Modele de regresie
Intervale de încredere
1 Intervale de încredere
Dacă în problema de estimare punctuală am găsit, plecând de la un eșantion generat dintr-o populație guvernată de un parametru \(\theta\), o valoare cât mai apropiată de parametrul necunoscut, în această secțiune ne propunem să determinăm un interval de valori care să aibă o probabilitate mare să conțină parametrul real. Este clar că între estimarea punctuală și cea prin intervale de încredere va fi o strânsă legătură, cea de-a doua abordare bazându-se pe prima. Avem următoarea definiție
Definiția 1.1 (Interval de estimare) Fie \(X_1,\ldots,X_n\) un eșantion de talie \(n\) dintr-o populație \(F_{\theta}=\mathbb{P}\circ X^{-1}\), \(\theta\in\Theta\) cu \(X_i:\Omega\to(S,\mathcal{S})\). Fie \(\alpha\in(0,1)\) și funcțiile măsurabile \(A_{\alpha}, B_{\alpha}:S^n\to\mathbb{R}\) care verifică
\[ A_{\alpha}(x_1,\ldots,x_n)\leq B_{\alpha}(x_1,\ldots,x_n),\quad\forall (x_1,\ldots,x_n)\in S^n. \]
Intervalul aleator \(\left[A_{\alpha}(X_1,\ldots,X_n), B_{\alpha}(X_1,\ldots,X_n)\right]\) se numește interval de estimare pentru \(\theta\) cu coeficientul de încredere \(1-\alpha\) dacă
\[ \mathbb{P}_{\theta}\left(\left[A_{\alpha}(X_1,\ldots,X_n), B_{\alpha}(X_1,\ldots,X_n)\right]\ni \theta\right)\geq 1-\alpha,\quad\forall\theta\in\Theta. \]
Este important de notat că în definiția anterioară intervalul \(\left[A_{\alpha}(X_1,\ldots,X_n), B_{\alpha}(X_1,\ldots,X_n)\right]\) este un interval aleator și nu parametrul \(\theta\) este aleator.
Definiția 1.2 (Probabilitate de acoperire) Având dat un interval de estimare \(\left[A_{\alpha}(X_1,\ldots,X_n), B_{\alpha}(X_1,\ldots,X_n)\right]\) pentru \(\theta\) se numește probabilitatea de acoperire a acestuia
\[ \mathbb{P}_{\theta}\left(\left[A_{\alpha}(X_1,\ldots,X_n), B_{\alpha}(X_1,\ldots,X_n)\right]\ni \theta\right) \]
iar coeficientul de încredere al intervalului este definit prin
\[ \inf_{\theta}\mathbb{P}_{\theta}\left(\left[A_{\alpha}(X_1,\ldots,X_n), B_{\alpha}(X_1,\ldots,X_n)\right]\ni \theta\right) = 1-\alpha \]
Trebuie menționat că atunci când avem observațiile \(x_1,\ldots,x_n\), intervalul de estimare realizat se numește interval de încredere de nivel de încredere \(1-\alpha\) și se notează cu
\[ IC^{1-\alpha}(\theta) = \left[A_{\alpha}(x_1,\ldots,x_n), B_{\alpha}(x_1,\ldots,x_n)\right]. \]
Chiar dacă noțiunea de interval de încredere și interval de estimare va fi folosită alternativ (prin abuz de limbaj) este important de notat că pentru un interval de încredere nu are sens să vorbim de \(\mathbb{P}_{\theta}\left(IC^{1-\alpha}(\theta)\ni \theta\right)\) deoarece această probabilitate este \(0\) sau \(1\) după cum parametrul \(\theta\in IC^{1-\alpha}(\theta)\).
Ca prim exemplu să presupunem că \(X_1,\ldots,X_n\) este un eșantion de talie \(n\) dintr-o populație \(\mathcal{N}(\theta, 1)\). Am văzut că \(\bar X_n\sim\mathcal{N}(\theta, 1/n)\) sau încă \(\frac{\bar X_n - \theta}{\frac{1}{\sqrt{n}}}\sim\mathcal{N}(0,1)\). Fie \(z_1, z_2\) cuantile ale repartiției normale standard pentru care are loc relația
\[ \mathbb{P}_{\theta}\left(z_1\leq \frac{\bar X_n - \theta}{\frac{1}{\sqrt{n}}}\leq z_2\right) = \mathbb{P}_{\theta}\left(\bar X_n - \frac{z_2}{\sqrt{n}}\leq \theta \leq \bar X_n - \frac{z_1}{\sqrt{n}}\right) = 1-\alpha \]
Atunci, pentru eșantionul realizat \(x_1,\ldots,x_n\), intervalul \(IC^{1-\alpha}(\theta) = \left[\bar x_n - \frac{z_2}{\sqrt{n}},\bar x_n - \frac{z_1}{\sqrt{n}}\right]\) este un interval de încredere de nivel de încredere \(1-\alpha\) pentru \(\theta\) a cărui lungime este \(l\left(IC^{1-\alpha}(\theta)\right)=\frac{1}{\sqrt{n}}(z_2-z_1)\). Observăm că putem avea o infinitate de astfel de intervale dar dorim să determinăm acel interval care are lungimea cea mai mică. Dacă facem ipoteza suplimentară că \(z_2 = z_2(z_1)\) (o funcție de \(z_1\)) atunci suntem în cadrul unei probleme de optimizare, mai precis avem problema (cu notațiile standard pentru funcția de repartiție și densitatea repartiției normale standard)
\[ \left\{\begin{array}{ll} \min \frac{1}{\sqrt{n}}(z_2-z_1)\\ \Phi(z_2) - \Phi(z_1) = 1-\alpha \end{array}\right. \]
care, prin derivare, conduce la relațiile \(\phi(z_2)\frac{d}{dz_1}z_2 - \phi(z_1) = 0\) și \(\frac{d}{dz_1}z_2 - 1 = 0\) ceea ce implică \(\phi(z_2)=\phi(z_1)\). Din simetria repartiției normale deducem că \(z_2=z_{1-\alpha/2}\) și \(z_1 = z_{\alpha/2} = -z_{1-\alpha/2}\) unde \(z_{\alpha}\) este cuantila de ordin \(\alpha\) a repartiției \(\mathcal{N}(0,1)\). Am obținut astfel intervalul de încredere pentru \(\theta\)
\[ IC^{1-\alpha}(\theta) = \left[\bar x_n - \frac{z_{1-\alpha/2}}{\sqrt{n}},\bar x_n + \frac{z_{1-\alpha/2}}{\sqrt{n}}\right] \]
1.1 Metoda pivotului de determinare a intervalelor de încredere
O primă metodă de determinare a intervalelor de încredere este metoda pivotului.
Definiția 1.3 (Funcție pivot) Fie \(X_1,\ldots,X_n\) un eșantion de talie \(n\) dintr-o populație \(F_{\theta}=\mathbb{P}\circ X^{-1}\), \(\theta\in\Theta\). O funcție \(g(x_1,\ldots,x_n,\theta):S^n\times\Theta\to\mathbb{R}\) se numește funcție pivot dacă verifică următoarele proprietăți:
- repartiția lui \(g(X_1,\ldots,X_n,\theta)\) nu depinde de \(\theta\)
- pentru orice valori reale \(u_1\leq u_2\) și orice \((x_1,\ldots,x_n)\in S^n\) inecuația \(u_1\leq g(x_1,\ldots,x_n,\theta)\leq u_2\) se poate rezolva în \(\theta\) (se poate pivota) conducând la o soluție de forma \(a(x_1,\ldots,x_n)\leq \theta\leq b(x_1,\ldots,x_n)\).
Existența unei funcții pivot asigură o procedură de determinare a intervalelor de încredere de nivel de încredere dat.
Propoziția 1.1 Fie \(X_1,\ldots,X_n\) un eșantion de talie \(n\) dintr-o populație \(F_{\theta}=\mathbb{P}\circ X^{-1}\), \(\theta\in\Theta\) și \(g:S^n\times\Theta\to\mathbb{R}\) o funcție care verifică:
- \(g(x_1,\ldots,x_n, \cdot)\) este continuă și strict monotonă ca funcție de \(\theta\)
- \(g(\cdot,\theta)\) este măsurabilă ca funcție de \((x_1,\ldots,x_n)\) pentru orice \(\theta\) și variabila aleatoare \(g(X_1,\ldots,X_n,\theta)\) are o repartiție independentă de \(\theta\).
Atunci pentru orice \(\alpha\in(0,1)\) există un interval de încredere \(IC^{1-\alpha}(\theta)\) de nivel \(1-\alpha\) pentru \(\theta\).
Pentru a exemplifica rezultatul anterior să considerăm că avem un eșantion \(X_1,\ldots,X_n\sim\mathcal{E}(\lambda)\). Cum variabila aleatoare \(T_n = \sum_{i=1}^{n}X_i\sim \Gamma(n, \lambda)\), densitatea ei este
\[ f_{T_n}(t) = \frac{\lambda^n}{(n-1)!}t^{n-1}e^{-\lambda t}\mathbf{1}_{\{t\geq 0\}} \]
prin urmare variabila aleatoare \(\lambda T_n\) are densitatea
\[ \begin{aligned} f_{\lambda T_n}(t) &= \frac{d}{dt}F_{\lambda T_n}(t) = \frac{d}{dt}\mathbb{P}(\lambda T_n\leq t) = \frac{d}{dt}F_{T_n}\left(\frac{t}{\lambda}\right) \\ &= \frac{1}{\lambda}f_{T_n}\left(\frac{t}{\lambda}\right) = \frac{1}{(n-1)!}t^{n-1}e^{-t}\mathbf{1}_{\{t\geq 0\}} \end{aligned} \]
ceea ce implică \(\lambda T_n\sim\Gamma(n,1)\) și nu depinde de \(\lambda\). Definim funcția
\[ g(x_1,\ldots,x_n,\lambda) = \lambda\sum_{i=1}^n x_i \]
care verifică proprietățile unei funcții pivot. Fie, de asemenea, \(u_1\) și \(u_2\) cuantilele de ordin \(\alpha/2\) și respectiv \(1-\alpha/2\) a repartiției \(\Gamma(n,1)\) atunci
\[ \mathbb{P}_{\lambda}\left(u_1\leq g(X_1,\ldots,X_n,\lambda)\leq u_2\right) = 1-\alpha \]
determină intervalul de estimare (încredere) de nivel \(1-\alpha\) pentru \(\lambda\)
\[ IC^{1-\alpha}(\theta) = \left[\frac{u_1}{\sum_{i=1}^n X_i},\frac{u_2}{\sum_{i=1}^n X_i}\right]. \]
Una dintre întrebările importante atunci când vorbim de intervale de încredere este cum alegem cuantilele \(u_1\) și \(u_2\) dat fiind că în general avem o infinitate de metode de alegere (ar trebui să verifice \(F(u_2) - F(u_1) = 1-\alpha\)). Următorul rezultat răspunde parțial la această întrebare:
Definiția 1.4 (Densitate unimodală) Spunem că o densitate de repartiție \(f\) este unimodală dacă există \(x^*\) astfel încât \(f(x)\) este crescătoare pentru \(x\leq x^*\) și descrescătoare pentru \(x\geq x^*\).
Propoziția 1.2 Fie \(f(x)\) o densitate de repartiție unimodală. Dacă intervalul \([a,b]\) satisface:
- \(\int_{a}^{b}f(x)\,dx = 1-\alpha\)
- \(f(a)=f(b)>0\)
- \(a\leq x^*\leq b\) unde \(x^*\) este modul lui \(f\)
atunci \([a,b]\) este intervalul de lungime minimă care verifică \(\int_{a}^{b}f(x)\,dx = 1-\alpha\).
1.2 Metode asimptotice
În context general, presupunem că avem un eșantion \(X_1,\ldots,X_n\) un eșantion de talie \(n\) dintr-o populație \(F_{\theta}=\mathbb{P}\circ X^{-1}\), \(\theta\in\Theta\) și există un estimator \(T_n\) pentru \(\theta\) care verifică o relație de tipul Teormei Limită Centrale,
\[ \frac{T_n - \theta}{s_{n}(\theta)}\overset{d}{\to}\mathcal{N}(0,1) \]
unde \(s_{n}(\cdot)\) este o funcție care depinde de \(\theta\), aleasă potrivit (de cele mai multe ori este chiar abaterea standard a lui \(T_n\)). Dacă funcția (în \(\theta\)) \(\frac{T_n - \theta}{s_{n}(\theta)}\) se poate pivota atunci putem rezolva pentru a-l izola pe \(\theta\) și astfel putem determina intervalul de încredere dorit. În caz contrar, vom folosi abordarea lui Wald (Wald plug-in) care ne spune că, în anumite condiții de regularitate, putem să-l înlocuim pe \(\theta\) de la numitor cu estimatorul \(T_n\), acesta fiind consistent (dat fiind relația de tip Teoremă Limită Centrală). Reamintim următorul rezultat, datorat lui Slutsky:
Propoziția 1.3 (Lema lui Slutsky) Fie \(\left(X_n\right)_n\) și \(\left(Y_n\right)_n\) două șiruri de variabile aleatoare astfel încât \(X_n\overset{d}{\to}X\) și \(Y_n\overset{\mathbb{P}}{\to}a\), \(a\) este o constantă. Atunci
\[ X_{n}+Y_{n} \overset{d}{\underset{n \to \infty}{\longrightarrow}} X+a \quad \text { și } \quad X_{n} Y_{n} \overset{d}{\underset{n \to \infty}{\longrightarrow}} a X \]
Dacă \(s_n(\cdot)\) este continuă și \(T_n\overset{\mathbb{P}}{\rightarrow}\theta\) atunci \(s_n(T_n)\overset{\mathbb{P}}{\rightarrow}s_n(\theta)\) și din Teorema lui Slutsky avem
\[ \frac{T_n - \theta}{s_{n}(T_n)} = \underbrace{\frac{T_n - \theta}{s_{n}(\theta)}}_{\overset{d}{\rightarrow}\mathcal{N}(0,1)}\times\underbrace{\frac{s_n(\theta)}{s_n(T_n)}}_{\overset{\mathbb{P}}{\rightarrow}1}\overset{d}{\rightarrow}\mathcal{N}(0,1). \]
Astfel, pentru \(\alpha\in(0,1)\) fixat și \(z_{\frac{\alpha}{2}} = -z_{1 - \frac{\alpha}{2}}\) și \(z_{1 - \frac{\alpha}{2}}\) cuantilele de ordin \(\frac{\alpha}{2}\) și respectiv \(1-\frac{\alpha}{2}\) ale repartiției \(\mathcal{N}(0,1)\) avem
\[ \mathbb{P}_{\theta}\left(z_{\frac{\alpha}{2}}\leq \frac{T_n - \theta}{s_{n}(T_n)}\leq z_{1 - \frac{\alpha}{2}}\right) \approx 1-\alpha \]
de unde prin pivotare obținem intervalul de încredere aproximativ
\[ IC^{1-\alpha}(\theta)=\left[t_n - z_{1 - \frac{\alpha}{2}}s_n(t_n), t_n + z_{1 - \frac{\alpha}{2}}s_n(t_n)\right] \]
unde \(t_n\) este realizarea lui \(T_n\). Intervalul de încredere de mai sus este aproximativ în sensul că procedura adoptată nu asigură cu exactitate un nivel \(1-\alpha\) pentru orice \(\theta\), \(n\) finit.
Pentru a exemplifica vom considera cazul unei populații Poisson: \(X_1,\ldots,X_n\sim\mathrm{Pois}(\theta)\). Din Teorema Limită Centrală avem (\(s_n(\theta) = \sqrt{\frac{\theta}{n}}\))
\[ \sqrt{n}\frac{\bar X_n - \theta}{\sqrt{\theta}}\overset{d}{\rightarrow}\mathcal{N}(0,1) \]
de unde
\[ \mathbb{P}_{\theta}\left(z_{\frac{\alpha}{2}}\leq \sqrt{n}\frac{\bar X_n - \theta}{\sqrt{\theta}}\leq z_{1 - \frac{\alpha}{2}}\right) \approx 1-\alpha. \]
Dubla inegalitate din probabilitatea de mai sus poate fi scrisă sub forma \(n\frac{(\bar X_n - \theta)}{\theta}\leq z_{1 - \frac{\alpha}{2}}^2\) ceea ce revine la a rezolva o inecuație de gradul doi. Soluția acestei inecuații conduce la intervalul de încredere aproximativ
\[ \mathbb{P}_{\theta}\left(\bar X_n + \frac{z_{1-\frac{\alpha}{2}}^2}{n}-\sqrt{\frac{\bar X_n z_{1-\frac{\alpha}{2}}^2}{n} + \frac{z_{1-\frac{\alpha}{2}}^4}{4n^2}}\leq \theta\leq \bar X_n + \frac{z_{1-\frac{\alpha}{2}}^2}{n}+\sqrt{\frac{\bar X_n z_{1-\frac{\alpha}{2}}^2}{n} + \frac{z_{1-\frac{\alpha}{2}}^4}{4n^2}}\right) \approx 1-\alpha. \]
Observăm că dacă în expresia de mai sus neglijăm termenii de ordin \(\frac{1}{n^2}\) de sub radical și termenii de ordin \(\frac{1}{n}\) din afara acestuia obținem intervalul de încredere de tip Wald:
\[ \mathbb{P}_{\theta}\left(\bar X_n -z_{1-\frac{\alpha}{2}}\sqrt{\frac{\bar X_n}{n}}\leq \theta\leq \bar X_n +z_{1-\frac{\alpha}{2}}\sqrt{\frac{\bar X_n}{n}}\right) \approx 1-\alpha. \]
Pentru a finaliza, mai rămâne întrebarea existenței estimatorului \(T_n\) care să verifice o expresie asimptotică precum cea de la începutul secțiunii. Am văzut că atunci când populația din care provine eșantionul îndeplinește o serie de condiții de regularitate, estimatorul de verosimilitate maximă \(\hat \theta_n\) a lui \(\theta\) satisface
\[ \frac{\hat\theta_n - \theta}{\sqrt{\frac{1}{n I_1(\theta)}}}\overset{d}{\rightarrow}\mathcal{N}(0,1) \]
unde \(I_1(\theta) = \mathbb{E}_{\theta}\left[\left(\frac{\partial}{\partial\theta}\log f_{\theta}(X_1)\right)^2\right]\) este Informația lui Fisher asociată unei observații. Cu excepția unor cazuri simple în care expresia lui \(I_1(\theta)\) ne permite să pivotăm vom folosi abordarea lui Wald, înlocuind \(I_1(\theta)\) cu \(I_1(\hat\theta_n)\). Obținem astfel intervalul de încredere asimptotic pentru \(\theta\)
\[ IC^{1-\alpha}(\theta)=\left[\hat\theta_n - \frac{z_{1 - \frac{\alpha}{2}}}{\sqrt{nI_1(\hat\theta_n)}}, \hat\theta_n + \frac{z_{1 - \frac{\alpha}{2}}}{\sqrt{nI_1(\hat\theta_n)}}\right]. \]
În secțiunile următoare vom exemplifica modul de construcție al unui interval de încredere în contextul unei populații normale.
1.3 Intervale de încredere pentru media unei populații normale atunci când varianța este cunoscută
Fie \(X_1, \ldots, X_n\) un eșantion de talie \(n\) dintr-o populație normală \(\mathcal{N}(\mu, \sigma^2)\) cu \(\sigma^2\) cunoscut și \(\mu\) necunoscut. Vrem să determinăm un interval de încredere de nivel \(1-\alpha\) pentru media populației normale. Am văzut că \(\bar X_n\sim\mathcal{N}\left(\mu, \frac{\sigma^2}{n}\right)\) ceea ce implică \(\sqrt{n}\frac{\bar X_n - \mu}{\sigma}\sim\mathcal{N}(0,1)\).
Alegem funcția pivot \(g(x_1,\ldots,x_n,\mu) = \sqrt{n}\frac{\bar x_n - \mu}{\sigma}\) și pentru \(\alpha\in(0,1)\) fixat considerăm \(z_{\frac{\alpha}{2}}\) și \(z_{1 - \frac{\alpha}{2}}\) cuantilele de ordin \(\frac{\alpha}{2}\) și respectiv \(1-\frac{\alpha}{2}\) ale repartiției \(\mathcal{N}(0,1)\). Avem, ținând cont și de simetria normalei față de medie, că
\[ \mathbb{P}_{\mu}\left(z_{\frac{\alpha}{2}}\leq \sqrt{n}\frac{\bar X_n - \mu}{\sigma}\leq z_{1 - \frac{\alpha}{2}}\right) = \mathbb{P}_{\mu}\left(\bar X_n - z_{1-\frac{\alpha}{2}}\frac{\sigma}{\sqrt{n}}\leq \mu\leq \bar X_n + z_{1-\frac{\alpha}{2}}\frac{\sigma}{\sqrt{n}}\right) = 1-\alpha \]
de unde concluzionăm că
\[ IC^{1-\alpha}(\mu) = \left[\bar x_n - z_{1-\frac{\alpha}{2}}\frac{\sigma}{\sqrt{n}}, \bar x_n + z_{1-\frac{\alpha}{2}}\frac{\sigma}{\sqrt{n}}\right] \]
este un interval de încredere de nivel \(1-\alpha\) pentru \(\mu\).
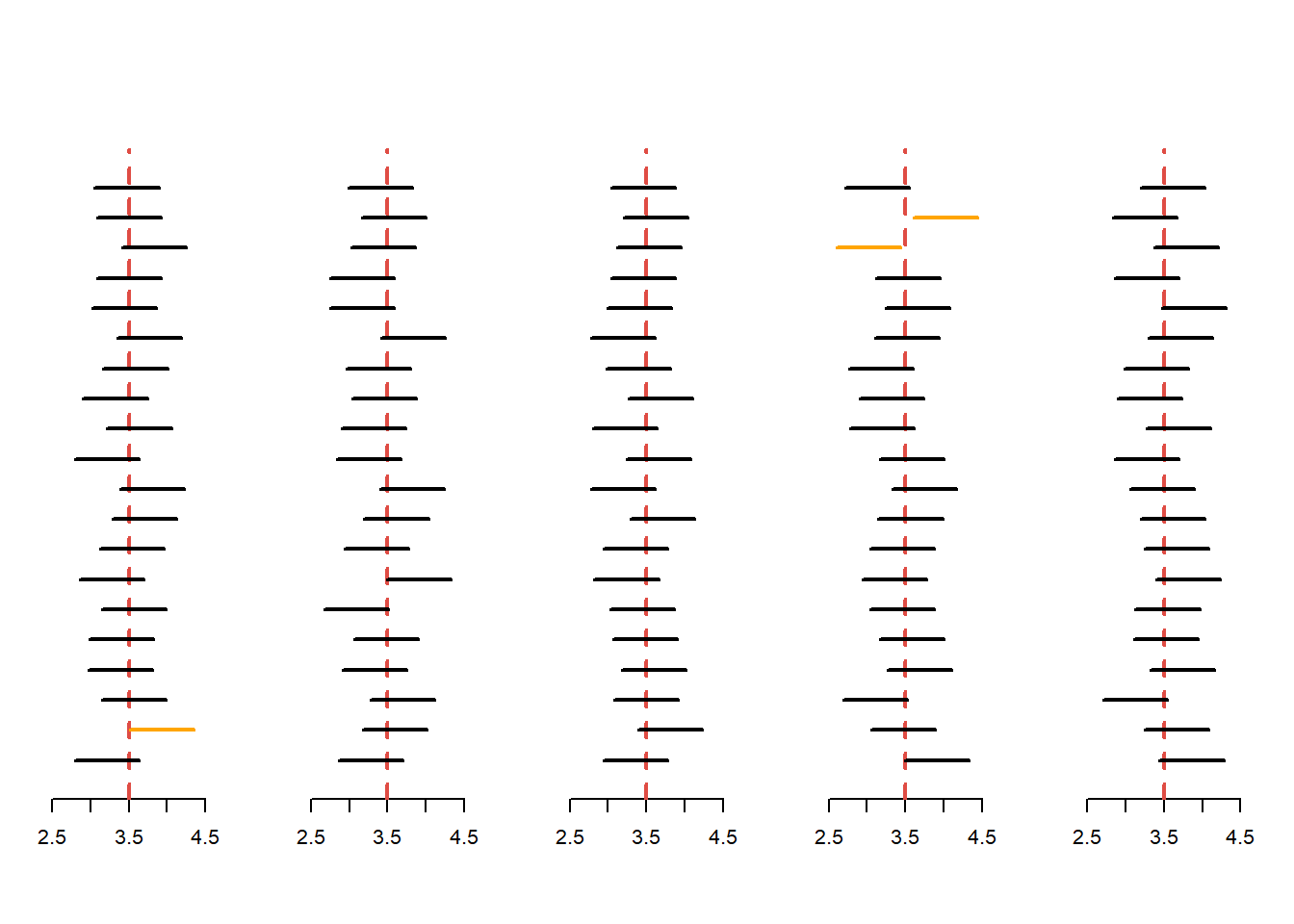
O ilustrare a \(100\) de intervalele de încredere de nivel de încredere \(1-\alpha = 0.95\) pentru media unei populații normale \(\mathcal{N}(3.5, 1.5^2)\) atunci când \(\sigma = 1.5\) este cunoscut este afișată mai jos:
Arată codul R din exemplul de mai sus
# cate panouri sa avem
p <- 5
# nr de intervale de incredere per panou
n <- 20
# volumul esantionului
m <- 50
# coeficient de incredere
alpha <- 0.05
# media si sd populatia normala
mu <- 3.5
sd <- 1.5
lo3 <- hi3 <- lo2 <- hi2 <- lo <- hi <- vector("list", p)
lo_s <- hi_s <- vector("list", p)
for(i in 1:p) {
dat <- matrix(rnorm(n*m, mean = mu, sd = sd), ncol = m)
# media si vaianta esantionului
me <- apply(dat,1,mean)
se <- apply(dat,1,sd)
# calcul intervale de incredere
lo[[i]] <- me - qnorm(1-alpha/2)*sd/sqrt(m)
hi[[i]] <- me + qnorm(1-alpha/2)*sd/sqrt(m)
lo2[[i]] <- me - qnorm(1-alpha/2)*se/sqrt(m)
hi2[[i]] <- me + qnorm(1-alpha/2)*se/sqrt(m)
lo3[[i]] <- me - qt(1-alpha/2, m-1)*se/sqrt(m)
hi3[[i]] <- me + qt(1-alpha/2, m-1)*se/sqrt(m)
lo_s[[i]] <- (m-1)*se^2/qchisq(1-alpha/2, df = m-1)
hi_s[[i]] <- (m-1)*se^2/qchisq(alpha/2, df = m-1)
}
r <- range(unlist(c(lo,hi,lo2,hi2,lo3,hi3)))
par(mfrow=c(1,5), las=1, mar=c(5.1,2.1,6.1,2.1))
for(i in 1:p) {
plot(0, 0, type="n",
ylim = 0.5+c(0,n),
xlim = r,
ylab = "",
xlab = "",
yaxt = "n", bty = "n")
abline(v = mu, lty=2, col=myred, lwd=2)
segments(lo[[i]], 1:n,
hi[[i]], 1:n,
lwd=2)
o = (1:n)[lo[[i]] > 3.5 | hi[[i]] < 3.5]
segments(lo[[i]][o], o,
hi[[i]][o], o,
lwd=2,col="orange")
}1.4 Intervale de încredere pentru media unei populații normale atunci când varianța este necunoscută
Fie \(X_1, \ldots, X_n\) un eșantion de talie \(n\) dintr-o populație normală \(\mathcal{N}(\mu, \sigma^2)\) cu \(\mu\) și \(\sigma^2\) necunoscute. Am văzut că înlocuind \(\sigma^2\) cu statistica \(S_n^2 = \frac{1}{n-1}\sum_{i=1}^{n}\left(X_i - \bar X_n\right)^2\) (varianța eșantionului) în \(\sqrt{n}\frac{\bar X_n - \mu}{\sigma}\) obținem statistica \(T_n = \sqrt{n}\frac{\bar X_n - \mu}{S_n}\) care este repartizată Student cu \(n-1\) grade de libertate, i.e.
\[ T_n = \sqrt{n}\frac{\bar X_n - \mu}{S_n}\sim t_{n-1}. \]
Pentru funcția pivot \(g(x_1,\ldots,x_n,\mu) = \sqrt{n}\frac{\bar x_n - \mu}{s_n}\) și pentru \(\alpha\in(0,1)\) fixat, fie \(t_{n-1,\frac{\alpha}{2}}\) și \(t_{n-1,1 - \frac{\alpha}{2}}\) cuantilele de ordin \(\frac{\alpha}{2}\) și respectiv \(1-\frac{\alpha}{2}\) ale repartiției \(t_{n-1}\). Atunci
\[ \mathbb{P}_{\mu}\left(t_{n-1,\frac{\alpha}{2}}\leq \sqrt{n}\frac{\bar X_n - \mu}{S_n}\leq t_{n-1,1-\frac{\alpha}{2}}\right) = \mathbb{P}_{\mu}\left(\bar X_n - t_{n-1,1-\frac{\alpha}{2}}\frac{S_n}{\sqrt{n}}\leq \mu\leq \bar X_n + t_{n-1, 1-\frac{\alpha}{2}}\frac{S_n}{\sqrt{n}}\right) = 1-\alpha, \]
unde \(t_{n-1,\frac{\alpha}{2}} = -t_{n-1,1-\frac{\alpha}{2}}\) din simetria repartiție Student și găsim astfel că un interval de încredere de nivel \(1-\alpha\) pentru \(\mu\) este
\[ IC^{1-\alpha}(\mu) = \left[\bar x_n - t_{n-1,1-\frac{\alpha}{2}}\frac{s_n}{\sqrt{n}}, \bar x_n + t_{n-1, 1-\frac{\alpha}{2}}\frac{s_n}{\sqrt{n}}\right]. \]
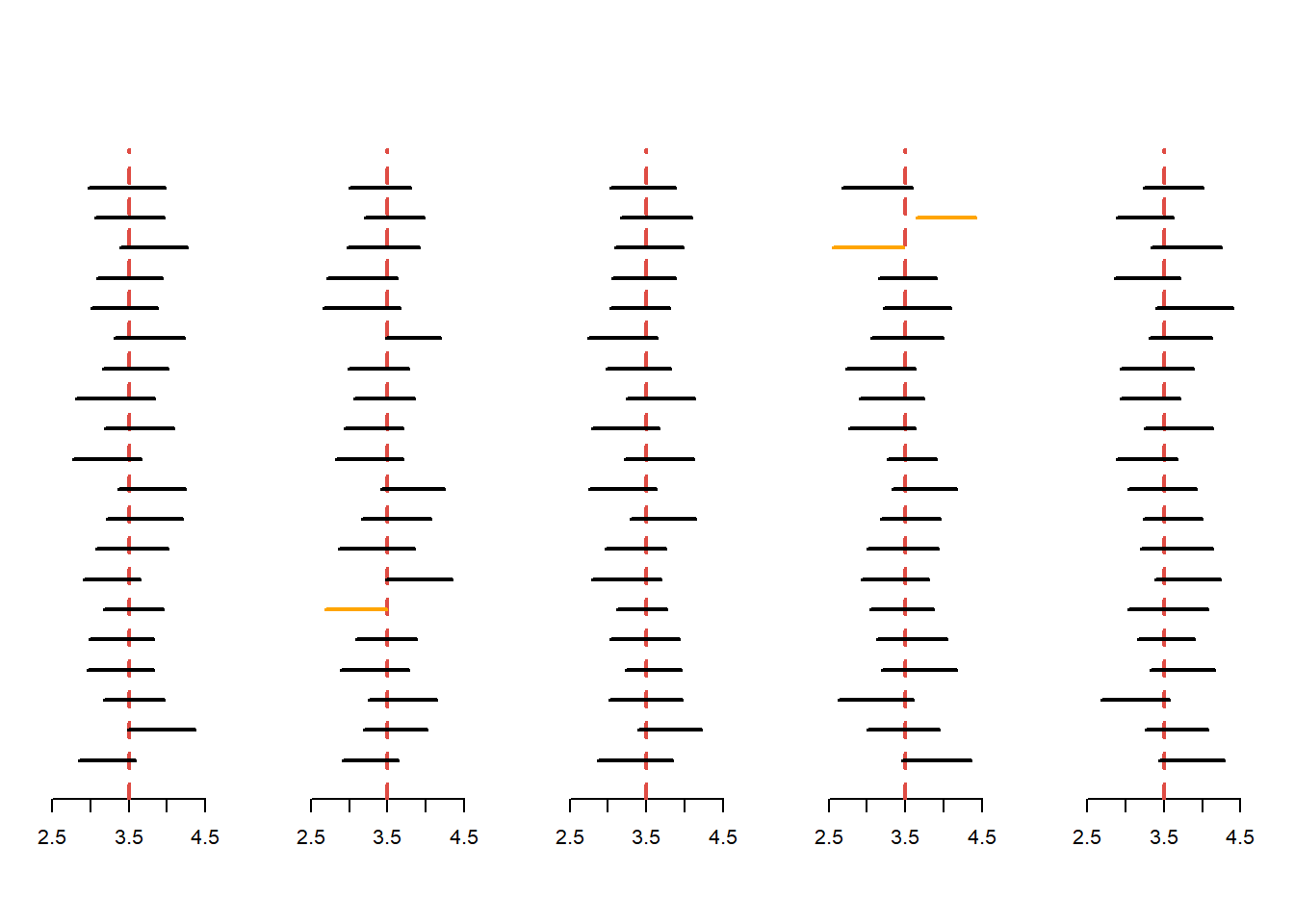
În Figura 1.2 de mai jos sunt prezentate \(100\) de intervale de încredere pentru \(\mu = 3.5\) de nivel de încredere \(1-\alpha = 0.95\) atunci când \(\sigma^2\) nu este cunoscut:
Arată codul R din exemplul de mai sus
par(mfrow=c(1,5), las=1, mar=c(5.1,2.1,6.1,2.1))
for(i in 1:p) {
plot(0,0,
type="n",
ylim=0.5+c(0,n),
xlim=r,
ylab="",
xlab="",
yaxt="n", bty = "n")
abline(v = mu, lty=2, col=myred, lwd=2)
segments(lo3[[i]],1:n,
hi3[[i]],1:n,
lwd=2)
o = (1:n)[lo3[[i]] > 3.5 | hi3[[i]] < 3.5]
segments(lo3[[i]][o],o,
hi3[[i]][o],o,
lwd=2, col="orange")
}1.5 Intervale de încredere pentru varianța unei populații normale
Fie \(X_1, \ldots, X_n\) un eșantion de talie \(n\) dintr-o populație normală \(\mathcal{N}(\mu, \sigma^2)\) cu \(\mu\) și \(\sigma^2\) necunoscute. Până acum am dat intervale de încredere pentru media populației iar acum ne interesăm la un interval de încredere pentru varianța populației. Reamintim că varianța eșantionului \(S_n^2\) este un estimator nedeplasat pentru \(\sigma^2\) care pentru populații normale verifică \(\frac{(n-1)S_n^2}{\sigma^2}\sim \chi_{n-1}^2\).
Pentru \(\alpha\in(0,1)\) fixat considerăm \(\chi_{n-1,\frac{\alpha}{2}}^2\) și \(\chi_{n-1,1 - \frac{\alpha}{2}}^2\) cuantilele de ordin \(\frac{\alpha}{2}\) și respectiv \(1-\frac{\alpha}{2}\) ale repartiției \(\chi_{n-1}^2\). Alegem ca funcție pivot \(g(x_1,\ldots,x_n,\sigma^2) = \frac{(n-1)s_n^2}{\sigma^2}\) și observăm că
\[ \mathbb{P}_{\mu}\left(\chi_{n-1,\frac{\alpha}{2}}^2\leq \frac{(n-1)S_n^2}{\sigma^2}\leq \chi_{n-1,1-\frac{\alpha}{2}}^2\right) = \mathbb{P}_{\mu}\left(\frac{(n-1)S_n^2}{\chi_{n-1,1-\frac{\alpha}{2}}^2}\leq \sigma^2\leq \frac{(n-1)S_n^2}{\chi_{n-1,\frac{\alpha}{2}}^2}\right) = 1-\alpha, \]
de unde concluzionăm că un interval de încredere pentru \(\sigma^2\) de nivel de încredere \(1-\alpha\) este
\[ IC^{1-\alpha}(\sigma^2) = \left[\frac{(n-1)S_n^2}{\chi_{n-1,1-\frac{\alpha}{2}}^2}, \frac{(n-1)S_n^2}{\chi_{n-1,\frac{\alpha}{2}}^2}\right]. \]
Este important de remarcat că în cazul în care media populației \(\mu\) este cunoscută atunci \(\frac{1}{\sigma^2}\sum_{i=1}^{n}(X_i-\mu)^2\sim \chi_{n}^2\) ceea ce conduce la un interval de încredere de forma
\[ IC^{1-\alpha}(\sigma^2) = \left[\frac{\sum_{i=1}^{n}(x_i-\mu)^2}{\chi_{n,1-\frac{\alpha}{2}}^2}, \frac{\sum_{i=1}^{n}(x_i-\mu)^2}{\chi_{n,\frac{\alpha}{2}}^2}\right]. \]
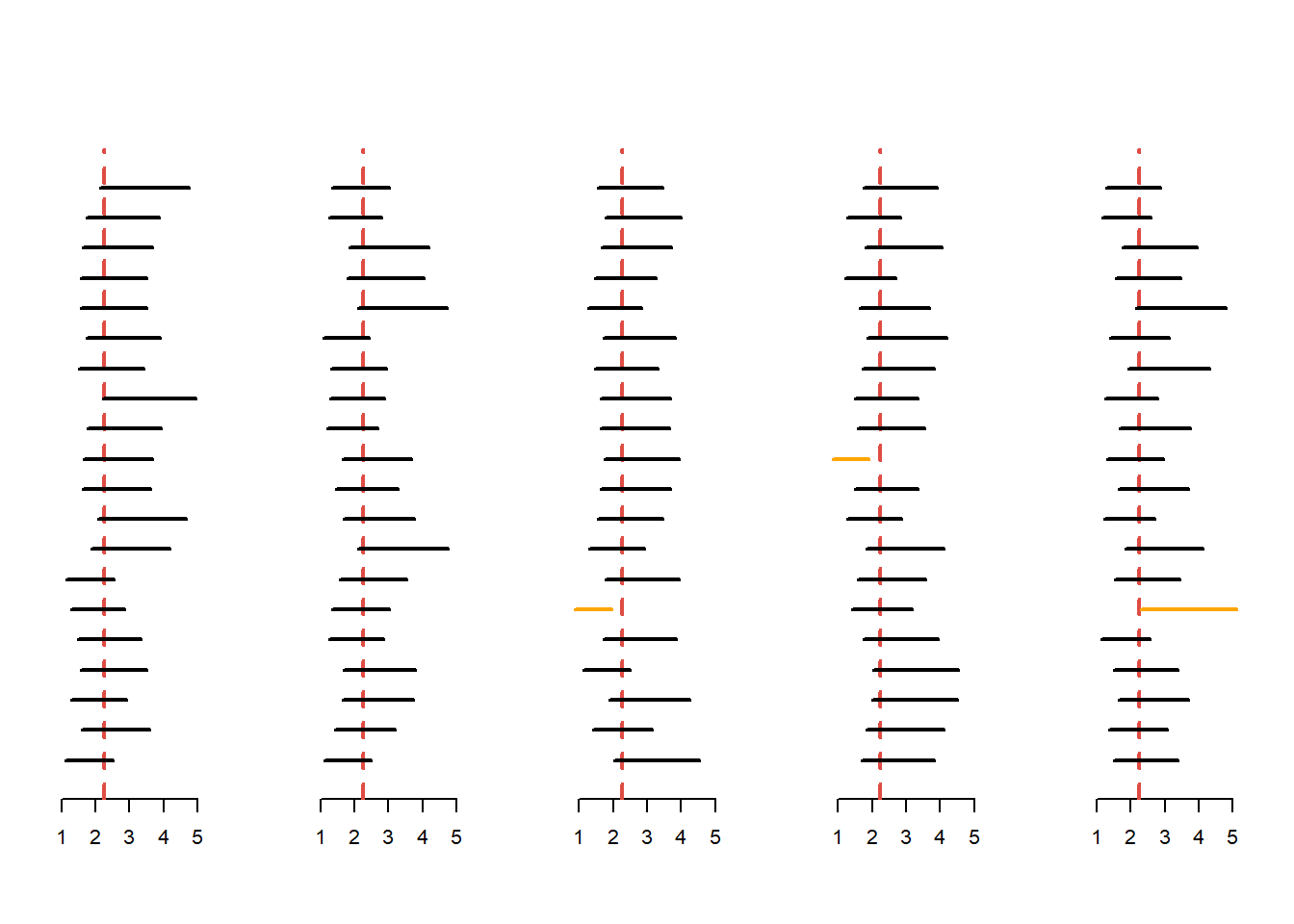
Figura 1.3 de mai jos ilustrează 100 de intervale de încredere pentru \(\sigma^2\) de nivel de încredere \(1-\alpha = 0.95\) atunci populația este normală și media este necunoscută.
Arată codul R din exemplul de mai sus
r <- range(unlist(c(lo_s,hi_s)))
par(mfrow=c(1,5), las=1, mar=c(5.1,2.1,6.1,2.1))
for(i in 1:p) {
plot(0,0,
type="n",
ylim=0.5+c(0,n),
xlim=r,
ylab="",
xlab="",
yaxt="n", bty = "n")
abline(v = sd^2, lty=2, col=myred, lwd=2)
segments(lo_s[[i]],1:n,
hi_s[[i]],1:n,
lwd=2)
o = (1:n)[lo_s[[i]] > sd^2 | hi_s[[i]] < sd^2]
segments(lo_s[[i]][o],o,
hi_s[[i]][o],o,
lwd=2, col="orange")
}1.6 Intervale de încredere pentru diferența mediilor a două populații normale
Fie \(X_1,\ldots,X_{n_1}\sim\mathcal{N}(\mu_1, \sigma^2)\) și \(Y_1,\ldots,Y_{n_2}\sim\mathcal{N}(\mu_2, \sigma^2)\) două eșantioane independente (între ele) de talie \(n_1\) și respectiv \(n_2\) din populații normale de medii diferite dar cu aceeași dispersie necunoscută \(\sigma^2\). Ne propunem să construim un interval de încredere de nivel \(1-\alpha\) pentru diferența mediilor \(\mu_1-\mu_2\). Ca și în cazul unei populații normale avem că \(\bar X_{n_1}\sim\mathcal{N}\left(\mu_1, \frac{\sigma^2}{n_1}\right)\) și \(\bar Y_{n_2}\sim\mathcal{N}\left(\mu_2, \frac{\sigma^2}{n_2}\right)\) prin urmare, ținând cont de independență, \(\bar X_{n_1} - \bar Y_{n_2}\sim\mathcal{N}\left(\mu_1-\mu_2, \sigma^2\left(\frac{1}{n_1} + \frac{1}{n_2}\right)\right)\). Din ultima relație deducem că
\[ \frac{(\bar X_{n_1} - \bar Y_{n_2})-(\mu_1-\mu_2)}{\sigma\sqrt{\frac{1}{n_1} + \frac{1}{n_2}}}\sim\mathcal{N}(0,1). \]
Cum \(\sigma^2\) este necunoscut îl vom estima plecând de la cele două eșantioane remarcând pentru început că \(\frac{(n_1-1)S_1^2}{\sigma^2}\sim \chi_{n_1-1}^2\) și \(\frac{(n_2-1)S_2^2}{\sigma^2}\sim \chi_{n_2-1}^2\), unde \(S_i^2\) reprezintă varianța eșantionului \(i = 1,2\). Ținând cont de independența dintre eșantioane avem că \(S_1^2\) și \(S_2^2\) sunt independente, prin urmare
\[ \frac{(n_1-1)S_1^2}{\sigma^2} + \frac{(n_1-1)S_1^2}{\sigma^2} \sim \chi_{n_1+n_2-2}^2. \]
Folosind aceeași metodă ca și în cazul mediei unei populații normale cu \(\mu\) și \(\sigma^2\) necunoscute deducem că statistica
\[ \frac{\frac{(\bar X_{n_1} - \bar Y_{n_2})-(\mu_1-\mu_2)}{\sigma\sqrt{\frac{1}{n_1} + \frac{1}{n_2}}}}{\sqrt{\frac{\frac{(n_1-1)S_1^2}{\sigma^2} + \frac{(n_1-1)S_1^2}{\sigma^2}}{n_1+n_2-2}}} \sim \frac{\mathcal{N}(0,1)}{\sqrt{\frac{\chi_{n_1+n_2-2}^2}{n_1+n_2-2}}}\sim t_{n_1+n_2-2}. \]
Astfel, notând cu \(S_p^2 = \frac{\frac{(n_1-1)S_1^2}{\sigma^2} + \frac{(n_1-1)S_1^2}{\sigma^2}}{n_1+n_2-2}\) estimatorul varianței \(\sigma^2\) (pooled variance), putem rescrie
\[ \frac{(\bar X_{n_1} - \bar Y_{n_2})-(\mu_1-\mu_2)}{S_p\sqrt{\frac{1}{n_1} + \frac{1}{n_2}}}\sim t_{n_1+n_2-2} \]
ceea ce conduce la intervalul de încredere de nivel \(1-\alpha\) pentru diferența mediilor (similar cu cel din cazul mediei populației normale atunci când varianța este necunoscută)
\[ \begin{aligned} IC^{1-\alpha}(\mu) &= \left[(\bar x_{n_1} - \bar y_{n_2}) - t_{n_1+n_2-2,1-\frac{\alpha}{2}}s_p\sqrt{\frac{1}{n_1} + \frac{1}{n_2}},\right.\\ &\quad\left.(\bar x_{n_1} - \bar y_{n_2}) + t_{n_1+n_2-2,1-\frac{\alpha}{2}}s_p\sqrt{\frac{1}{n_1} + \frac{1}{n_2}}\right]. \end{aligned} \]
Trebuie menționat că în cazul în care eșantioanele provin din populații cu varianțe diferite \(\sigma_1^2\neq \sigma_2^2\) atunci statistica \(\frac{(\bar X_{n_1} - \bar Y_{n_2})-(\mu_1-\mu_2)}{\sqrt{\frac{S_1^2}{n_1} + \frac{S_2^2}{n_2}}}\) nu mai este repartizată Student. În acest caz se folosește corecția lui Welch–Satterthwaite:
\[ \frac{(\bar X_{n_1} - \bar Y_{n_2})-(\mu_1-\mu_2)}{\sqrt{\frac{S_1^2}{n_1} + \frac{S_2^2}{n_2}}} \sim t_{\nu}, \quad \text{cu}\quad \nu = \frac{\left(\frac{S_1^2}{n_1} + \frac{S_2^2}{n_2}\right)^2}{\frac{\left(\frac{S_1^2}{n_1}\right)^2}{n_1-1}+\frac{\left(\frac{S_2^2}{n_2}\right)^2}{n_2-1}}. \]
1.7 Intervale de încredere pentru diferența mediilor a două populații normale atunci când datele vin în pereche
În cazul în care datele vin în perechi (de exemplu provin de la gemeni de sex diferit, de la indivizi care sunt potriviți după o serie de caracteristici sau de la aceiași indivizi inainte și după un eveniment de interes) atunci există dependență între acestea și nu mai putem aplica metoda anterioară. În acest context presupunem că \(X_1,\ldots,X_{n}\sim\mathcal{N}(\mu_1, \sigma_1^2)\) și \(Y_1,\ldots,Y_{n}\sim\mathcal{N}(\mu_2, \sigma_2^2)\) sunt două eșantioane cu date pereche și ne interesăm la determinarea unui interval de încredere pentru \(d = \mu_1-\mu_2\).
Fie \(D_i = X_i - Y_i\) variabilele aleatoare independente cu \(D_i\sim\mathcal{N}(d, s_d^2)\) unde \(d = \mu_1 - \mu_2\) iar \(s_d^2 = \sigma_1^2 + \sigma_2^2 - 2Cov(X_i,Y_i)\). Observăm, din normalitatea și independența variabilelor aleatoare \(D_i\), că statistica
\[ \sqrt{n}\frac{\bar D_n - d}{S_d}\sim t_{n-1} \]
unde \(S_d^2 = \frac{1}{n-1}\sum_{i=1}^{n}\left(D_i - \bar D_n\right)^2\) ceea ce conduce la intervalul de încredere de nivel de încredere \(1-\alpha\) pentru diferența mediilor
\[ IC^{1-\alpha}(\mu) = \left[\bar d_n - t_{n-1,1-\frac{\alpha}{2}}\frac{s_d}{\sqrt{n}}, \bar d_n + t_{n-1, 1-\frac{\alpha}{2}}\frac{d_n}{\sqrt{n}}\right]. \]
1.8 Intervale de încredere pentru raportul varianțelor a două populații normale
Fie \(X_1,\ldots,X_{n_1}\sim\mathcal{N}(\mu_1, \sigma_1^2)\) și \(Y_1,\ldots,Y_{n_2}\sim\mathcal{N}(\mu_2, \sigma_2^2)\) două eșantioane independente (între ele) de talie \(n_1\) și respectiv \(n_2\) din populații normale de medii și dispersii diferite. Ne propunem să construim un interval de încredere de nivel \(1-\alpha\) pentru raportul varianțelor \(\frac{\sigma_1^2}{\sigma_2^2}\).
Cum \(\frac{(n_1-1)S_1^2}{\sigma_1^2}\sim \chi_{n_1-1}^2\) și \(\frac{(n_2-1)S_2^2}{\sigma_2^2}\sim \chi_{n_2-1}^2\) unde \(S_1^2\) și \(S_2^2\) sunt varianțele primului și respectiv celui de-a doilea eșantion și ținând cont de independența dintre eșantioane, și în particular dintre \(S_1^2\) și \(S_2^2\), găsim
\[ \frac{\frac{S_1^2}{\sigma_1^2}}{\frac{S_2^2}{\sigma_2^2}} = \frac{\frac{\frac{(n_1-1)S_1^2}{\sigma_1^2}}{n_1-1}}{\frac{\frac{(n_2-1)S_2^2}{\sigma_2^2}}{n_2-1}} \sim \frac{\frac{\chi_{n_1-1}^2}{n_1-1}}{\frac{\chi_{n_1-1}^2}{n_1-1}}\sim F_{n_1-1,n_2-1}. \]
Astfel, pentru \(\alpha\in(0,1)\), avem
\[ \mathbb{P}_{\frac{\sigma_1^2}{\sigma_2^2}}\left(f_{n_1-1,n_2-1, \frac{\alpha}{2}}\leq \frac{\frac{S_1^2}{\sigma_1^2}}{\frac{S_2^2}{\sigma_2^2}}\leq f_{n_1-1,n_2-1, 1-\frac{\alpha}{2}}\right) = 1-\alpha, \]
unde \(f_{n_1-1,n_2-1, \alpha}\) este cuantila de ordin \(\alpha\) a repartiției Fisher-Snedecor \(F_{n_1-1,n_2-1}\) ceea ce conduce la intervalul de încredere de nivel \(1-\alpha\) pentru \(\frac{\sigma_1^2}{\sigma_2^2}\)
\[ IC^{1-\alpha}\left(\frac{\sigma_1^2}{\sigma_2^2}\right) = \left[\frac{S1^2}{S_2^2}f_{n_1-1,n_2-1, \frac{\alpha}{2}}, \frac{S1^2}{S_2^2}f_{n_1-1,n_2-1, 1-\frac{\alpha}{2}}\right]. \]
1.9 Intervale de încredere pentru o proporție
Sunt multe situațiile în care vrem să determinăm un interval de încredere pentru o proporție, de exemplu în cazul unui sondaj aleator dorim să determinăm un interval de încredere de nivel \(95\%\) pentru proporția \(p\) a persoanelor care verifică o anumită proprietate de interes (e.g. au votat cu partidul X). În acest contex avem \(X_1, \ldots, X_n\) un eșantion de talie \(n\) dintr-o populație Bernoulli \(\mathcal{B}(p)\) cu \(p\) necunoscut. Din Teorema Limită Centrală știm că
\[ \sqrt{n}\frac{\bar X_n - p}{\sqrt{p(1-p)}} \overset{d}{\to}\mathcal{N}(0,1) \]
ceea ce implică, pentru \(n\) suficient de mare (în practică \(\geq 30\)), că
\[ \mathbb{P}_{\mu}\left(-z_{1-\frac{\alpha}{2}}\leq \sqrt{n}\frac{\bar X_n - p}{\sqrt{p(1-p)}}\leq z_{1 - \frac{\alpha}{2}}\right)\approx 1-\alpha. \]
Cantitatea \(\sqrt{n}\frac{\bar X_n - p}{\sqrt{p(1-p)}}\) se poate pivota în raport cu \(\theta\) și rezolvând inecuația de ordin \(2\) în \(p\)
\[ n\frac{\left(\bar X_n - p\right)^2}{p(1-p)}\leq z_{1-\frac{\alpha}{2}}^2 \]
găsim un interval de încredere asimptotic de forma
\[ \begin{aligned} IC^{1-\alpha}(\theta) &= \left[\frac{\bar X_n + \frac{z_{1-\frac{\alpha}{2}}^2}{2n}}{1 + \frac{z_{1-\frac{\alpha}{2}}^2}{n}} - \frac{1}{1 + \frac{z_{1-\frac{\alpha}{2}}^2}{n}}\sqrt{\frac{z_{1-\frac{\alpha}{2}}^2}{n}\bar X_n(1-\bar X_n) + \frac{z_{1-\frac{\alpha}{2}}^4}{4n^2}},\right.\\ &\quad\left.\frac{\bar X_n + \frac{z_{1-\frac{\alpha}{2}}^2}{2n}}{1 + \frac{z_{1-\frac{\alpha}{2}}^2}{n}} + \frac{1}{1 + \frac{z_{1-\frac{\alpha}{2}}^2}{n}}\sqrt{\frac{z_{1-\frac{\alpha}{2}}^2}{n}\bar X_n(1-\bar X_n) + \frac{z_{1-\frac{\alpha}{2}}^4}{4n^2}}\right]. \end{aligned} \]
Eliminând termenii de ordin \(\frac{1}{n^2}\) de sub radical și pe cei de ordin \(\frac{1}{n}\) din afara radicalului găsim exact intervalul de încredere asimptotic pe care l-am fi obținut dacă aplicam metoda lui Wald:
\[ IC^{1-\alpha}(\theta) = \left[\bar X_n - z_{1-\frac{\alpha}{2}}\sqrt{\frac{\bar X_n(1-\bar X_n)}{n}}, \bar X_n + z_{1-\frac{\alpha}{2}}\sqrt{\frac{\bar X_n(1-\bar X_n)}{n}}\right]. \]
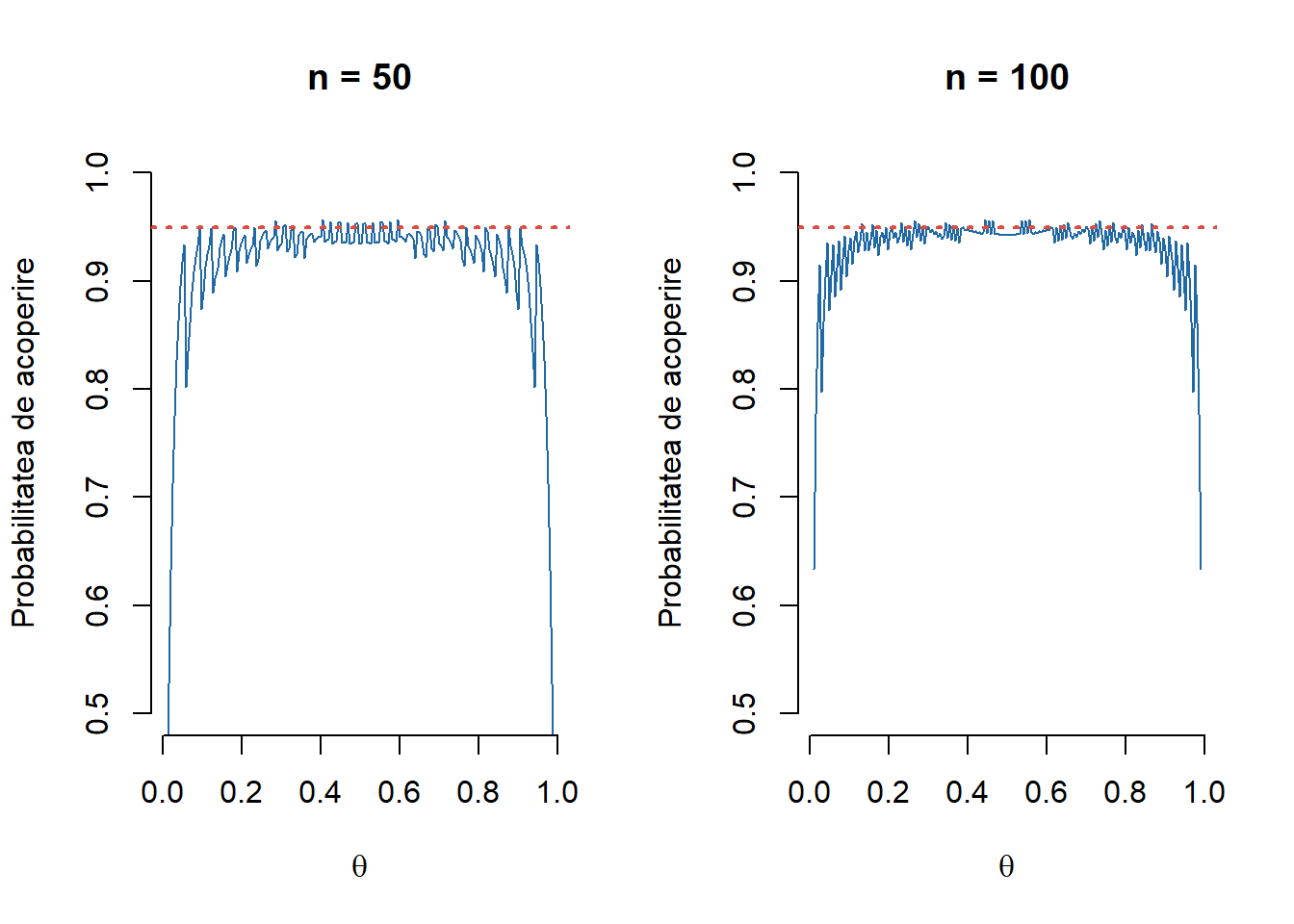
Probabilitatea de acoperire este:
Arată codul R din exemplul de mai sus
binom.wald.cvg <- function(theta, n, alpha) {
z <- qnorm(1 - alpha / 2)
f <- function(p) {
t <- 0:n
s <- sqrt(t * (n - t) / n)
o <- (t - z * s <= n * p & t + z * s >= n * p)
return(sum(o * dbinom(t, size = n, prob = p)))
}
out <- sapply(theta, f)
return(out)
}
# date intrare
par(mfrow = c(1,2))
n <- 50
alpha <- 0.05
theta <- seq(0.01, 0.99, len=200)
plot(theta, binom.wald.cvg(theta, n, alpha),
ylim=c(0.5, 1), type="l", lwd=1,
bty = "n",
col = myblue,
main = paste0("n = ", n),
xlab = expression(theta),
ylab = "Probabilitatea de acoperire")
abline(h = 1-alpha, lty=3, lwd=2,
col = myred)
# al doilea grafic
n <- 100
plot(theta, binom.wald.cvg(theta, n, alpha),
ylim=c(0.5, 1), type="l", lwd=1,
bty = "n",
col = myblue,
main = paste0("n = ", n),
xlab = expression(theta),
ylab = "Probabilitatea de acoperire")
abline(h = 1-alpha, lty=3, lwd=2,
col = myred)