Notă! Au fost adăugate proiectele (grupa 301 și grupele 311 și 321) și o serie de exerciții propuse (detalii) care să vină în sprijinul pregătirii examenului.
Pachetul ggplot2 folosește o serie de transformări statistice, sau stat, pentru a aduce datele la formatul dorit pentru trasare. Forma generală a acestora este stat_[nume statistică]. De obicei aceste transformări sumarizează datele într-un anume fel, de exemplu în cazul unui boxplot pentru valorile de pe y se calculează mediana (\(Q_2\)), prima și a treia cuartila (\(Q_1\) și \(Q_3\)) și distanța dintre acestea (\(IQR\)), iar în cazul unei curbe de regresie (geom_smooth) se calculează valoarea medie a lui y condiționată la x. Un alt exemplu constă în trasarea unei diagrame cu bare (barplot) în care axa y este definită ca fiind numărul de elemente din fiecare clasă (count) a lui x, număr care nu aparține setului de date inițial ci este obținut prin aplicarea unei transformări statistice stat_count. Fiecare obiect geometric geom admite o transformare statistică predefinită și vice versa dar acestea pot fi schimbate. De exemplu, transformarea statistică predefinită pentru geom_bar este stat_count
# argumentele functiei geom_barargs(geom_bar)
function (mapping = NULL, data = NULL, stat = "count", position = "stack",
..., just = 0.5, width = NULL, na.rm = FALSE, orientation = NA,
show.legend = NA, inherit.aes = TRUE)
NULL
# argumentele functiei stat_countargs(stat_count)
function (mapping = NULL, data = NULL, geom = "bar", position = "stack",
..., width = NULL, na.rm = FALSE, orientation = NA, show.legend = NA,
inherit.aes = TRUE)
NULL
Următorul tabel prezintă o serie de transformări statistice și obiectele geometrice pentru care acestea reprezintă un comportament implicit:
Tabelul 1: Principalele transformări statistice și obiectele geometrice pentru care acestea reprezintă un comportament implicit.
Transformare statistică
Obiect geometric
stat_identity
geom_point
stat_count()
geom_bar()
stat_bin()
geom_freqpoly(), geom_histogram()
stat_boxplot()
geom_boxplot()
stat_smooth()
geom_smooth()
stat_bin2d()
geom_bin2d()
stat_binhex()
geom_hex()
stat_bindot()
geom_dotplot()
stat_contour()
geom_contour()
De exemplu transformarea identitate (identity) va lăsa datele așa cum sunt și folosită în geom_bar conduce la construcția unei diagrame cu bare în care pe axa y se află valorile variabilei y fără a mai efectua transformarea (în acest caz este nevoie atât de estetica x cât și de y). În figura următoare afișăm populația totală a țărilor de pe fiecare dintre cele patru continente considerate în setul de date gapminder_2018:
Figura 1: Exemplu de utilizare a statisticii identity în geom_bar.
Pe lângă transformările implicite există și o serie de transformări care nu pot fi create prin aplicarea funcțiilor geom_. Tabelul de mai jos prezintă o parte dintre acestea (pentru mai multe informații se poate consulta documentația pachetului ggplot2 la adresa https://ggplot2.tidyverse.org/reference/index.html#section-layer-stats):
Tabelul 2: O serie de transformări care nu pot fi create prin aplicarea funcțiilor geom_.
Transformare statistică
Descriere
stat_ecdf()
calculează și ilustrează funcția de repartiție empirică
stat_function()
calculează valorile lui y aplicând o funcție valorilor lui x
stat_summary()
sumarizează valorile lui y la clase diferite în x
stat_summary2d(), stat_summary_hex()
este o versiune bidimensională a lui stat_summary
stat_unique()
elimină valorile duplicate
stat_qq()
efectuează calculele pentru un grafic cuantilă-cuantilă
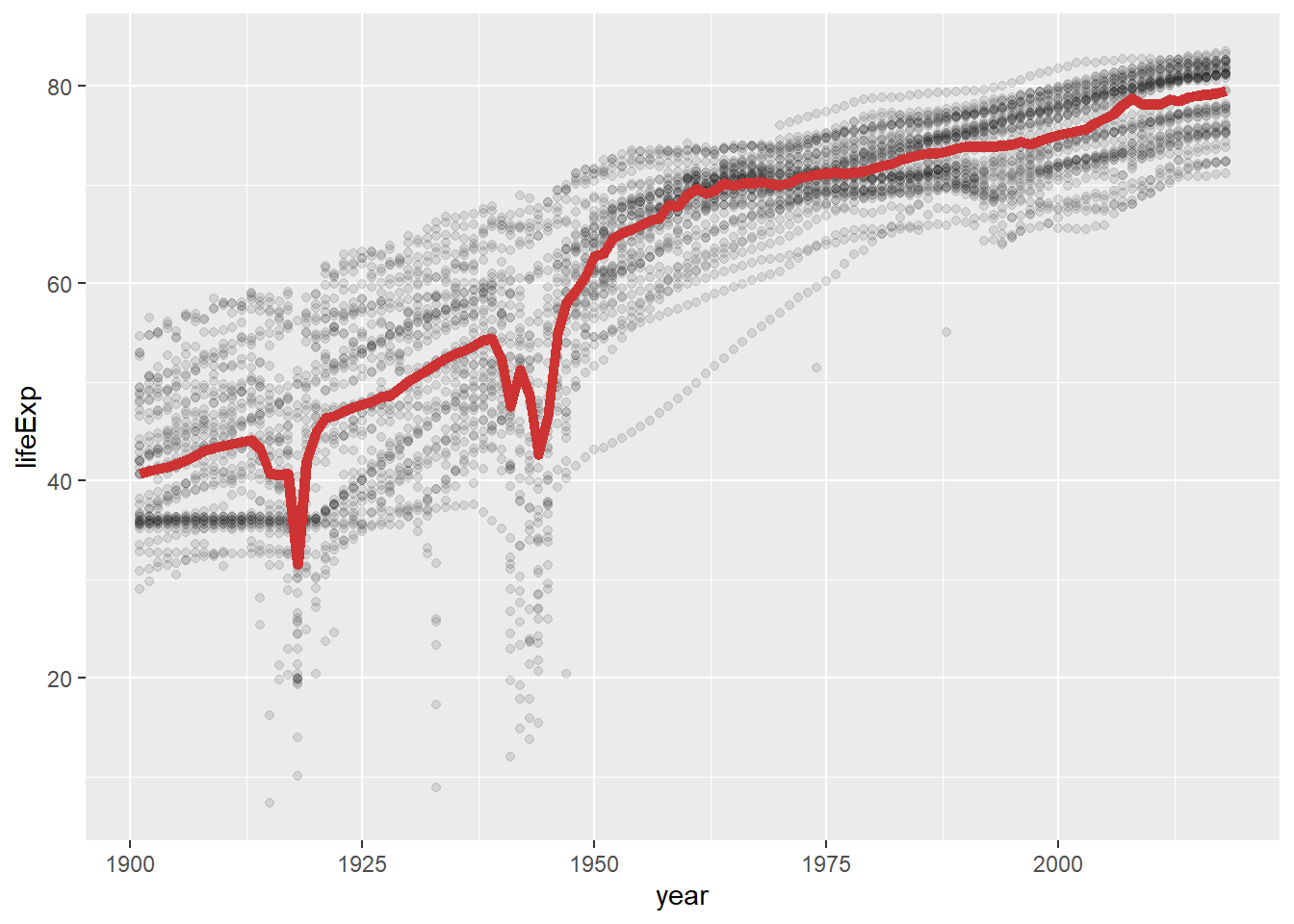
Pentru a folosi aceste funcții putem sau să le apelăm în mod direct utilizând stat_[nume] și astfel suprascriind obiectul geometric sau să le apelăm în interiorul unui strat geometric. Pentru ilustrare vom folosi setul de date gapminder_all în care vom trasa o diagramă de împrăștiere unde pe axa x avem anii de după 1900 iar pe y speranța medie de viață a țărilor europene (pentru a evita supraaglomerarea punctelor - ovreplotting vom folosi estetic alpha = 0.1). Vom adăuga cu roșu la această diagramă valoarea mediană a duratei medii de viață a tuturor țărilor pentru fiecare an și vom uni aceste valori printr-o linie:
Figura 2: Exemplu de diagrama de împrăștiere în care se utilizează statistica summary.
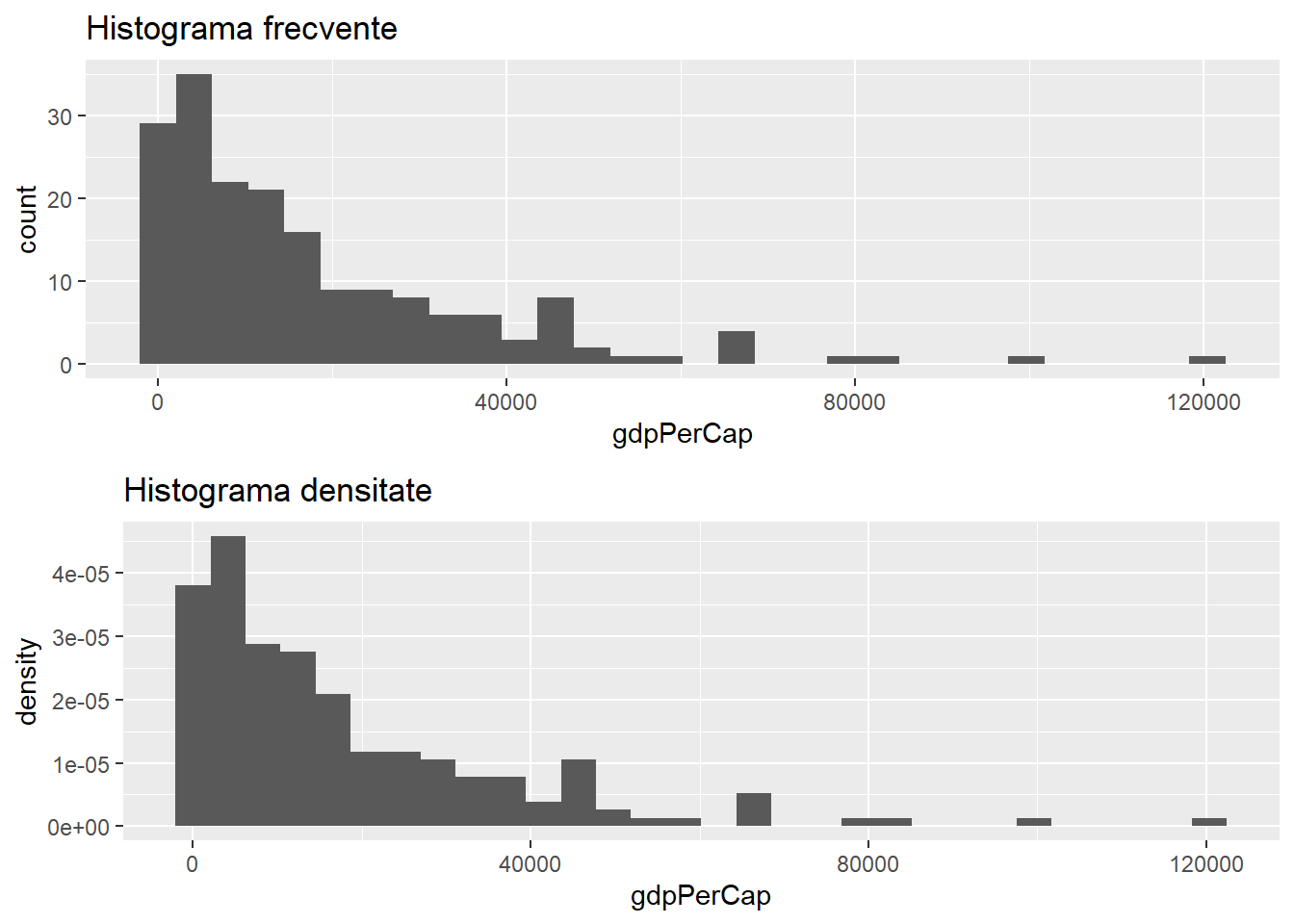
Trebuie avut în vedere că atunci când funcțiile stat_ transformă datele, în realitate se construiește un alt data.frame la care pot să apară noi variabile (noi coloane) și prin urmare este posibil să utilizăm aceste noi variabile în trasarea graficului. De exemplu, în cazul transformării stat_bin (statistica folosită pentru trasarea unei histograme) sunt construite următoarele variabile: count - numărul de observații din fiecare subinterval (bin), density - densitatea observațiilor din fiecare subinterval (procentul din total pe lungimea subintervalului), x - centrul subintervalului. Aceste variabile pot fi folosite în trasarea graficului folosind .. în jurul numelui acestora (i.e. ..[nume variabilă]..) pentru a evita o eventuală confuzie cu o variabilă din setul de date inițial care are aceeași denumire. Spre exemplu atunci când trasăm o histogramă observăm că în mod automat (implicit) înălțimea barelor este egală cu numărul de observații din subintervalul corespunzător (count) prin urmare vorbim de o histogramă de frecvențe și nu una de densitate. Pentru a obține-o pe cea din urmă trebuie să specificăm că înălțimea barelor este dată de variabila density. În contextul setului de date gapminder_2018 aceasta se traduce prin
Figura 3: Exemplu de diagrama de histogramă de frecvențe și densitate.
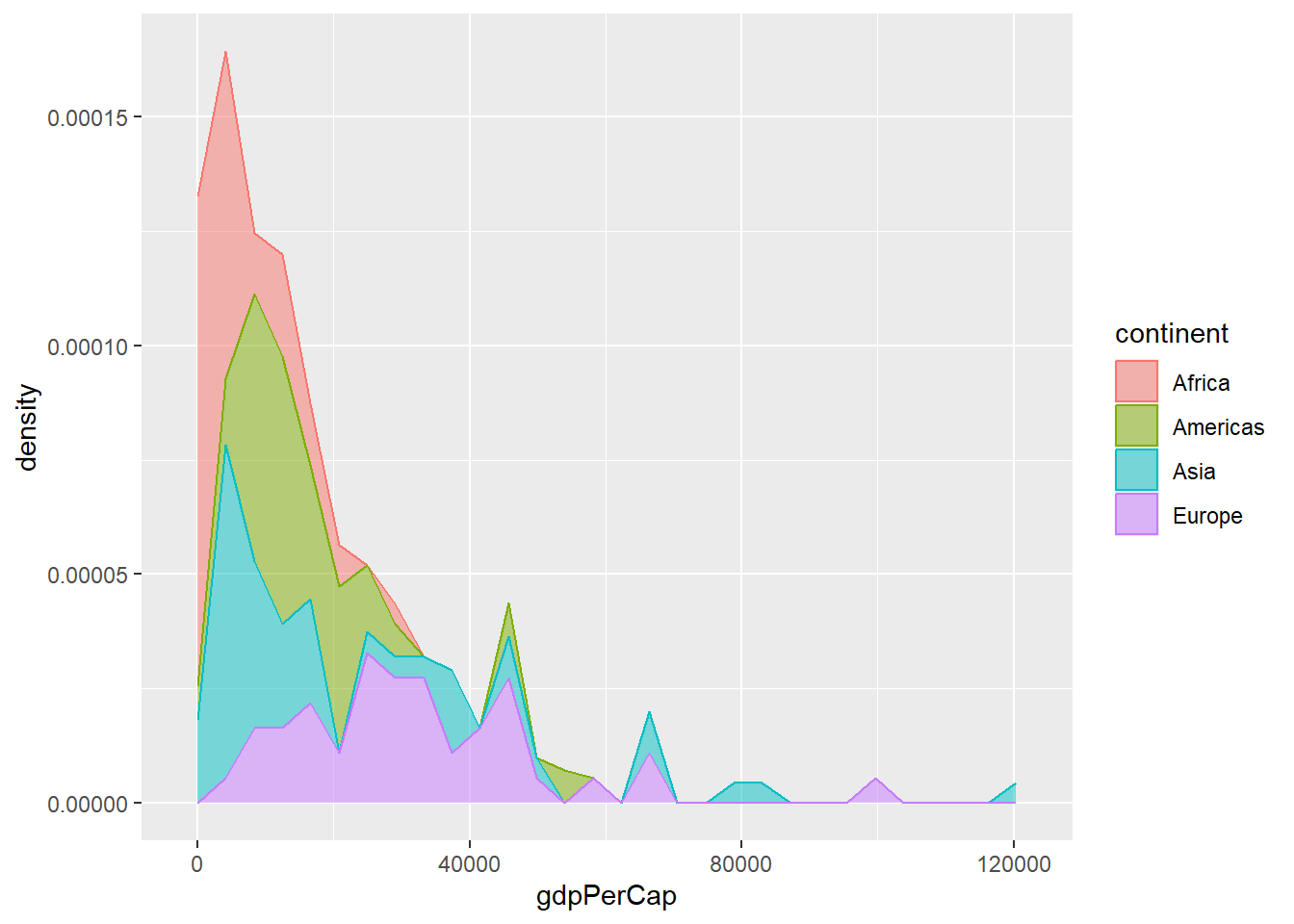
Mai mult dacă dorim să comparăm modul de repartiție a produsului intern brut pe cap de locuitor pentru fiecare continent atunci este recomandată folosirea datelor standardizate:
Figura 4: Exemplu de utilizare a transformării stat = "bin" împreună cu variabila ..density...