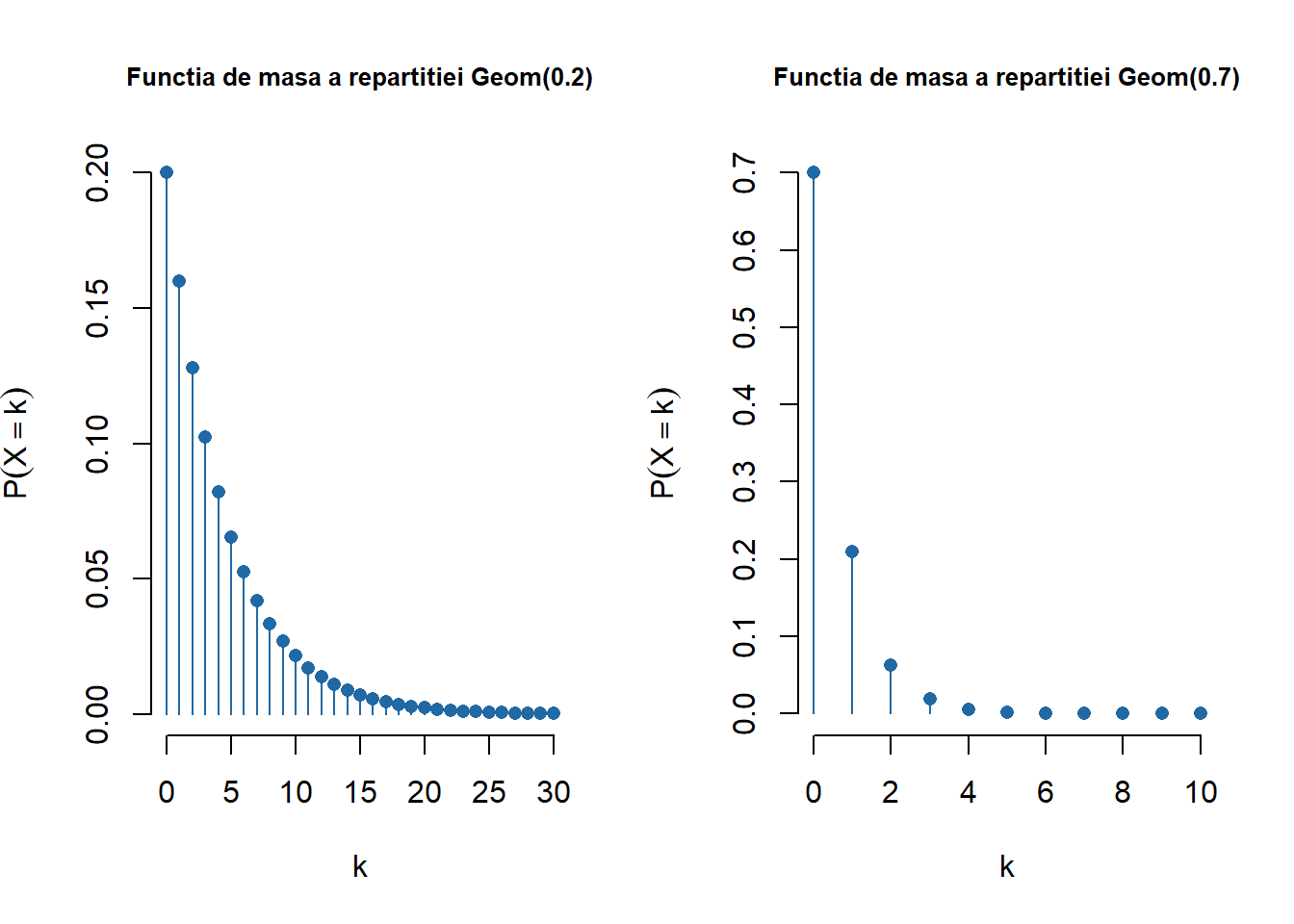
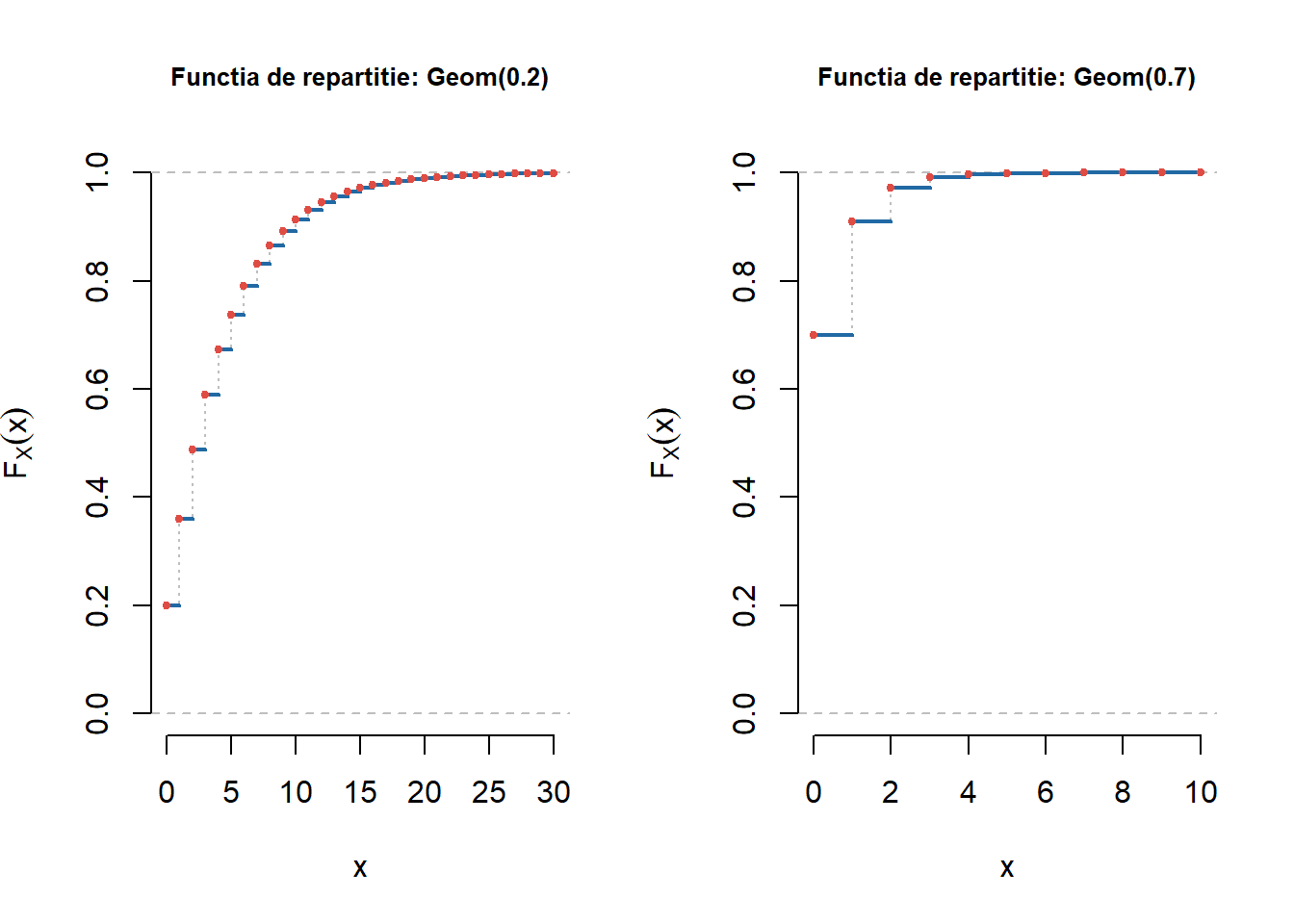
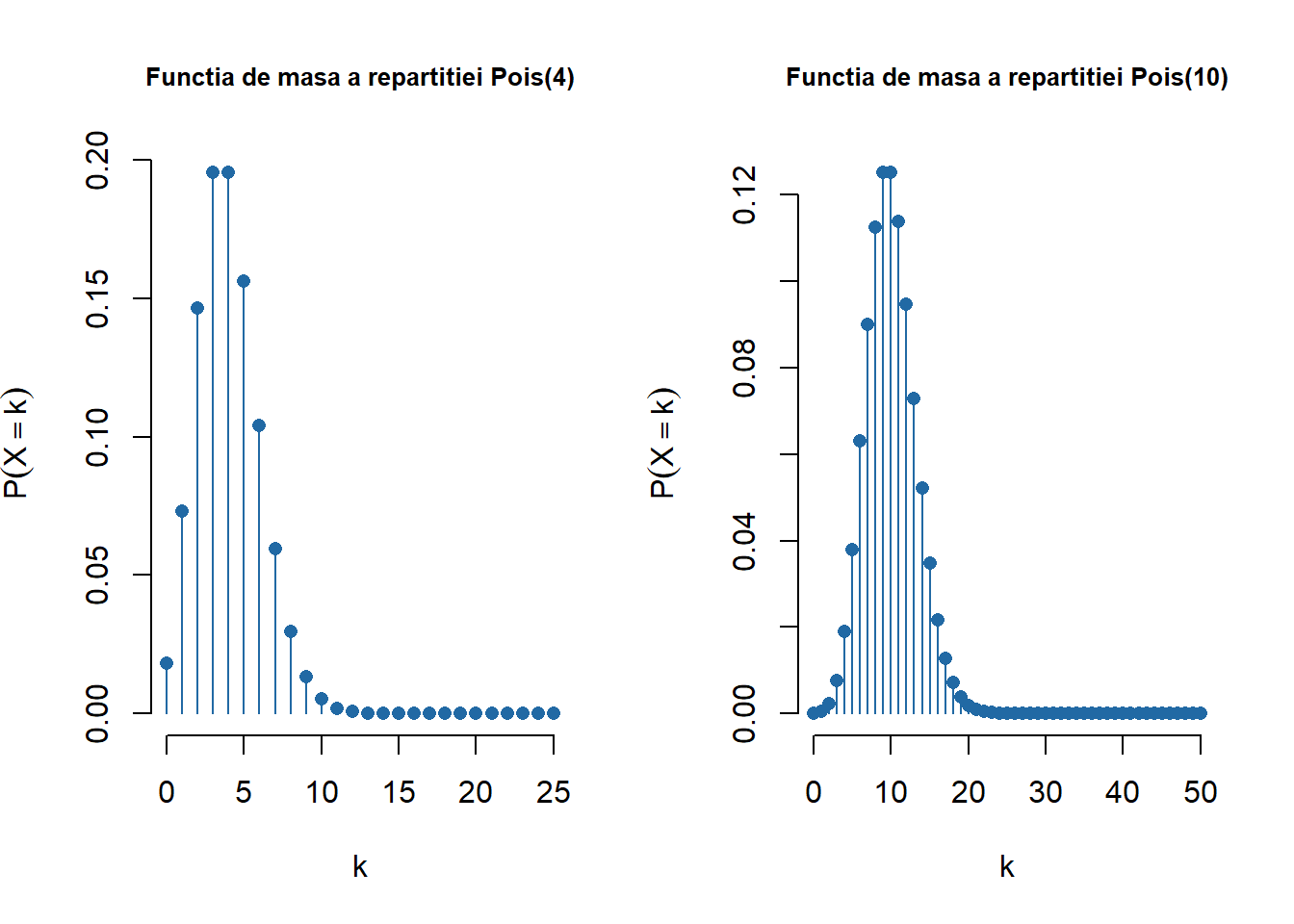
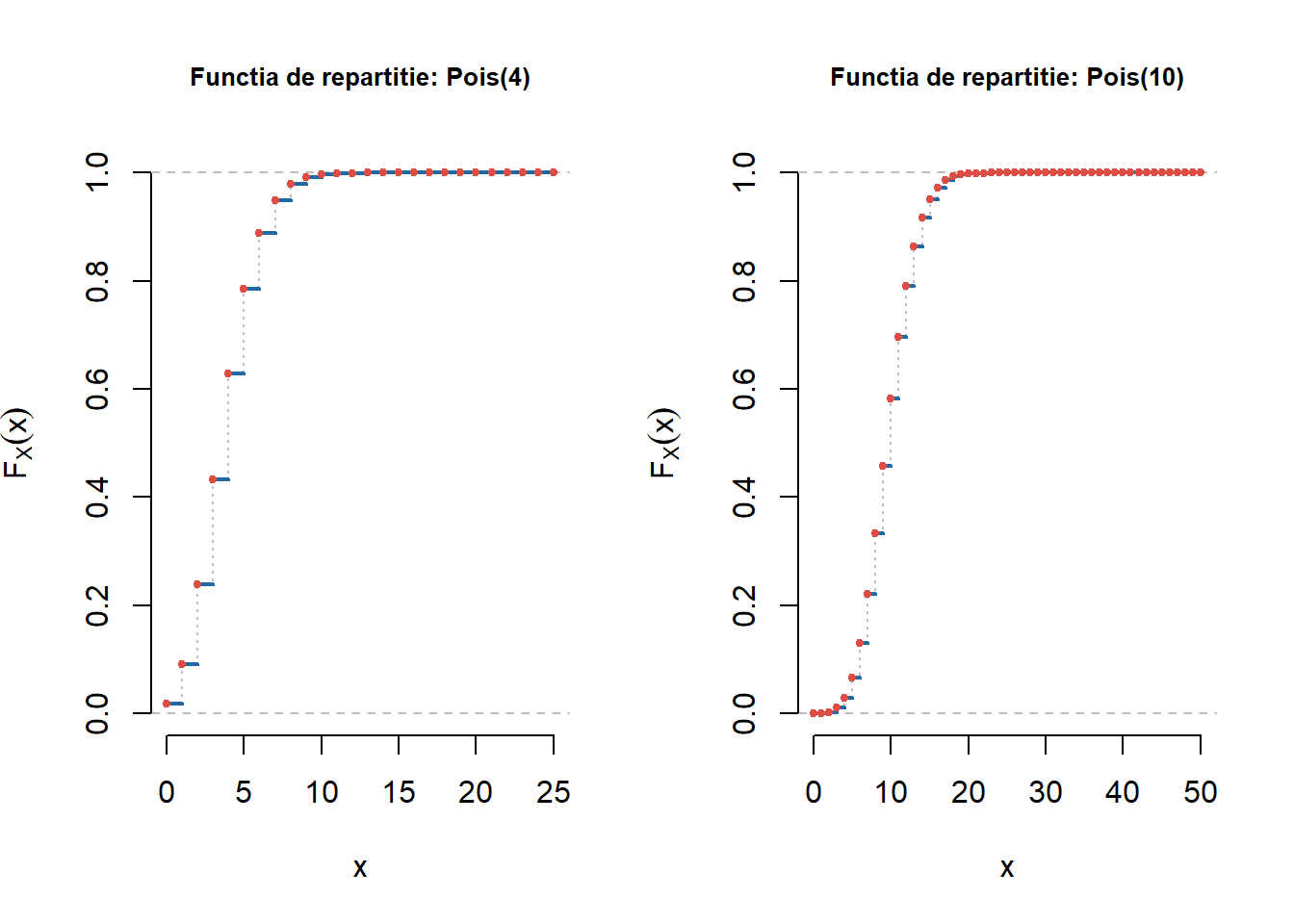
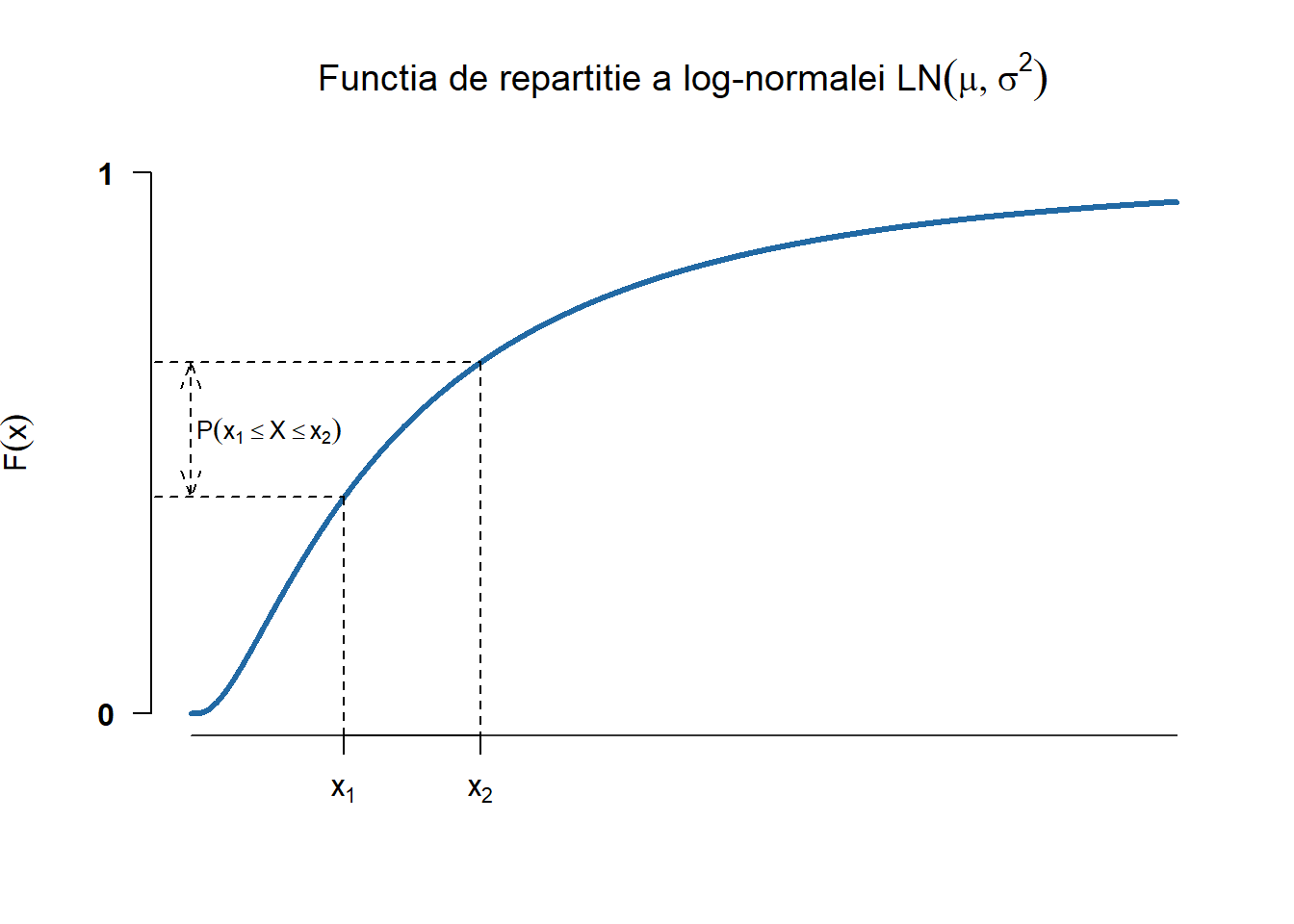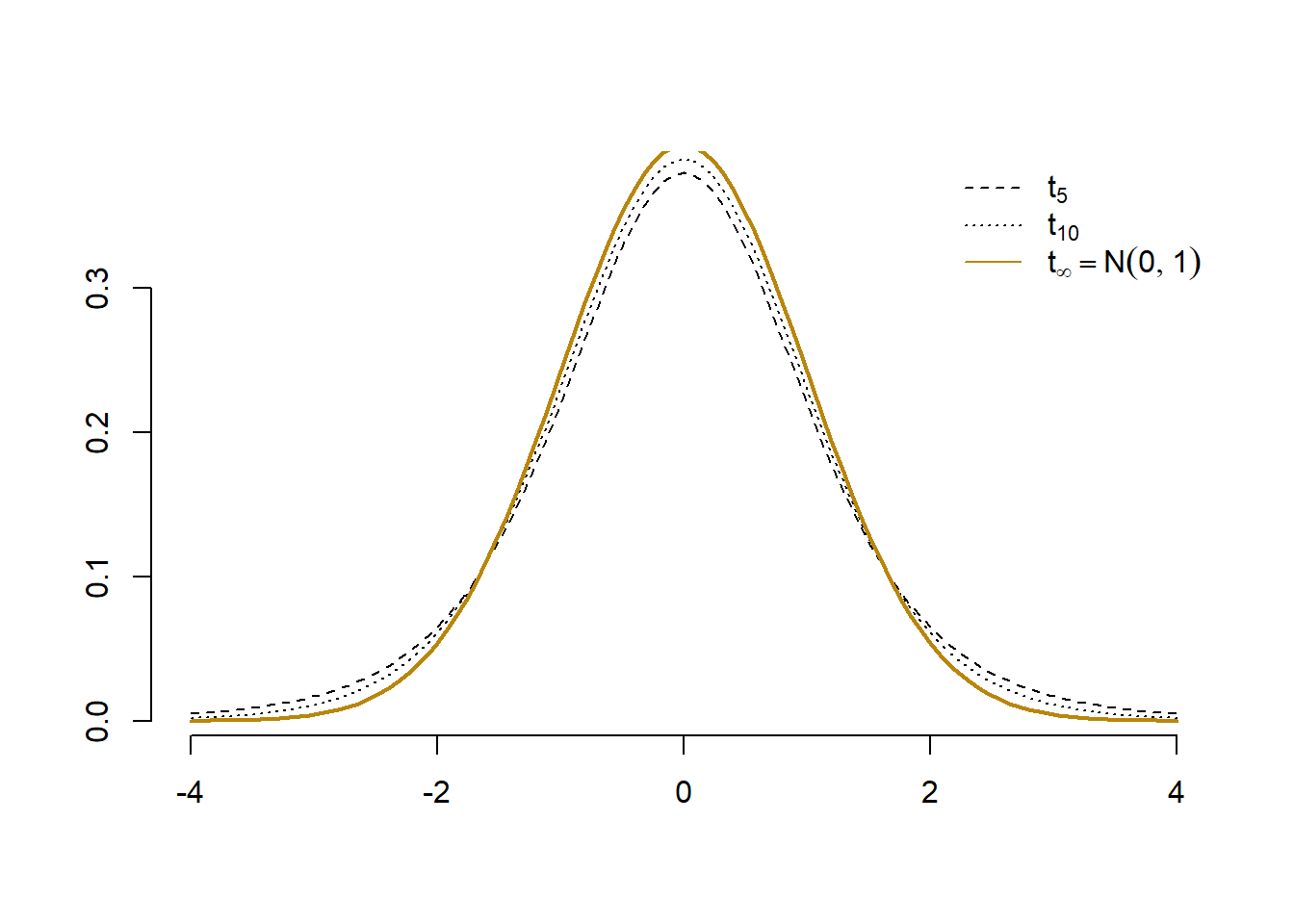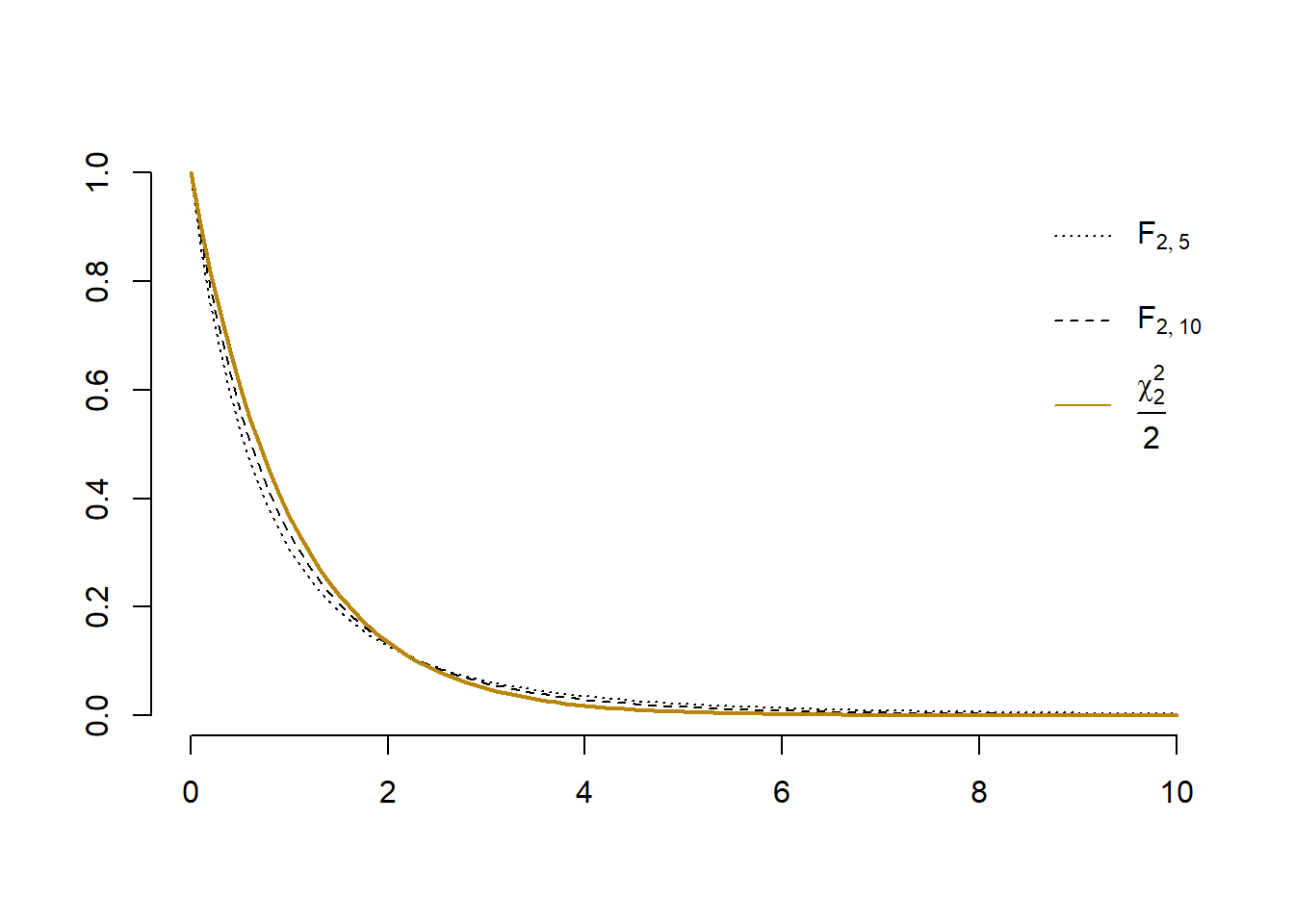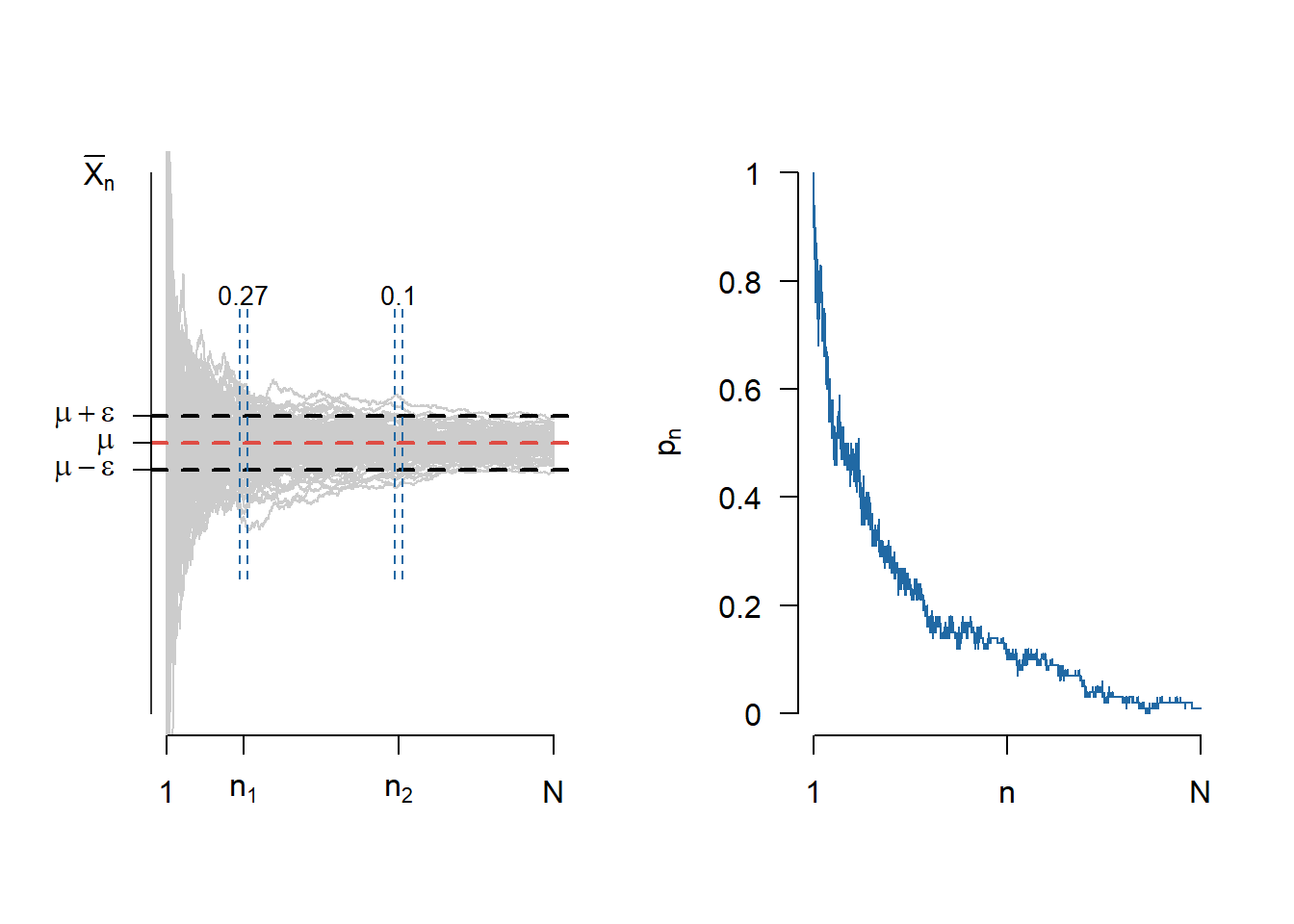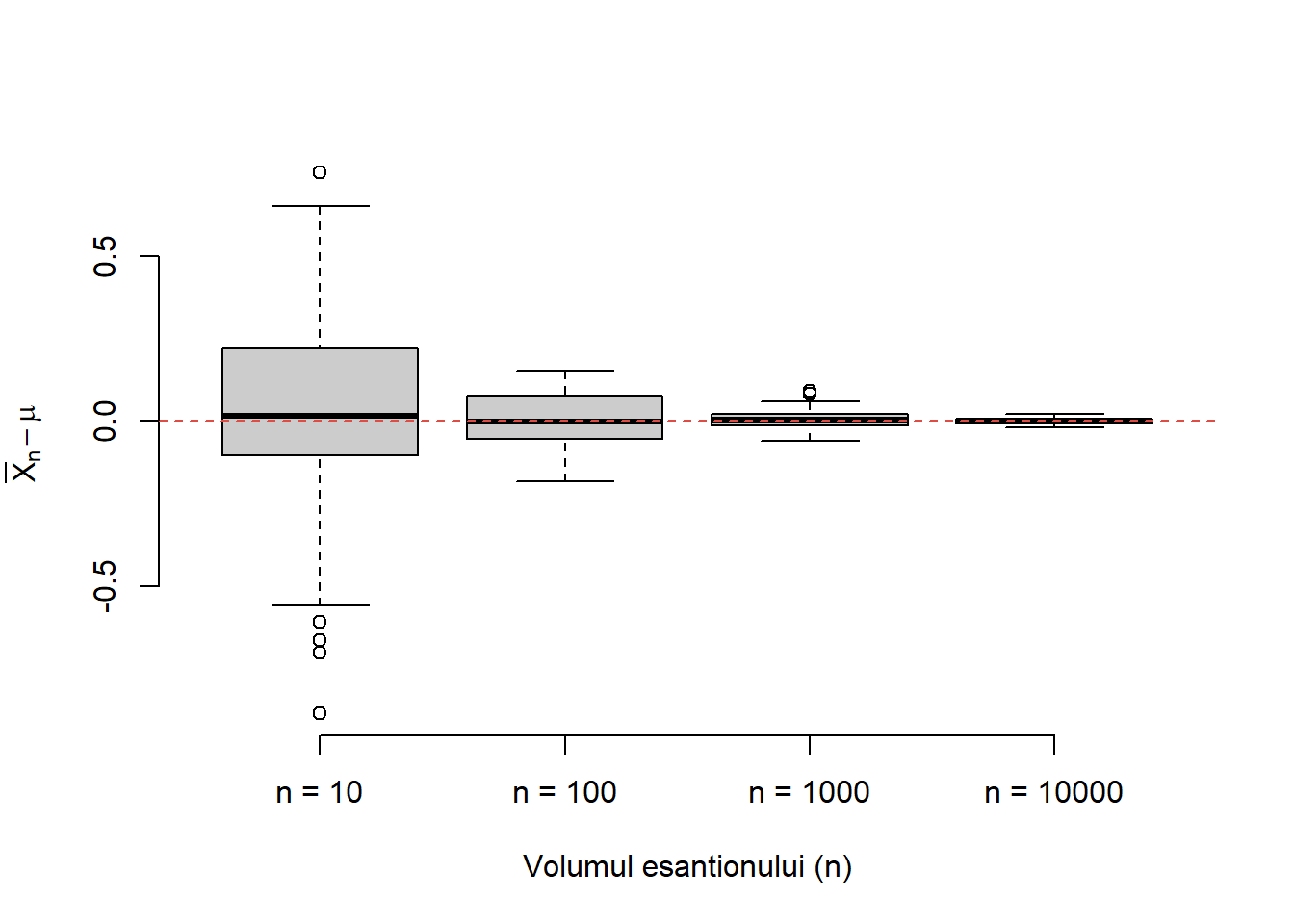Notă! Au fost adăugate proiectele (grupa 301 și grupele 311 și 321) și o serie de exerciții propuse (detalii) care să vină în sprijinul pregătirii examenului.
Elemente de probabilități în R
Note de laborator
Scopul acestor note de laborator este de a introduce, prin intermediul programului R, principalele repartiții discrete și continue folosite la curs. Sunt prezentate de asemenea și o serie de aplicații ale rezultatelor asimptotice principale: Legea Numerelor Mari și Teorema Limită Centrală.
Variabile aleatoare discrete
Limbajul R pune la dispoziție majoritatea repartițiilor discrete folosite în mod uzual. Tabelul de mai jos prezintă numele, parametrii acestora precum și funcția de masă corespunzătoare:
Tabelul 1.1: Numele și parametrii repartițiilor discrete uzuale în R.
Pentru fiecare repartiție, există patru comenzi în R prefixate cu literele d, p, q și r și urmate de numele repartiției (coloana a 2-a). De exemplu dbinom, pbinom, qbinom și rbinom sunt comenzile corespunzătoare repartiției binomiale pe când dgeom, pgeom, qgeom și rgeom sunt cele corespunzătoare repartiției geometrice.
dname: calculează densitatea atunci când vorbim de o variabilă continuă sau funcția de masă atunci când avem o repartiție discretă (\(\mathbb{P}(X=x)\))
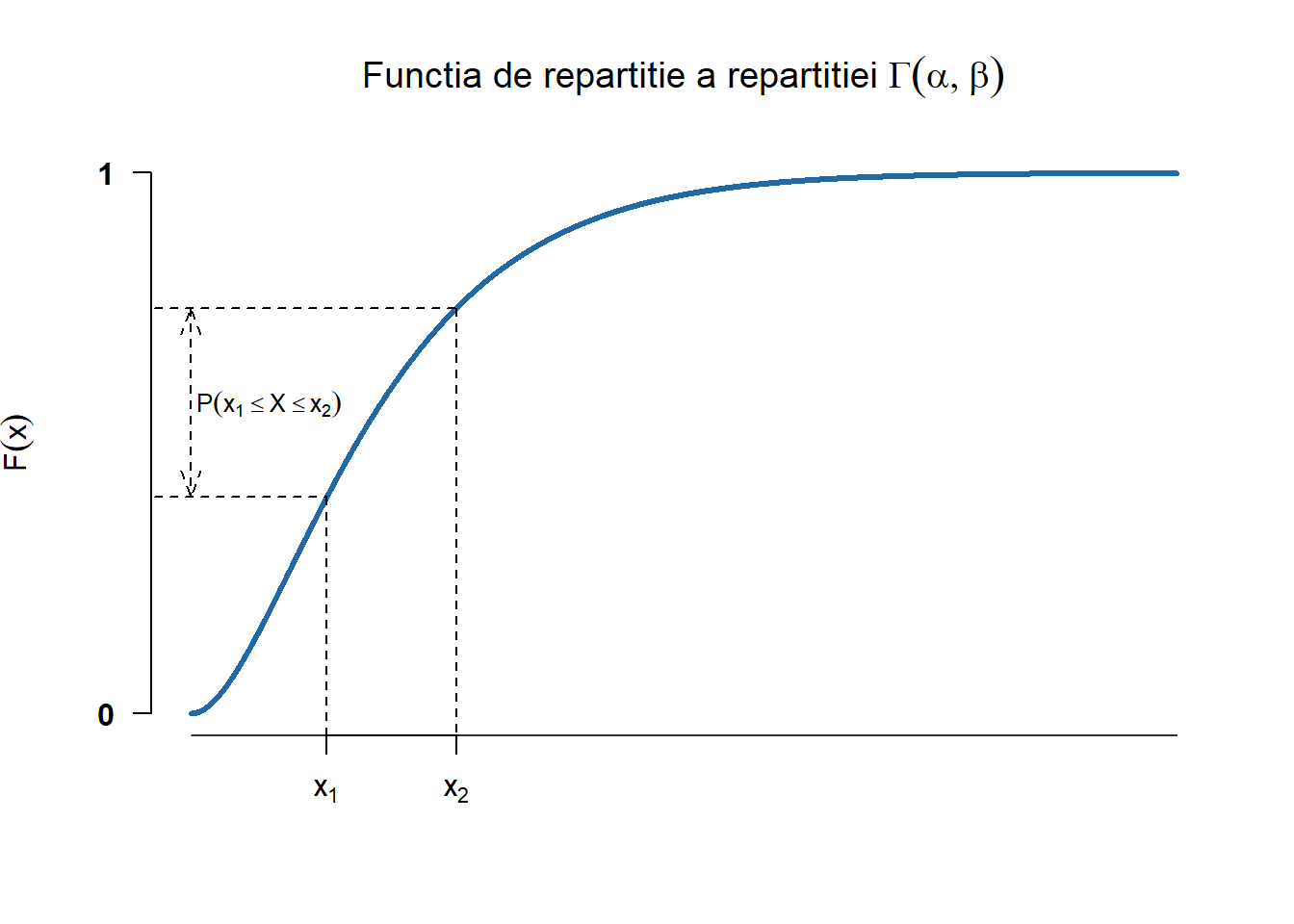
pname: calculează funcția de repartiție, i.e. \(F(x)=\mathbb{P}(X\leq x)\)
qname: reprezintă funcția cuantilă, cu alte cuvinte valoarea pentru care funcția de repartiție are o anumită probabilitate; în cazul continuu, dacă pname(x) = p atunci qname(p) = x iar în cazul discret întoarce cel mai mic întreg \(u\) pentru care \(\mathbb{P}(X\leq u)\geq p\).
rname: generează observații independente din repartiția dată
Avem următoarele exemple:
# Functia de repartitie pentru binomialapbinom(c(3,5), size =10, prob =0.5)
[1] 0.1718750 0.6230469
# Genereaza observatii din repartitia binomialarbinom(5, size =10, prob =0.5)
[1] 3 5 2 5 3
# Calculeaza functia de masa in diferite punctedbinom(0:7, size =10, prob =0.3)
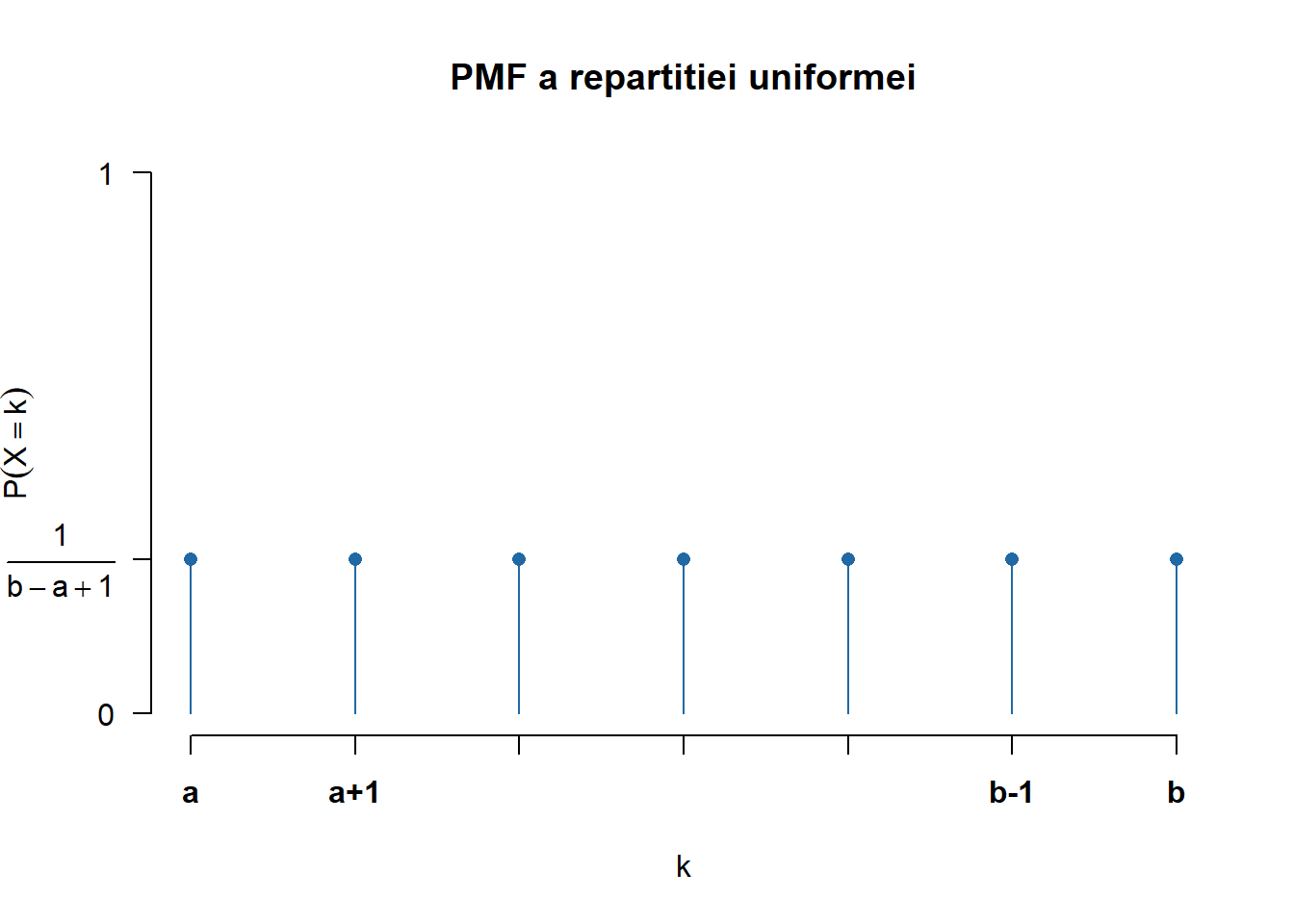
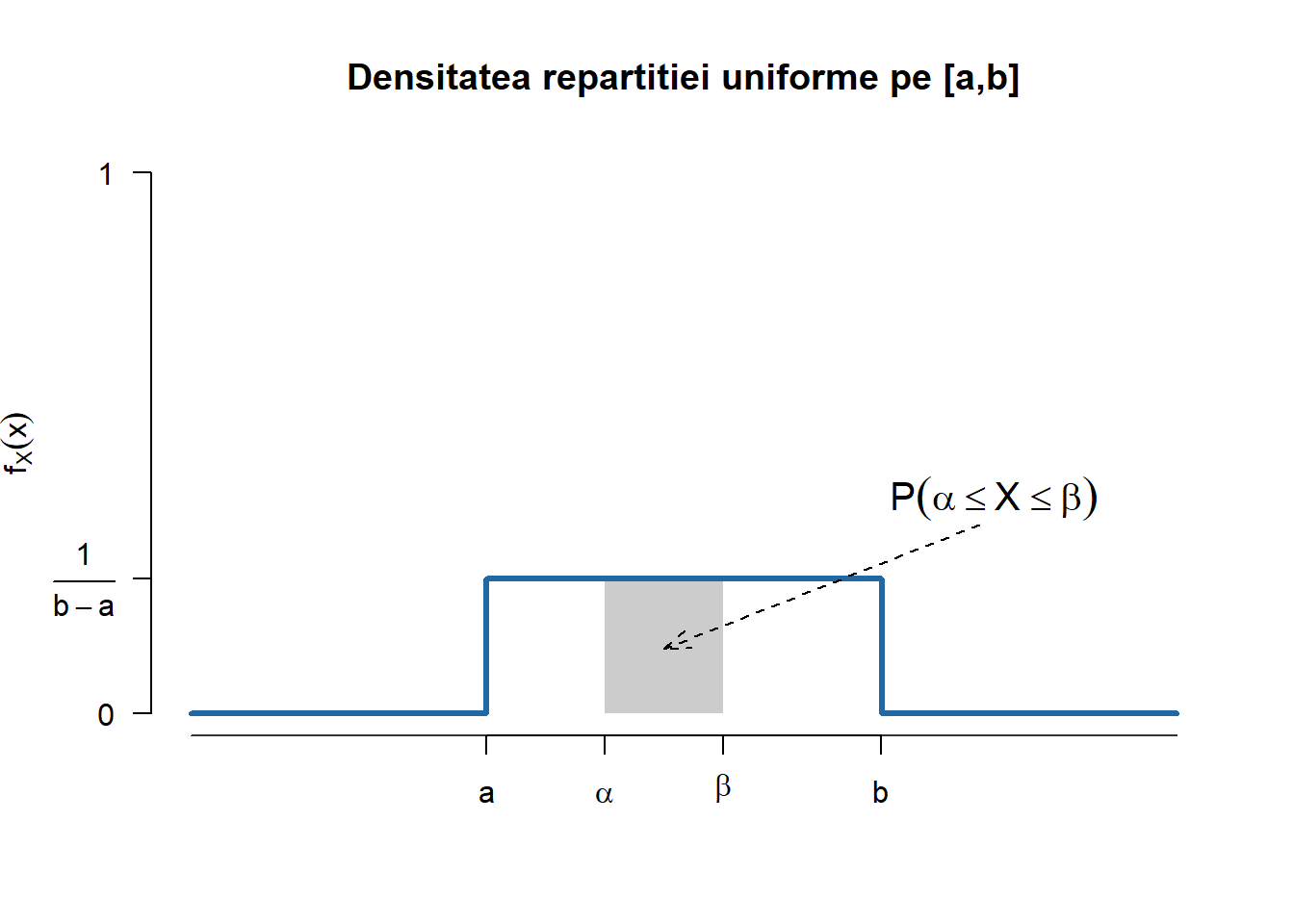
O variabilă aleatoare \(X\) este repartizată uniform pe mulțimea \(\{a, a+1, \ldots, b\}\), și se notează \(X\sim\mathcal{U}(\{a, a+1, \ldots, b\})\), are funcția de masă (PMF - probability mass function) dată de
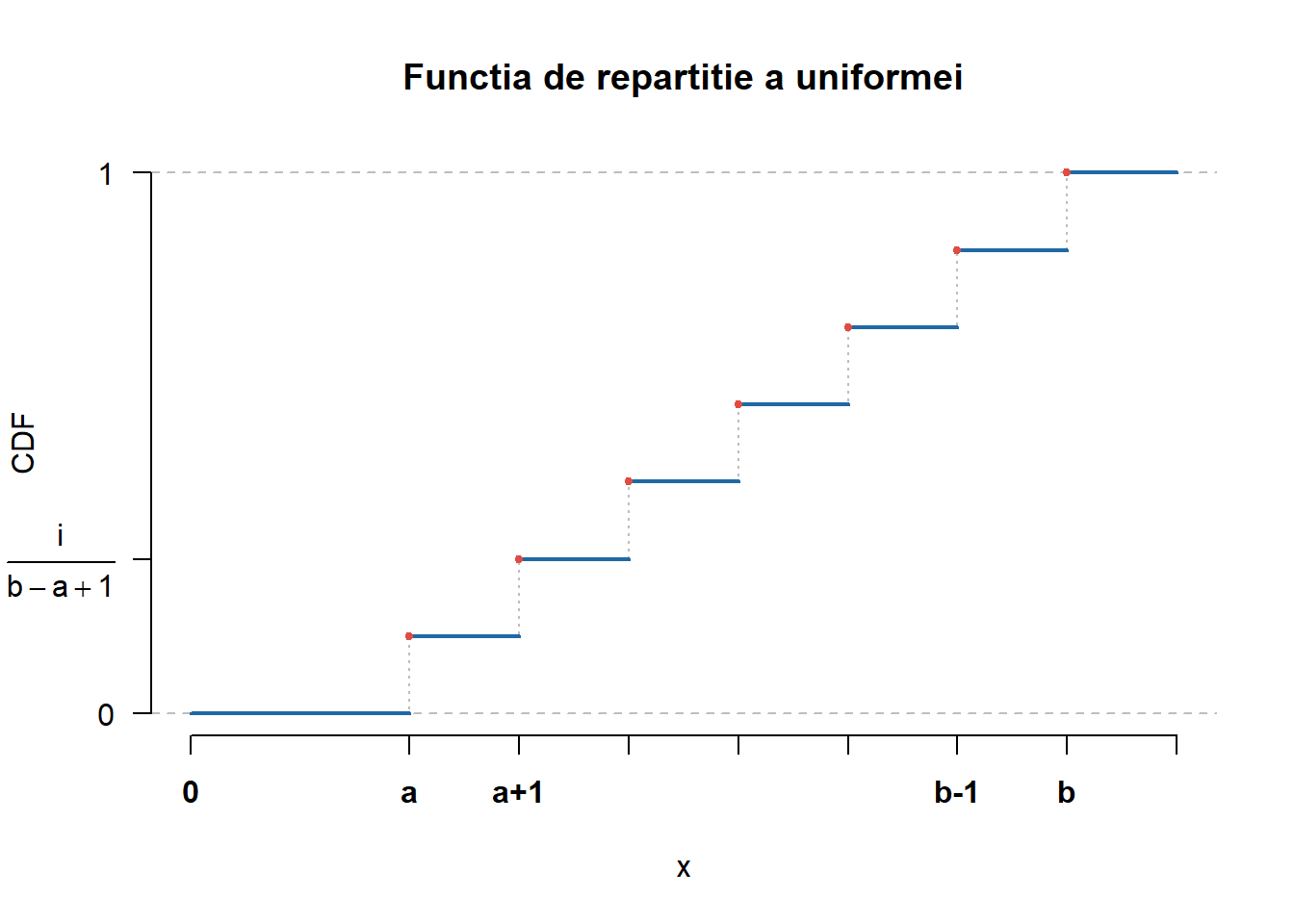
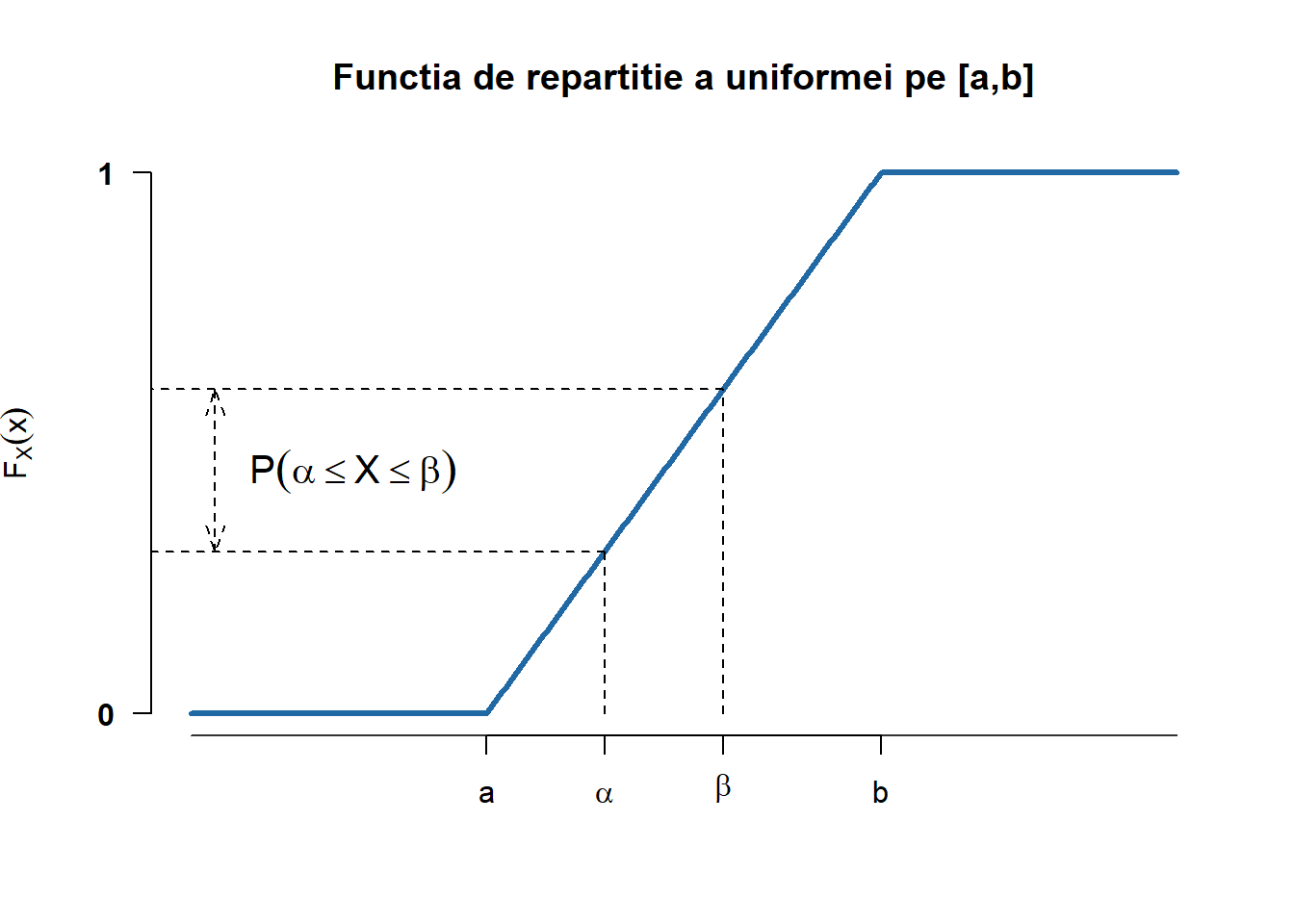
Funcția de repartiție a repartiției uniforme \(\mathcal{U}(\{a, a+1, \ldots, b\})\) este dată de
\[
F_{X}(x) = \mathbb{P}(X \leq x) = \frac{\lfloor x\rfloor - a + 1}{b - a + 1}, \quad x\in[a,b].
\]
(a) Densitatea
(b) Funcția de repartiție
Figura 1.1: Densitatea și funcția de repartiție a repartiției uniforme pe mulțimea \(\{a, a+1, \ldots, b\}\).
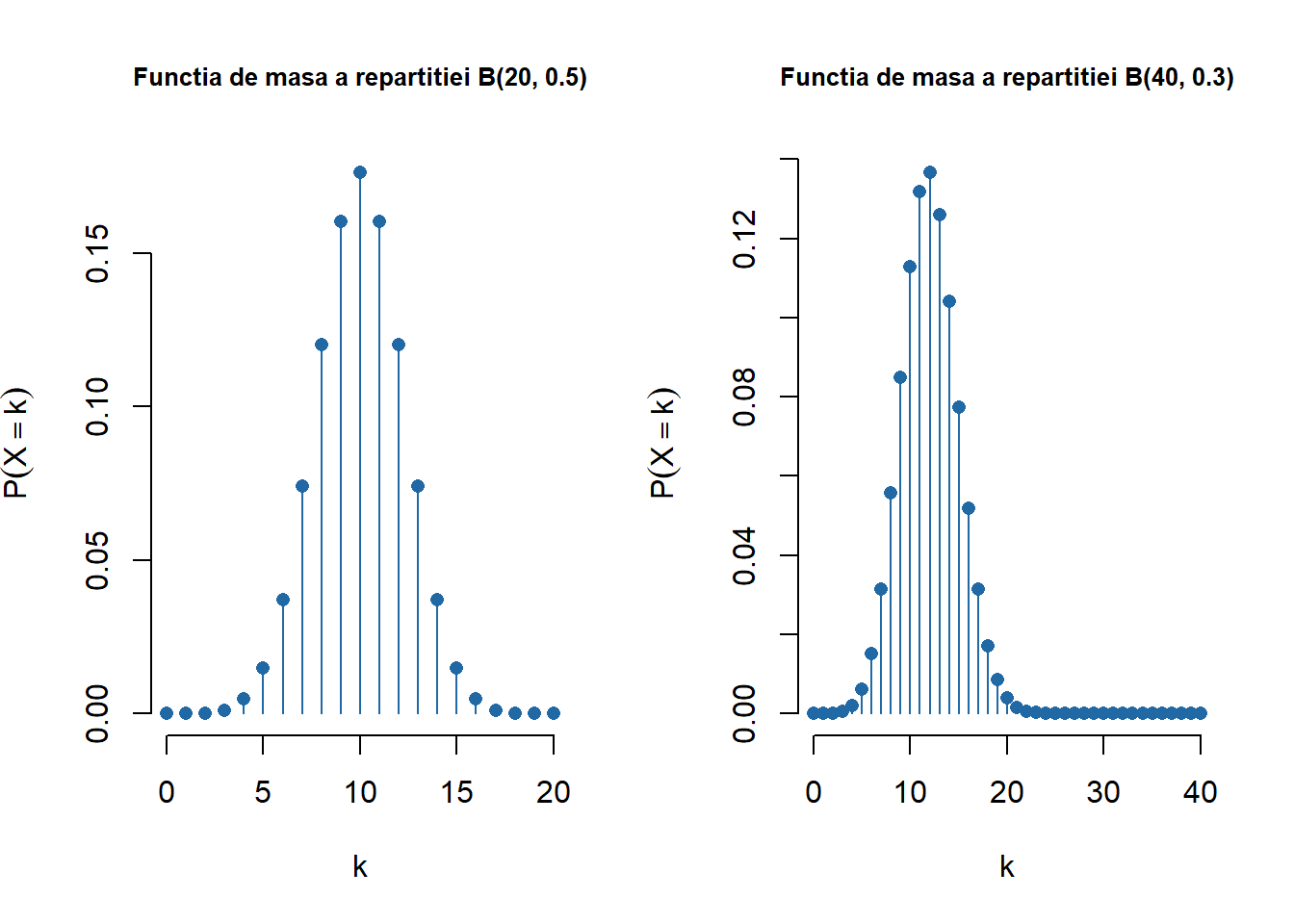
Repartiția binomială \(\mathcal{B}(n, p)\)
Spunem că variabila aleatoare \(X\) este repartizată binomial de parametrii \(n\geq 1\) și \(p\in[0,1]\), și se notează cu \(X\sim\mathcal{B}(n,p)\), dacă funcția de masă este
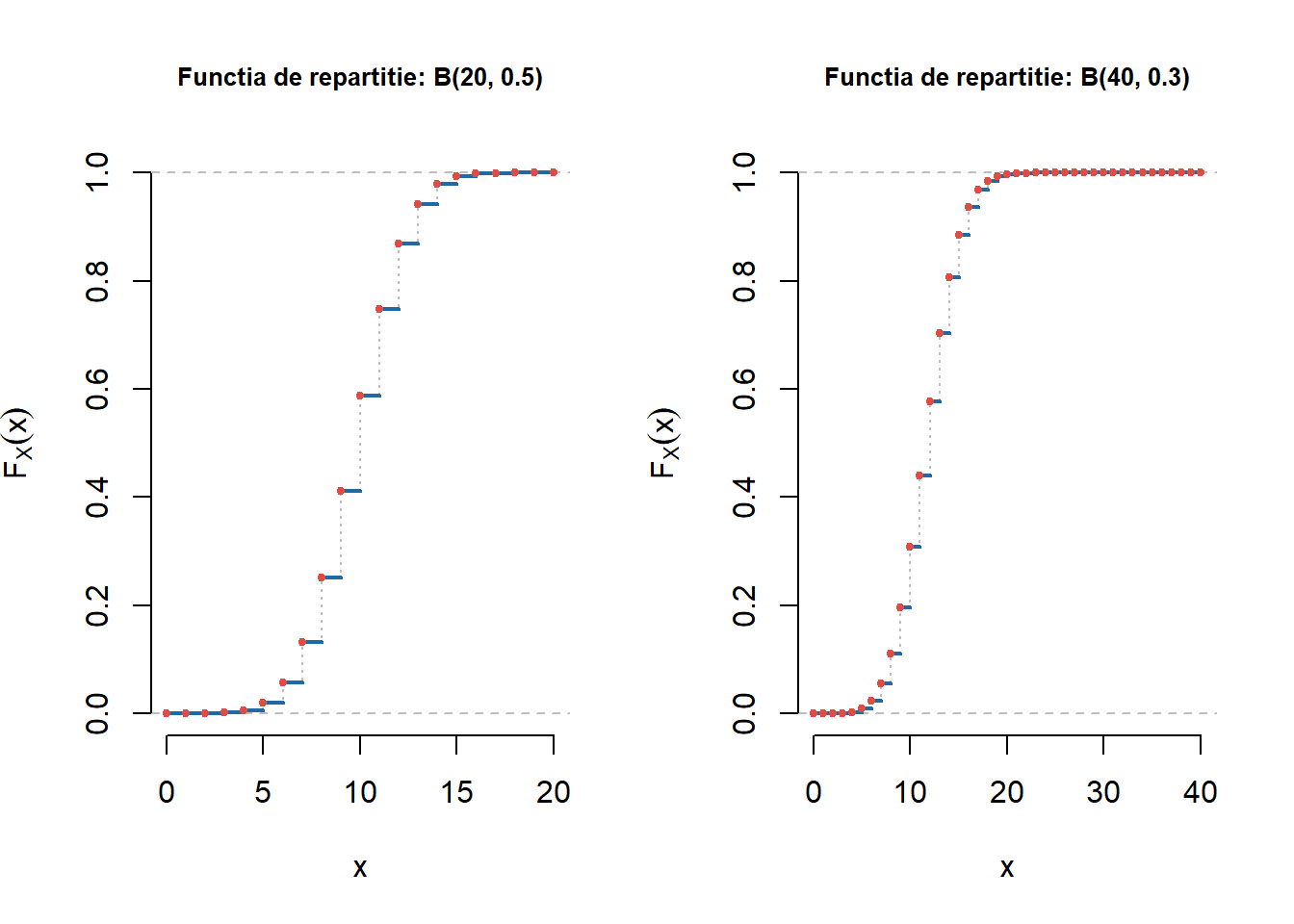
care în cazul exemplelor considerate mai sus devine
Figura 1.7: Ilustrarea funcțiilor de repartiție pentru repartițiile Poisson \(\mathrm{Pois}(4)\) și \(\mathrm{Pois}(10)\).
În exemplele anterioare am folosit două funcții pentru trasarea funcției de masă respectiv a funcției de repartiție.
Exercițiul 1.1 Construiți câte o funcție în R care să traseze graficul funcției de masă respectiv a funcției de repartiție a unei distribuții date. Verificați și documentația funcției ecdf.
Pentru funcția de masă avem următorul cod:
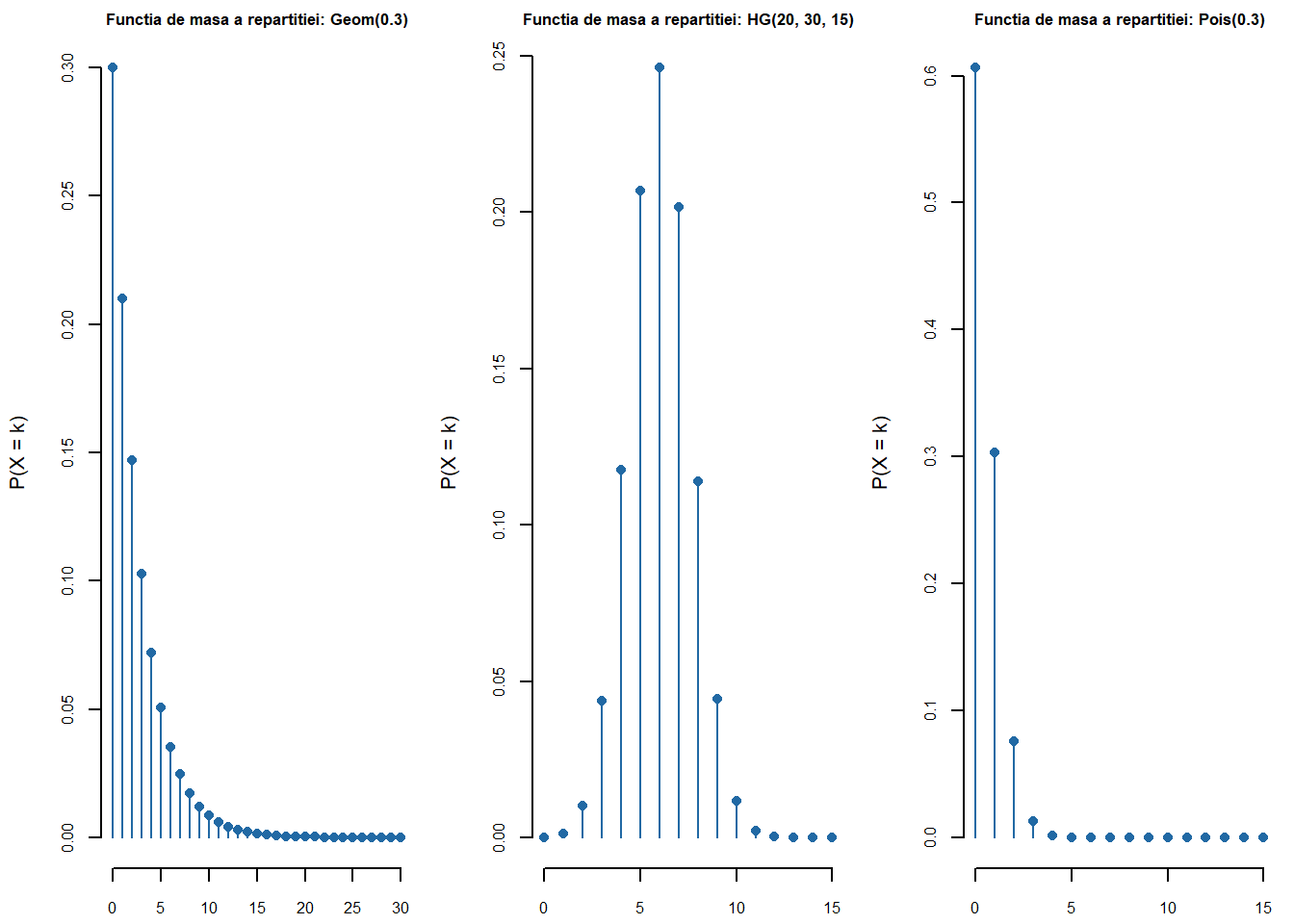
pmfPlot <-function(x =0:25, dist =dpois(0:25, 4), title ="", ...){plot(x, dist,type ="h", col = myblue, xlab ="k",ylab ="P(X = k)",main =paste0("Functia de masa a repartitiei: ", title),cex.main =0.8,bty ="n")points(x, dist, pch =16, col = myblue)}
Ilustrăm funcția pentru repartițiile discrete: \(\mathrm{Geom}(0.3)\), \(\mathcal{HG}(20, 30, 15)\) și \(\mathrm{Pois}(0.5)\)
Figura 1.8: Ilustrarea funcțiilor de masă pentru \(\mathrm{Geom}(0.3)\), \(\mathcal{HG}(20, 30, 15)\) și \(\mathrm{Pois}(0.5)\).
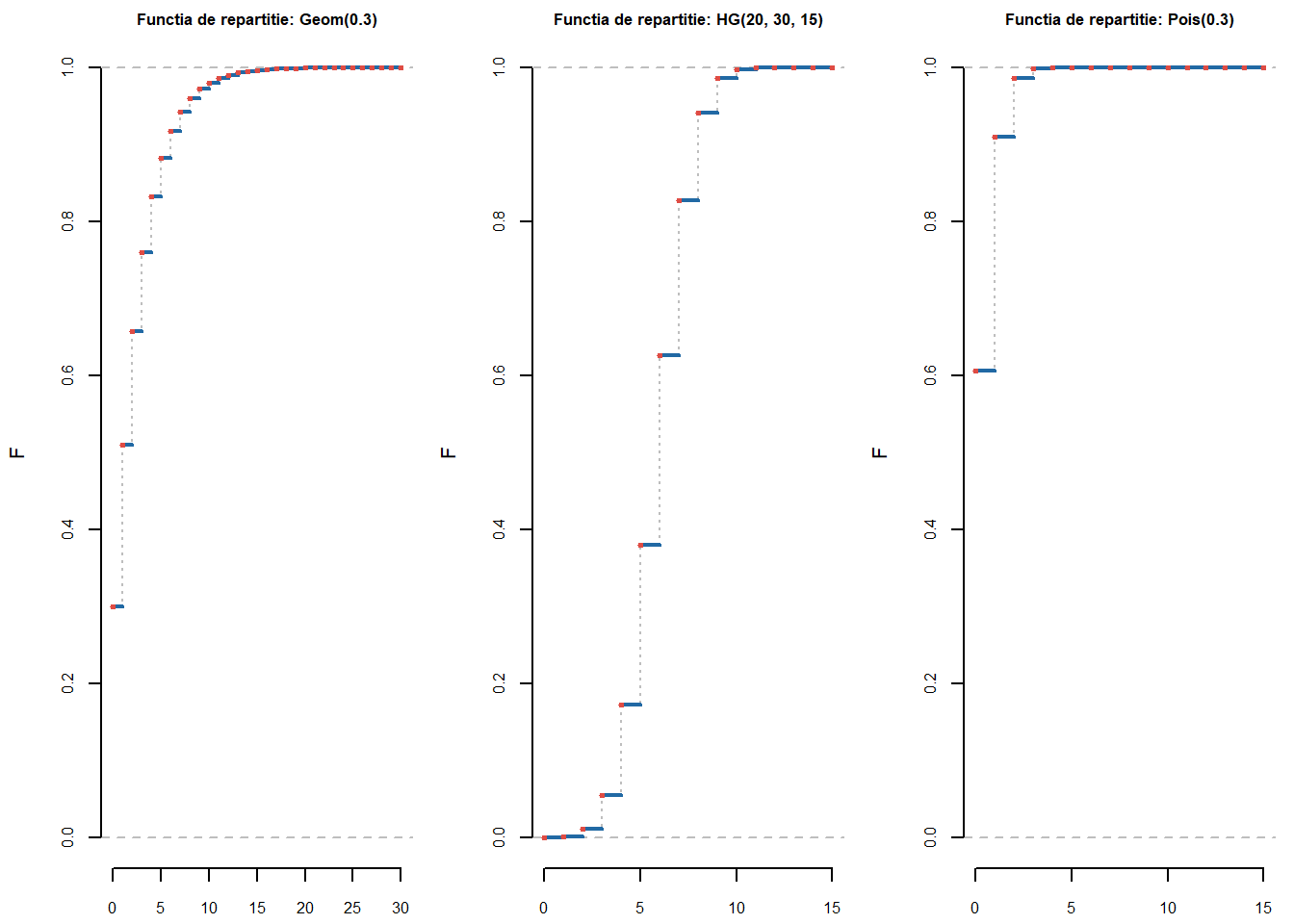
Pentru funcția de repartiție avem următorul cod:
cdfPlot <-function(dist, title, err =1e-5, ...){# dist - repartitia discreta (sau discretizata) lp <-length(dist)if (abs(sum(dist)-1)>err |sum(dist>=0)!=lp){stop("Eroare: vectorul de probabilitati nu formeaza o repartitie") }else{ x <-0:(lp-1) # ia valori in 1:lp cp <-cumsum(dist)plot(x, cp, type ="s", lty =3, xlab ="x", ylab ="F", main =paste("Functia de repartitie:", title), ylim =c(0,1), col ="grey",bty ="n", ...)abline(h =0, lty =2, col ="grey")abline(h =1, lty =2, col ="grey")for(i in1:(lp-1)){lines(c(x[i], x[i+1]), c(cp[i], cp[i]), col = myblue,lwd =2) }points(x,cp, col = myred, pch =20, cex =0.85) }}
Pentru a testa această funcție să considerăm ca repartiții discrete: \(\mathrm{Geom}(0.3)\), \(\mathcal{HG}(20, 30, 15)\) și \(\mathrm{Pois}(0.5)\):
Figura 1.9: Ilustrarea funcțiilor de repartiție pentru \(\mathrm{Geom}(0.3)\), \(\mathcal{HG}(20, 30, 15)\) și \(\mathrm{Pois}(0.5)\).
Aproximarea Poisson și Normală a Binomialei
Exercițiul 1.2 Ilustrați grafic aproximarea Poisson și normală a repartiției binomiale.
Scopul acestui exercițiu este de a ilustra grafic aproximarea legii binomiale cu ajutorul repartiției Poisson și a repartiției normale.
Pentru o v.a. \(X\) repartizată binomial de parametrii \(n\) și \(p\) (\(q = 1-p\)) funcția de masă este
Dacă \(n\to\infty\) (\(n\) este mare) și \(p\to 0\) (\(p\) este mic, evenimentele sunt rare) așa încât \(np\to\lambda\) atunci se poate verifica cu ușurință că
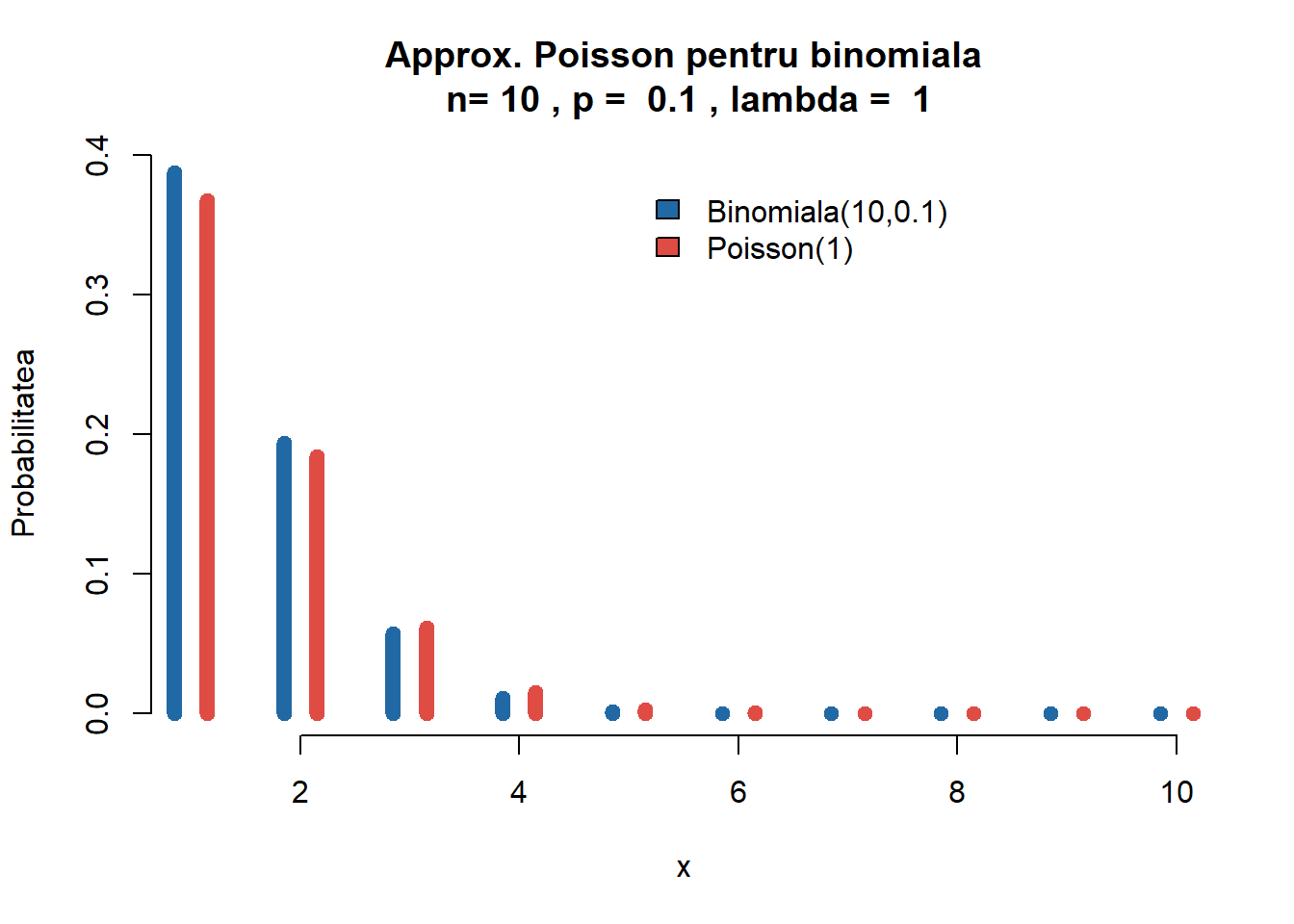
Pentru a ilustra acuratețea acestei aproximări vom folosi instrucțiunile Rdbinom și dpois care permit calcularea funcțiilor de masă \(f_{n,p}(k)\) și \(f_{\lambda}(k)\).
AppBP <-function(n,p,a,b){ lambda <- n*p x <-matrix(numeric((b-a+1)*3),ncol=3,dimnames =list(a:b,c("Binomiala","Poisson","Eroarea Absoluta"))) x[,1] <-dbinom(a:b,n,p) x[,2] <-dpois(a:b,lambda) x[,3] <-abs(x[,1]-x[,2]) error <-max(abs(x[,3]))return(list(x =as.data.frame(x), error = error, param =c(n, p, lambda)))}# Functie care ilustreaza aproximarea Binomial vs. Poissonpl <-function(n,p,a,b){ clr =c(myblue, myred)# culori lambda = n*p mx =max(dbinom(a:b,n,p))plot(c(a:b,a:b), c(dbinom(a:b,n,p), dpois(a:b,lambda)), type="n", main =paste("Approx. Poisson pentru binomiala\n n=", n, ", p = ", p, ", lambda = ",lambda), ylab ="Probabilitatea", xlab="x",bty ="n")points((a:b)-.15, dbinom(a:b,n,p), type ="h",col = clr[1], lwd =8)points((a:b)+.15, dpois(a:b,lambda), type ="h",col = clr[2], lwd =8)legend(b-b/2, mx, legend =c(paste0("Binomiala(",n,",",p,")"),paste0("Poisson(",lambda,")")), fill = clr, bg="white",bty ="n")}
Pentru setul de parametrii \(n=10\) și \(p=0.1\) avem următorul tabel și următoarea figură
Tabelul 1.2: Exemplificare de aproximare Poisson a binomialei
k
Binomiala
Poisson
Eroarea Absoluta
1
0.3874205
0.3678794
0.0195410
2
0.1937102
0.1839397
0.0097705
3
0.0573956
0.0613132
0.0039176
4
0.0111603
0.0153283
0.0041680
5
0.0014880
0.0030657
0.0015776
6
0.0001378
0.0005109
0.0003732
7
0.0000087
0.0000730
0.0000642
8
0.0000004
0.0000091
0.0000088
9
0.0000000
0.0000010
0.0000010
10
0.0000000
0.0000001
0.0000001
Figura 1.10: Ilustrarea aproximării Poisson pentru \(\mathcal{B}(10, 0.1)\).
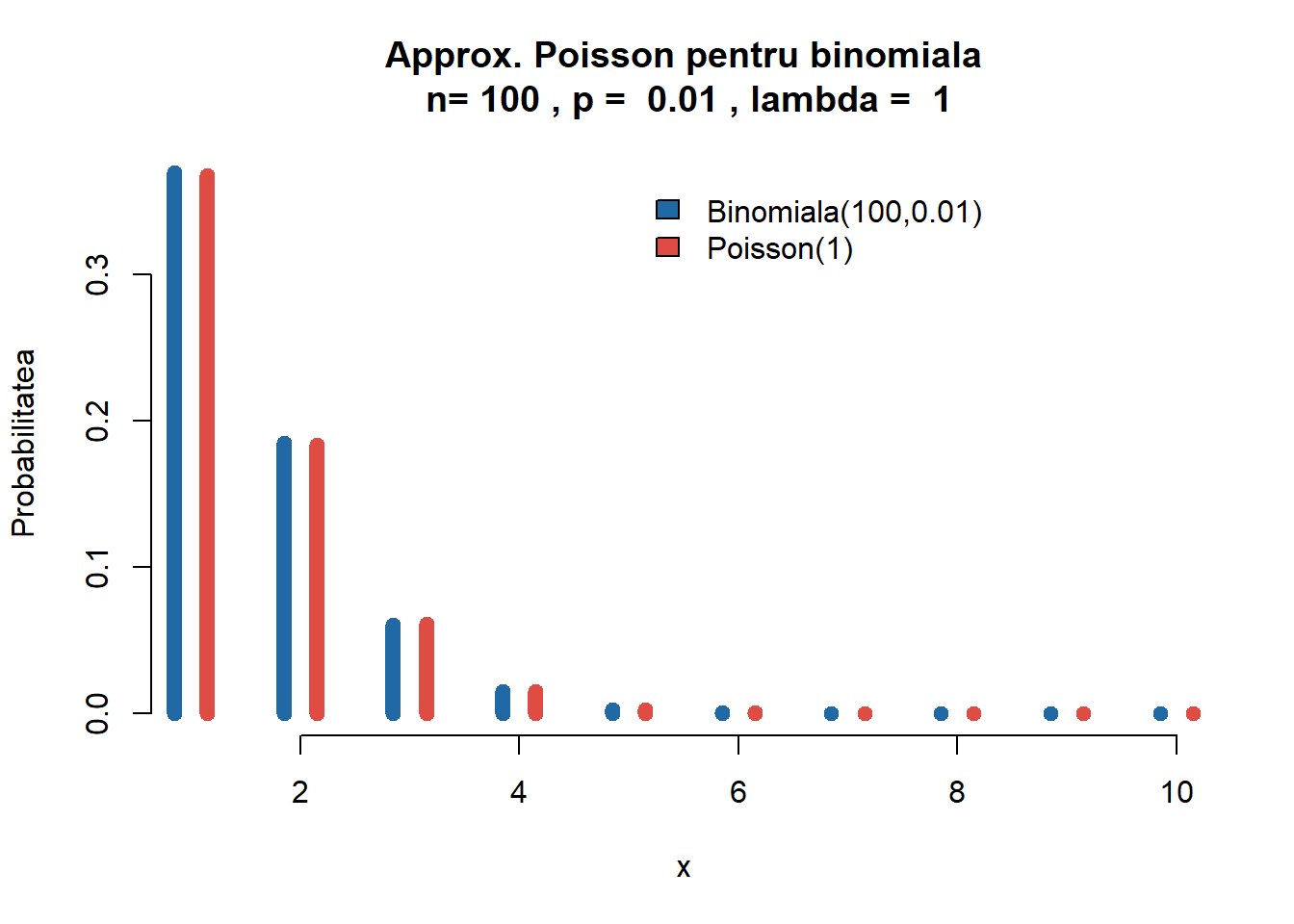
iar pentru parametrii \(n=100\) și \(p=0.01\) obținem
Tabelul 1.3: Exemplificare de aproximare Poisson a binomialei
k
Binomiala
Poisson
Eroarea Absoluta
1
0.3697296
0.3678794
0.0018502
2
0.1848648
0.1839397
0.0009251
3
0.0609992
0.0613132
0.0003141
4
0.0149417
0.0153283
0.0003866
5
0.0028978
0.0030657
0.0001679
6
0.0004635
0.0005109
0.0000475
7
0.0000629
0.0000730
0.0000101
8
0.0000074
0.0000091
0.0000017
9
0.0000008
0.0000010
0.0000003
10
0.0000001
0.0000001
0.0000000
Figura 1.11: Ilustrarea aproximării Poisson pentru \(\mathcal{B}(100, 0.01)\).
Pentru funcția de repartiție \(F_{n,p}(k)\), folosind aproximarea Poisson avem că
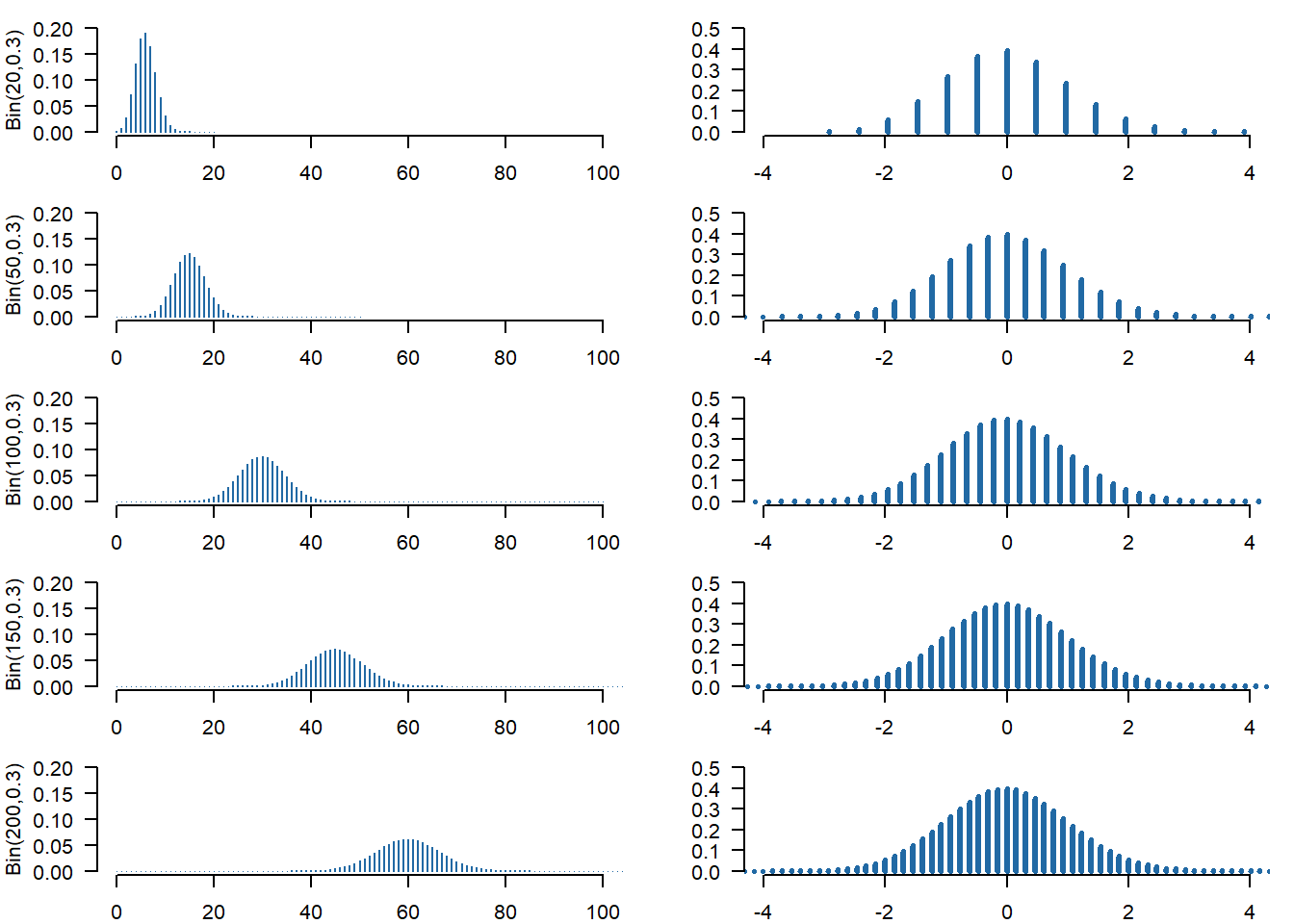
Să considerăm repartiția binomială \(\mathcal{B}(n, p)\) pentru \(p = 0.3\) și \(n\in\{20, 50, 100, 150, 200\}\) și să trasăm histogramele variabilelor aleatoare care au aceste repartiții (\(X_n\)) precum și a variabilelor standardizate \(Z_n = \frac{X_n-np}{\sqrt{npq}}\).
Figura 1.12: Histogramele variabilelor aleatoare \(X_n\) și a variabilelor standardizate \(Z_n = \frac{X_n-np}{\sqrt{npq}}\).
Observăm, pentru graficele din partea stângă, că valoarea maximă se atinge în jurul punctului \(n\times 0.3\) pentru fiecare grafic în parte. De asemenea se observă că odată cu creșterea lui \(n\) crește și gradul de împrăștiere, cu alte cuvinte crește și abaterea standard (\(\sigma_n = \sqrt{npq}\)).
Pe de altă parte putem remarca că figurile din partea dreaptă au o formă simetrică, de tip clopot, concentrate în jurul lui \(0\), fiind translatate în origine și scalate pentru a avea o varianță egală cu \(1\). Abraham de Moivre1 a justificat acest efect (pentru \(p=0.5\)) încă din 1756 observând că raportul
pentru \(k = 1,2,\ldots,n\). Astfel \(f_{n,p}(k)\geq f_{n,p}(k-1)\) dacă și numai dacă \((n+1)p\geq k\) de unde, pentru \(n\) fixat, deducem că \(f_{n,p}(k)\) atinge valoarea maximă pentru \(k_{\max} = \lfloor{(n+1)p\rfloor}\approx np\) (acesta este motivul pentru care fiecare grafic din partea stângă are vârful în jurul punctului \(np\)).
Să observăm ce se întâmplă în jurul lui \(k_{\max}\). Avem
unde \(\alpha = \frac{a-np-\frac{1}{2}}{\sigma_n}\), \(\beta = \frac{b-np+\frac{1}{2}}{\sigma_n}\) și \(\Phi(x)=\frac{1}{\sqrt{2\pi}}\int_{-\infty}^{x}e^{-\frac{y^2}{2}}\,dy\).
Aplicând rezultatele de mai sus, în cele ce urmează vom considera două aproximări pentru funcția de repartiție \(F_{n,p}(k)\):
În practică această ultimă aproximare se aplică atunci când atât \(np\geq 5\) cât și \(n(1-p)\geq 5\).
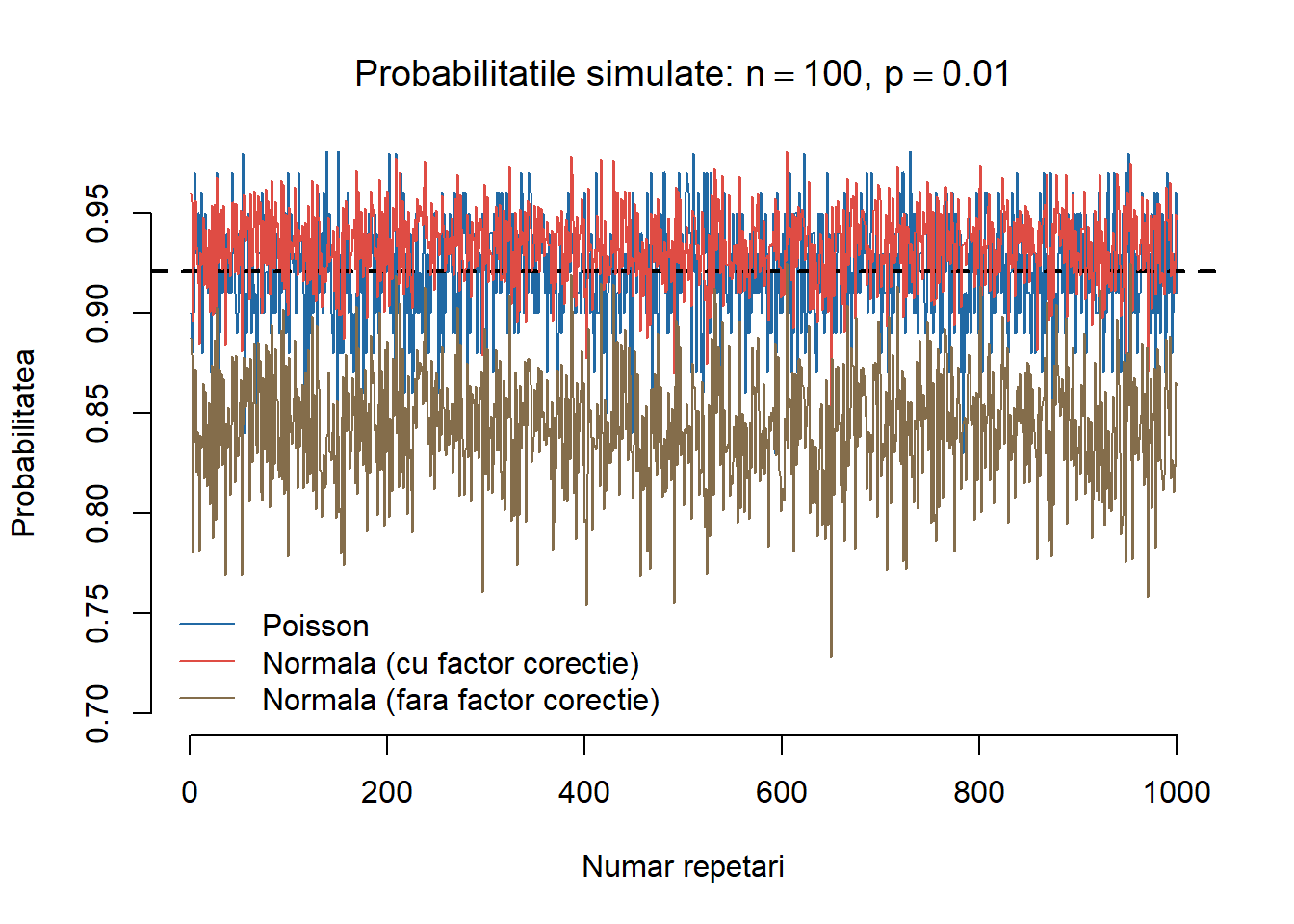
Următorul cod crează o funcție care calculează cele trei aproximări pentru funcția de repartiție binomială
appBNP <-function(n, p, R =1000, k =6) { trueval <-pbinom(k, n, p) # adevarata valoare a functiei de repartitie in k prob.zcc <- prob.zncc <- prob.pois <-NULL# initializare q <-1-pfor (i in1:R) {# repetam procesul de R ori x <-rnorm(n, n * p, sqrt(n * p * q)) # generare n v.a. normale de medie np z.cc <- ((k + .5) -mean(x))/sd(x) # cu coeficient de corectie prob.zcc[i] <-pnorm(z.cc) z.ncc <- (k -mean(x))/sd(x) # fara coeficient de corectie prob.zncc[i] <-pnorm(z.ncc) y <-rpois(n, n * p) prob.pois[i] <-length(y[y <= k])/n # aproximate Poisson }list(prob.zcc = prob.zcc, prob.zncc = prob.zncc, prob.pois = prob.pois, trueval = trueval)}
Avem următoarea ilustrație grafică a diferitelor metode de aproximare:
Figura 1.13: Ilustrarea celor trei metode de aproximare.
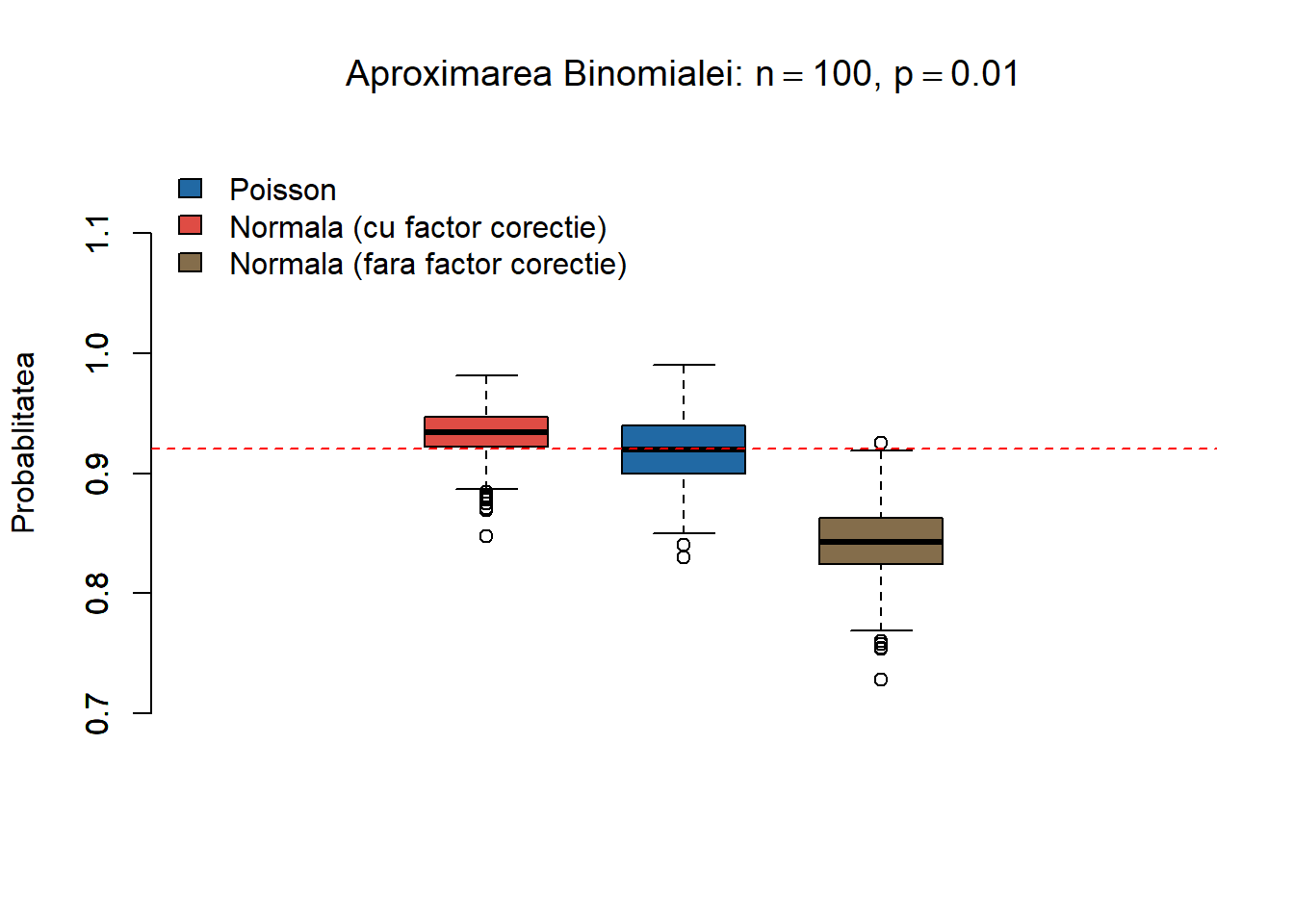
Avem și următorul boxplot (discuție ce reprezintă un boxplot) care ne permite să evidențiem care dintre aproximări este mai bună pentru valorile selectate
Figura 1.14: Compararea celor trei metode de aproximare.
Variabile aleatoare continue (univariate)
În afară de repartițiile discrete văzute în Capitolul 1, R pune la dispoziție și o gamă largă de repartiții continue. Tabelul de mai jos prezintă numele și parametrii acestora:
Tabelul 2.1: Numele și parametrii repartițiilor continue uzuale în R.
Pentru fiecare repartiție continuă, există patru comenzi în R care sunt compuse din prefixul d, p, q și r și din numele repartiției (coloana a 2-a). De exemplu dnorm, pnorm, qnorm și rnorm sunt comenzile corespunzătoare repartiției normale pe când dunif, punif, qunif și runif sunt cele corespunzătoare repartiției uniforme.
dnume: calculează densitatea atunci când vorbim de o variabilă continuă sau funcția de masă atunci când avem o repartiție discretă
pnume: calculează funcția de repartiție, i.e. \(F(x)=\mathbb{P}(X\leq x)\)
qnume: reprezintă funcția cuantilă, cu alte cuvinte valoarea pentru care funcția de repartiție are o anumită probabilitate; în cazul continuu, dacă pnume(x) = p atunci qnume(p) = x iar în cazul discret întoarce cel mai mic întreg \(u\) pentru care \(\mathbb{P}(X\leq u)\geq p\).
rnume: generează observații independente din repartiția dată
Repartiția Uniformă \(\mathcal{U}([a,b])\)
Definiția 2.1 (Variabilă aleatoare repartizată uniform) Spunem că o variabilă aleatoare \(X\) este repartizată uniform pe intervalul \([a,b]\), și notăm cu \(X\sim \mathcal{U}([a,b])\), dacă admite densitatea de repartiție
Variabilele aleatoare repartizate uniform joacă un rol important în teoria simulării variabilelor aleatoare datorită următorului rezultat datorat lui Paul Levy și numit teorema de universalitate a repartiției uniforme:
Teorema 2.1 (Universalitatea Repartiției Uniforme) Fie \(X\) o variabilă aleatoare reală cu funcția de repartiție \(F\), \(U\) o variabilă aleatoare repartizată uniform pe \([0,1]\) și fie funcția cuantilă (inversa generalizată) asociată lui \(F\), \(F^{-1}:(0,1)\to\mathbb{R}\) definită prin
calculăm densitatea unei variabile aleatoare repartizate uniform pe \([a, b]\) în diferite puncte
dunif(c(3.1, 3.7, 3.95, 4.86), 3, 5)
[1] 0.5 0.5 0.5 0.5
calculăm funcția de repartiție a unei variabile repartizate uniform pe \([a,b]\) pentru diferite valori
punif(c(3.1, 3.7, 3.95, 4.86), 3, 5)
[1] 0.050 0.350 0.475 0.930
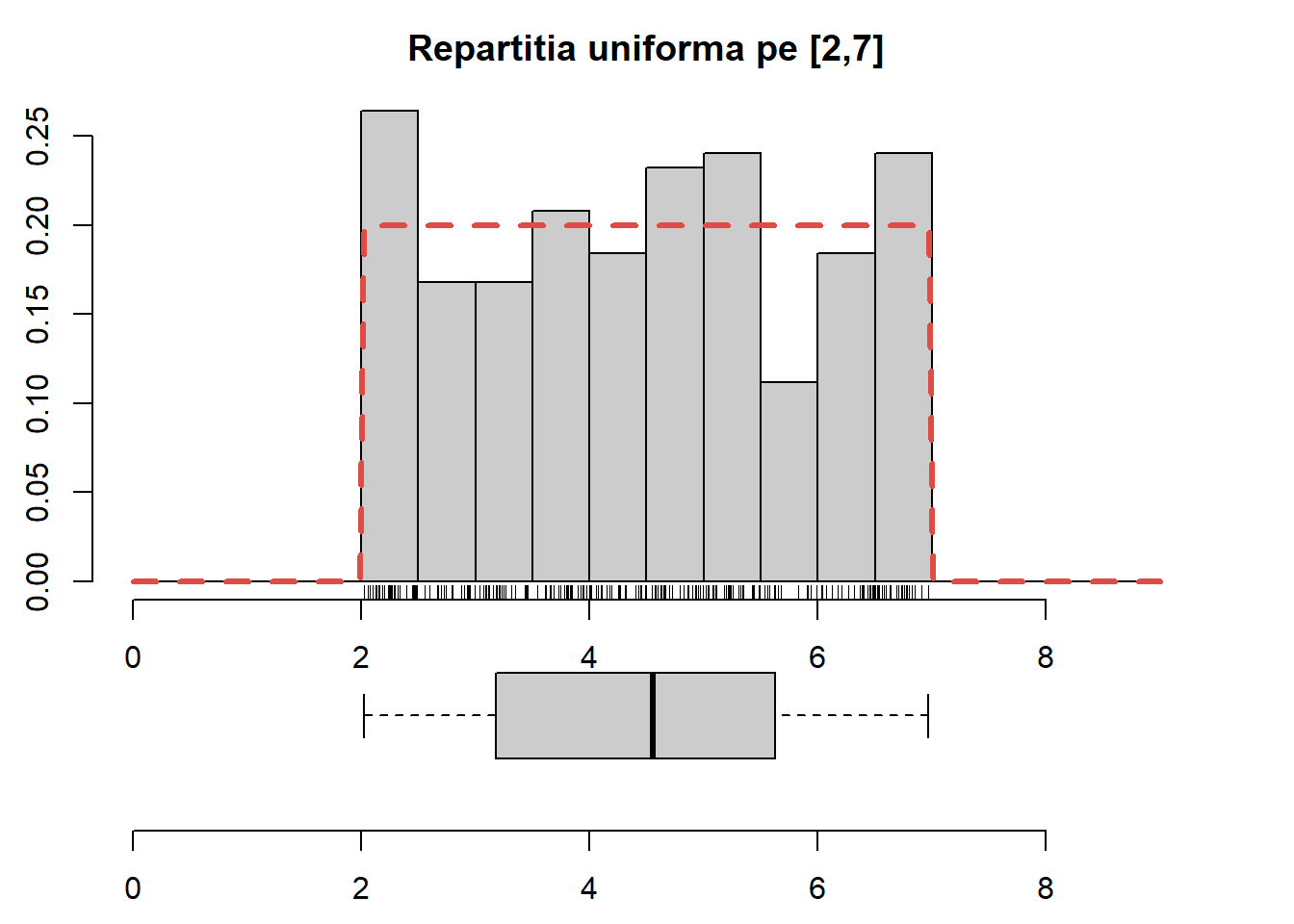
Exercițiul 2.1 Fie \(X\) o variabilă aleatoare repartizată uniform pe \([2,7]\). Determinați:
\(\mathbb{P}(X\in\{1,2,3,4,5,6,7\})\)
\(\mathbb{P}(X<3)\) și \(\mathbb{P}(X\leq 3)\)
\(\mathbb{P}(X\leq 3 \cup X>4)\)
Generați \(250\) de observații din repartiția dată, trasați histograma acestora și suprapuneți densitatea repartiției date (vezi figura de mai jos).
Figura 2.2: Densitatea repartiției uniforme suprapuse peste histograma celor \(250\) de observații generate.
Exercițiul 2.2 Dacă \(X\) o variabilă aleatoare repartizată uniform pe \([a,b]\) și \([c,d]\subset [a,b]\) este un subinterval, atunci repartiția condiționată a lui \(X\) la \(X\in [c,d]\) este \(\mathcal{U}[c,d]\).
Repartiția Normală \(\mathcal{N}(\mu, \sigma^2)\)
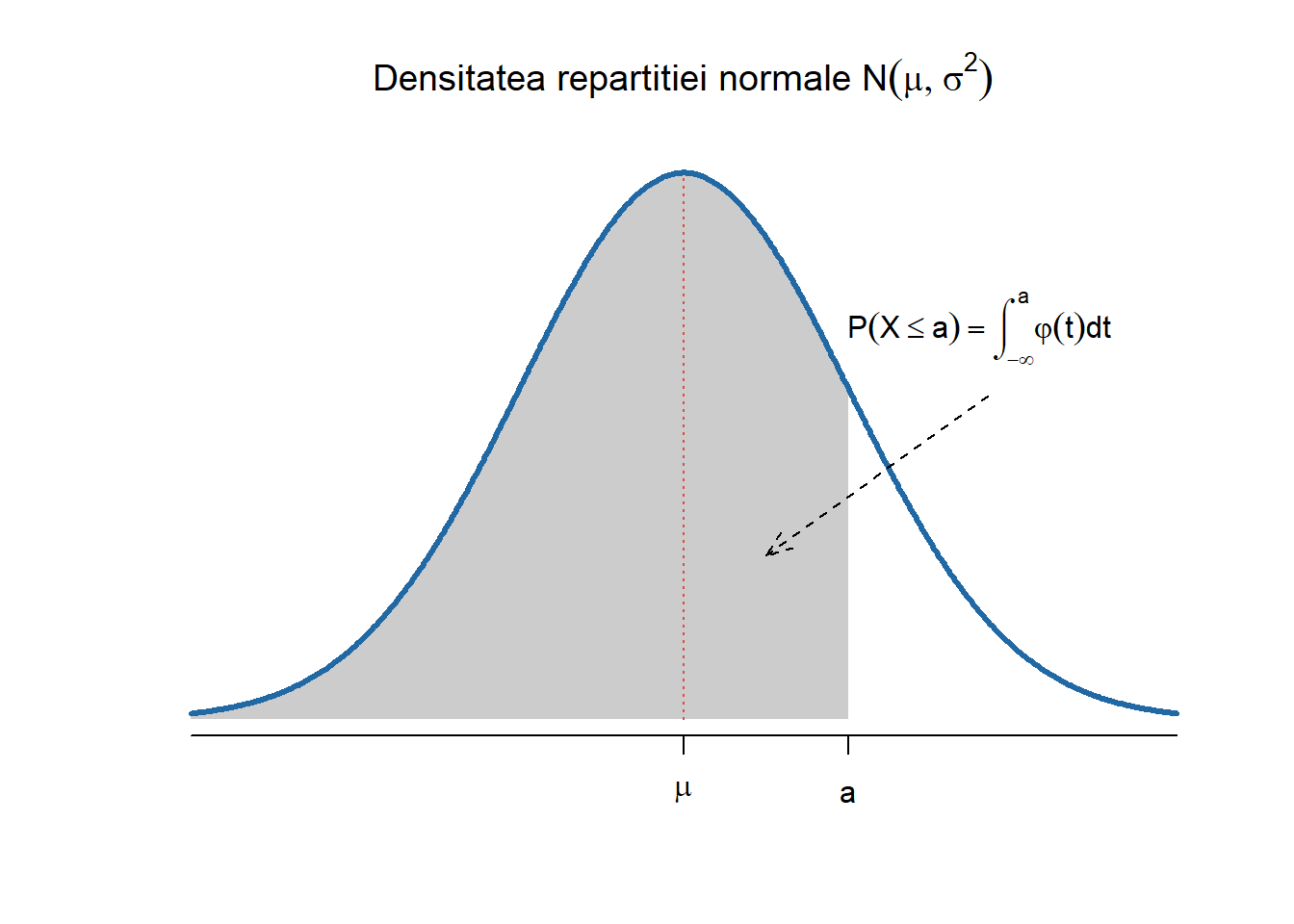
Definiția 2.2 (Variabilă aleatoare repartizată normal) Spunem că o variabilă aleatoare \(X\) este repartizată normal sau Gaussian de medie \(\mu\) și varianță \(\sigma^2\), și se notează cu \(X\sim\mathcal{N}(\mu, \sigma^2)\), dacă densitatea ei de repartiție are forma
Figura 2.3: Densitatea și funcția de repartiție a repartiției normale \(\mathcal{N}(\mu, \sigma^2)\).
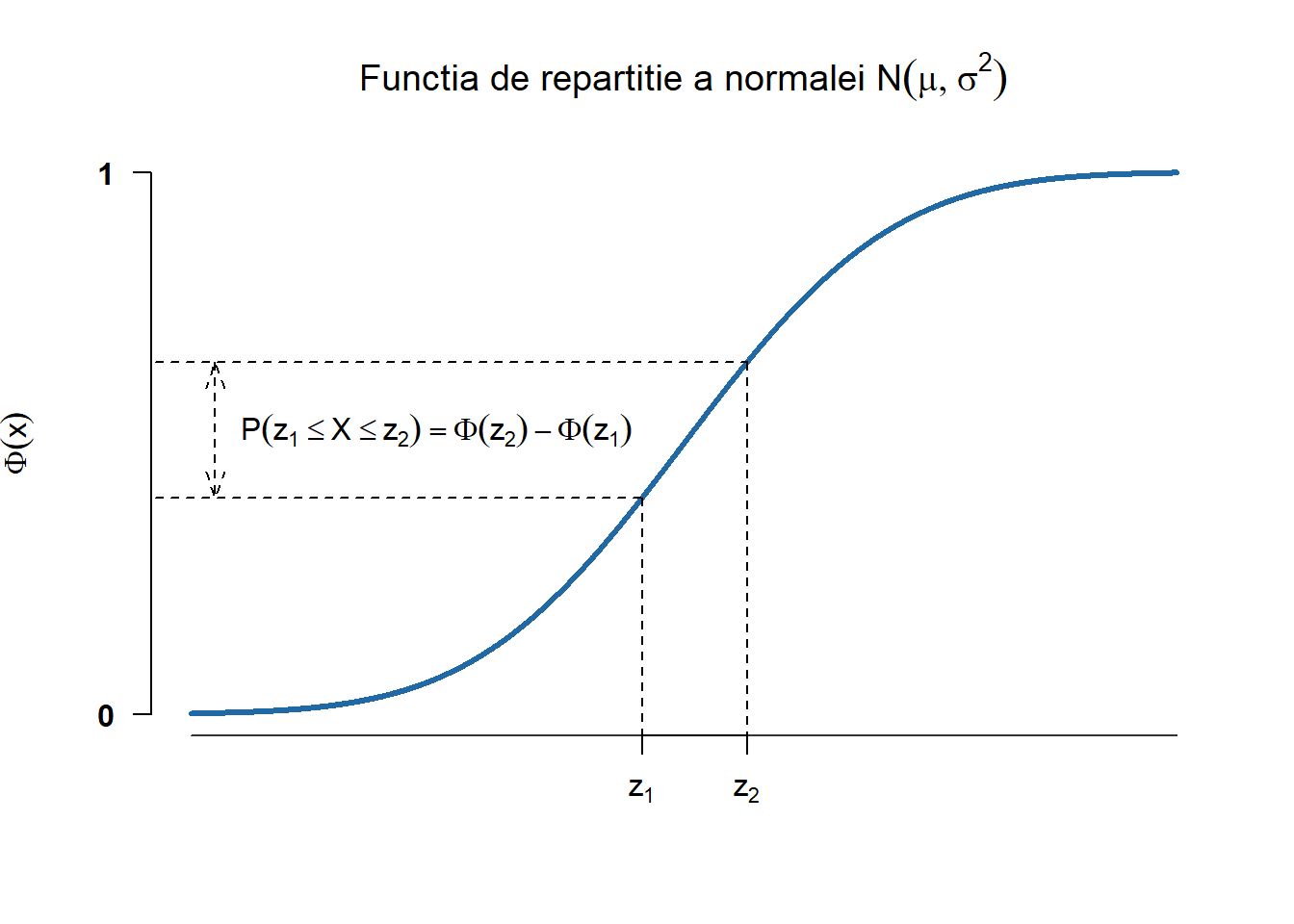
Pentru funcția de repartiție nu avem o formulă explicită de calcul, ea poate fi aproximată cu ajutorul descompunerii în serie. În cazul variabilelor normale standard (\(X\sim\mathcal{N}(0,1)\)) avem proprietățile
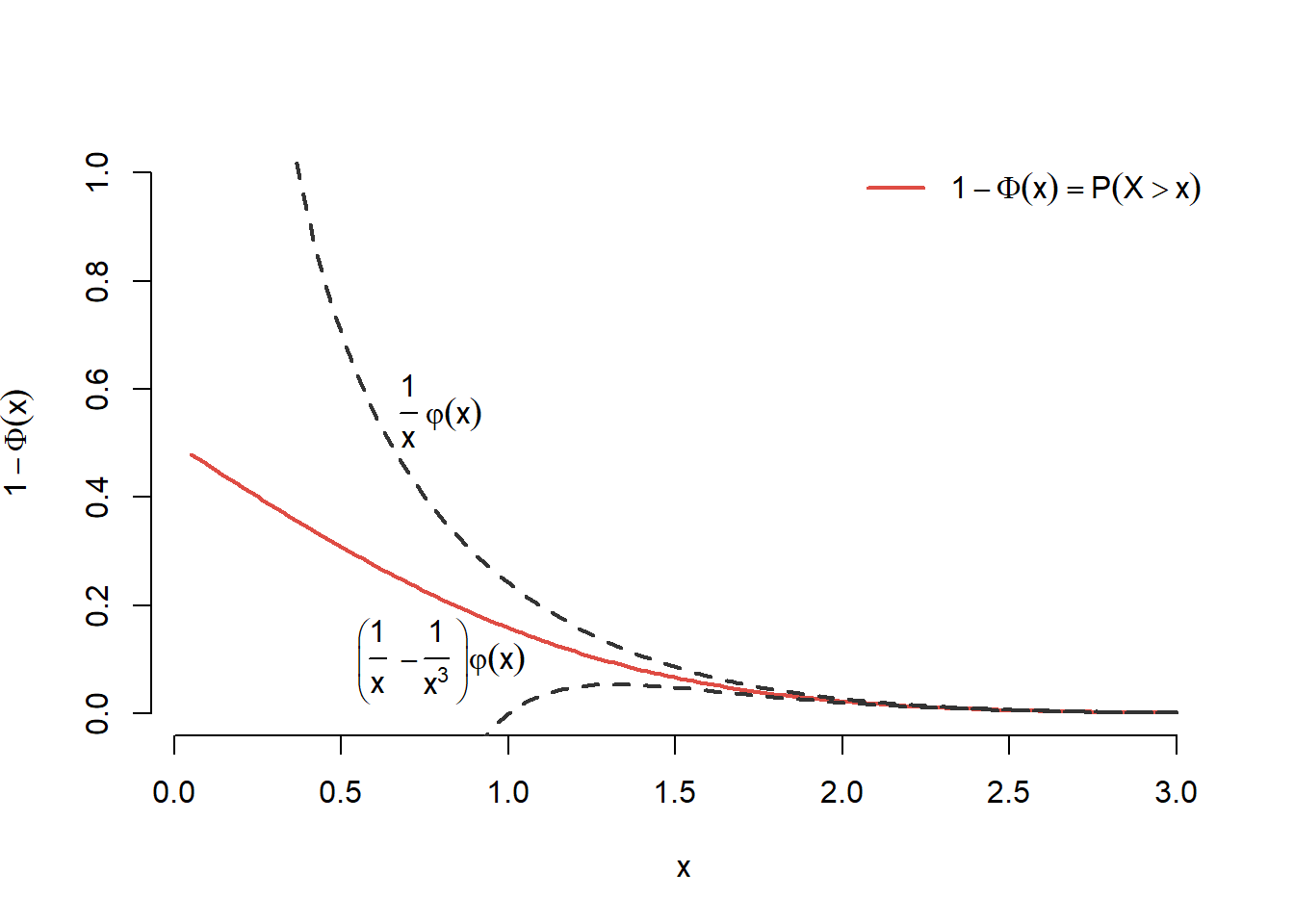
\(\Phi(x) = 1-\Phi(-x)\) pentru toate valorile \(x\in\mathbb{R}\)
\(1-\Phi(a)\leq\frac{1}{2}e^{-\frac{a^2}{2}}\) pentru \(a>0\)3
Media și varianța variabilei aleatoare \(X\) repartizate normal de parametrii \(\mathcal{N}(\mu, \sigma^2)\) sunt egale cu
generăm observații independente din repartiția \(\mathcal{N}(\mu, \sigma^2)\) (e.g. \(\mu = 0\) și \(\sigma^2 = 2\) - în R funcțiile rnorm, dnorm, pnorm și qnorm primesc ca parametrii media și abaterea standard, \(\sigma\)nu varianța \(\sigma^2\))
calculăm cuantilele de ordin \(\alpha\in(0,1)\) (i.e. valoarea \(z_{\alpha}\) pentru care \(\Phi(z_{\alpha}) = \alpha\) sau altfel spus \(z_{\alpha} = \Phi^{-1}(\alpha)\))
Exercițiul 2.3 Fie \(X\) o variabilă aleatoare repartizată \(\mathcal{N}(\mu, \sigma^2)\). Atunci pentru \(\mu = 1\) și \(\sigma = 3\) calculați:
\(\mathbb{P}(\text{$X$ este par})\)
\(\mathbb{P}(X<3.4)\) și \(\mathbb{P}(X>1.3)\)
\(\mathbb{P}(1<X<4)\)
\(\mathbb{P}(X\in [2,3]\cup[3.5,5])\)
\(\mathbb{P}(|X-3|>6)\)
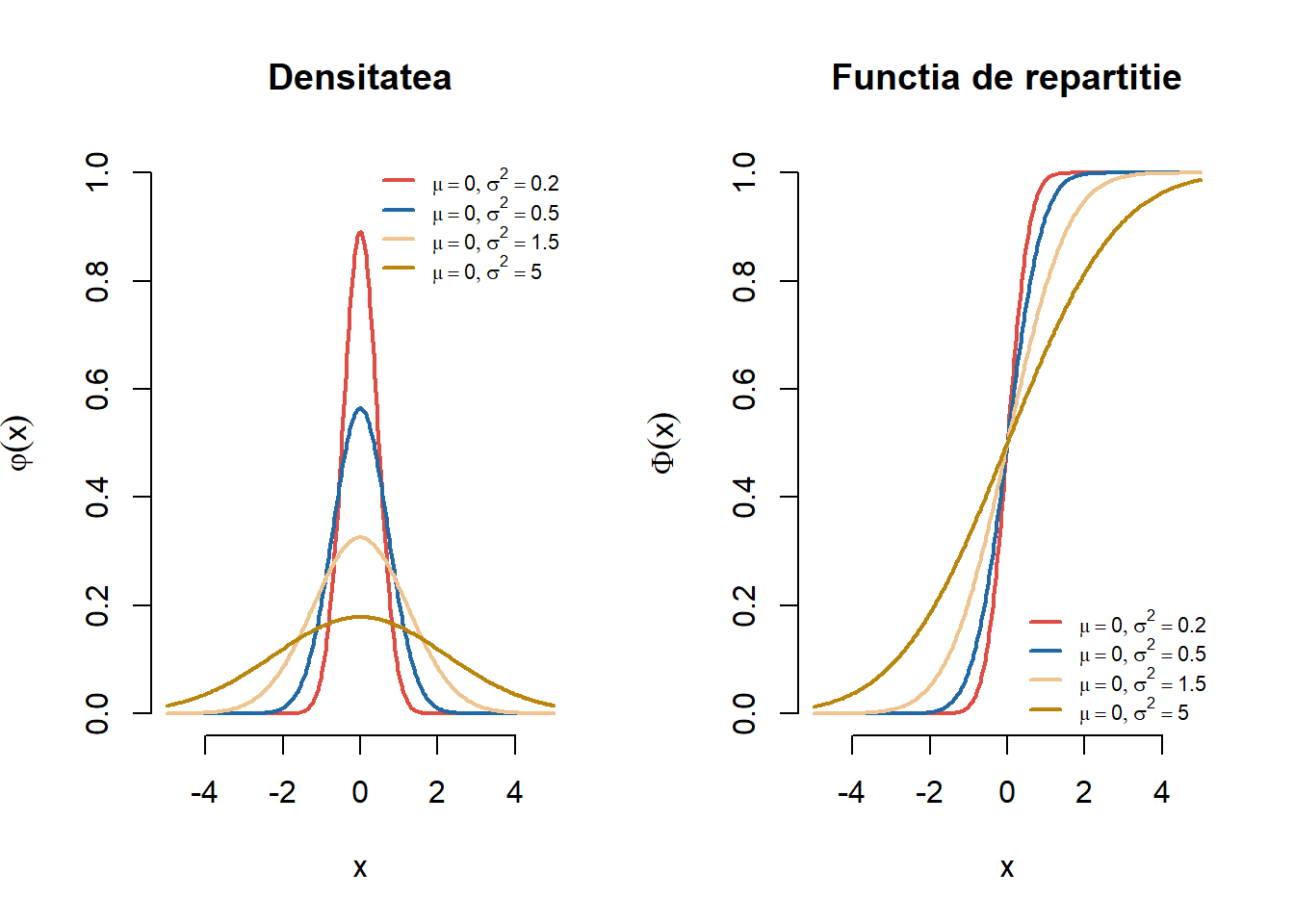
Exercițiul 2.4 Fie \(X\) o variabilă aleatoare repartizată \(\mathcal{N}(\mu, \sigma^2)\). Pentru \(\mu = 0\) și \(\sigma^2 \in \{0.2, 0.5, 1.5, 5\}\) trasați pe același grafic densitățile repartițiilor normale cu parametrii \(\mathcal{N}(\mu, \sigma^2)\). Adăugați legendele corespunzătoare. Aceeași cerință pentru funcțiile de repartiție.
Figura 2.4: Densitatea și funcția de repartiție pentru o serie de repartiții normale.
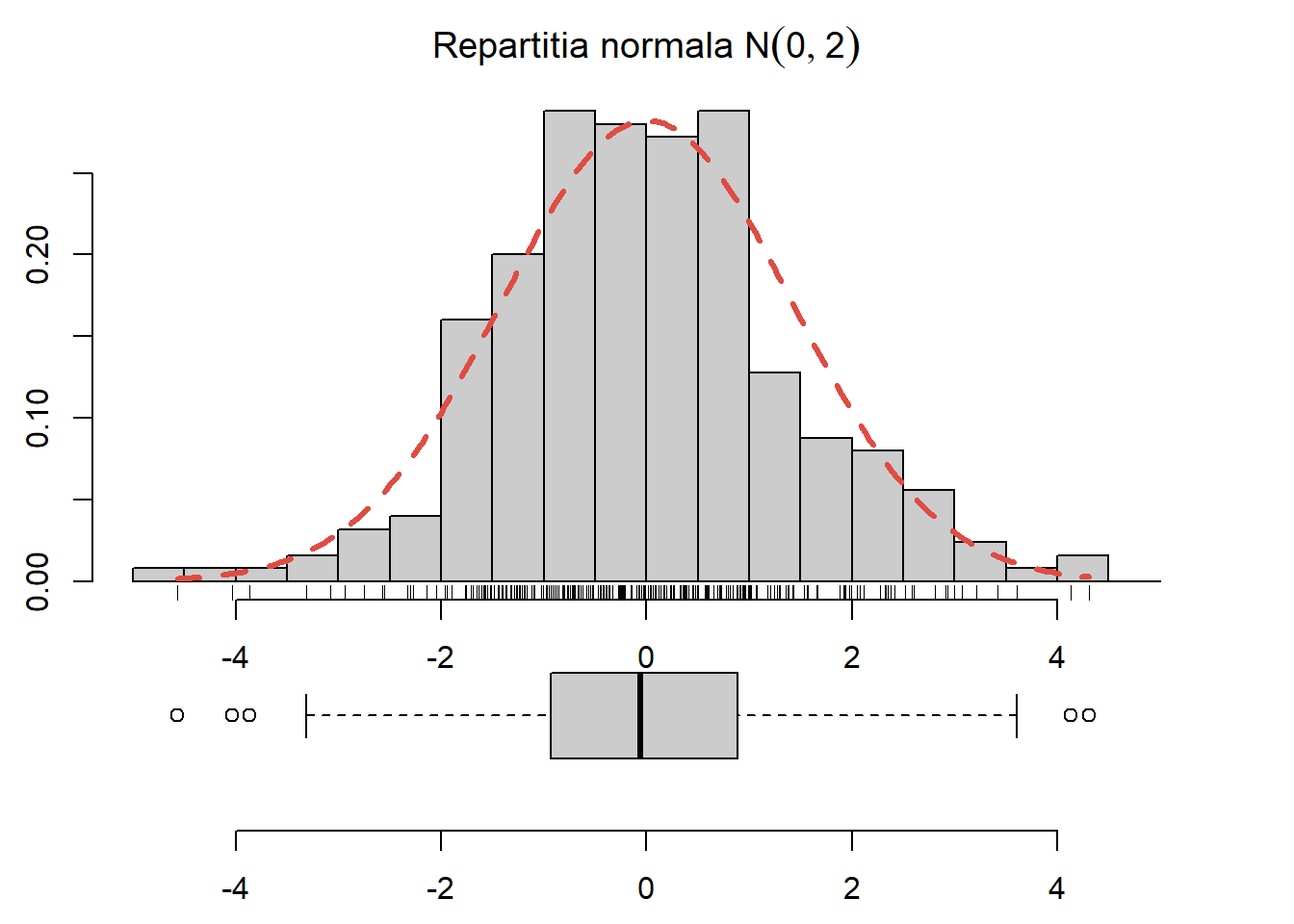
Exercițiul 2.5 Generați \(250\) de observații din repartiția \(\mathcal{N}(0, 2)\), trasați histograma acestora și suprapuneți densitatea repartiției date (vezi Figura 2.5).
Figura 2.5: Densitatea normalei suprapusă peste histograma eșantionului generat.
Exercițiul 2.6 Fie \(X\) o variabilă aleatoare repartizată normal de parametrii \(\mu\) și \(\sigma^2\). Ilustrați grafic pentru \(\mu = 0\) și \(\sigma = 1\) că are loc următoarea inegalitate:
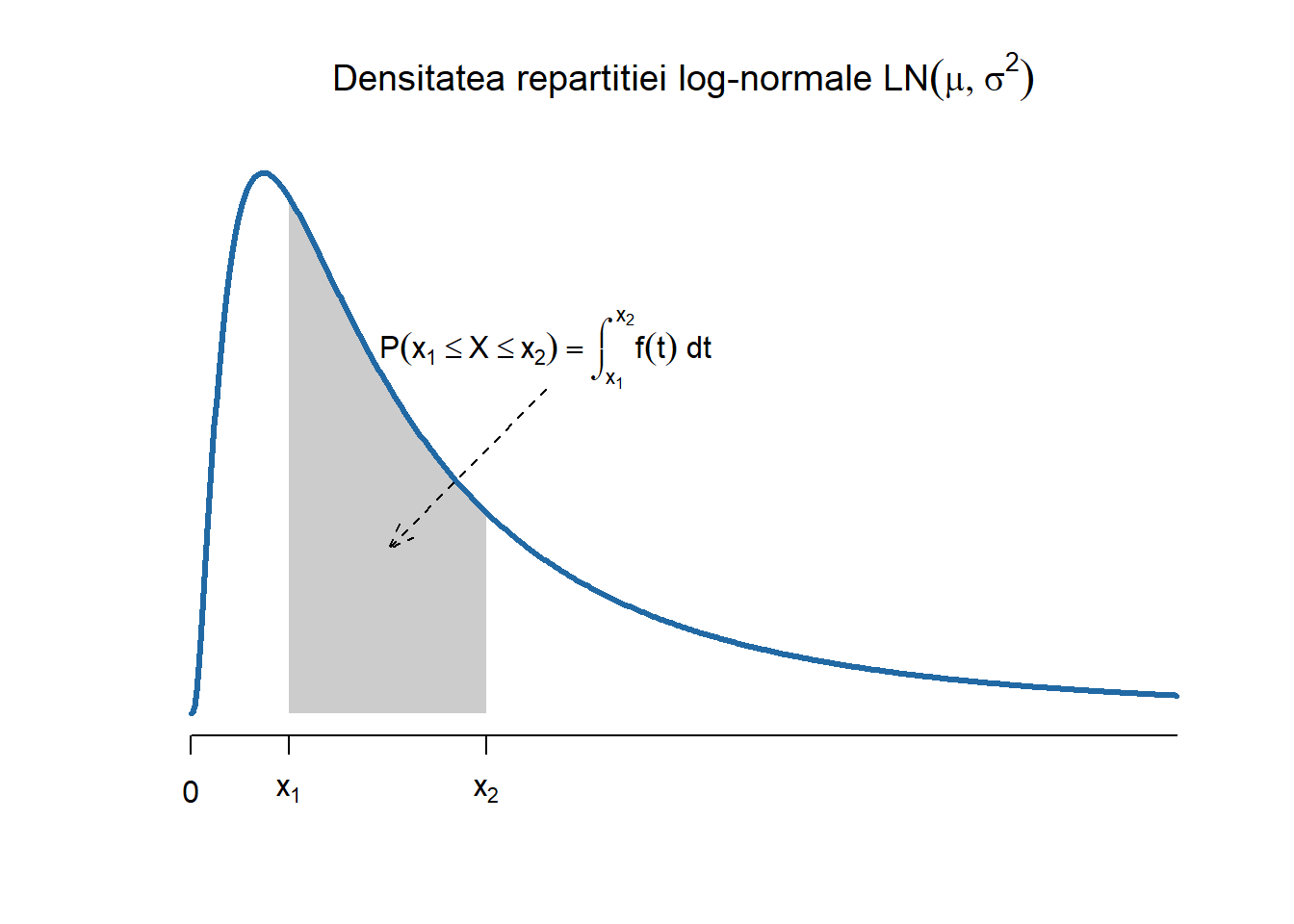
Definiția 2.3 (Variabilă aleatoare repartizată log-normal) Spune că o variabilă aleatoare \(X\) este repartizată log-normal de parametrii \(\mu\) și \(\sigma^2\), și notăm \(X\sim LN(\mu, \sigma^2)\), dacă admite densitatea de repartiției
și, ca și în cazul repartiției normale, nu are o formulă explicită de calcul.
NoteRemarcă
O variabilă aleatoare \(X\) este repartizată log-normal de parametrii \(\mu\) și \(\sigma^2\) dacă \(\ln(X)\) este repartizată normal de parametrii \(\mu\) și \(\sigma^2\). Cu alte cuvinte dacă \(Y\sim \mathcal{N}(\mu, \sigma^2)\) atunci \(X=e^Y\sim LN(\mu, \sigma^2)\).
(a) Densitatea
(b) Funcția de repartiție
Figura 2.7: Densitatea și funcția de repartiție a repartiției log-normale \(\mathcal{LN}(\mu, \sigma^2)\).
Media și varianța variabilei aleatoare \(X\) repartizate log-normal de parametrii \(LN(\mu, \sigma^2)\) sunt egale cu
generăm observații independente din repartiția \(LN(\mu, \sigma^2)\) (e.g. \(\mu = 0\) și \(\sigma^2 = 3\) - ca și în cazul repartiției normale, funcțiile rlnorm, dlnorm, plnorm și qlnorm primesc ca parametrii media și abaterea standard, \(\sigma\) pentru \(\ln(X)\) - variabila normală)
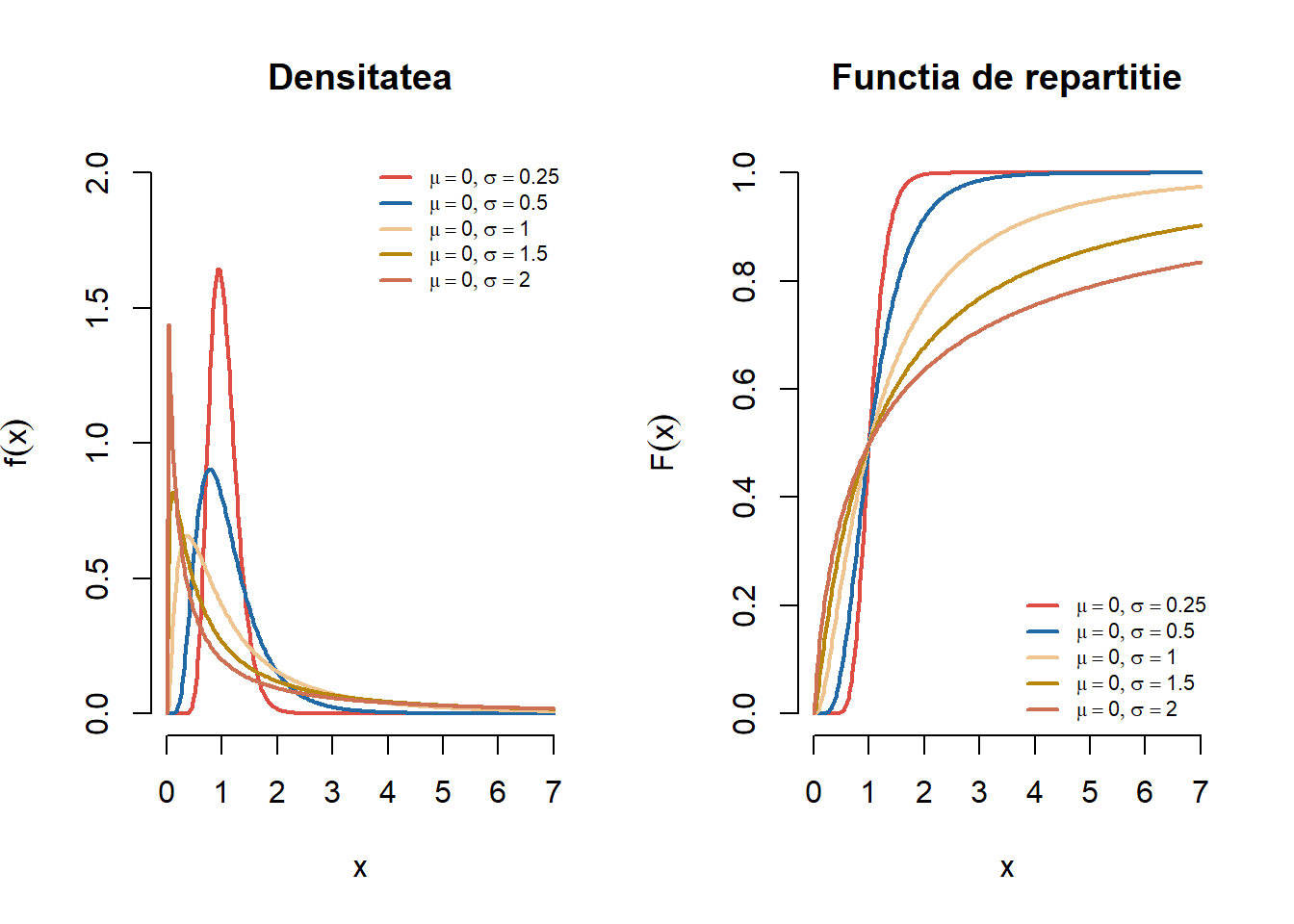
Exercițiul 2.8 Fie \(X\) o variabilă aleatoare repartizată \(LN(\mu, \sigma^2)\). Pentru \(\mu = 0\) și \(\sigma \in \{0.25, 0.5, 1.5, 5\}\) trasați pe același grafic densitățile repartițiilor log-normale cu parametrii \(LN(\mu, \sigma^2)\). Adăugați legendele corespunzătoare. Aceeași cerință pentru funcțiile de repartiție.
Figura 2.8: Densitatea și funcția de repartiție pentru o serie de repartiții log-normale.
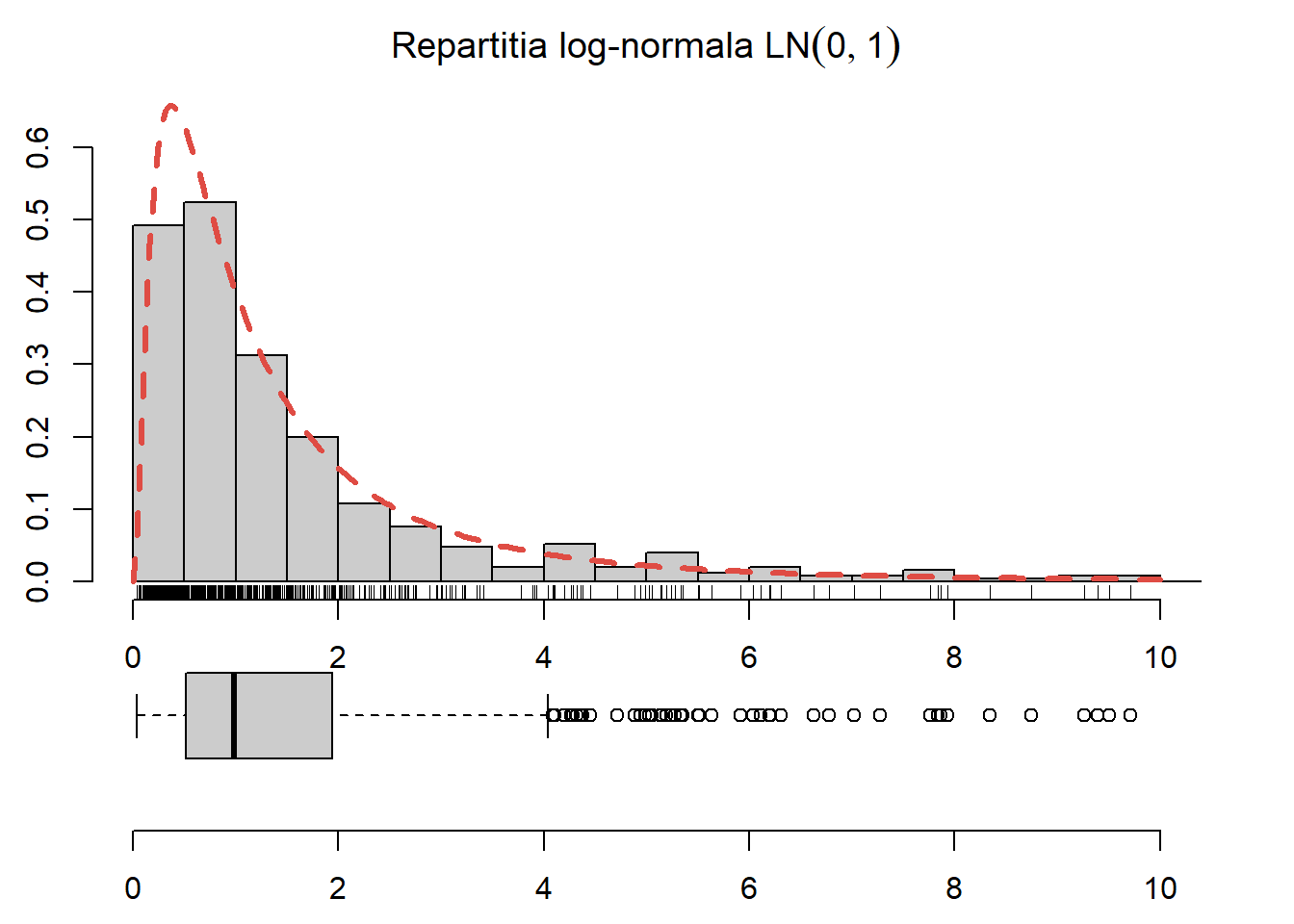
Exercițiul 2.9 Generați \(500\) de observații din repartiția \(LN(0, 2)\), trasați histograma acestora și suprapuneți densitatea repartiției date (vezi Figura 2.9).
Figura 2.9: Histograma observațiilor generate și densitatea teoretică suprapusă.
Printre fenomenele care pot fi modelate cu ajutorul repartiției log-normale se numără: cantitatea de lapte produsă de vaci, cantitatea de ploaie dintr-o perioadă dată, repartiția mărimii picăturilor de ploaie, volumul de gaz dintr-o rezervă petrolieră, etc. Pentru mai multe aplicații se poate consulta lucrarea lui Limpert, E., Stajel, W. și Abbt, M. Log-normal Distributions across the Sciences: Keys and Clues, BioScience, Vol. 51, Nr. 5, 2001.
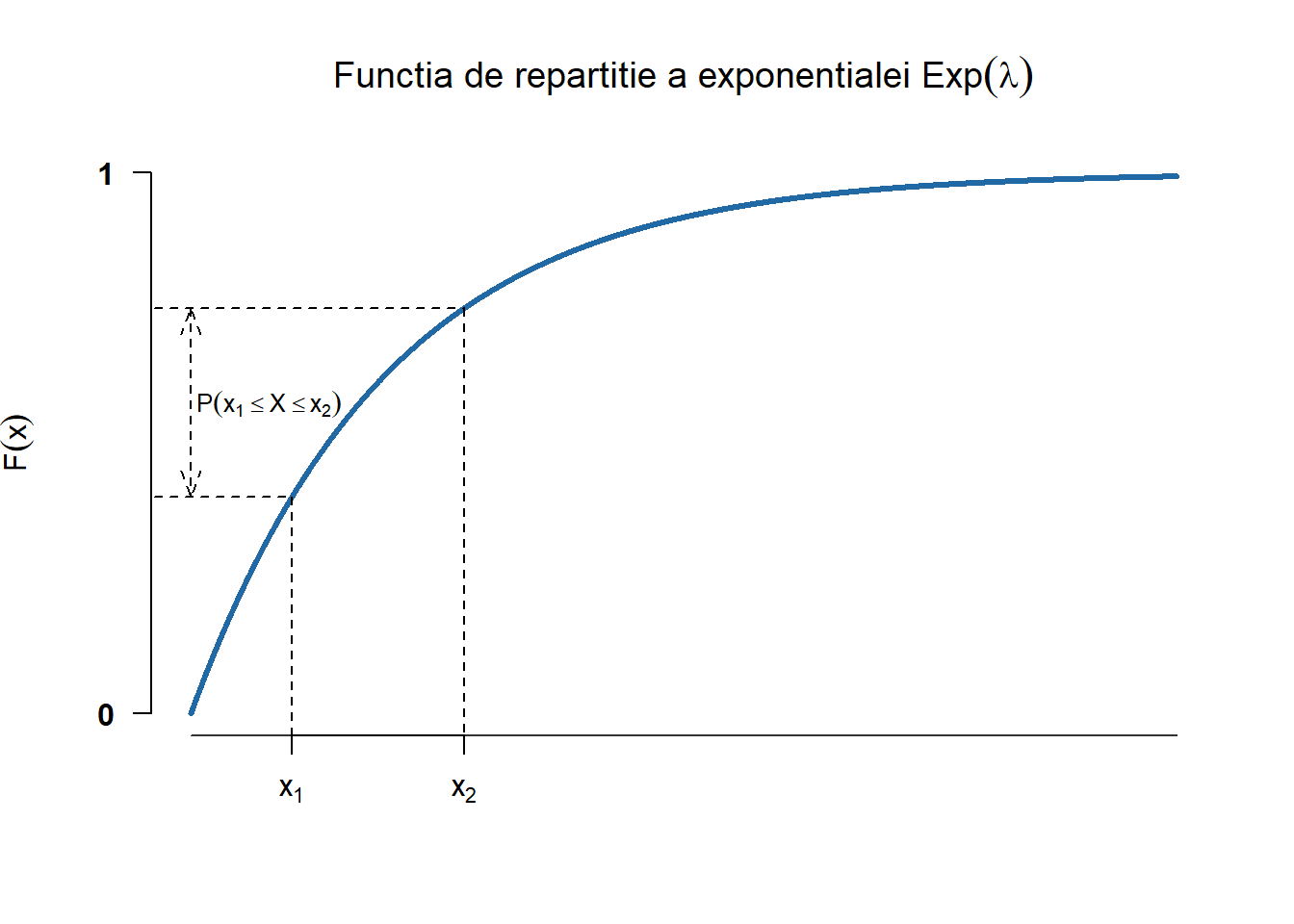
Repartiția Exponențială \(\mathrm{Exp}(\lambda)\)
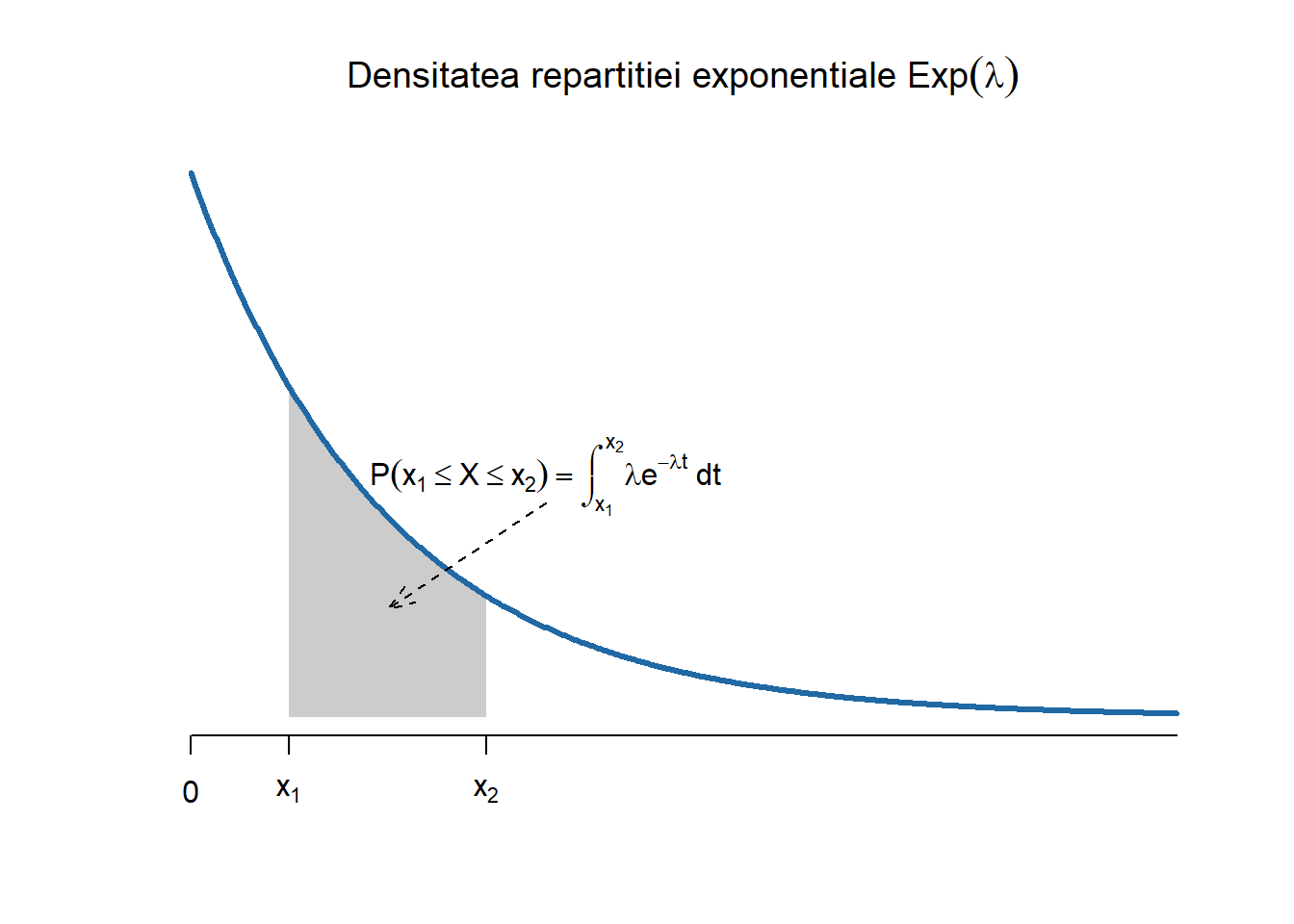
Definiția 2.4 (Variabilă aleatoare repartizată exponențial) Spunem că o variabilă aleatoare \(X\) este repartizată exponențial de parametru \(\lambda\), și se notează cu \(X\sim\mathrm{Exp}(\lambda)\), dacă densitatea ei de repartiție are forma
Exercițiul 2.10 Arătați că momentul de ordin \(k\), \(k\geq 1\), al unei variabile aleatoare repartizate exponențial \(X\sim\mathrm{Exp}(\lambda)\) este egal cu
\[
\mathbb{E}[X^k] = \frac{k!}{\lambda^k}.
\]
Următorul rezultat caracterizează repartiția exponențială:
Propoziția 2.2 Fie \(X\) o variabilă repartizată exponențial de parametru \(\lambda\). Atunci are loc următoarea proprietate numită și lipsa de memorie:
Mai mult, dacă o variabilă aleatoare continuă4\(X\) verifică proprietatea de mai sus atunci ea este repartizată exponențial.
Variabilele aleatoare repartizate exponențial sunt utilizate în modelarea fenomenelor care se desfășoară în timp continuu și care satisfac (aproximativ) proprietatea lipsei de memorie: de exemplu timpul de așteptare la un ghișeu, durata de viață a unui bec sau timpul până la următoarea convorbire telefonică.
În R putem să
generăm observații independente din repartiția \(\mathrm{Exp}(\lambda)\) (e.g. \(\lambda = 5\))
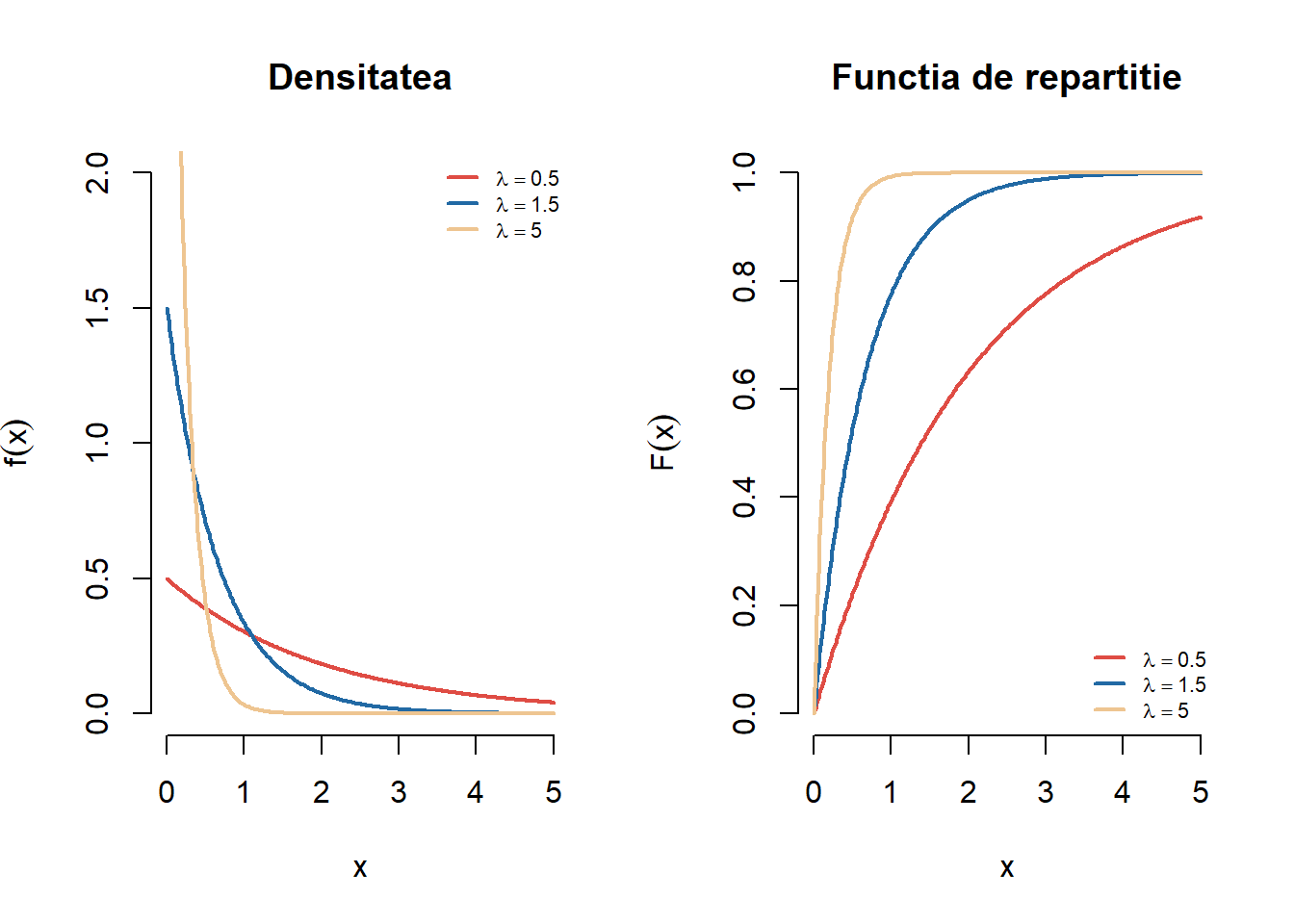
Exercițiul 2.11 Fie \(X\) o variabilă aleatoare repartizată \(\mathcal{E}(\lambda)\). Pentru \(\lambda \in \{0.5, 1.5, 5\}\) trasați pe același grafic densitățile repartițiilor exponențiale de parametru \(\lambda\). Adăugați legendele corespunzătoare. Aceeași cerință pentru funcțiile de repartiție.
Figura 2.11: Densitatea și funcția de repartiție pentru o serie de repartiții exponențiale.
Exercițiul 2.12 Folosind rezultatul de universalitate de la repartiția uniformă, descrieți o procedură prin care puteți simula o variabilă aleatoare repartizată exponențial \(\mathrm{Exp}(\lambda)\).
Construiți o funcție care permite generarea de \(n\) observații independente dintr-o variabilă repartizată \(X\sim \mathrm{Exp}(\lambda)\).
Generați \(250\) de observații din repartiția \(\mathrm{Exp}(3)\), trasați histograma acestora și suprapuneți densitatea repartiției date (vezi Figura 2.12).
Figura 2.12: Histograma observațiilor generate și densitatea teoretică suprapusă.
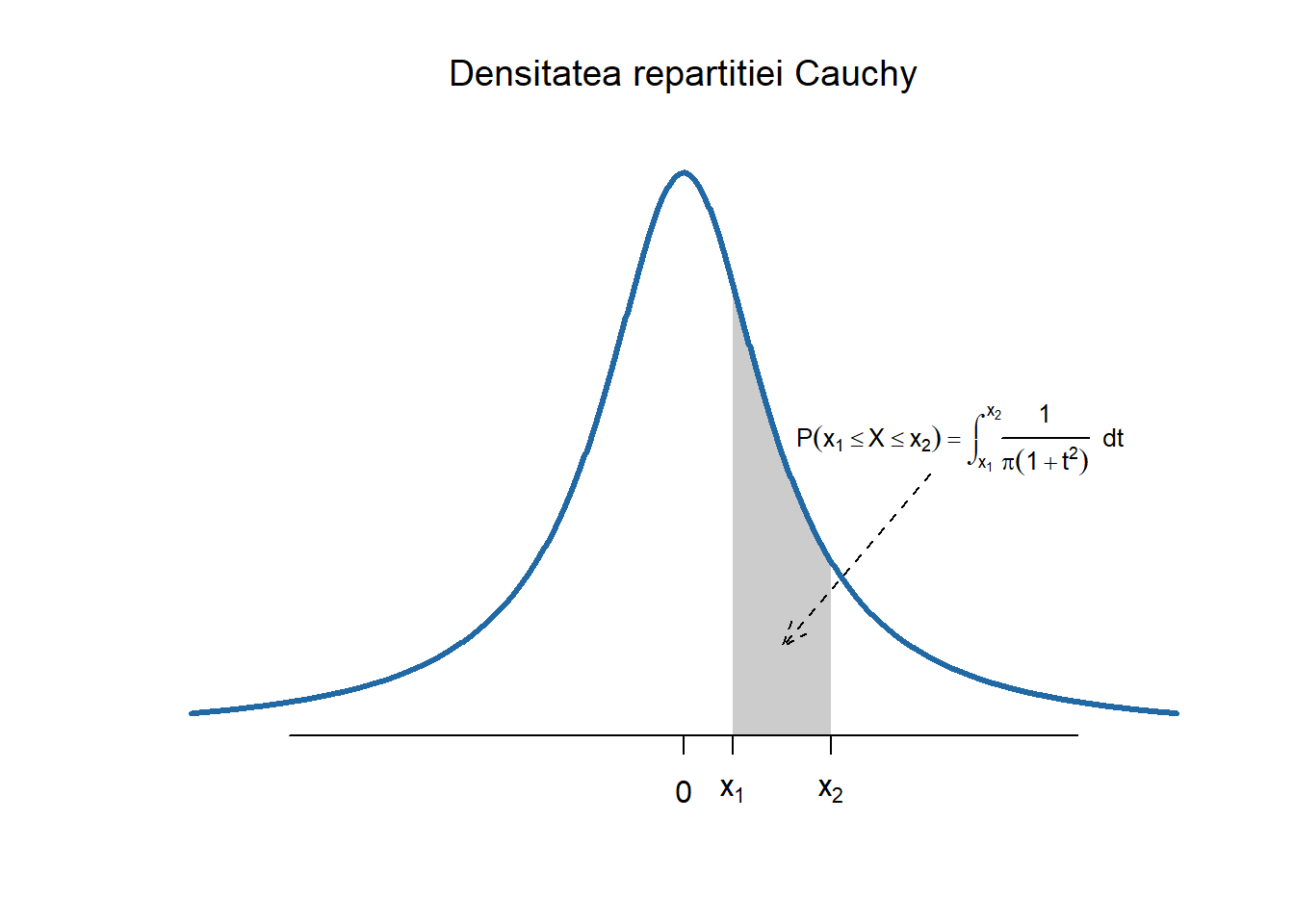
Repartiția Cauchy \(C(\alpha, \beta)\)
Definiția 2.5 (Variabilă aleatoare repartizată Cauchy) Spunem că o variabilă aleatoare \(X\) este repartizată Cauchy de parametrii \((0, 1)\), și se notează cu \(X\sim C(0,1)\), dacă densitatea ei de repartiție are forma
Observăm că graficul densității repartiției Cauchy este asemănător cu cel al repartiției normale. Parametrul \(M = 0\) reprezintă mediana (de fapt \(\mathbb{P}(X\leq 0) = \mathbb{P}(X\geq 0) = \frac{1}{2}\)) variabilei aleatoare \(X\) și nu media iar prima și a treia cuartilă sunt \(Q_1 = -1\) și respectiv \(Q_3=1\) (avem \(\mathbb{P}(X\leq -1) = \mathbb{P}(X\geq 1) = \frac{1}{4}\)).
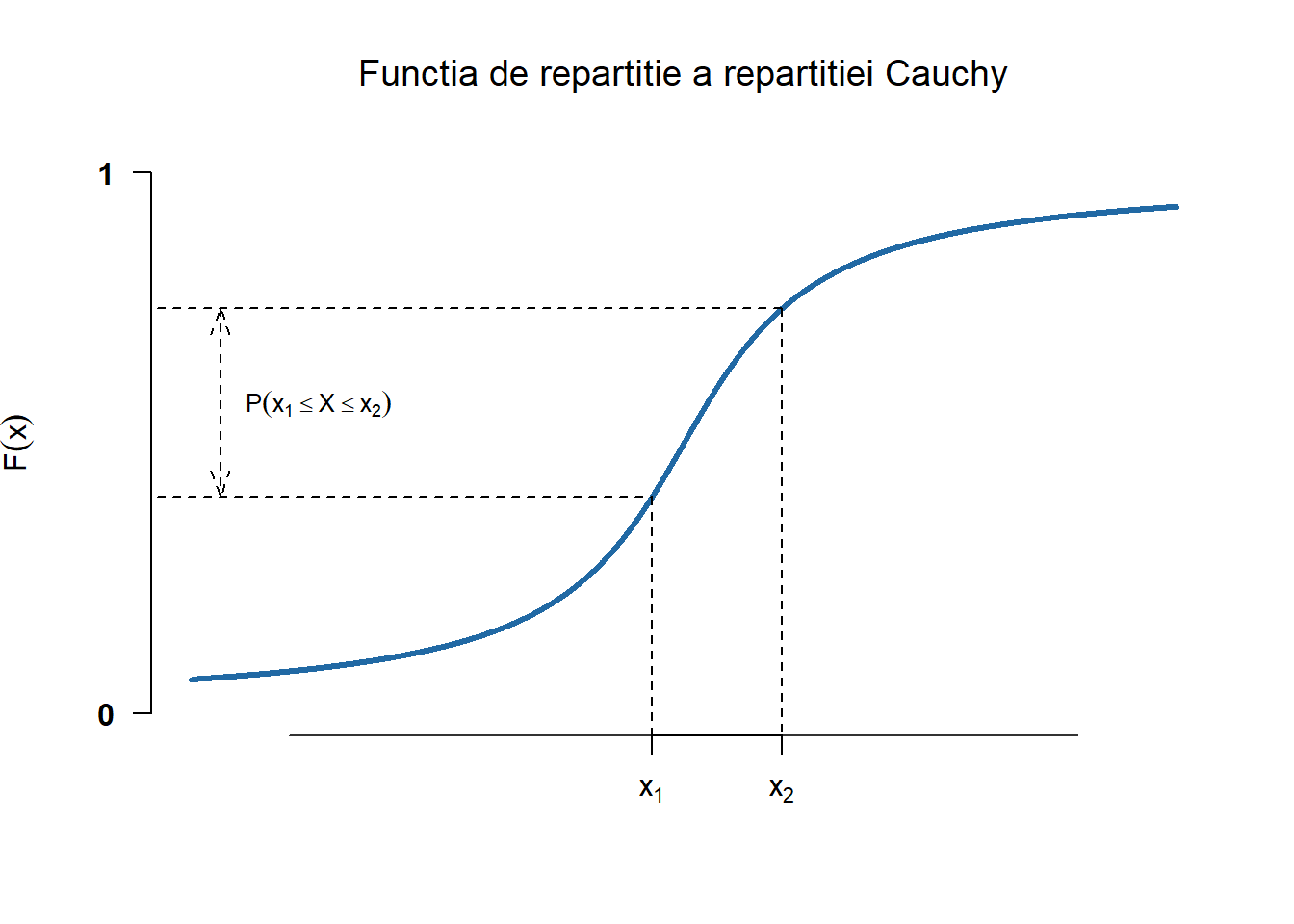
Funcția de repartiție a unei variabile aleatoare \(X\sim C(0,1)\) este dată de
Fie \(Y\sim C(0,1)\) și \(\alpha, \beta\in\mathbb{R}\) cu \(\beta>0\). Spunem că variabila aleatoare \(X = \alpha + \beta Y\) este repartizată Cauchy de parametrii \((\alpha, \beta)\), \(X\sim C(\alpha, \beta)\). Densitatea ei este
Parametrii \(\alpha\) și \(\beta\) se interpretează în modul următor: \(M = \alpha\) este mediana lui \(X\) iar \(Q_1 = \alpha-\beta\) și \(Q_3 = \alpha + \beta\) reprezintă prima și a treia cuartilă.
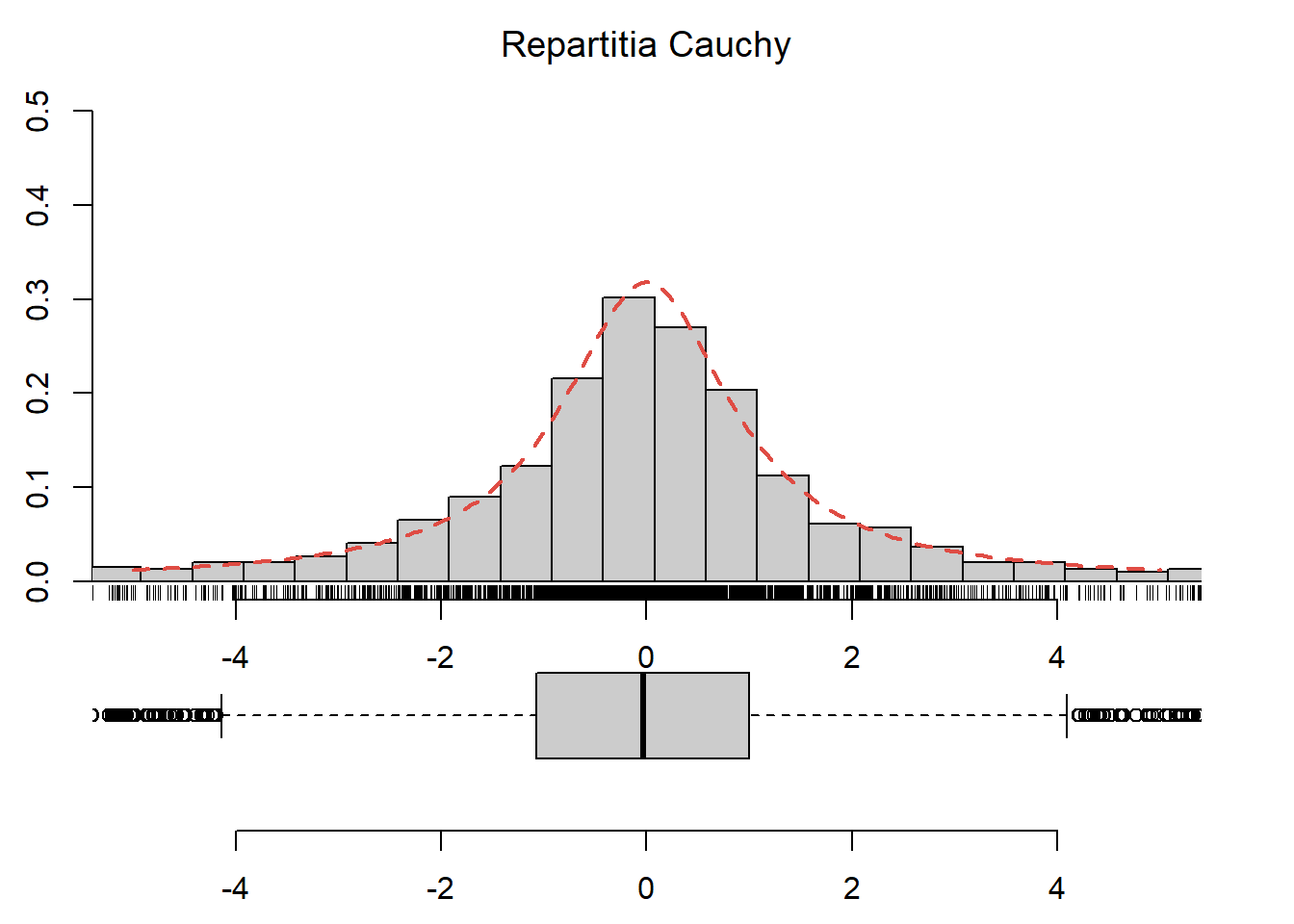
Exercițiul 2.14 Generați \(2500\) de observații din repartiția Cauchy, trasați histograma acestora și suprapuneți densitatea repartiției date pentru intervalul \([-5,5]\) (vezi Figura 2.14).
Figura 2.14: Histograma observațiilor generate din repartiția Cauchy \(C(0,1)\).
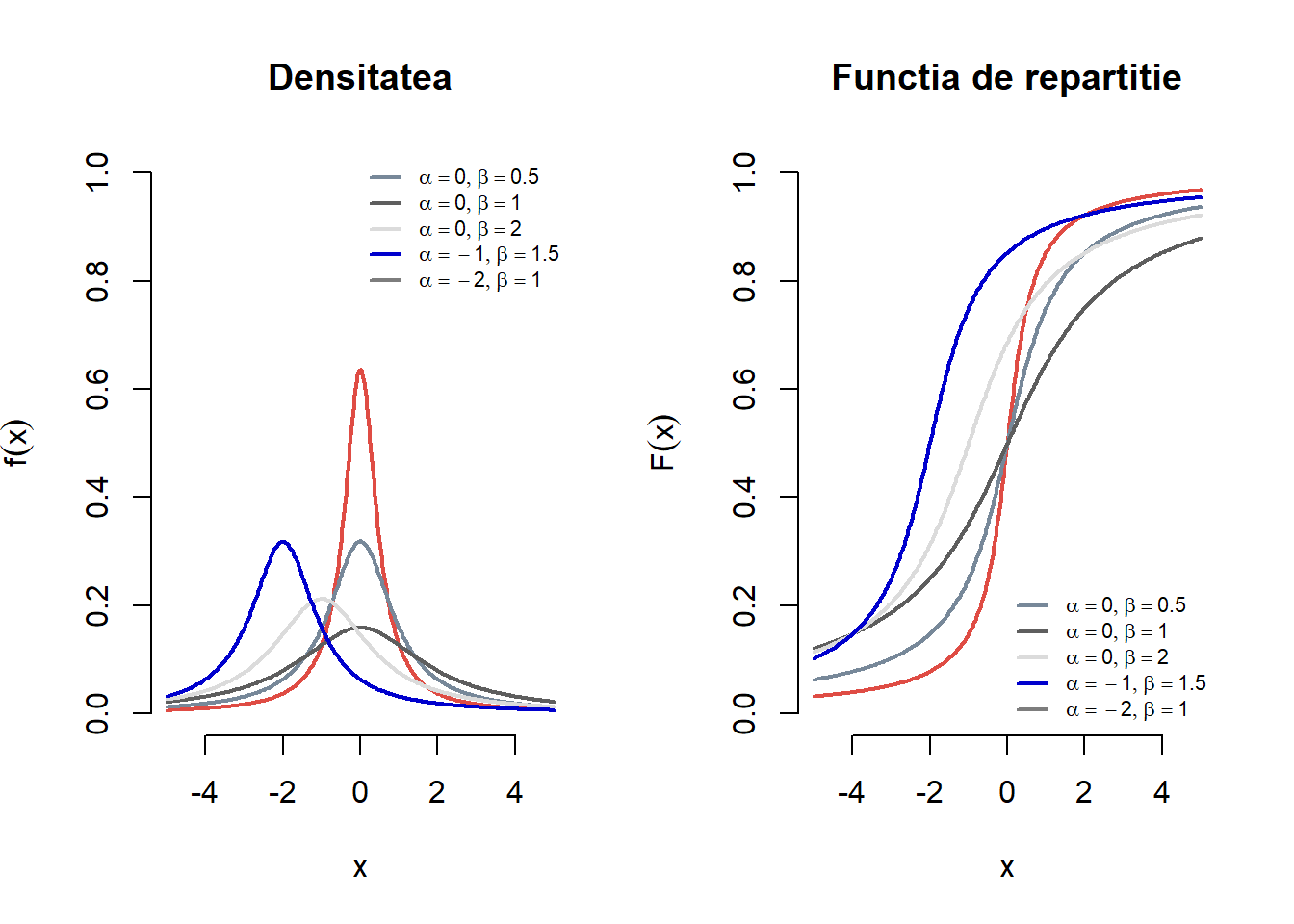
Exercițiul 2.15 Fie \(X\) o variabilă aleatoare repartizată Cauchy \(C(\alpha, \beta)\). Pentru fiecare pereche de parametrii \((\alpha, \beta)\) din mulțimea \(\{(0,0.5), (0, 1), (0, 2), (-1, 1.5), (-2, 1)\}\) trasați pe același grafic densitățile repartițiilor Cauchy cu parametrii \((\alpha, \beta)\). Adăugați legendele corespunzătoare. Aceeași cerință pentru funcțiile de repartiție.
Figura 2.15: Densitatea și funcția de repartiție pentru o serie de repartiții Cauchy \(C(\alpha, \beta)\).
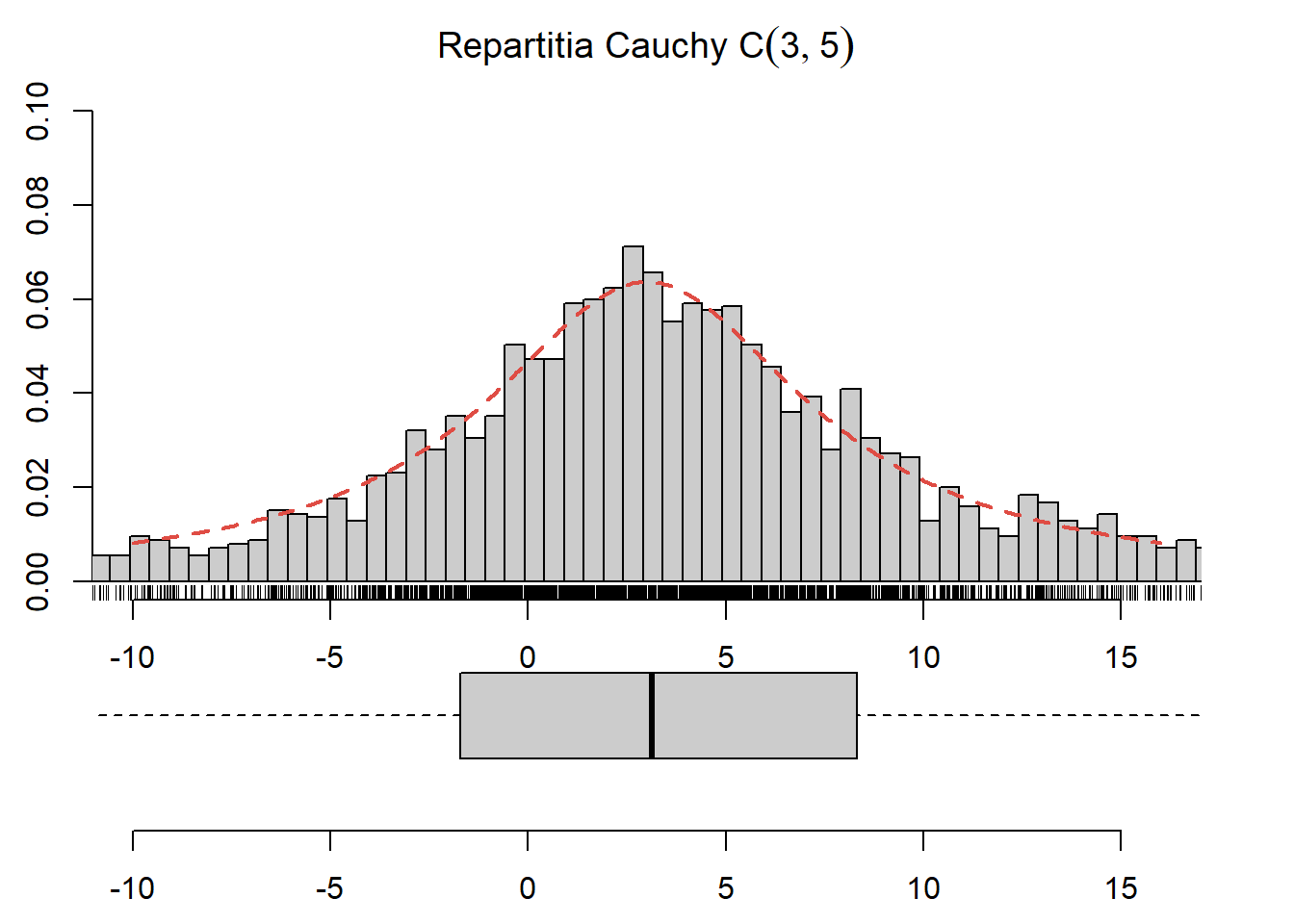
Exercițiul 2.16 Folosind rezultatul de universalitate de la repartiția uniformă, descrieți o procedură prin care puteți simula o variabilă aleatoare repartizată Cauchy \(C(0,1)\) și construiți o funcție care permite generarea de \(n\) observații independente dintr-o variabilă repartizată \(X\sim C(\alpha, \beta)\). Verificați pentru parametrii \(\alpha = 3\) și \(\beta = 5\) (a se vedea Figura 2.16).
Figura 2.16: Histograma observațiilor generate din repartiția Cauchy \(C(3,5)\).
Exercițiul 2.17 Fie \(X\) și \(Y\) două variabile aleatoare independente repartizate \(\mathcal{N}(0,1)\). Arătați că variabila aleatoare \(\frac{X}{Y}\) este repartizată Cauchy \(C(0,1)\).
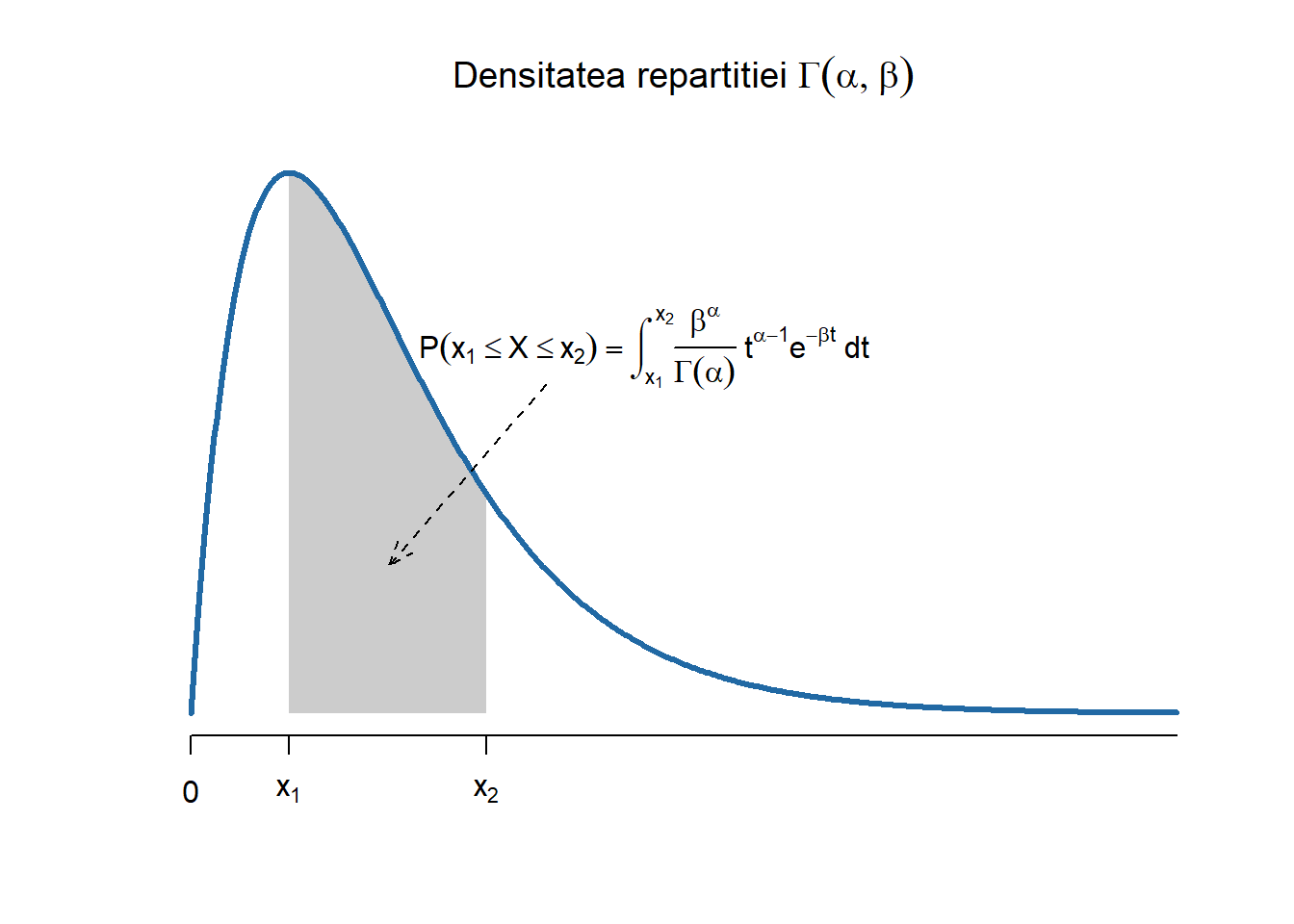
Repartiția Gama \(\Gamma(\alpha,\beta)\)
Definiția 2.6 (Variabilă aleatoare repartizată Gama) Spunem că o variabilă aleatoare \(X\) este repartizată Gama de parametrii \((\alpha, \beta)\), cu \(\alpha, \beta > 0\), și se notează cu \(X\sim \Gamma(\alpha,\beta)\), dacă densitatea ei are forma
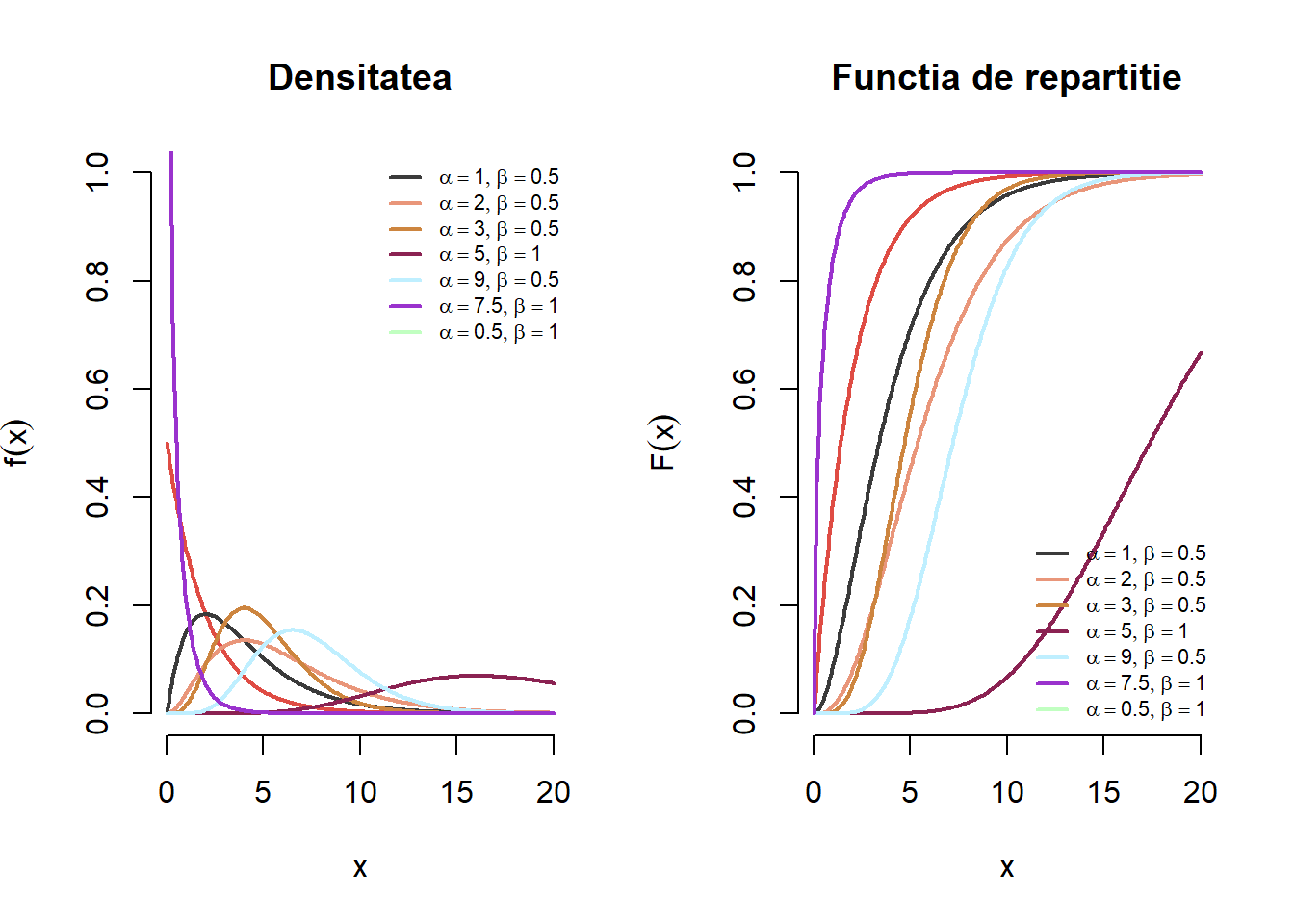
Exercițiul 2.20 Fie \(X\) o variabilă aleatoare repartizată \(\Gamma(\alpha, \beta)\). Pentru fiecare pereche de parametrii \((\alpha, \beta)\) din mulțimea \(\{(1,0.5), (2, 0.5), (3, 0.5), (5, 1), (9, 0.5), (7.5, 1), (0.5, 1) \}\) trasați pe același grafic densitățile repartițiilor Gama cu parametrii \((\alpha, \beta)\). Adăugați legendele corespunzătoare. Aceeași cerință pentru funcțiile de repartiție.
Figura 2.18: Ilustrarea densității și a funcției de repartiție pentru o serie de parametrii a repartiției Gamma \(\Gamma(\alpha,\beta)\).
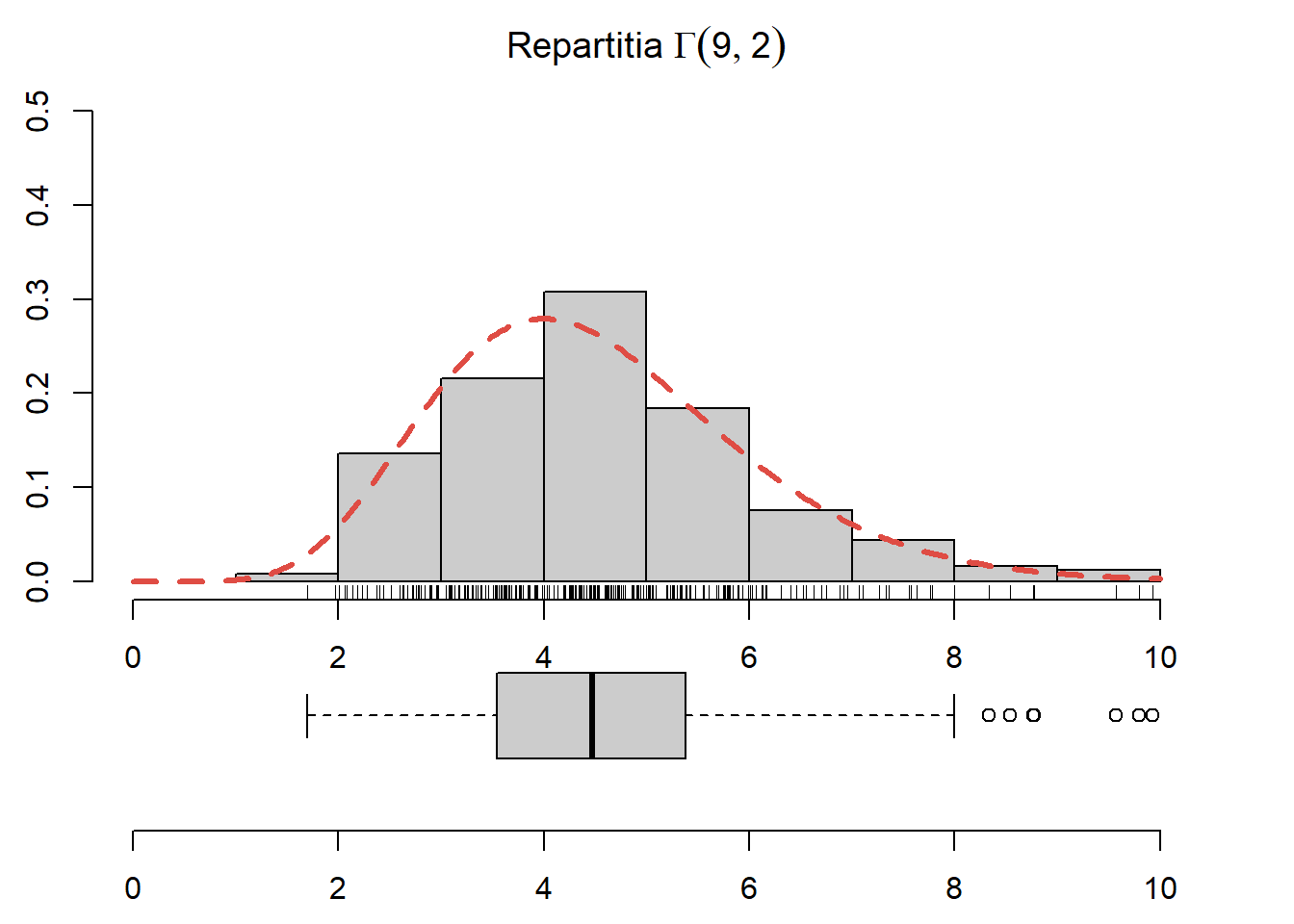
Exercițiul 2.21 Generați \(250\) de observații din repartiția \(\Gamma(9,2)\), trasați histograma acestora și suprapuneți densitatea repartiției date (vezi Figura 2.19).
Figura 2.19: Histograma observațiilor generate din repartiția \(\Gamma(9,2)\).
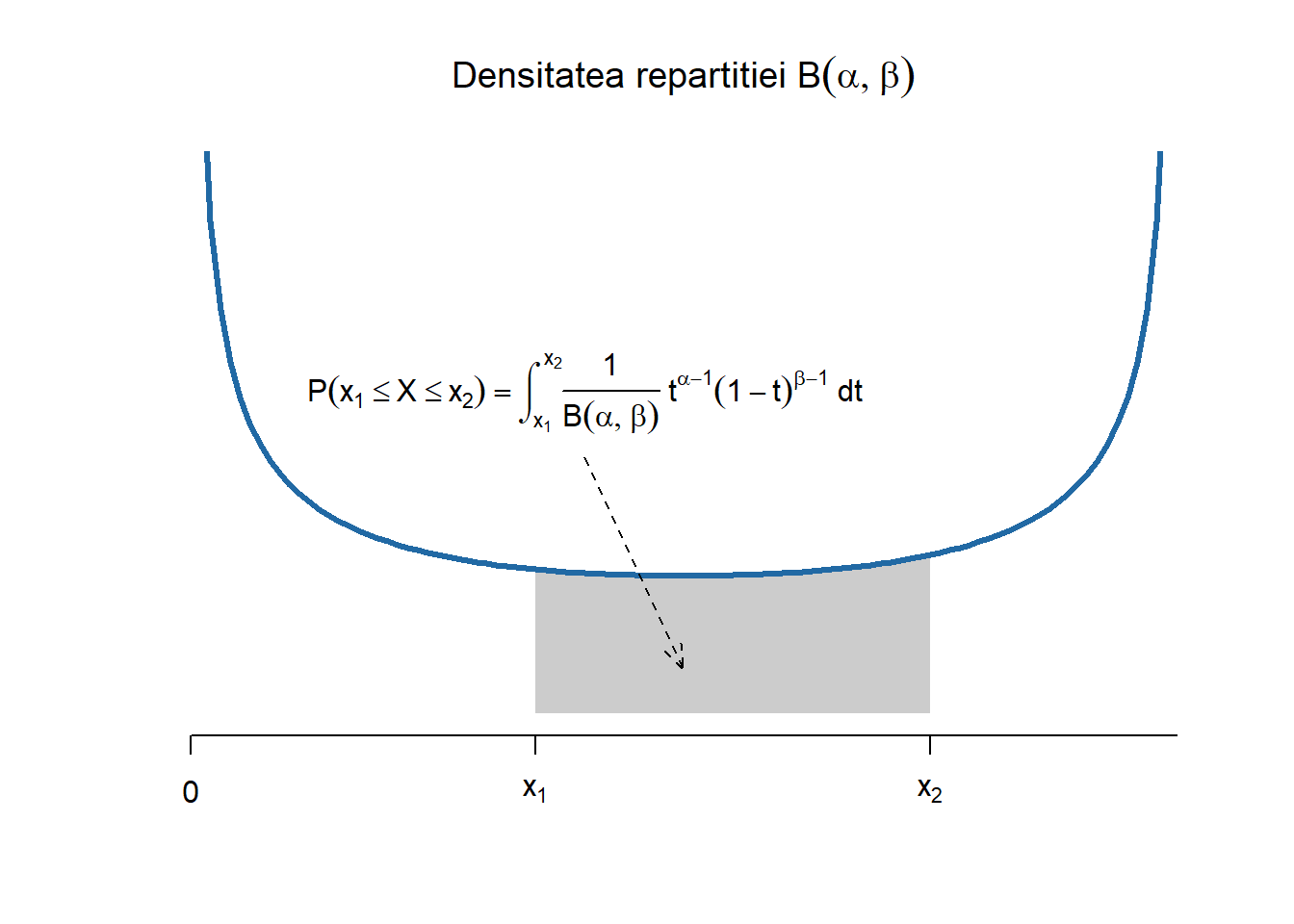
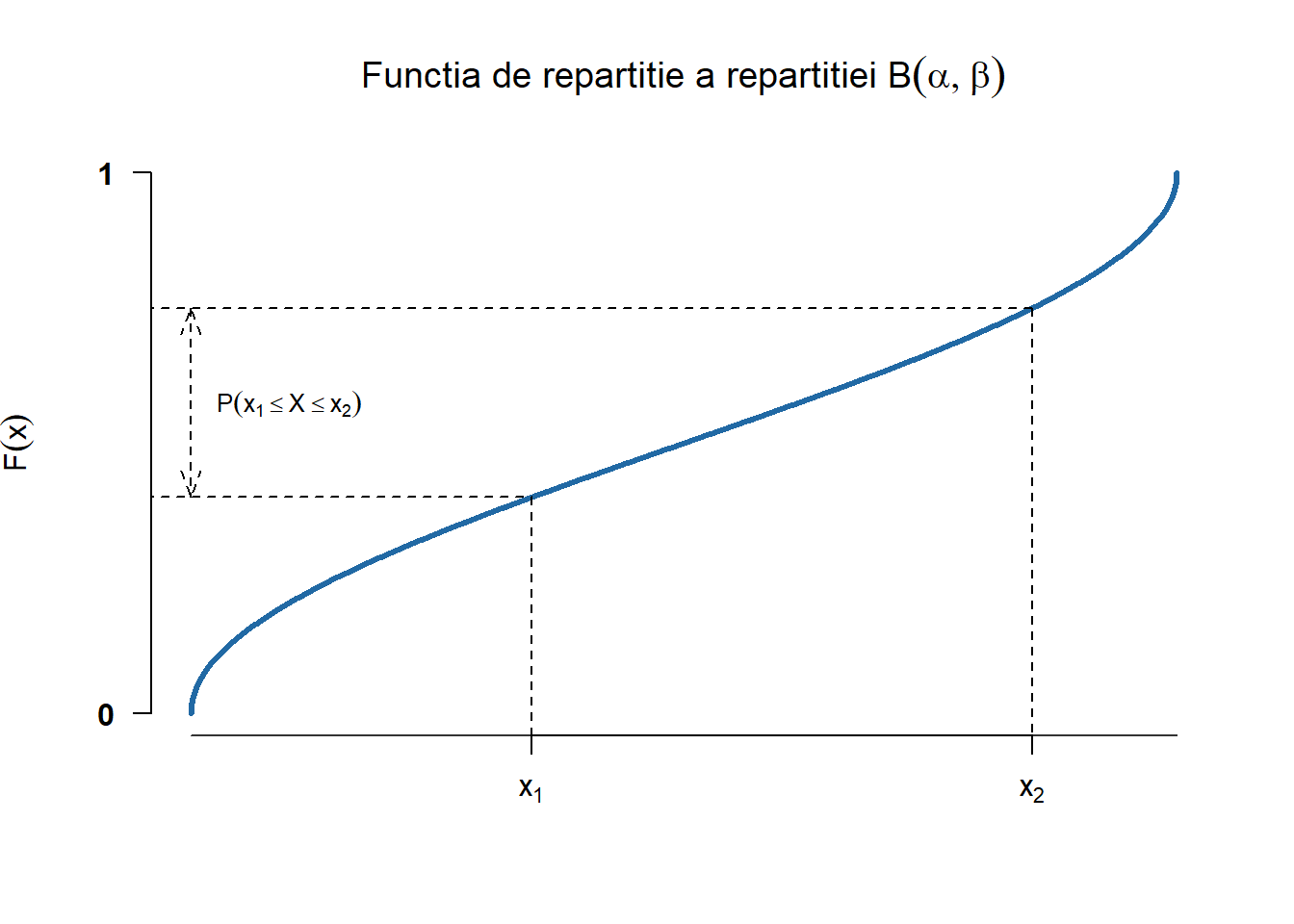
Repartiția Beta \(B(\alpha,\beta)\)
Definiția 2.7 (Variabilă aleatoare repartizată Beta) Spunem că o variabilă aleatoare \(X\) este repartizată Beta de parametrii \((\alpha, \beta)\), cu \(\alpha, \beta > 0\), și se notează cu \(X\sim B(\alpha,\beta)\), dacă densitatea ei are forma
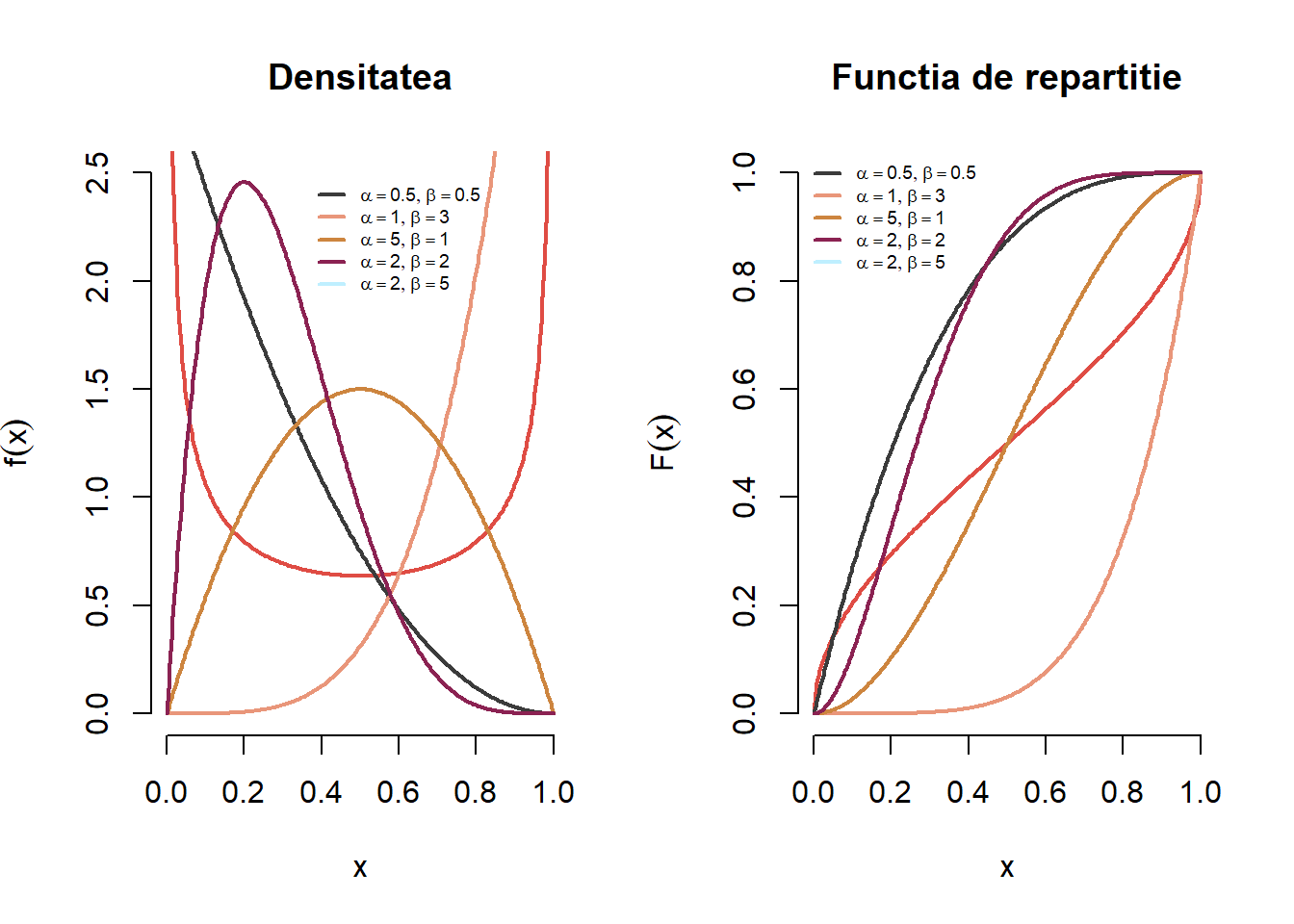
Exercițiul 2.24 Fie \(X\) o variabilă aleatoare repartizată \(B(\alpha, \beta)\). Pentru fiecare pereche de parametrii \((\alpha, \beta)\) din mulțimea \(\{(0.5,0.5), (1, 3), (5, 1), (2, 2), (2, 5)\}\) trasați pe același grafic densitățile repartițiilor Beta cu parametrii \((\alpha, \beta)\). Adăugați legendele corespunzătoare. Aceeași cerință pentru funcțiile de repartiție.
Figura 2.21: Densitatea și funcția de repartiție a repartiției Beta \(B(\alpha,\beta)\) pentru o serie de parametrii.
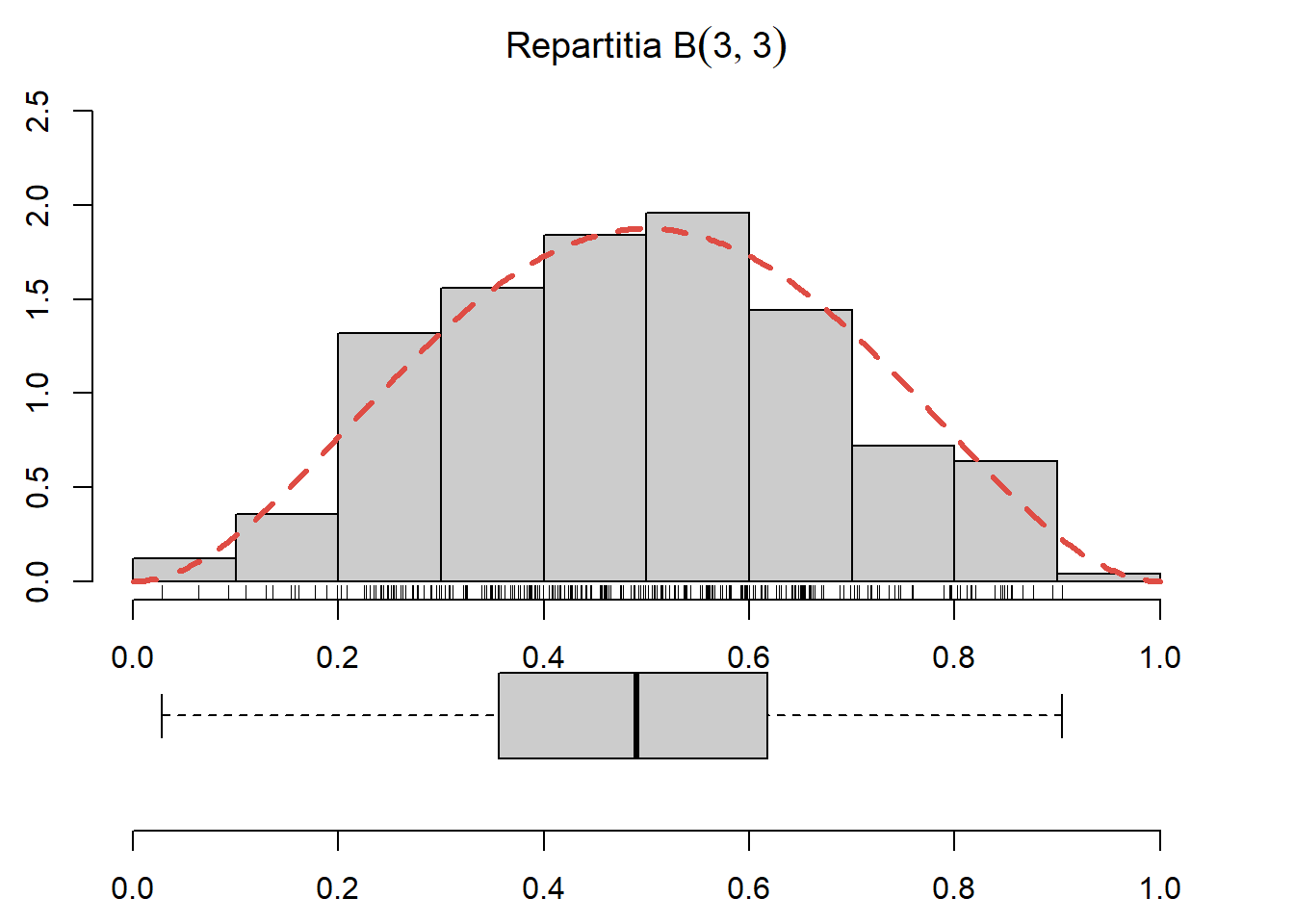
Exercițiul 2.25 Generați \(250\) de observații din repartiția \(B(3,3)\), trasați histograma acestora și suprapuneți densitatea repartiției date (vezi Figura 2.22).
Figura 2.22: Histograma observațiilor generate din repartiția Beta \(B(3,3)\) și densitatea teoretică suprapusă.
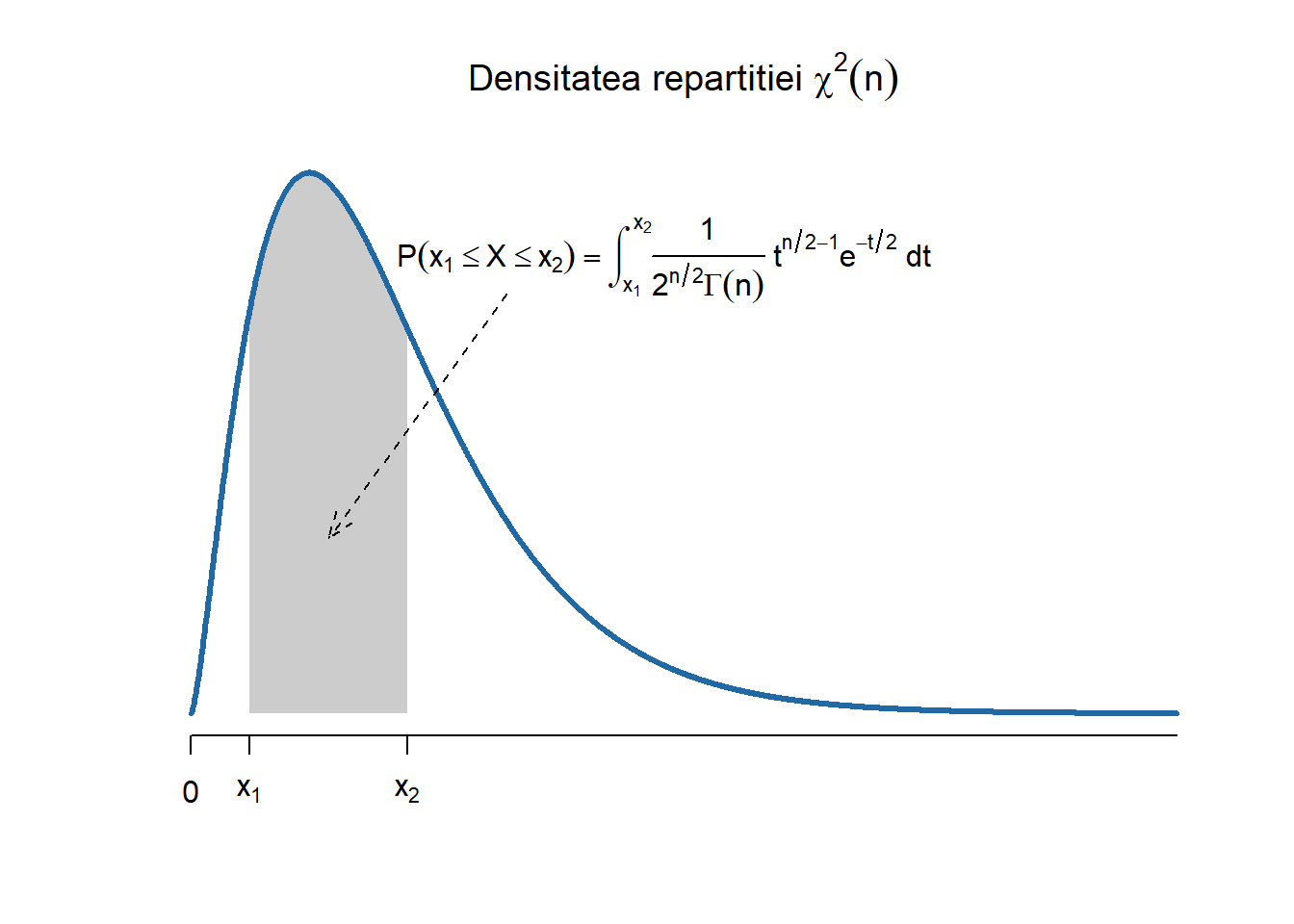
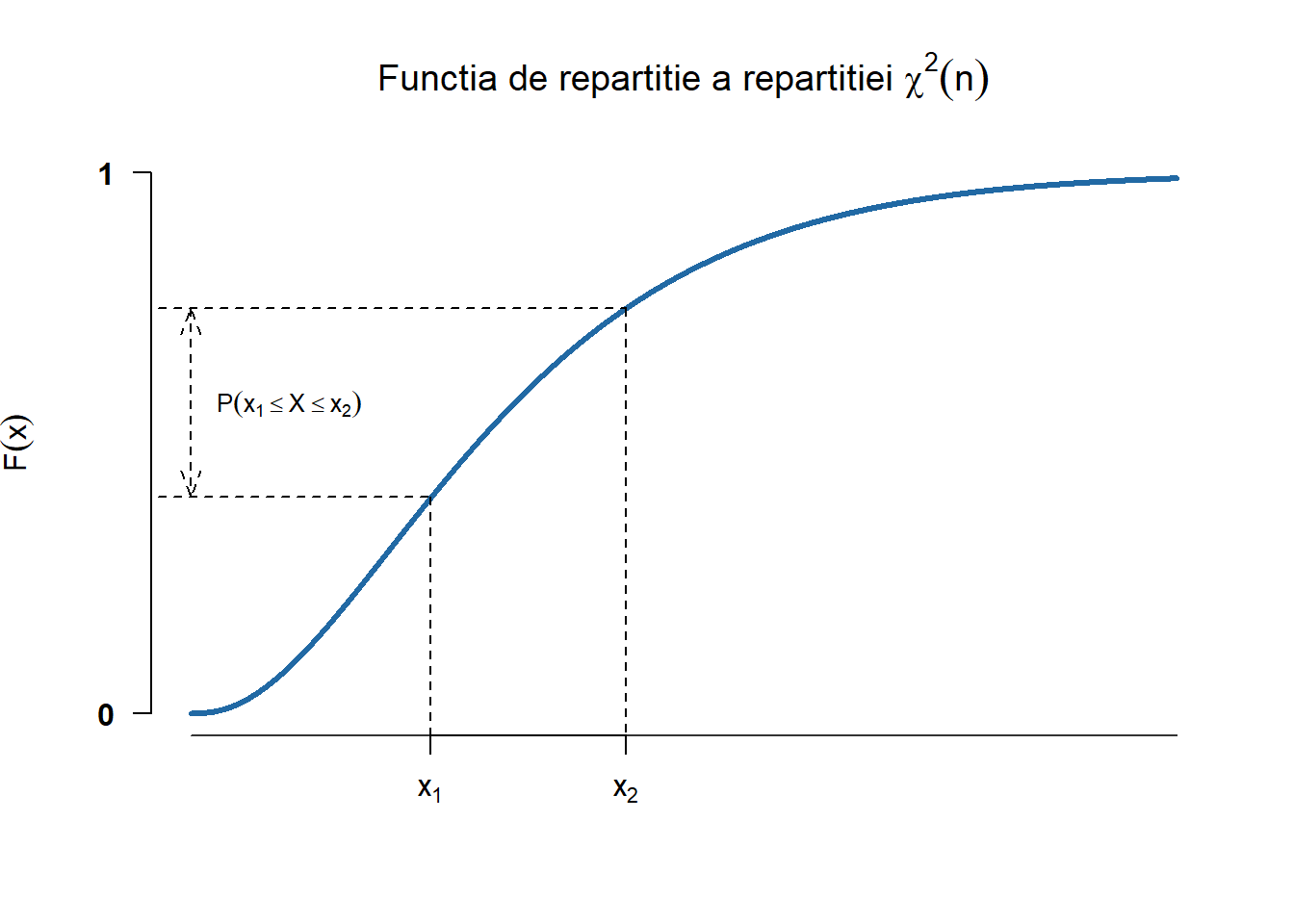
Repartiția \(\chi^2(n)\)
Definiția 2.8 (Variabilă aleatoare repartizată \(\chi^2(n)\)) Spunem că o variabilă aleatoare \(X\) este repartizată \(\chi^2\) (Hi-pătrat) cu \(n\) grade de libertate și se notăm cu \(X\sim \chi^2(n)\) (sau încă \(X\sim \chi^2_n\)) dacă admite densitatea de repartiție
unde \(\Gamma(\cdot)\) este funcția Gamma dată de \(\Gamma(x)=\int_{0}^{\infty} u^{x-1} \mathrm{e}^{-u} \mathrm{d} u, x>0\).
NoteRemarcă
Se poate observa cu ușurință că repartiția \(\chi^2(n)\) este un caz particular al repartiției \(\Gamma(\alpha, \beta)\), mai precis pentru \(\alpha = \frac{n}{2}\) și respectiv \(\beta=\frac{1}{2}\).
(a) Densitatea
(b) Funcția de repartiție
Figura 2.23: Densitatea și funcția de repartiție a repartiției \(\chi^2(n)\).
Exercițiul 2.26 Arătați că dacă \(X\sim \mathcal{N}(0, 1)\) atunci \(Y=X^2\sim\chi^2(1)\).
Soluție. Să observăm pentru început că dacă \(y<0\) atunci
Exercițiul 2.27 (Rezultat de caracterizare a repartiției \(\chi^2(n)\)) Dacă \(X_1,\ldots,X_n\) sunt variabile aleatoare i.i.d. repartizate \(\mathcal{N}(0, 1)\) atunci variabila aleatoare \(X = \sum_{i = 1}^{n}X_i^2\) este repartizată \(\chi^2(n)\).
Soluție. Vom arăta pentru început că dacă \(X\sim \chi^2(n)\) iar \(Y\sim \chi^2(m)\) cu \(X\) și \(Y\) independente atunci
\[
X + Y \sim \chi^2(n + m).
\]
Știm că dacă \(X\sim f_{X}\), \(Y\sim f_{Y}\) și \(X\) și \(Y\) independente atunci densitatea sumei \(X+Y\) este dată de
Am văzut în exercițiul anterior că dacă \(X_i\sim\mathcal{N}(0, 1)\) atunci \(X_i^2\sim\chi^2(1)\). Cum \(X_1,\ldots,X_n\) sunt variabile aleatoare i.i.d. repartizate \(\mathcal{N}(0, 1)\) rezultă că \(X_1^2,\ldots,X_n^2\) sunt variabile aleatoare i.i.d. repartizate \(\chi^2(1)\). Aplicând identitatea sumei de mai sus pentru variabile \(\chi^2\) independente obținem concluzia.
Alternativ, acest rezultat se poate demonstra ușor folosind noțiunea de funcție generatoare de moment. De exemplu, funcția generatoare de moment pentru \(X\sim\chi^2(n)\) este dată de
Din ipoteză avem că \(X = \sum_{i = 1}^{n}X_i^2\), unde \(X_i^2\) sunt variabile aleatoare independente repartizate \(\chi^2(1)\) prin urmare \(M_{X_i^2}(t) = (1-2 t)^{-1 / 2}\). Știm că funcția generatoare de moment a unei sume de variabile aleatoare independente este egală cu produsul funcțiilor generatoare de moment, astfel
ceea ce arată că funcția generatoare de moment a lui \(X\) coincide cu cea a repartiției \(\chi^2(n)\). Din teorema de unicitate a funcțiilor generatoare de moment avem concluzia.
Exercițiul 2.28 Pentru o v.a. \(X\sim \chi^2(n)\) avem că \(\mathbb{E}[X] = n\) și \(Var(X) = 2n\).
Soluție. Într-adevăr, ținând cont că \(X = \sum_{i = 1}^{n}X_i^2\), cu \(X_i\sim\mathcal{N}(0, 1)\), și că \(\mathbb{E}\left[X_i^2\right]=1\) avem că
Exercițiul 2.29 Fie \(X\) o variabilă aleatoare repartizată \(\chi^2(n)\). Pentru fiecare \(n\in\{1, 3, 9\}\) trasați pe același grafic densitățile repartițiilor \(\chi^2(n)\) corespunzătoare. Adăugați legendele aferente. Aceeași cerință pentru funcțiile de repartiție.
Figura 2.24: Ilustrarea densității și a funcției de repartiție a repartiției \(\chi^2_n\) pentru o serie de parametrii.
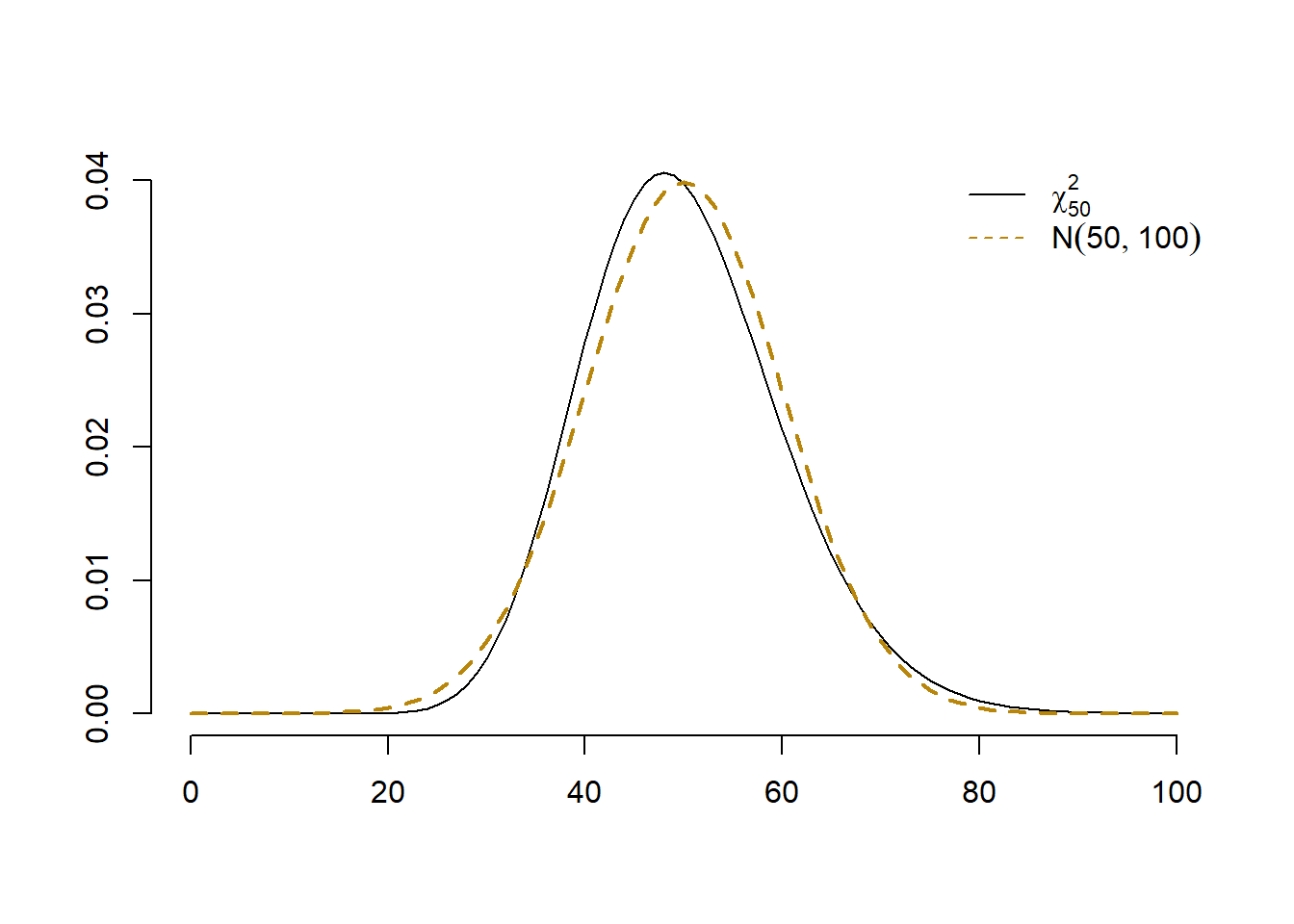
Din Teorema Limită Centrală avem că pentru \(n\) suficient de mare, \(X\approx \mathcal{N}(n, 2n)\) ceea ce sugerează că aproximativ \(95\%\) dintre valori se situează în intervalul \([n - 2\sqrt{2n}, n + 2\sqrt{2n}]\).
Figura 2.25: Aproximarea densității repartiției \(\chi^2_n\) cu normala \(\mathcal{N}(n, 2n)\).
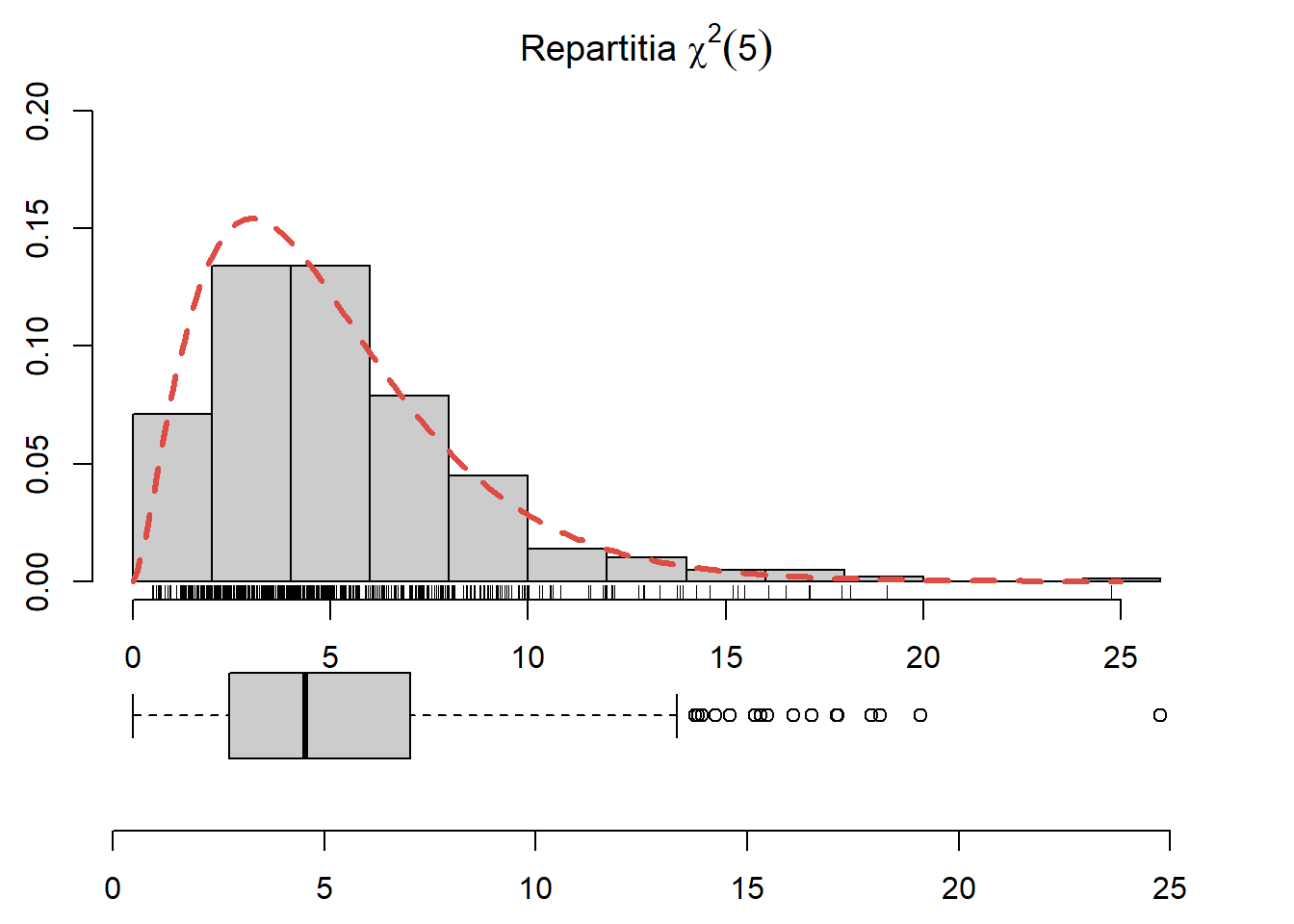
Exercițiul 2.30 Generați \(250\) de observații din repartiția \(\chi^2(5)\), trasați histograma acestora și suprapuneți densitatea repartiției date (vezi Figura 2.26).
Figura 2.26: Histograma observațiilor generate din repartiția \(\chi^2(5)\) și densitatea teoretică suprapusă.
Repartiția \(t\)-Student
Repartiția Student sau t-Student este numită după un autor care a publicat în revista Biometrika în anul 1908 un articol care făcea referire la această repartiție sub pseudonimul Student. În realitate, cel care a publicat articolul era William Sealy Gosset.
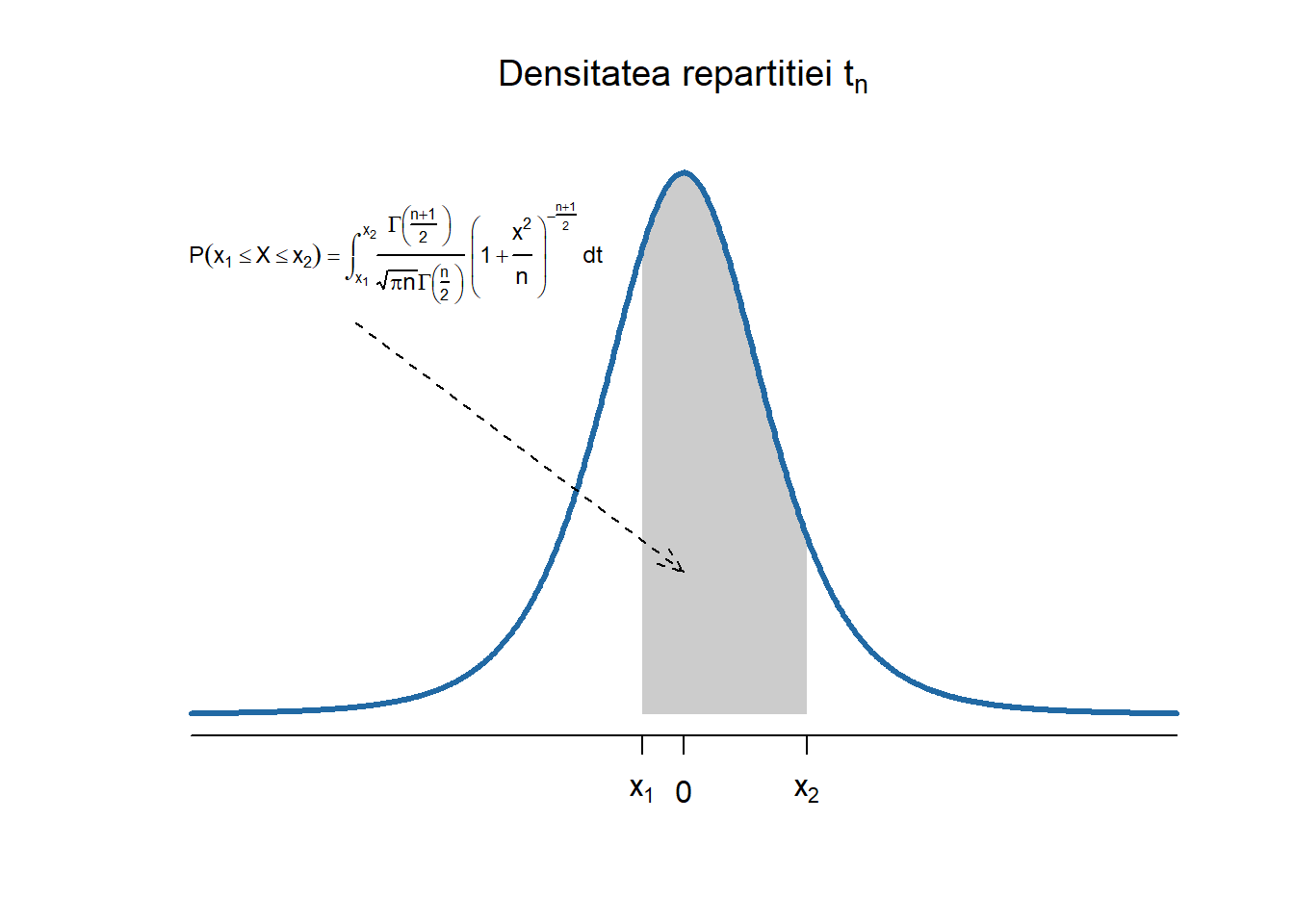
Definiția 2.9 (Variabilă aleatoare repartizată Student) Spunem că variabila aleatoare \(T\) este repartizată Student cu \(n\) grade de libertate și notăm cu \(T\sim t_n\) (sau încă \(T\sim t(n)\)) dacă \(T\) admite densitatea de repartiție
\[
f_n(x)=\frac{\Gamma\left(\frac{n+1}{2}\right)}{\sqrt{\pi n}\Gamma\left(\frac{n}{2}\right)}\left(1+\frac{x^{2}}{n}\right)^{-\frac{n+1}{2}},\, x \in \mathbb{R}
\]
(a) Densitatea
(b) Funcția de repartiție
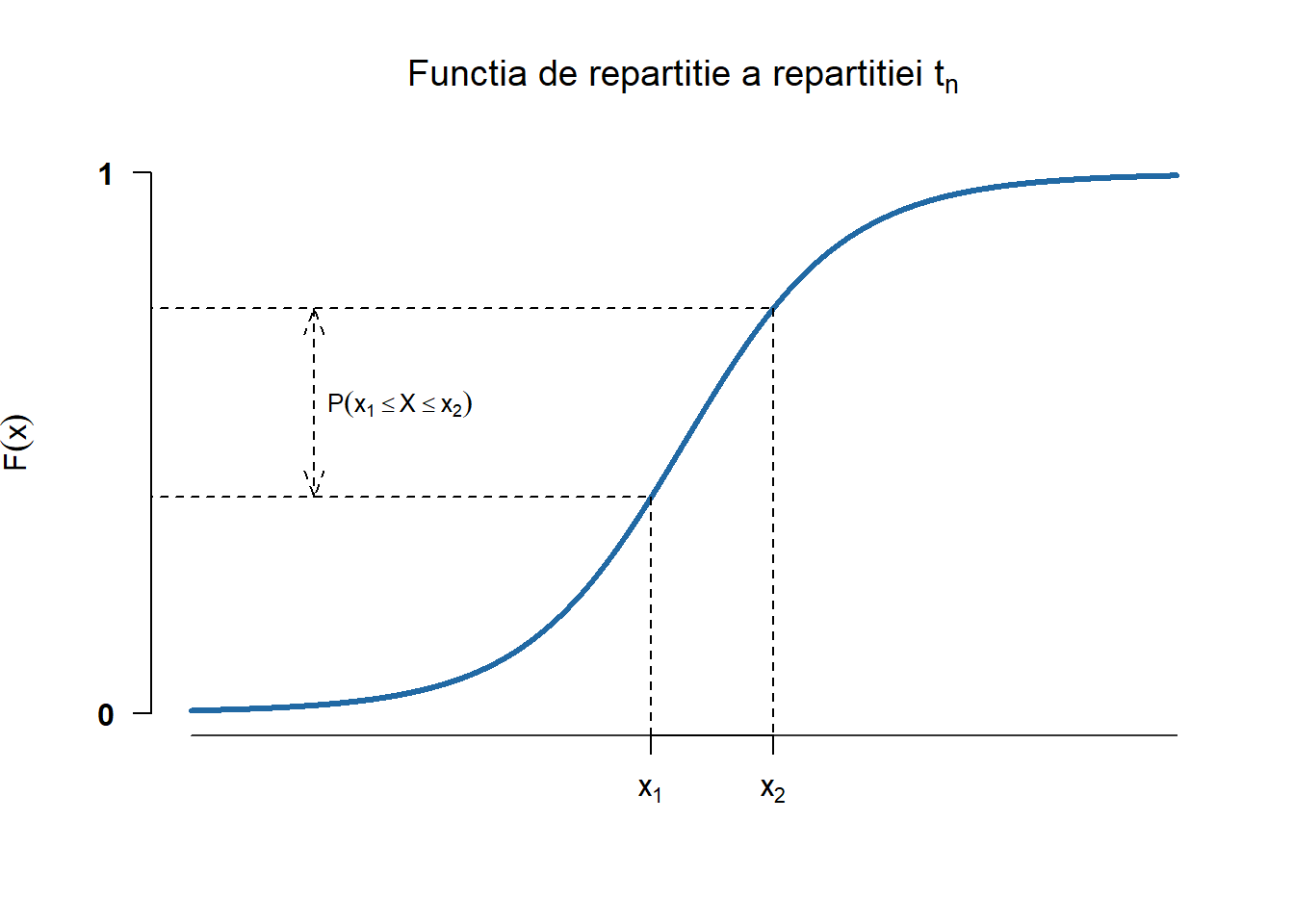
Figura 2.27: Densitatea și funcția de repartiție a repartiției Student \(t_n\).
Avem următorul rezultat:
Exercițiul 2.31 (Rezultat de caracterizare a repartiției Student) Fie \(U\) o variabilă aleatoare repartizată \(\mathcal{N}(0, 1)\) și \(V\) o variabilă repartizată \(\chi^2(n)\), cu \(U\) și \(V\) independente, atunci variabila aleatoare \(T = \frac{U}{\sqrt{\frac{V}{n}}}\) este repartizată Student cu \(n\) grade de libertate.
Soluție. Vom determina pentru început repartiția comună a vectorului \((T, V)\) și, plecând de la aceasta, vom găsi repartiția marginală a lui \(T\). În acest sens considerăm transformarea
de unde găsim determinantul \(\operatorname{det}\left(J_{g^{-1}}(t, v)\right)=\sqrt{\frac{v}{n}}\). Cum \(U\) și \(V\) sunt independente rezultă că densitatea comună a vectorului \((U,V)\) este
\[
f_T(t)=\frac{1}{2^{\frac{n}{2}} \sqrt{2\pi n} \Gamma\left(\frac{n}{2}\right)} \int_0^{\infty} e^{-\frac{v}{2}\left(\frac{t^2}{n}+1\right)} v^{\frac{n+1}{2}-1} d v
\]
și considerând schimbarea de variabilă \(y = \frac{v}{2}\left(\frac{t^2}{n}+1\right)\) găsim \(v = \frac{2y}{\frac{t^2}{n}+1}\) de unde \(d v = \frac{2}{\frac{t^2}{n}+1} d y\) ceea ce conduce la
Ca aplicație fundamentală a acestui rezultat, să observăm că dacă \(X_1,\ldots,X_n\) este un eșantion de volum \(n\) dintr-o populație \(\mathcal{N}(\mu,\sigma^2)\) atunci
Dacă \(T\sim t_n\) și \(n = 1\) atunci variabila \(T\) este repartizată Cauchy (raport de două normale independente) și prin urmare nu are medie (evident nici varianță). Dacă \(n = 2\) atunci \(T\) este de medie \(0\) dar de varianță infinită iar pentru \(n\geq 3\), \(\mathbb{E}[T] = 0\) și \(Var(T) = \frac{n}{n-2}\).
În R putem să
generăm observații independente din repartiția \(t_n\) (e.g. \(n = 3\))
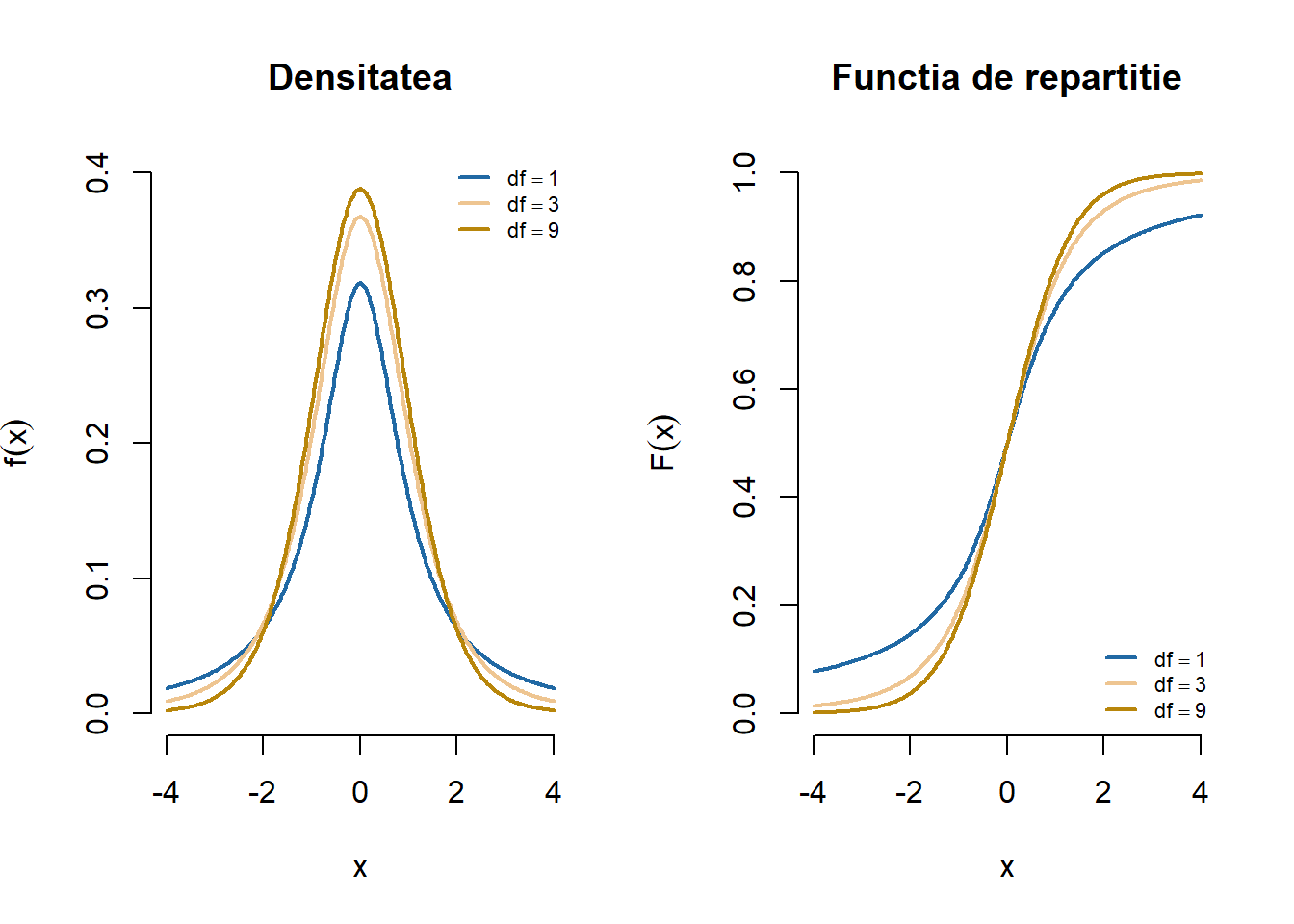
Exercițiul 2.32 Fie \(X\) o variabilă aleatoare repartizată \(t_n\). Pentru fiecare \(n\in\{1, 3, 9\}\) trasați pe același grafic densitățile repartițiilor \(t_n\) corespunzătoare. Adăugați legendele aferente. Aceeași cerință pentru funcțiile de repartiție.
Figura 2.28: Ilustrarea densității și a funcției de repartiție a repartiției \(t_n\) pentru o serie de grade de libertate.
Exercițiul 2.33 Arătați că pentru \(n\) suficient de mare avem că \(T\approx \mathcal{N}(0,1)\) (de exemplu observând că, din Legea Numerelor Mari, numitorul tinde la \(1\) atunci când \(n\to\infty\)). Ilustrați grafic acest fenomen.
Figura 2.29: Aproximarea densității repartiției \(t_n\) cu normala \(\mathcal{N}(0,1)\).
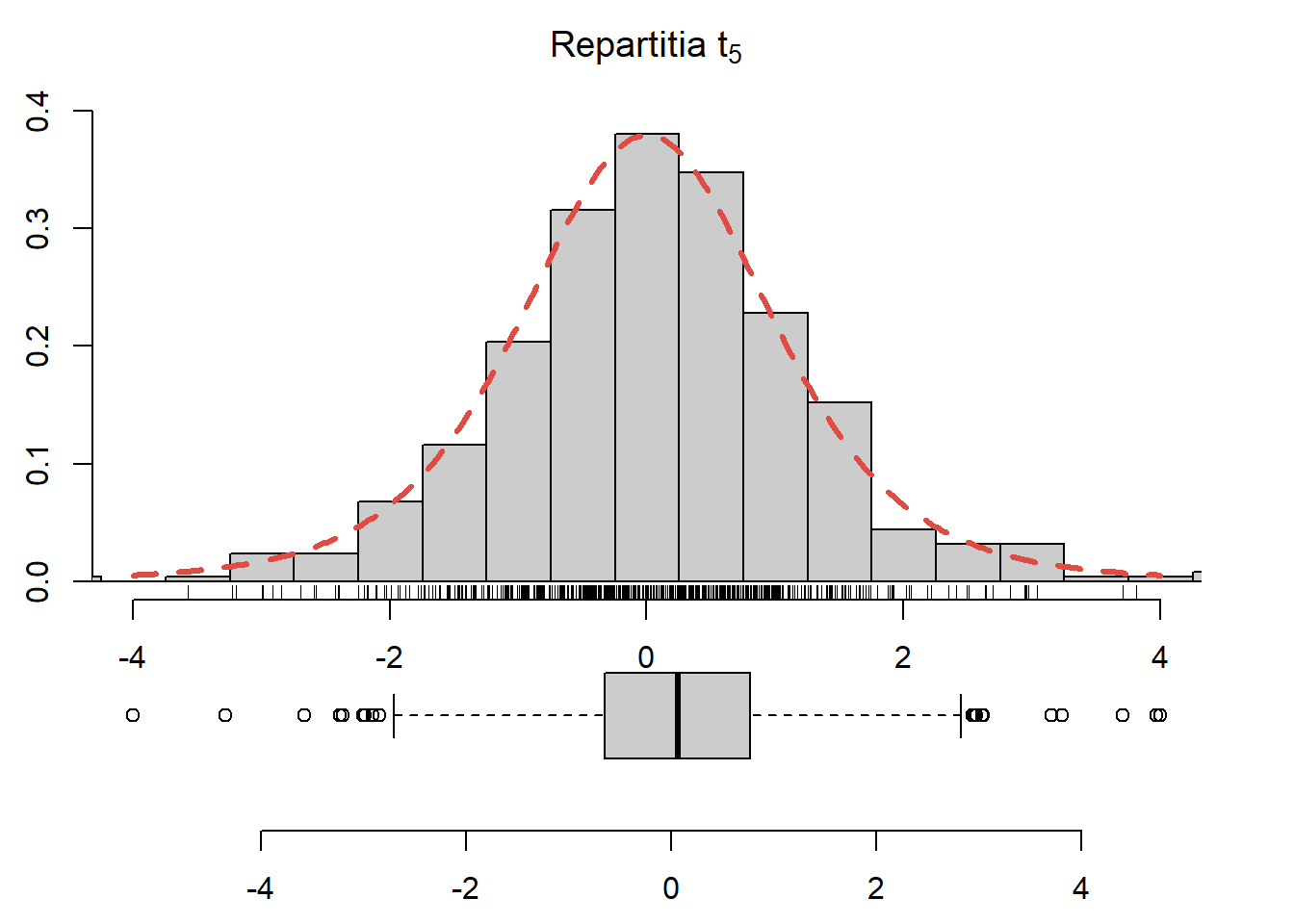
Exercițiul 2.34 Generați \(250\) de observații din repartiția \(t_5\), trasați histograma acestora și suprapuneți densitatea repartiției date (vezi Figura 2.30).
Figura 2.30: Histograma observațiilor generate din repartiția \(t_5\) și densitatea teoretică suprapusă.
Repartiția Fisher-Snedecor
Definiția 2.10 (Variabilă aleatoare repartizată Fisher-Snedecor) Spunem că o variabilă aleatoare \(F\) este repartizată Fisher-Snedecor (sau pe scurt are repartiția \(F\) sau Fisher) cu \(n_1\) grade de libertate la numărător și \(n_2\) grade de libertate la numitor și notăm \(F\sim F_{n_1,n_2}\) dacă admite densitatea de repartiție
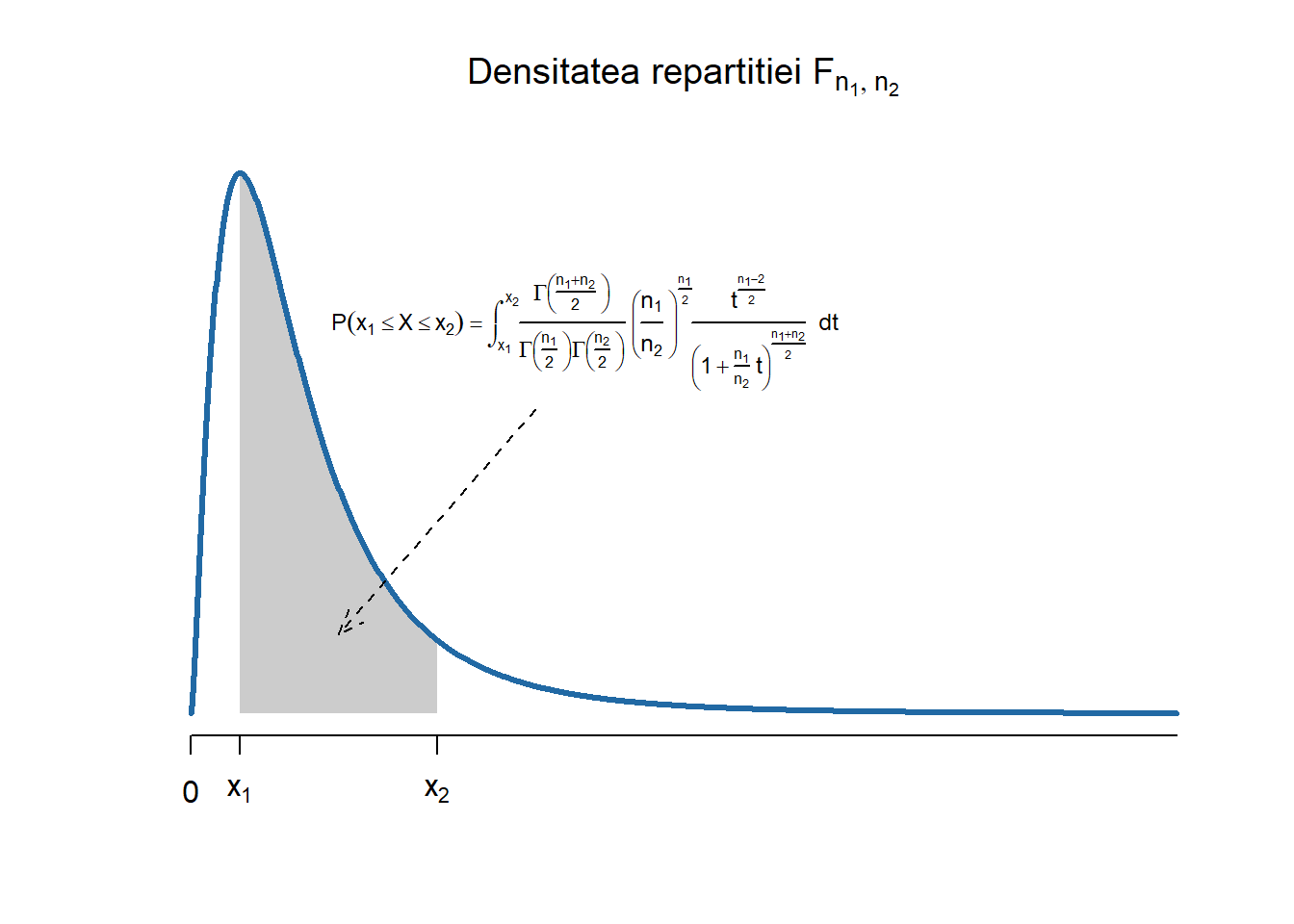
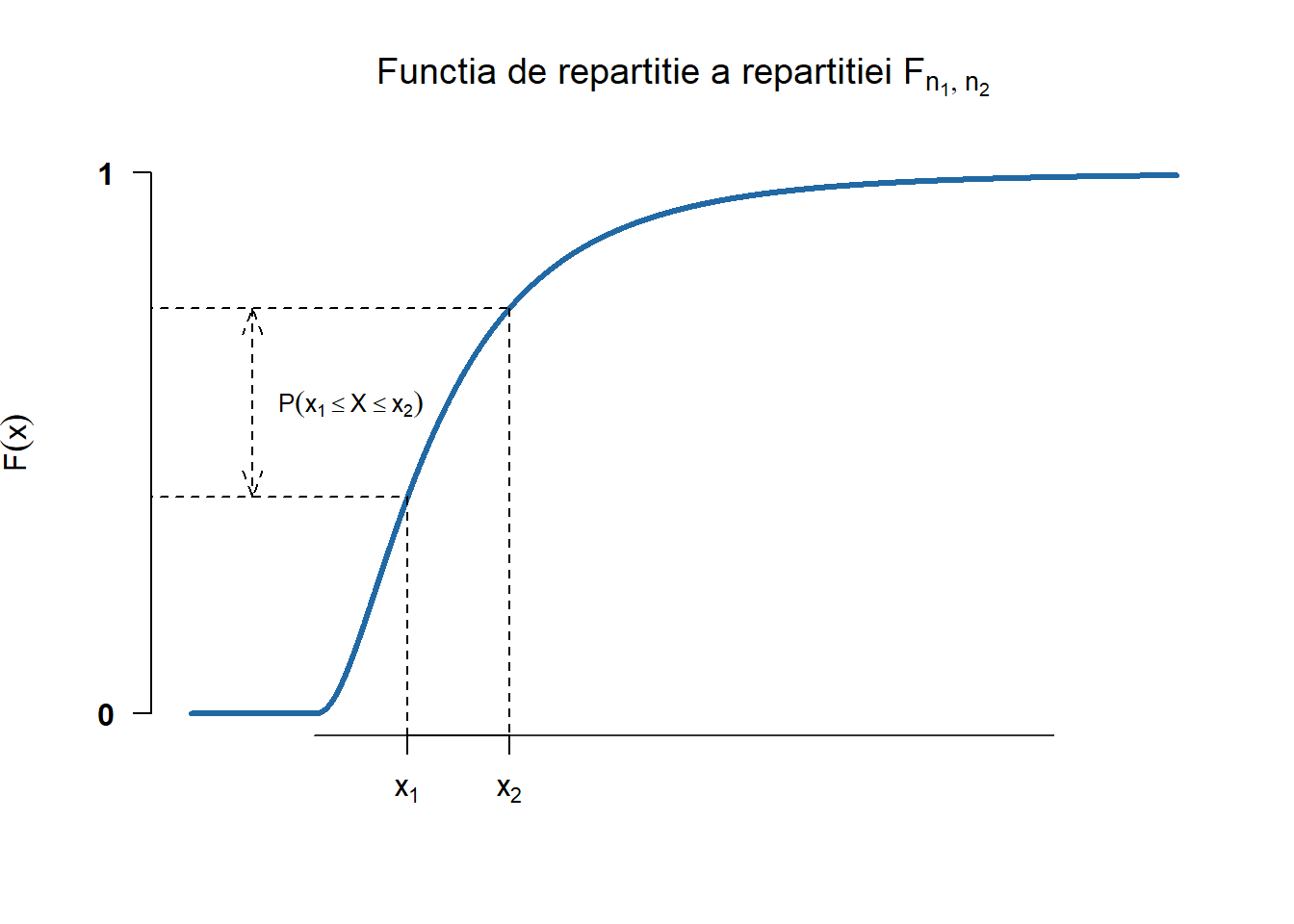
Figura 2.31: Densitatea și funcția de repartiție a repartiției Fisher-Snedecor \(F_{n_1,n_2}\).
NoteRemarcă
Pentru \(n_2\geq 3\) media variabilei aleatoare \(F\) există și este egală cu \(\frac{n_2}{n_2-2}\) iar pentru \(n_2\geq 5\) varianța există și este egală cu \(\frac{2 n_{2}^{2}\left(n_{1}+n_{2}-2\right)}{n_{1}\left(n_{2}-2\right)^{2}\left(n_{2}-4\right)}\).
Avem următorul de rezultat:
Exercițiul 2.35 (Rezultat de caracterizare a repartiției Fisher) Fie \(U\) o variabilă aleatoare repartizată \(\chi^2_{n_1}\) și \(V\) o variabilă aleatoare repartizată \(\chi^2_{n_2}\), cu \(U\) și \(V\) independente. Atunci variabila aleatoare \(F = \frac{U/n_1}{V/n_2}\) este repartizată Fisher-Snedecor cu \(n_1\) grade de libertate la numărător și \(n_2\) grade de libertate la numitor.
Soluție. Vom determina pentru început repartiția comună a vectorului \((F, V)\) și, plecând de la aceasta, vom găsi repartiția marginală a lui \(F\). În acest sens considerăm transformarea
de unde găsim determinantul \(\operatorname{det}\left(J_{g^{-1}}(f, v)\right)=\frac{n_1}{n_2}v\). Cum \(U\) și \(V\) sunt independente rezultă că densitatea comună a vectorului \((U,V)\) este egală cu produsul densităților marginale,
și considerând schimbarea de variabilă \(y = \frac{v}{2}\left(\frac{n_1}{n_2}f + 1\right)\) găsim \(v = \frac{2y}{\frac{n_1}{n_2}f + 1}\) de unde \(d v = \frac{2}{\frac{n_1}{n_2}f + 1} d y\), \(y\in[0,\infty)\) ceea ce conduce la
Ca aplicație fundamentală a acestui rezultat avem:
NoteRemarcă
Fie \(X_1, \ldots,X_n\stackrel{\mathrm{iid}}{\sim} \mathcal{N}\left(\mu_1, \sigma^2\right)\) și \(Y_1, \ldots,Y_m\stackrel{\mathrm{iid}}{\sim} \mathcal{N}\left(\mu_2, \sigma^2\right)\) de eșantioane de volume \(n\) și respectiv \(m\) din populații normale de medii diferite și de aceeași dispersie. Dacă \(X_i\) și \(Y_j\) sunt independente între ele atunci
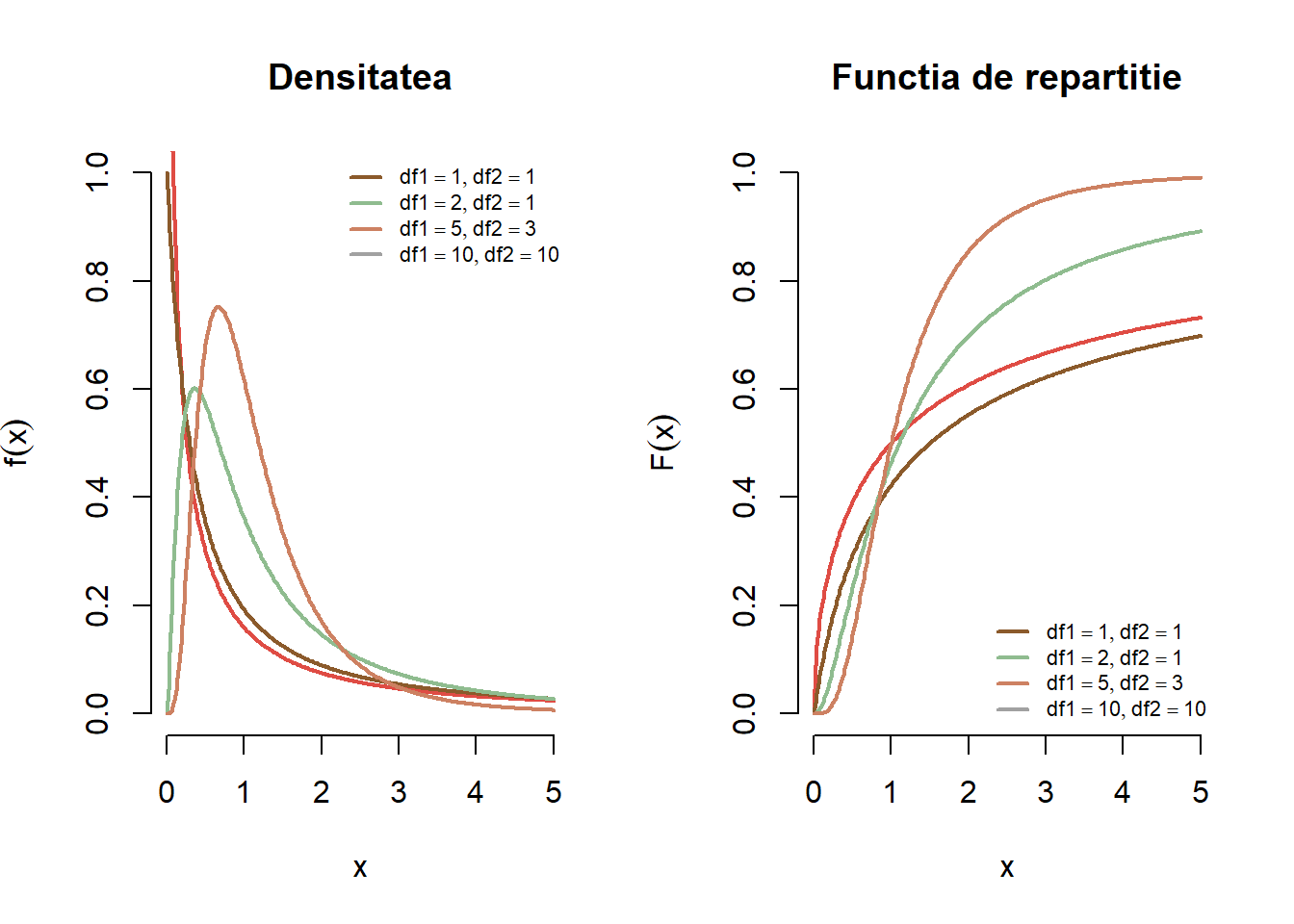
Exercițiul 2.36 Fie \(X\) o variabilă aleatoare repartizată \(F_{n_1,n_2}\). Pentru fiecare pereche de parametrii \((n_1,n_2)\) din mulțimea \(\{(1,1), (2, 1), (5, 3), (10,10)\}\) trasați pe același grafic densitățile repartițiilor Fisher cu parametrii \((n_1,n_2)\). Adăugați legendele corespunzătoare. Aceeași cerință pentru funcțiile de repartiție.
Figura 2.32: Ilustrarea densității și a funcției de repartiție a repartiției \(F_{n_1,n_2}\) pentru o serie de grade de libertate.
NoteRemarcă
Se observă că dacă \(F\sim F_{n_1,n_2}\) atunci \(\frac{1}{F}\sim F_{n_2,n_1}\). Mai mult, între repartiția Student și repartiția Fisher există relația
\[
F_{1,n} = t_n^2
\]
altfel spus, repartiția Fisher cu un grad de libertate la numărător și \(n\) grade de libertate la numitor este pătratul repartiției Student cu \(n\) grade de libertate.
În plus, dacă \(n_2\) este mare atunci putem aproxima repartiția lui \(F\) cu \(F\approx \frac{\chi^2_{n_1}}{n_1}\).
Figura 2.33: Aproximarea densității repartiției \(F\) cu \(\frac{\chi^2_{n_1}}{n_1}\).
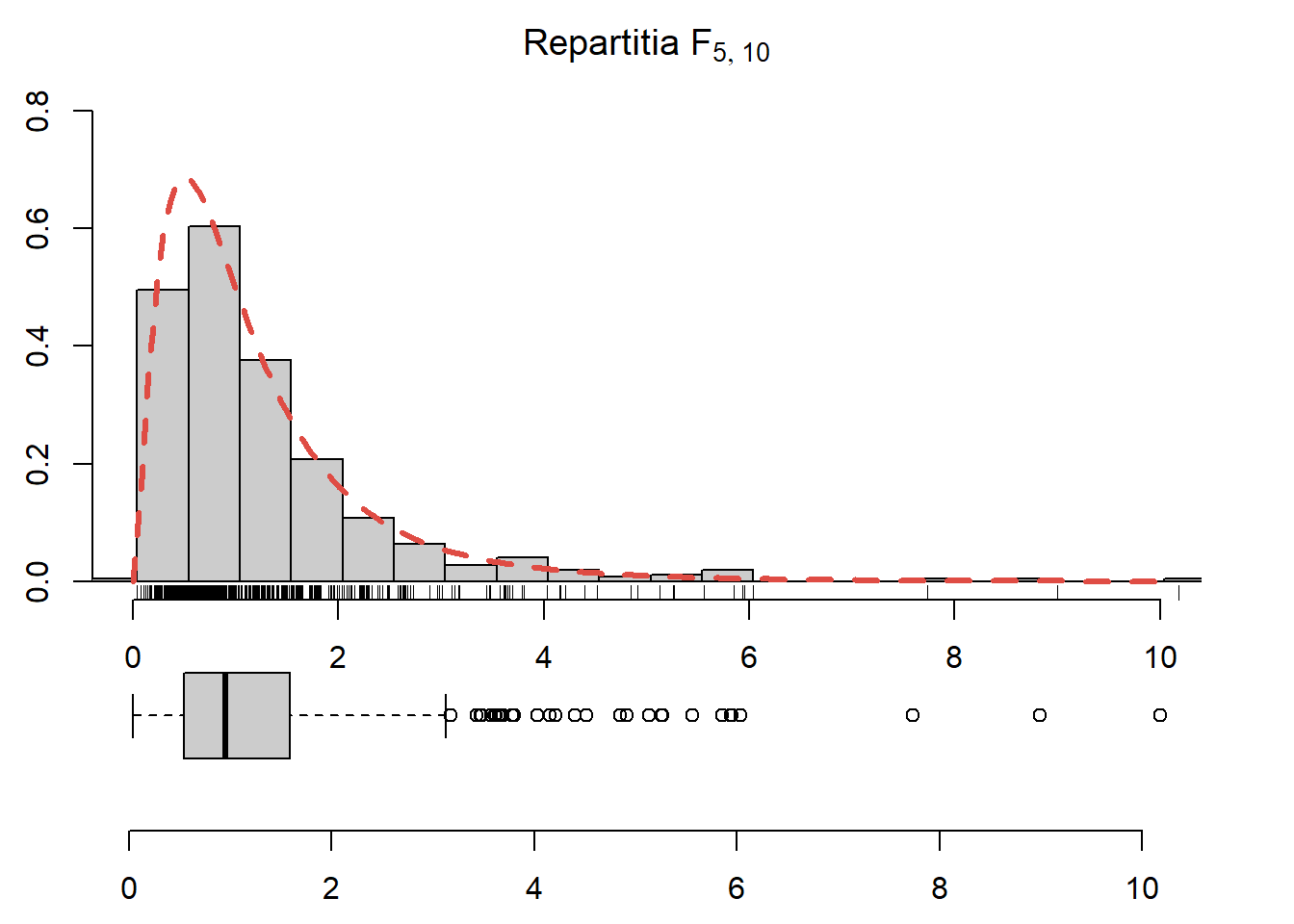
Exercițiul 2.37 Generați \(250\) de observații din repartiția \(F_{5,10}\), trasați histograma acestora și suprapuneți densitatea repartiției date (vezi Figura 2.34).
Figura 2.34: Histograma observațiilor generate din repartiția \(F_{5,10}\) și densitatea teoretică suprapusă.
Legea Numerelor Mari
Înainte de a discuta despre Legea Numerelor Mari este bine să reamintim și să încercăm să înțelegem la nivel intuitiv noțiunea de convergență în probabilitate.
Fie \(X_n, n\geq 1\) și \(X\) variabile aleatoare definite pe câmpul de probabilitate \((\Omega, \mathcal{F}, \mathbb{P})\). Spunem că un șirul de variabile aleatoare \((X_n)_n\) converge în probabilitate la variabila aleatoare \(X\), și notăm \(X_n\overset{\mathbb{P}}{\to}X\), dacă pentru orice \(\epsilon>0\) are loc
De asemenea putem observa că \(X_n\overset{\mathbb{P}}{\to}X\) dacă și numai dacă \(X_n-X\overset{\mathbb{P}}{\to}0\). Pentru a ilustra grafic acest tip de convergență6 vom aproxima probabilitatea \(\mathbb{P}(A_n)\), unde \(A_n = \{\omega\in\Omega\,|\,\left|X_{n}(\omega) - X(\omega)\right| > \epsilon\}\), folosind abordarea frecvenționistă. Aceasta presupune ca pentru \(n\) dat să considerăm \(\omega_1, \ldots,\omega_M\in\Omega\), \(M\) realizări ale experimentului (repetat în condiții identice) și să folosim aproximarea
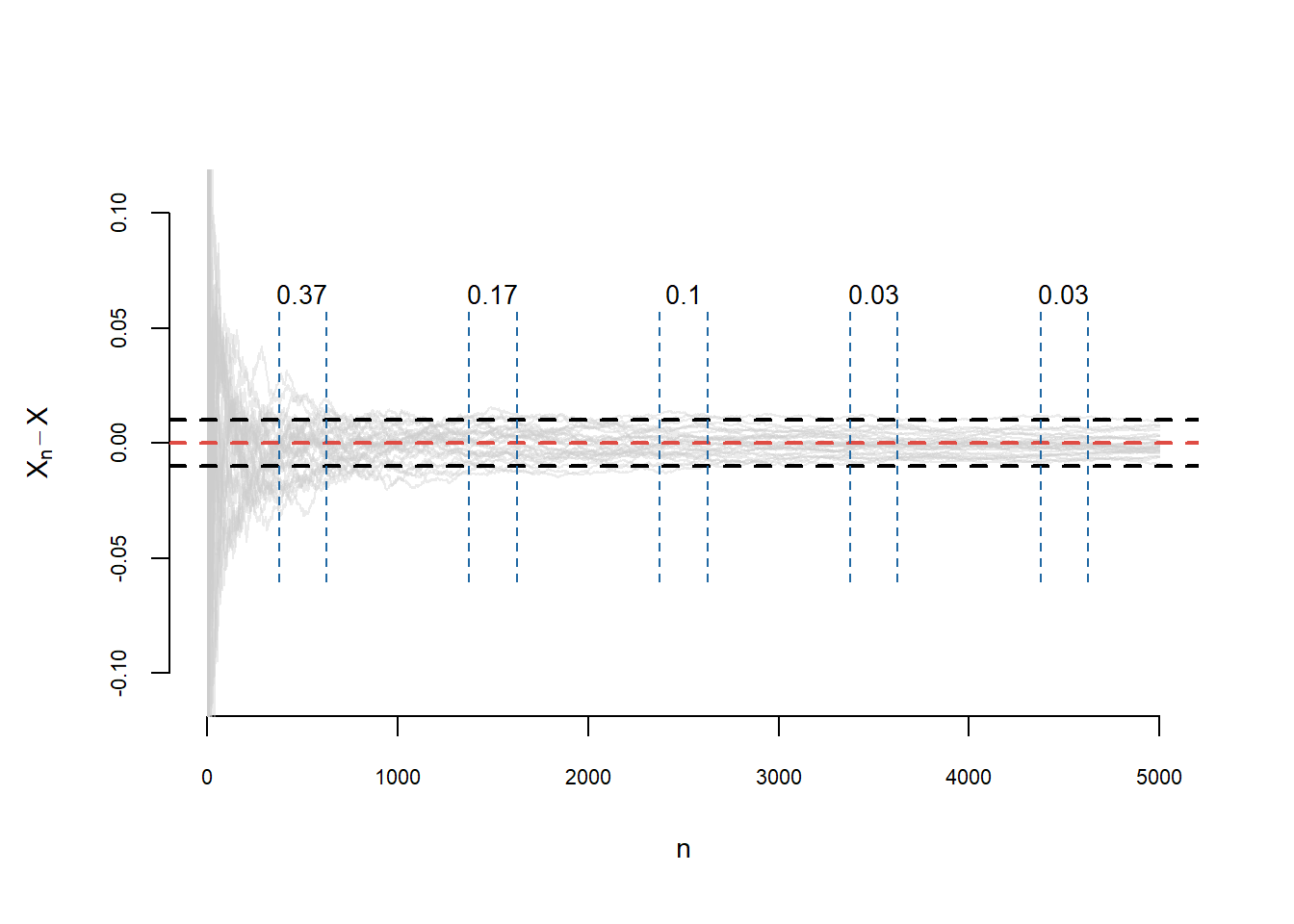
Concret, în Figura 3.1, considerăm \(M = 30\) de repetiții ale experimentului (avem \(M\) curbe) cu \(n = 5000\) de realizări ale unui șir de variabile aleatoare \(X_k = \frac{Y_1+\cdots+Y_k}{k}\), cu \(Y_i\) independente și repartizate \(\mathcal{U}[0,1]\), \(X = 0.5\) și \(\epsilon = 0.01\). Pentru \(i\in\{500, 1500, 2500, 3500, 4500\}\) am calculat și afișat frecvența de realizarea a evenimentului \(A_i\) (câte din cele \(M\) curbe sunt în afara benzii \([-\epsilon, \epsilon]\) pentru \(i\), fixat). Observăm că \(p_{500}(30) = 0.37\) și \(p_{3500}(30) = 0.03\), convergența lui \(p_n(M)\underset{n\to \infty}{\longrightarrow} 0\) implicând convergența în probabilitate.
Figura 3.1: Ilustrarea convergenței în probabilitate.
Teorema 3.1 (Legea numerelor mari (versiunea slabă)) Fie \(X_1, X_2, \ldots\) un șir de variabile aleatoare independente și identic repartizate, de medie \(\mathbb{E}[X_1] = \mu<\infty\) și varianță \(Var(X_1) = \sigma^2<\infty\). Atunci \(\forall \epsilon>0\) avem
Notând media eșantionului cu \(\bar{X}_n = \frac{X_1+\cdots X_n}{n}\), Legea numerelor mari (versiunea slabă) afirmă că \(\bar{X}_n\overset{\mathbb{P}}{\to}\mu\). Figura 3.2 de mai jos ilustrează această convergență pentru \(M = 100\) de traiectorii. În figura din dreapta este ilustrată evoluția probabilității \(p_n\) pentru \(n\in\{1,2,\ldots, N\}\).
Figura 3.2: Ilustrarea convergenței în Legea Numerelor Mari.
Exercițiul 3.1 Să presupunem că primim o monedă și ni se spune că aceasta aterizează pe fața cap în \(48\%\) din cazuri. Vrem să testăm această afirmație. Folosind Legea numerelor mari și știind că vrem să fim siguri în \(95\%\) din cazuri, ne întrebăm de câte ori trebuie să aruncăm moneda pentru a verifica afirmația?
Să presupunem că aruncăm moneda, independent, de \(n\) ori și fie \(X_i\) rezultatul obținut la cea de-a \(i\)-a aruncare: \(X_i=1\) dacă la a \(i\)-a aruncare am obținut cap și \(X_i = 0\) dacă am obținut pajură. Avem că variabilele aleatoare \(X_1, X_2, \ldots, X_n\) sunt independente și repartizare \(\mathcal{B}(p)\), cu \(p=0.48\) din ipoteză.
De asemenea, observăm că \(\mathbb{E}[X_1]= \mu = 0.48\) și \(Var(X_1) = \sigma^2 = p(1-p) = 0.2496\). Pentru testarea monedei permitem o eroare \(\epsilon = 0.02\) ceea ce înseamnă că probabilitatea ca moneda să aterizeze cap se află în intervalul \((0.46, 0.5)\). Din Inegalitatea lui Cebîșev avem că
de unde, având un grad de încredere de \(95\%\), vrem să determinăm pe \(n\) pentru care
\[
\frac{0.2496}{n\times(0.02)^2} = 0.05
\]
ceea ce implică \(n = 12480\).
Exercițiul 3.2 (Ilustrarea Legii Numerelor Mari (I)) Fie \(X_1,X_2,\dots,X_N\), \(N\) v.a. i.i.d. de lege \(\mathcal{U}([0,1])\). Pentru \(1\leq n\leq N\), notăm cu \(S_n=X_1+X_2+\cdots X_n\) șirul sumelor parțiale și \(\mu\) media legii \(\mathcal{U}([0,1])\). Trasați pe același grafic funcția \(n\to \bar{X}_n=\frac{S_n}{n}\) pentru \(n=1,\dots,N\) și dreapta de ecuație \(y=\mu\). Faceți același lucru pentru legea normală \(\mathcal{N}(2,1)\).
În cazul în care v.a. \(X_1,X_2,\dots,X_N\) sunt repartizate uniform \(\mathcal{U}([0,1])\) (deci media este \(\mu=\frac{1}{2}\)) avem:
Figura 3.3: Ilustrarea convergenței în Legea Numerelor Mari pentru un șir de variabile i.i.d. \(\mathcal{U}([0,1])\).
În cazul în care v.a. \(X_1,X_2,\dots,X_N\) sunt normale de parametrii \(\mathcal{N}(2,1)\) (deci media este \(\mu=2\)) avem:
Figura 3.4: Ilustrarea convergenței în Legea Numerelor Mari pentru un șir de variabile i.i.d. \(\mathcal{N}(2, 1)\).
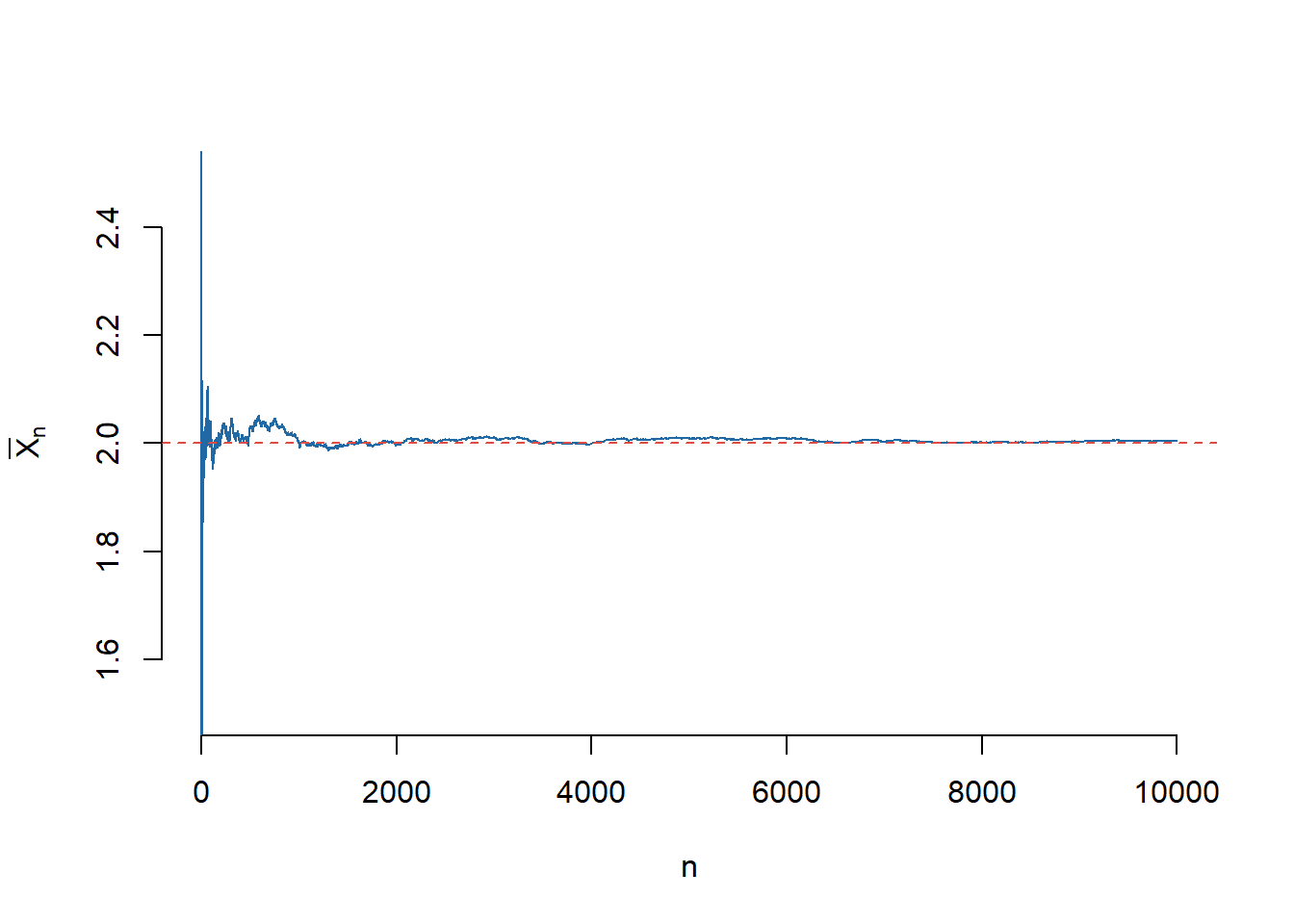
Exercițiul 3.3 (Ilustrarea Legii Numerelor Mari (II)) Construiți o funcție care să vă permită generarea a \(m\) eșantioane de volum \(n\) dintr-o populație normală de medie \(\mu\) și varianță \(\sigma^2\) dată. Ilustrați grafic cu ajutorul unui boxplot cum variază diferența dintre media aritmetică (media eșantionului \(\bar{X}_n\)) și media teoretică pentru \(m = 100\) și diferite volume ale eșantionului \(n\in\{10, 100, 1000, 10000\}\). Se consideră \(\mu = 1\) și \(\sigma^2 = 1\).
Următoarea funcție verifică cerința din problemă (normal.mean =\(\mu\), normal.sd =\(\sigma\), num.samp = m și samp.size = n). Să observăm că am folosit funcția rowMeans pentru a calcula media fiecărui eșantion (media pe liniile matricii de observații).
normalSampleMean <-function(normal.mean, normal.sd, num.samp, samp.size) {# generam matricea de observatii x <-matrix(rnorm(n = num.samp * samp.size, mean = normal.mean, sd = normal.sd), nrow = num.samp, ncol = samp.size)# calculam media esantionului pentru fiecare esantion x.mean =rowMeans(x)return(x.mean)}
Pentru a ilustra grafic să considerăm o populație \(\mathcal{N}(1,1)\) și pentru volumul eșantionului, \(n\in\{10, 100, 1000, 10000\}\), să calculăm \(\bar{X}_n\) corespunzător (aici am folosit funcția sapply).
Figura 3.5: Ilustrarea convergenței în Legea Numerelor Mari.
Din boxplot-ul din Figura 3.5 observăm că pe măsură ce creștem volumul eșantionului media boxplot-ului se duce spre \(0\) ceea ce justifică enunțul Legii Numerelor Mari, și anume că media eșantionului converge la media populației (media teoretică). De asemenea putem observa că și varianța scade (gradul de împrăștiere scade) odată cu creșterea numărului de observații.
Exercițiul 3.4 (Calculul unei integrale (I)) Utilizați Legea Numerelor Mari pentru a aproxima integrala următoare
\[
I = \int_{0}^{1}e^{x}sin(2x)cos(2x)dx.
\]
Calculați de asemenea valoarea exactă \(I\) a acesteia și comparați-o cu aproximarea găsită.
Fie \(U_1,U_2,\dots,U_n\) un șir de v.a. i.i.d. repartizare uniform pe \([0,1]\). Cum \(g\) este o funcție continuă atunci \(g(U_1), g(U_2),\ldots, g(U_n)\) sunt variabile aleatoare i.i.d. și aplicând Legea Numerelor Mari obținem
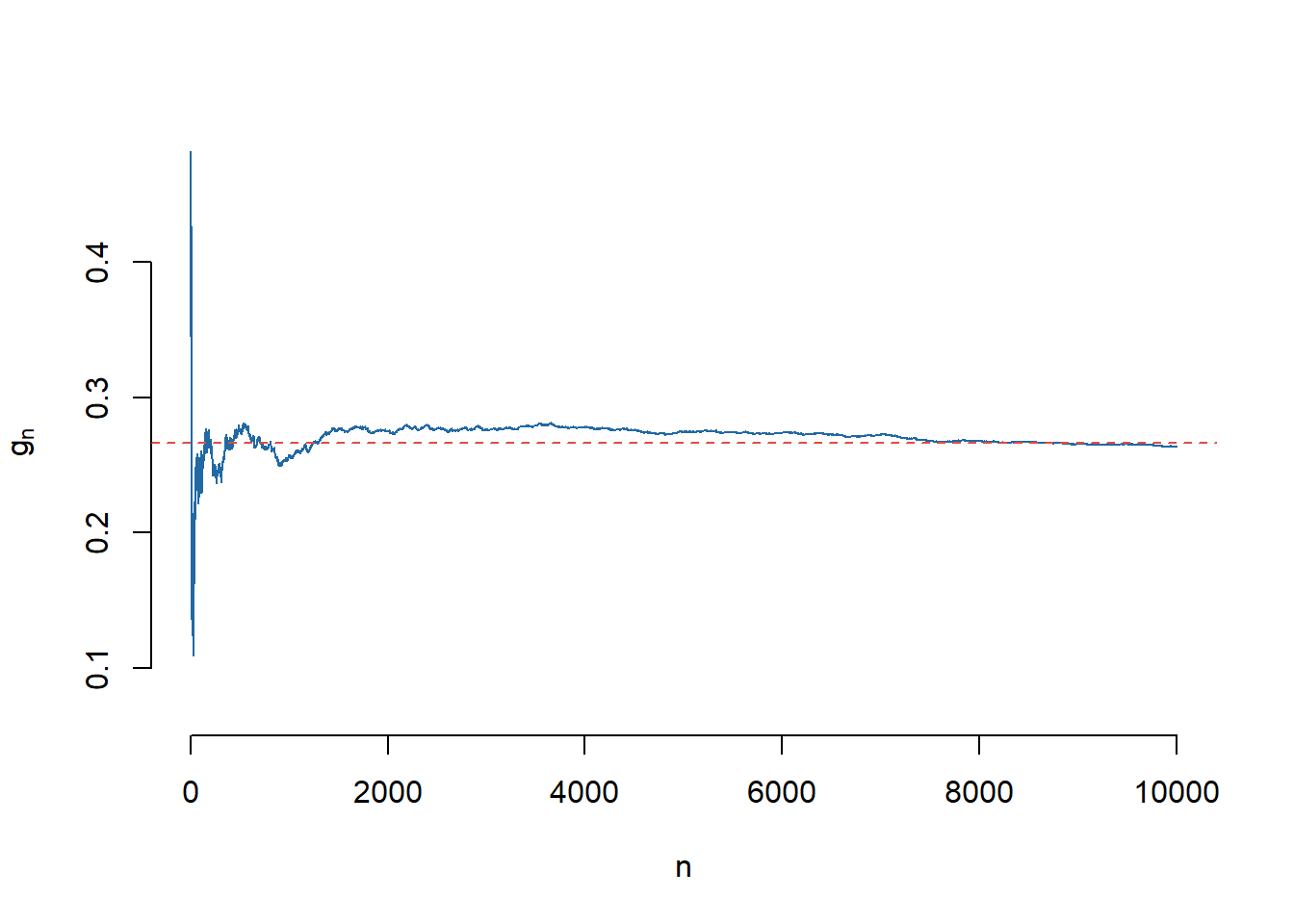
Pentru a calcula integrala numeric vom folosi funcția integrate (trebuie observat că această integrală se poate calcula ușor și exact prin integrare prin părți). Următorul script ne dă valoare numerică și aproximarea obținută cu ajutorul metodei Monte Carlo pentru integrale \(\int_{0}^{1}g(x)dx\):
myfun <-function(x){ y <-exp(x)*sin(2*x)*cos(2*x);return(y);}# calculul integralei cu metode numericeI <-integrate(myfun,0,1) # raspunsul este o lista si oprim prima valoareI <- I[[1]]# calculul integralei cu ajutorul metodei Monte Carlon <-10000u <-runif(n) # generarea sirului U_nz <-myfun(u) # calcularea sirului g_nI2 <-sum(z)/n # aproximarea MC
Obținem că valoarea numerică a lui \(I\) este 0.2662 iar cea obținută cu ajutorul metodei Monte Carlo este 0.2673.
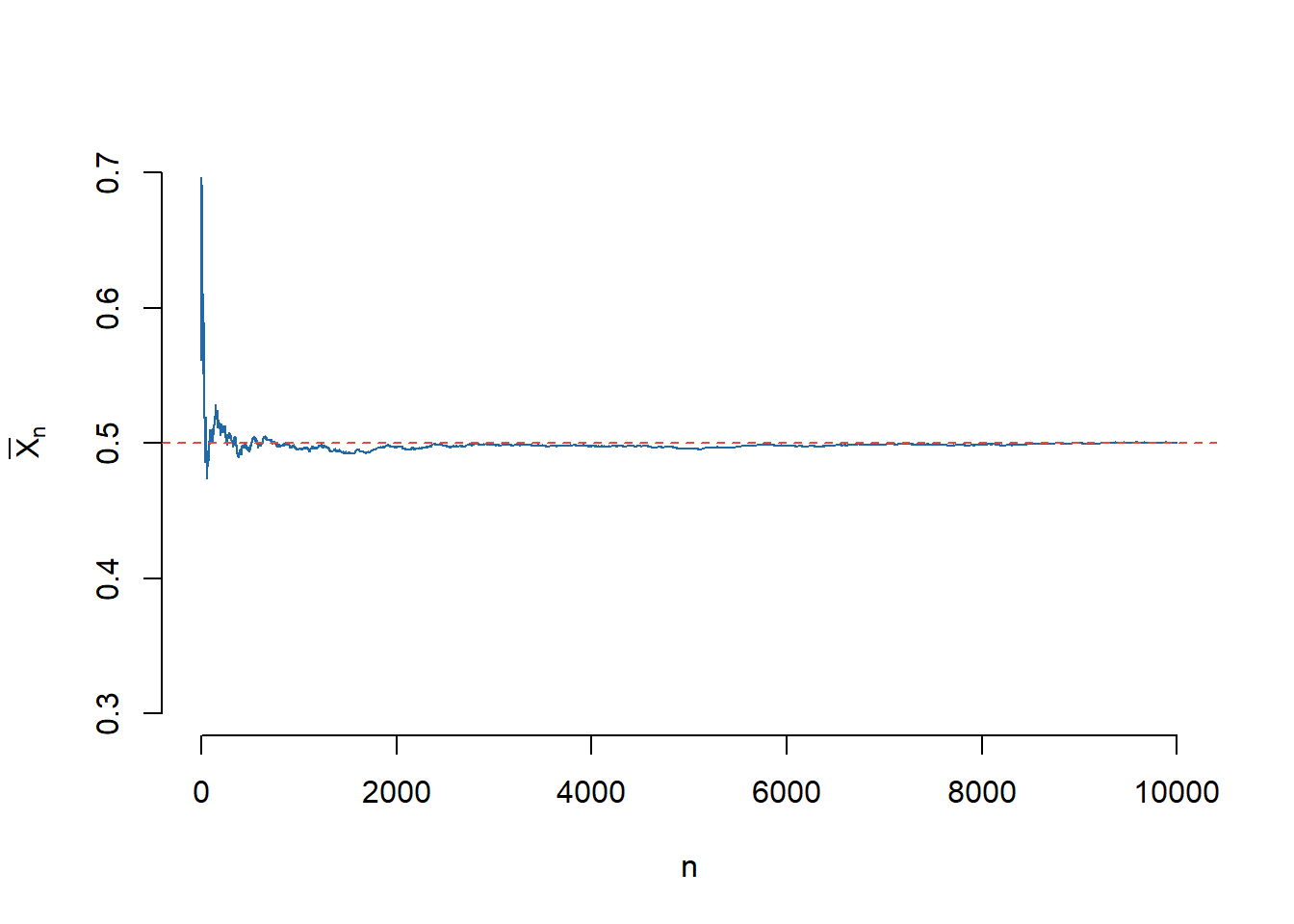
Avem următoarea ilustrare grafică a convergenței metodei Monte Carlo:
Figura 3.6: Ilustrarea convergenței în metoda Monte Carlo.
Teorema Limită Centrală
Teorema 4.1 (Teorema Limită Centrală) Fie \(X_1, X_2, \ldots\) un șir de variabile aleatoare independente și indentic repartizate, de medie \(\mathbb{E}[X_1] = \mu<\infty\) și varianță \(Var(X_1) = \sigma^2<\infty\). Atunci, notând \(S_n = X_1 + \cdots + X_n\), avem
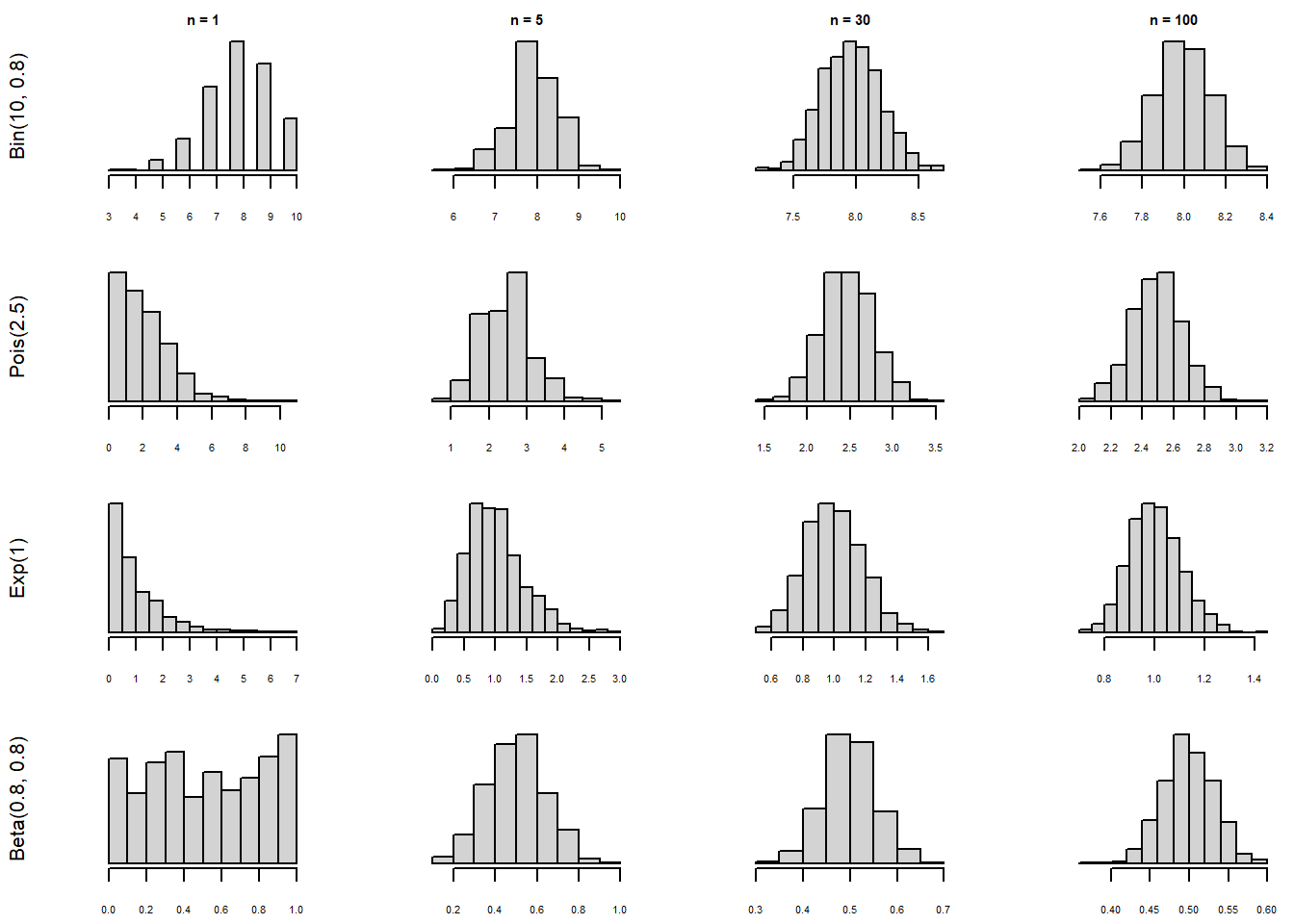
În esență, Teorema Limită Centrală ne spune că, indiferent de repartiția mamă a eșantionului, media eșantionului \(\bar{X}_n\) este aproximativ normal repartizată. În Figura 4.1 de mai jos prezentăm evoluția repartiției lui \(\bar{X}_n\) după volumul eșantionului pentru diferite repartiții inițiale:
Figura 4.1: Ilustrarea Teoremei Limită Centrale: repartiția lui \(\bar{X}_n\) după volumul eșantionului pentru diferite repartiții inițiale.
O aplicație simplă a Teoremei Limită Centrale este dat de următorul exercițiu:
Exercițiul 4.1 Să presupunem că primim o monedă și ni se spune că aceasta aterizează pe fața cap în \(48\%\) din cazuri. Vrem să testăm această afirmație. Folosind Teorema Limită Centrală și știind că vrem să fim siguri în \(95\%\) din cazuri, ne întrebăm de câte ori trebuie să aruncăm moneda pentru a verifica afirmația? Comparați răspunsul cu cel din exercițiul în care am folosit LNM, de mai sus.
Folosind aceleași notații ca și în exercițiul din secțiunea de mai sus și notând în plus \(S_n = X_1+\cdots+X_n\), avem
Prin urmare, \((0.04\sqrt{n}\geq 1.645\) de unde \(n = 1692\). Putem observa că rezultatul obținut prin aplicarea Teoremei Limită Centrală este mai precis decât cel obținut prin aplicarea Legii numerelor mari.
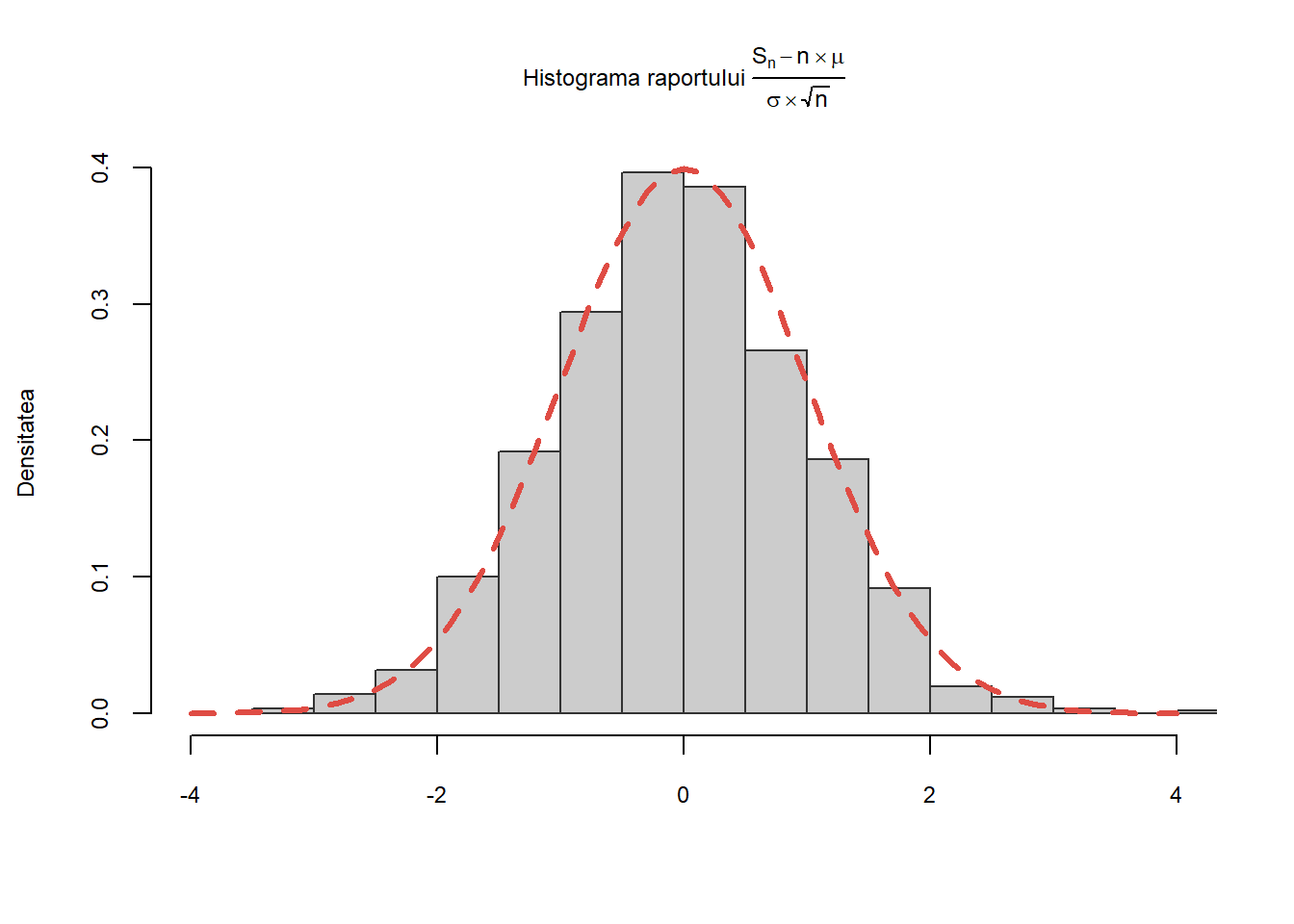
Exercițiul 4.2 Fie \((X_n)_{n\geq1}\) un șir de v.a. i.i.d. de lege \(\mathcal{E}(1)\). Pentru toți \(n\), notăm cu \(S_n=X_1+X_2+\cdots X_n\) șirul sumelor parțiale, \(\mu\) și \(\sigma^2\) reprezentând media și respectiv varianța legii \(\mathcal{E}(1)\). Teorema Limită Centrală afirmă că dacă \(n\) este mare atunci v.a.
\[
\frac{S_n-n\mu}{\sqrt{n}\sigma}
\]
are aproximativ aceeași distribuție ca și legea normală \(\mathcal{N}(0,1)\). Ilustrați această convergență în distribuție cu ajutorul unei histograme. Suprapuneți peste această histogramă densitatea legii \(\mathcal{N}(0,1)\).
Știm că media unei v.a. distribuite exponențial de parametru \(\lambda\), \(\mathcal{E}(\lambda)\) este \(\mu=\frac{1}{\lambda}\) iar varianța acesteia este \(\sigma^2=\frac{1}{\lambda^2}\). Pentru fiecare valoare a lui \(i\) de la \(1\) la \(N\) calculăm raportul \(\frac{S_n-n\mu}{\sigma\sqrt{n}}\) (cu alte cuvinte repetăm experimentul de \(N\) ori):
N <-1000# alegem numarul de repetitii ale experimentuluin <-1000# alegem n pentru care folosim aproximarea normalalambda <-1# parametrul legii E(1)mu <-1/lambda # mediasigma <-1/lambda # abaterea standard s <-rep(0,N) # initializam sirul sumelor partialefor (i in1:N){ x <-rexp(n, rate = lambda) # generam variabilele exponentiale s[i] <- (sum(x)-n*mu)/(sigma*sqrt(n)) # calculam raportul }
Continuăm prin trasarea histogramei cerute și adăugăm la grafic densitatea legii normale \(\mathcal{N}(0,1)\):
Figura 4.2: Ilustrarea Teoremei Limită Centrale.
Exercițiul 4.3 Fie \(X_1,X_2,\dots,X_{1000}\) v.a. i.i.d. de lege \(\mathcal{B}(\frac{1}{2})\) (Bernoulli de parametru \(\frac{1}{2}\)). Dați un interval de încredere bilateral \(\mathcal{I}\) de nivel \(99\%\) pentru \(S_{1000}=X_1+X_2+\cdots X_{1000}\). Fie \((Y_n)_{n\geq1}\) un șir de v.a. i.i.d. de aceeași lega ca și \(S_{1000}\). Luând:
\[
T=\inf\{n\geq1,\,Y_n\not\in\mathcal{I}\}
\]
afișați mai multe rezultate ale v.a. \(T\) și \(Y_T\). Analizați aceste rezultate.
Prin aplicarea Teoremei Limită Centrală avem că un interval de încredere \(\mathcal{I}\) de nivel \(99\%\) pentru v.a. \(S_n\), este dat de formula
Următorul cod permite construirea acestui interval:
n <-1000p <-1/2# parametrul v.a. Bernoullimu <- p # ,edia sigma <-sqrt(p*(1-p)) # abaterea standard# determinarea intervalului I z <-0.99Imin <- n*mu +qnorm((1-z)/2)*sqrt(n)*sigmaImax <- n*mu -qnorm((1-z)/2)*sqrt(n)*sigma
Obținem astfel că intervalul de încredere este I = [459, 541].
Funcția care generează realizările v.a. \(T\) și \(Y_T\) plecând de la intervalul găsit \(\mathcal{I}\) este dată de codul următor:
# functia care genereaza v.a. T si Y_Tgen_T <-function(n,p,Imin,Imax){ t <-1 y <-rbinom(1,n,p)while (Imin<=y & y<=Imax){ y <-rbinom(1,n,p) t <- t+1 } out =c(t,y)return(out)}
Următorul cod returnează \(10\) realizări ale v.a. \(T\) și \(Y_T\):
# realizari ale v.a. T si Y_Titer <-10v <-c()for (i in1:iter){ v <-rbind(v,gen_T(1000,0.5,Imin,Imax))}v <-data.frame(v)names(v) =c("T", "Y_T")
Tabelul 4.1: O serie de realizări
T
Y_T
141
547
315
542
15
459
87
454
34
542
15
458
59
542
47
544
77
454
40
459
Putem observa cu ușurință că v.a. \(T\) este o v.a. geometrică de parametru \(p=\mathbb{P}(Y_1\not\in\mathcal{I})=0.01\), deoarece pentru \(k\geq1\)
și verificăm această afirmație prin simulări numerice. Media empirică a lui \(Y_T\) este 500.37, pentru 1000 iterații, iar cea teoretică este \(500\).
Note de subsol
de Moivre, A. (1756). The Doctrine of Chances: or, A Method of Calculating the Probabilities of Events in Play (Third ed.). New York: Chelsea.↩︎
A se vedea cartea lui Feller, W. (1968). An Introduction to Probability Theory and Its Applications (third ed.), Volume 1. New York: Wiley. pag. 52-53 pentru o derivare a formulei lui Stirling.↩︎
Pentru mai multe astfel de inegalități se poate consulta cartea (capitolul 2): Lin, Z. și Bai, Z. Probability Inequalities, Springer, 2010.↩︎
Pentru cazul discret avem variabila repartizată Geometric.↩︎
Pentru mai multe proprietăți puteți consulta lucrarea lui E. Artin The Gamma Function↩︎
Pentru alte moduri de convergență și ilustrarea lor grafică se poate consulta lucrarea: Pierre LAFAYE DE MICHEAUX și Benoit LIQUET Understanding Convergence Concepts: A Visual-Minded and Graphical Simulation-Based Approach, The American Statistician, Vol. 63, No. 2, 2009↩︎