut în Propoziția 1.7 că varianța erorii de predicție este dată de formula
\[ Var(\hat{\varepsilon}_{n+1}) = \sigma^2\left(1 + \symbf x_{n+1}^\intercal(\symbf X^\intercal \symbf X)^{-1}\symbf x_{n+1}\right). \]
Ținând cont de scrierea sub formă de blocuri a matricii \(\left(\symbf X^\intercal \symbf X\right)^{-1}\) găsim că
\[ \begin{aligned} \symbf x_{n+1}^\intercal(\symbf X^\intercal \symbf X)^{-1}\symbf x_{n+1} &= \begin{pmatrix}1 & \symbf z_{n+1}^\intercal\end{pmatrix} \frac{1}{n}\begin{pmatrix}1 + \bar{\symbf x}^\intercal\symbf \Gamma^{-1}\bar{\symbf x} & -\bar{\symbf x}^\intercal\symbf \Gamma^{-1}\\ -\symbf \Gamma^{-1}\bar{\symbf x} & \symbf \Gamma^{-1}\end{pmatrix} \begin{pmatrix}1\\ \symbf z_{n+1}\end{pmatrix} \\ &= \frac{1}{n}\left(1 + \bar{\symbf x}^\intercal\symbf\Gamma^{-1}\bar{\symbf x} - \symbf z_{n+1}^\intercal \symbf\Gamma^{-1}\bar{\symbf x} - \bar{\symbf x}^\intercal\symbf\Gamma^{-1}\symbf z_{n+1} + \symbf z_{n+1}^\intercal\symbf\Gamma^{-1}\symbf z_{n+1}\right). \end{aligned} \]
Notând cu \(\symbf Z_c\) matricea (centrată) cu coloanele \(\symbf X_j - \bar{\symbf x}_j\mathbf{1}\), \(j = 1,\ldots,p\) putem observa că
\[ \symbf \Gamma = \frac{1}{n}\symbf Z^\intercal\symbf Z - \bar{\symbf x}\bar{\symbf x}^\intercal = \frac{1}{n}\symbf Z_c^\intercal\symbf Z_c \]
prin urmare \(\symbf \Gamma = \symbf \Gamma^\intercal\), deci \(\symbf \Gamma\) este simetrică. Astfel, folosind faptul că un scalar este egal cu transpusul său, avem
\[ \symbf z_{n+1}^\intercal \symbf\Gamma^{-1}\bar{\symbf x} = \left(\symbf z_{n+1}^\intercal \symbf\Gamma^{-1}\bar{\symbf x}\right)^\intercal = \bar{\symbf x}^\intercal\symbf\Gamma^{-1}\symbf z_{n+1} \]
ceea ce conduce la
\[ \begin{aligned} \symbf x_{n+1}^\intercal(\symbf X^\intercal \symbf X)^{-1}\symbf x_{n+1} &= \frac{1}{n}\left(1 + \bar{\symbf x}^\intercal\symbf\Gamma^{-1}\bar{\symbf x} - 2\bar{\symbf x}^\intercal\symbf\Gamma^{-1}\symbf z_{n+1} + \symbf z_{n+1}^\intercal\symbf\Gamma^{-1}\symbf z_{n+1}\right) \\ &= \frac{1}{n}\left[1 + (\symbf z_{n+1} - \bar{\symbf x})^\intercal \symbf \Gamma^{-1}(\symbf z_{n+1} - \bar{\symbf x})\right] \end{aligned} \]
de unde găsim
\[ Var(\hat{\varepsilon}_{n+1}) = \sigma^2\left[1 + \frac{1}{n} + \frac{1}{n}(\symbf z_{n+1} - \bar{\symbf x})^\intercal \symbf \Gamma^{-1}(\symbf z_{n+1} - \bar{\symbf x})\right]. \]
Mai mult, să remarcăm că dacă \(\symbf X^\intercal \symbf X\) este inversabilă atunci matricea \(\symbf \Gamma\) este pozitiv definită. Într-adevăr am văzut că \(\symbf \Gamma = \frac{1}{n}\symbf Z_c^\intercal\symbf Z_c\) iar pentru \(\symbf u \in\mathbb{R}^p\) putem scrie
\[ \symbf u^\intercal \symbf \Gamma\symbf u = \frac{1}{n}\symbf u^\intercal \symbf Z_c^\intercal\symbf Z_c \symbf u = \frac{1}{n}\lVert\symbf Z_c \symbf u\rVert^2 \geq 0 \]
deci \(\symbf \Gamma\) este pozitiv semidefinită. Avem egalitate \(\frac{1}{n}\lVert\symbf Z_c \symbf u\rVert^2 = 0\) atunci când \(\symbf Z_c \symbf u = 0\) sau, altfel spus, atunci când
\[ u_1(\symbf X_1 - \bar{\symbf x}_1\mathbf{1}) + \cdots + u_p(\symbf X_p - \bar{\symbf x}_p\mathbf{1}) = 0 \iff \sum_{j=1}^{n}u_j\symbf X_j = \left(\sum_{j=1}^{n}u_j\bar{\symbf x}_j\right)\mathbf{1}. \]
Această ultimă relație ne spune că prima coloană a lui \(\symbf X\) se scrie ca o combinație liniară de celelalte, ceea ce înseamnă că \(\mathrm{rang}(\symbf X)\leq p\) de unde concluzionăm că matricea \(\symbf X^\intercal \symbf X\) nu este inversabilă.
Este interesant de remarcat cum din faptul că \(\symbf \Gamma\) este simetrică și pozitiv definită deducem că \((\symbf z_{n+1} - \bar{\symbf x})^\intercal \symbf \Gamma^{-1}(\symbf z_{n+1} - \bar{\symbf x})\geq 0\), cu egalitate dacă și numai dacă \(\symbf z_{n+1} = \bar{\symbf x}\), adică \(\symbf x_{n+1}^\intercal = (1, \symbf z_{n+1}^\intercal) = (1, \bar{\symbf x}^\intercal)\). În acest caz \(Var(\hat{\varepsilon}_{n+1}) = \sigma^2\left(1+\frac{1}{n}\right)\), rezultat care generalizează rezultatul corespunzător de la regresia liniară simplă: trebuie să ne plasăm în centrul norului de puncte ale variabilelor explicative pentru a prezice variabila răspuns cu mai multă precizie.
2 Exerciții
Exercițiul 2.1 (Regresie liniară simplă vs multiplă) Fie un eșantion de \(n\) perechi \(\left(x_{i}, y_{i}\right)_{1 \leq i \leq n}\) pentru modelul de regresie liniară simplă \(y= \beta_{0}+\beta_{1} x+\varepsilon\).
- Reamintiți formulele pentru \(\hat{\beta}_{0}\) și respectiv \(\hat{\beta}_{1}\).
- Reamintiți formula pentru \(\hat{\beta}=\left(\hat{\beta}_{1}, \hat{\beta}_{2}\right)^{\intercal}\).
- Găsiți răspunsul la întrebarea 1 pornind de la răspunsul la întrebarea 2 .
- Reamintiți formulele pentru varianțele și covarianțele lui \(\hat{\beta}_{1}\) și \(\hat{\beta}_{2}\).
- Reamintiți formula matricei de covarianță a lui \(\hat{\beta}\).
- Găsiți răspunsul la întrebarea 4 pornind de la răspunsul la întrebarea 5.
Exercițiul 2.2 (Rolul constantei) Fie \(X\) o matrice de dimensiuni \(n \times p\). Fie \(\hat{Y}\) proiecția ortogonală a unui vector \(Y\) din \(\mathbb{R}^{n}\) pe spațiul generat de coloanele lui \(X\). Notăm cu \(\mathbf{1}\) vectorul din \(\mathbb{R}^{n}\) compus numai din valoarea \(1\).
- Exprimați produsul scalar \(\langle Y, \mathbf{1}\rangle\) în funcție de \(y_{i}\).
- Fie \(\hat{\varepsilon}=Y-\hat{Y}\) și să presupunem că constanta face parte din model, adică prima coloană din \(X\) este \(\mathbf{1}\). Care este valoarea lui \(\langle\hat{\varepsilon}, \mathbb{1}\rangle\) ?
- Se deduce că, atunci când constanta face parte din model, \(\sum_{i=1}^{n} y_{i}=\sum_{i=1}^{n} \hat{y}_{i}\).
Exercițiul 2.3 (Scalarea variabilelor explicative) Dorim să explicăm variabila \(Y\) prin intermediul a \(p\) variabile explicative \(X_1, \cdots, X_p\). Estimatorul obținut prin metoda celor mai mici pătrate este \(\hat{\beta}\). Din diferite motive, fiecare variabilă este pre-înmulțită cu un scalar \(a_1, \cdots, a_p\). Cu aceste noi variabile, estimatorul obținut prin metoda celor mai mici pătrate devine \(\tilde{\beta}\).
Arătați că acest lucru este echivalent cu împărțirea fiecărei componente a lui \(\hat{\beta}\) la scalarul corespunzător \(a_i\).
Exercițiul 2.4 (Diferențe regresie simplă vs multiplă) Dorim să explicăm variabila \(Y\) prin două intermediul covariabilelor \(X\) și \(Z\). Dispunem de \(n\) observații ale acestor variabile.
- Având modelul \(y_i=\beta_1 x_i+\beta_2 z_i+\varepsilon_i\) dați forma explicită a lui \(\hat{\beta}_1\) și \(\hat{\beta}_2\).
- Considerăm acum următoarele două modele univariate \(y_i=\beta_1 x_i+\varepsilon_i\) și \(y_i=\beta_2 z_i+\varepsilon_i\). Dați forma explicită a estimatorilor.
- Care este concluzia?
- Considerăm analiza secvențială: estimăm parametrii modelului \(y_i=\beta_1 x_i+\varepsilon_i\), apoi explicăm reziduurile prin variabila \(Z\). Comparați estimatorii.
Exercițiul 2.5 (Diferențe regresie simplă vs multiplă II) Vom simula două variabile explicative \(X_1\) și \(X_2\) care urmează, de exemplu, o repartiție uniformă pe intervalul \([0,1]\), și apoi considerăm modelul de regresie liniară
\[ Y=2-3 X_1+4 X_2+\varepsilon, \]
unde \(\varepsilon\) urmează o repartiție normală de medie \(0\) și varianță \(0.25\).
Desenați norul de puncte folosind funcția
plot3ddin pachetulrgl.Ce observați?
Efectuați o regresie multiplă, estimați parametrii și păstrați \(\hat{Y}\).
Efectuați regresiile simple ale lui \(Y\) pe \(X_1\) și respectiv pe \(X_2\) și estimați parametrul asociat (este același?).
Efectuați acum două regresii secvențiale: regresați \(Y\) pe \(X_1\), păstrați reziduurile și efectuați o regresie simplă a reziduurilor pe \(X_2\). Comparați parametrii estimați și comparați \(\hat{Y}\) cu \(\hat{Y}\) de la întrebarea 3.
Schimbați ordinea din întrebarea precedentă: începeți prin a regresa \(Y\) pe \(X_2\), apoi reziduurile pe \(X_1\); comparați estimatorii și valorile \(\hat{Y}\).
Variabilele \(X_1\) și \(X_2\) erau slab corelate (folosiți
cov), dar nu erau ortogonale (da, trebuie centrate!). Reluați întregul exercițiu înlocuind \(X_1\) cu \(X_{1c}=X_1-\overline{X_1}\) și pe \(X_2\) cu \(X_{2c}=X_2-\overline{X_2}\). Ce concluzionați?
Exercițiul 2.6 (Regresie ortogonală) Considerăm modelul de regresie liniară
\[ \boldsymbol Y = \boldsymbol X\boldsymbol \beta + \boldsymbol\varepsilon \]
unde \(\boldsymbol Y\in\mathbb{R}^n\), \(\boldsymbol X \in\mathcal{M}_{n, p}(\mathbb{R})\) este o matrice compusă din \(p\) vectori ortogonali, \(\boldsymbol \beta\in\mathbb{R}^{p}\) iar \(\boldsymbol \varepsilon\in\mathbb{R}^n\). Fie \(\boldsymbol Z\) matricea formată din primele \(q\) coloane ale lui \(\boldsymbol X\) și \(\boldsymbol U\) matricea formată din ultimele \(p-q\) coloane ale lui \(\boldsymbol X\). Prin metoda celor mai mici pătrate obținem
\[ \begin{aligned} \hat{\boldsymbol Y}_X &= \hat{\beta}_1^X \boldsymbol X_1 + \cdots + \hat{\beta}_p^X \boldsymbol X_p\\ \hat{\boldsymbol Y}_Z &= \hat{\beta}_1^Z \boldsymbol X_1 + \cdots + \hat{\beta}_q^Z \boldsymbol X_q\\ \hat{\boldsymbol Y}_U &= \hat{\beta}_{q+1}^U \boldsymbol X_{q+1} + \cdots + \hat{\beta}_p^U \boldsymbol X_p \end{aligned} \]
- Atunci \(\lVert P_X\boldsymbol Y\rVert^2 = \lVert P_Z\boldsymbol Y\rVert^2 + \lVert P_U\boldsymbol Y\rVert^2\).
- Pentru \(i\in\{1,2,\ldots,p\}\) dat, avem că \(\hat{\beta}_i^X = \hat{\beta}_i^Z\) dacă \(i\leq q\) și \(\hat{\beta}_i^X = \hat{\beta}_i^U\) altfel.
Exercițiul 2.7 (Centrarea variabilelor explicative) Considerăm modelul de regresie liniară multiplă
\[ Y=X \beta+\varepsilon \]
unde \(Y \in \mathbb{R}^{n}\), \(X\) este o matrice de dimensiune \(n \times p\) de rang \(p\), \(\beta \in \mathbb{R}^{p}\) și \(\varepsilon \in \mathbb{R}^{n}\). Presupunem că prima coloană a lui \(X\) este vectorul constant \(\mathbb{1}\), prin urmare \(X\) se poate scrie sub forma \(X=[\mathbb{1}\,|\,Z]\) unde \(Z=\left[X_{2}\,|\, \cdots\,|\, X_{p}\right]\) este matricea de dimensiune \(n \times(p-1)\) a ultimelor \((p-1)\) coloane din \(X\). Astfel modelul poate fi rescris sub forma:
\[ Y=\beta_{1} \mathbb{1}+Z \beta_{(1)}+\varepsilon \]
unde \(\beta_{1}\) este prima coordonată a vectorului \(\beta\) iar \(\beta_{(1)}\) reprezintă vectorul \(\beta\) fără prima coordonată.
Dați \(P_{\mathbb{1}}\), matricea de proiecție ortogonală pe subspațiul generat de vectorul \(\mathbb{1}\).
Determinași matricea de proiecție ortogonală \(P_{\mathbb{1}^\perp}\) pe subspațiul \(\mathbb{1}^{\perp}\) ortogonal la vectorul \(\mathbb{1}\).
Calculați \(P_{\mathbb{1}^\perp} Z\).
Deduceți că estimatorul lui \(\beta\) obținut prin metoda celor mai mici pătrate în modelul inițial poate fi determinat și prin metoda celor mai mici pătrate aplicate modelului următor:
\[ \tilde{Y}=\tilde{Z} \beta_{(1)}+\boldsymbol{\eta} \]
unde \(\tilde{Y}=P_{\mathbb{1}^\perp} Y\) iar \(\tilde{Z}=P_{\mathbb{1}^\perp} Z\).
Scrieți suma abaterilor pătratice reziduale (\(RSS\)) pentru modelul inițial și arătați că aceasta este egală cu \(RSS\) din modelul de la punctul 4.
Scrieți un cod
Rcare să ilustreze punctele anterioare.
Exercițiul 2.8 (Motoda celor mai mici pătrate)
- Considerăm modelul de regresie liniară
\[ Y=X \beta+\varepsilon \]
unde \(Y \in \mathbb{R}^{n}, X\) este o matrice de dimensiune \(n \times p\) de rang \(p\), \(\beta \in \mathbb{R}^{p}\) și \(\varepsilon \sim \mathcal{N}\left(0, \sigma^{2} I_{n}\right)\).
- Ce numim estimator obținut prin metoda celor mai mici pătrate \(\hat{\beta}\) al lui \(\beta\)? Reamintiți formula acestuia.
- Care este interpretarea geometrică a lui \(\hat{Y}=X \hat{\beta}\) (desenați)?
- Reamintim speranțele și matricile de covarianță ale lui \(\hat{\beta}\), \(\hat{Y}\) și \(\hat{\varepsilon}\).
- De acum înainte vom lua în considerare un model cu \(4\) variabile explicative (prima variabilă fiind constanta). Am observat:
\[ X^{\intercal} X=\begin{pmatrix} 100 & 20 & 0 & 0 \\ 20 & 20 & 0 & 0 \\ 0 & 0 & 10 & 0 \\ 0 & 0 & 0 & 1 \end{pmatrix}, \quad X^{\intercal} Y=\begin{pmatrix} -60 \\ 20 \\ 10 \\ 1 \end{pmatrix}, \quad Y^{\prime} Y=159 \]
- Estimați \(\beta\) și \(\sigma^{2}\).
- Dați o estimare a varianței lui \(\hat{\beta}\).
- Dați un interval de încredere pentru \(\beta_{2}\), la nivelul de încredere de \(95\%\).
- Calculați un interval de predicție pentru \(y_{n+1}\) la un nivel de \(95\%\), cunoscând: \(x_{n+1,2}=3\), \(x_{n+1,3}=0,5\) și \(x_{n+1,4}=2\).
Referințe
Faraway, Julian. 2015. Linear Models with r. 2nd ed. CRC Press.
Henderson, H. V., and S. R. Searle. 1981. “On Deriving the Inverse of a Sum of Matrices.” SIAM Review 23 (1): 53–60. https://doi.org/10.1137/1023004.
Ornea, L., and A. Turtoi. 2000. O Introducere in Geometrie. Fundatia Theta.
Rencher, Alvin C, and G Bruce Schaalje. 2008. Linear Models in Statistics. John Wiley & Sons.
Yanai, Haruo, Kei Takeuchi, and Yoshio Takane. 2011. Projection Matrices, Generalized Inverse Matrices, and Singular Value Decomposition. Springer-Verlag New York. https://doi.org/https://doi.org/10.1007/978-1-4419-9887-3.
Note de subsol
În general, numim proiecție un endomorfism \(p: W\to W\) cu proprietatea că există o descompunere în sumă directă \(W = V_1\oplus V_2\) (și spunem proiecție pe \(V_1\) de-a lungul lui \(V_2\)) astfel încât \(p(\symbf w) = \symbf v_1\), \(\forall \symbf w\in W\) cu \(\symbf w = \symbf v_1 + \symbf v_2\), \(\symbf v_1\in V_1\) și \(\symbf v_2\in V_2\).↩︎