Vizualizarea datelor cu ggplot2
Tehnicile de vizualizarea a datelor joacă un rol important în orice analiză statistică, putând conduce la identificarea de noi caracteristici, perspective sau pattern-uri în acestea. Scopul acestei secțiuni este de a introduce o serie de elemente de vizualizare a datelor prin intermediul pachetului ggplot2. Pachetul a fost dezvoltat inițial de Hadley Wickham (care încă menține și îmbunătățește activ pachetul), este parte integrantă din suita tidyverse și este bazat pe, ceea ce se numește în teoria vizualizării, gramatica elemntelor grafice introdusă de Leland Wilkinson în cartea The Grammar of graphics (de aici vine și prefixul gg - grammar of graphics). Similar cu gramatica unei limbi, în care diferite elemente precum substantive, verbe, articole, prepoziții, etc. se pot combina după anumite reguli și gramatica elementelor grafice prezintă o serie de reguli care să permită construcția de grafice statistice prin combinarea mai multor tipuri de straturi (layers) (Wilkinson 2005). Astfel, ideea principală a pachetului ggplot2 este de a specifica independent o serie de componente constructive ale graficului (obiecte geometrice), organizate în straturi, ce urmează a le combina pentru a genera figura dorită (Wickham 2016).
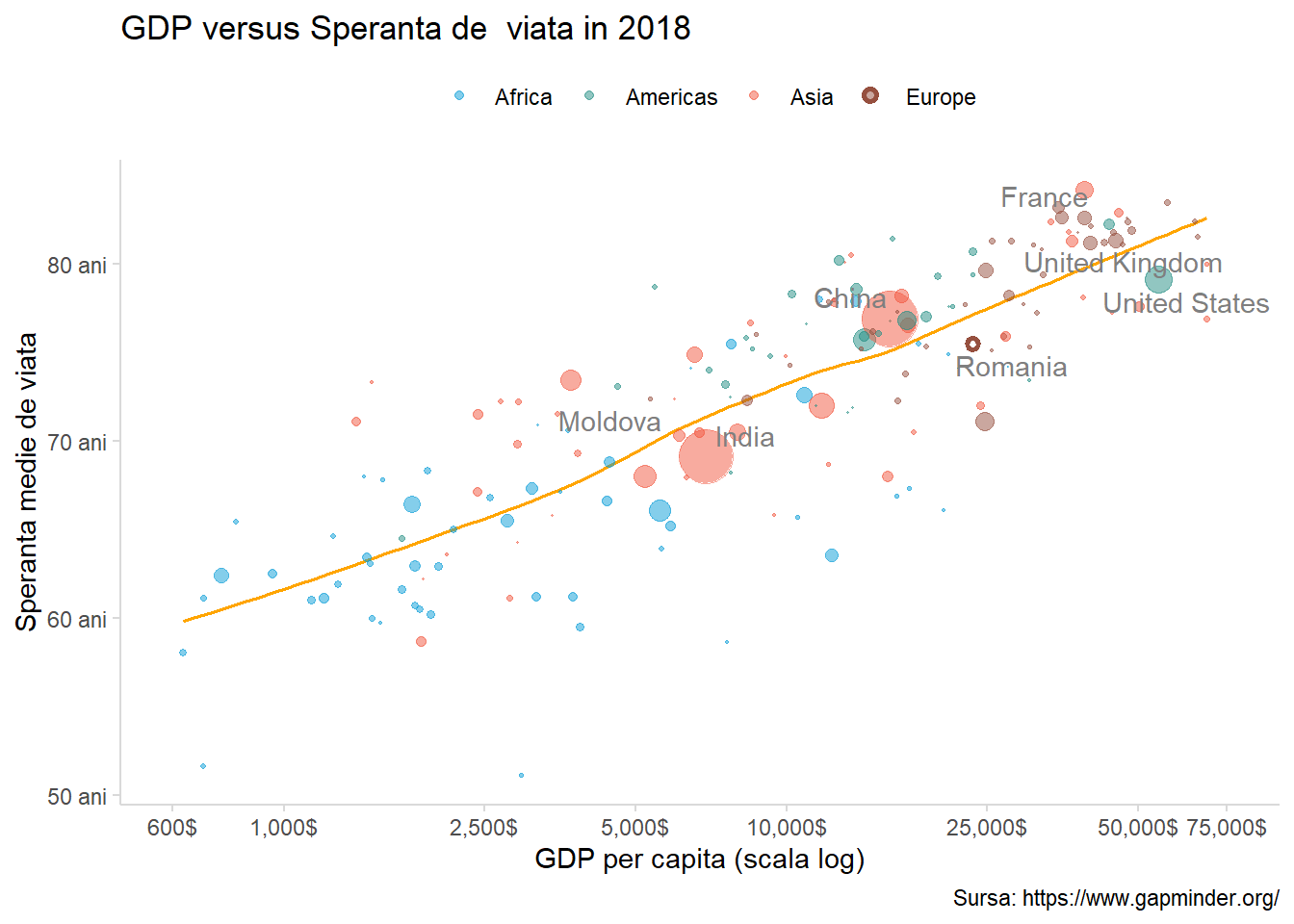
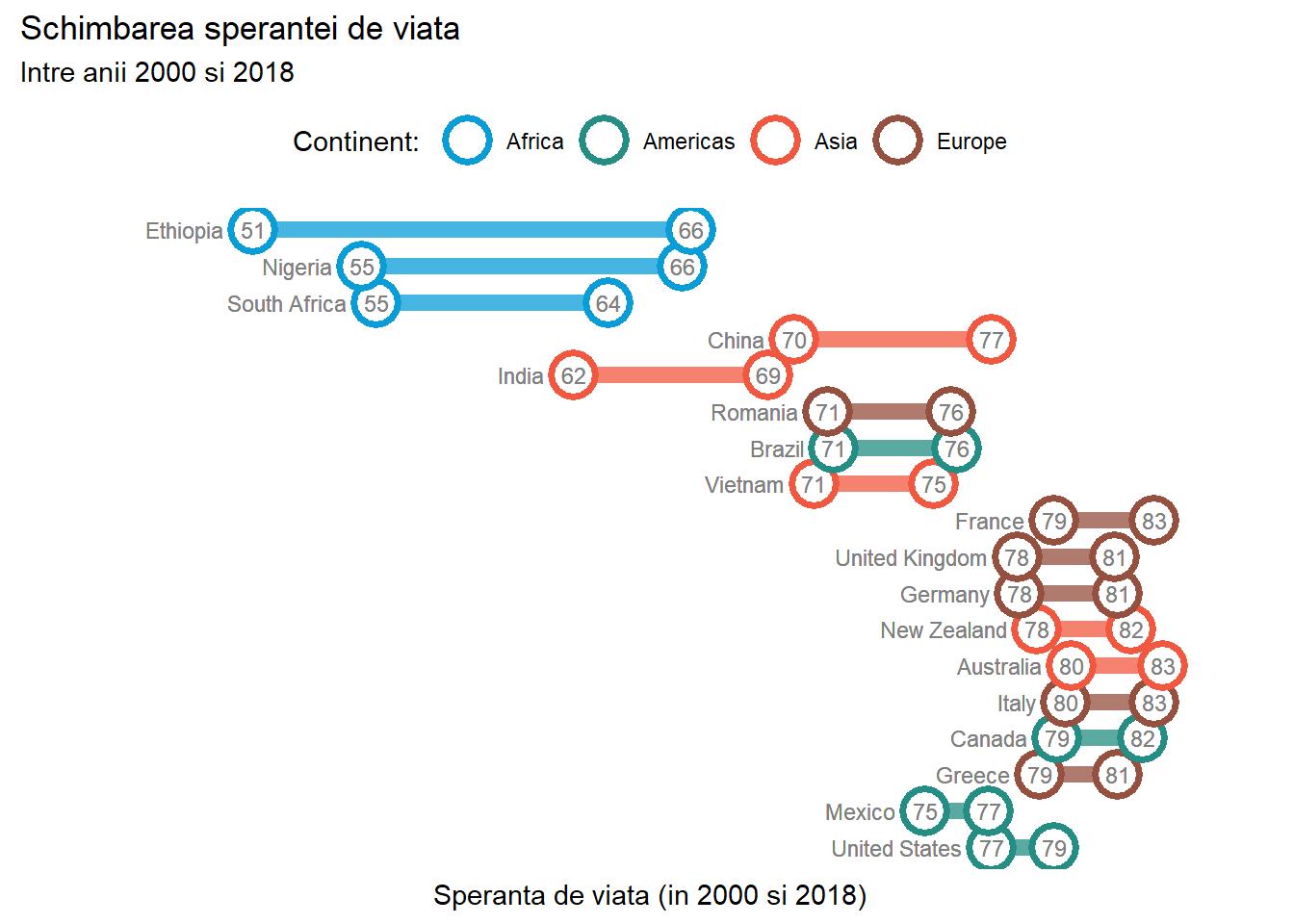
Ne dorim ca la finalul acestei secțiuni, să fim capabili să creăm grafice care să semene cu cele din Figura 1 și Figura 2 mai jos:
Înainte de prezentarea elementelor de bază ce compun un grafic folosind pachetul ggplot2 și de a descrie fiecare componentă în parte, vom specifica care sunt datele (setul/seturile de date) pe care le vom utiliza pe parcursul acestui capitol.
Setul de date folosit
Setul de date pe care îl vom folosi pentru a exemplifica elementele grafice introduse în acest capitol este creat prin manipularea unor date în format brut descărcate de pe platforma www.gapminder.org/data/. Mai precis vom descărca în format csv datele referitoare la durata medie de viață (sau speranța de viață) (Health -> Life expectancy sau http://gapm.io/ilex), produsul intern brut pe cap de locuitor ajustat la rata inflației (Economy -> Incomes & growth -> Income sau http://gapm.io/dgdppc) și respectiv populația totală (Population -> Population sau http://gapm.io/dpop) a peste 180 de state pe perioada 1800 - 2018. De asemenea, pentru a adăuga informații referitoare la locația geografică a țărilor din setul de date, respectiv continentul pe care se află fiecare țară, vom descărca fișierul excel de pe pagina https://www.gapminder.org/fw/four-regions/. Codul pentru crearea setului de date gapminder_all este ilustrat mai jos (acesta seamănă cu setul de date utilizat în prima parte și folosește noțiunile introduse în secțiunea de Metode de manipulare a datelor:
# citim seturile de date
life_exp_gap <- read_csv("../../dataIn/life_expectancy_years.csv")
tot_pop_gap <- read_csv("../../dataIn/population_total.csv")
gdp_gap <- read_csv("../../dataIn/income_per_person_gdppercapita_ppp_inflation_adjusted.csv")
countries_gap <- read_excel("../../dataIn/Data Geographies - v1 - by Gapminder.xlsx", sheet = 2)
# transformam seturile de date
life_exp_gap_pivot <- life_exp_gap %>%
pivot_longer(cols = -country, names_to = "year", values_to = "lifeExp")
tot_pop_gap_pivot <- tot_pop_gap %>%
pivot_longer(cols = -country, names_to = "year", values_to = "pop")
gdp_gap_pivot <- gdp_gap %>%
pivot_longer(cols = -country, names_to = "year", values_to = "gdpPerCap")
countries_gap_keep <- countries_gap %>%
select(geo, name, four_regions,
six_regions, "World bank region",
"World bank, 4 income groups 2017") %>%
rename(wb_region = "World bank region",
wb_income = "World bank, 4 income groups 2017",
country = "name")
# unim seturile de date
gapminder_all <- life_exp_gap_pivot %>%
left_join(tot_pop_gap_pivot) %>%
left_join(gdp_gap_pivot) %>%
left_join(countries_gap_keep) %>%
# capitalizarea primei litere, i.e. transformarea: asia -> Asia
mutate(four_regions = str_to_title(four_regions))Pentru a avea o imagine de ansamblu asupra setului de date construit vom folosi funcția glimpse:
glimpse(gapminder_all)Rows: 40,953
Columns: 10
$ country <chr> "Afghanistan", "Afghanistan", "Afghanistan", "Afghanistan…
$ year <chr> "1800", "1801", "1802", "1803", "1804", "1805", "1806", "…
$ lifeExp <dbl> 28.2, 28.2, 28.2, 28.2, 28.2, 28.2, 28.1, 28.1, 28.1, 28.…
$ pop <dbl> 3280000, 3280000, 3280000, 3280000, 3280000, 3280000, 328…
$ gdpPerCap <dbl> 603, 603, 603, 603, 603, 603, 603, 603, 603, 603, 604, 60…
$ geo <chr> "afg", "afg", "afg", "afg", "afg", "afg", "afg", "afg", "…
$ four_regions <chr> "Asia", "Asia", "Asia", "Asia", "Asia", "Asia", "Asia", "…
$ six_regions <chr> "south_asia", "south_asia", "south_asia", "south_asia", "…
$ wb_region <chr> "South Asia", "South Asia", "South Asia", "South Asia", "…
$ wb_income <chr> "Low income", "Low income", "Low income", "Low income", "…În multe din exemplele din această secțiune vom folosi doar datele corespunzătoare anului 2018 prin urmare vom crea și acest set de date și-l vom numi gapminder_2018:
# setul de date pentru anul 2018
gapminder_2018 <- gapminder_all%>%
filter(year == 2018) %>%
select(-geo) %>%
rename(continent = four_regions)Putem sumariza variabilele din setul de date gapminder_2018 pentru a înțelege mai bine tipul lor și a avea mai multe informații referitoare la statisticile elementare (media, mediana, valoarea minimă și respectiv maximă, etc.) asociate acestora:
summary(gapminder_2018) country year lifeExp pop
Length:187 Length:187 Min. :51.10 Min. :5.320e+04
Class :character Class :character 1st Qu.:67.10 1st Qu.:2.460e+06
Mode :character Mode :character Median :74.05 Median :9.420e+06
Mean :72.66 Mean :4.062e+07
3rd Qu.:78.03 3rd Qu.:3.005e+07
Max. :84.20 Max. :1.420e+09
NA's :3
gdpPerCap continent six_regions wb_region
Min. : 629 Length:187 Length:187 Length:187
1st Qu.: 3605 Class :character Class :character Class :character
Median : 11700 Mode :character Mode :character Mode :character
Mean : 17984
3rd Qu.: 25200
Max. :121000
wb_income
Length:187
Class :character
Mode :character
Observăm că pentru variabila lifeExp avem trei observații care nu prezintă valori, prin urmare putem exclude acele observații din setul de date:
gapminder_2018 <- gapminder_2018 %>%
filter(!is.na(lifeExp))Elemente de bază
Graficele (figurile) realizate prin intermediul pachetului ggplot2 au la bază o serie de elementele constructive, printre care putem enumera:
- setul de date ce urmează să fie prezentat grafic (data) - acesta trebuie să fie sub forma unui
data.frame(adus la un format tidy) - obiectele geometrice (geom) ce urmează să apară pe grafic (puncte, linii, etc.)
- o serie de corespondențe (mappings) de la variabilele din setul de date la aspectul (estetica - aesthetics) obiectelor geometrice
- transformări statistice (statistical transformations) folosite pentru a calcula valorile datelor ce sunt utilizate în grafic
- ajustări ale pozițiilor (position adjustments) obiectelor geometrice pe grafic
- scalări și scale (scales) pentru fiecare corespondență estetică folosită
- sisteme de coordonate (coordinate systems)
- fațete (facets) sau grupuri de date folosite în figuri diferite
Aceste componente constructive ale unui grafic sunt organizate în straturi (layers), unde fiecare strat conține un singur obiect grafic, transformare statistică sau ajustare de poziție și astfel putem vizualiza o figură/un grafic ca pe o mulțime de straturi de imagini suprapuse, fiecare prezentând un anumit aspect al datelor.

Primul pas în crearea unui grafic folosind pachetul ggplot2 este de a construi un obiect ggplot. Acest obiect, creat prin intermediul funcției ggplot(), inițializează suprafața de desen (canvas) fără a desena nimic pe ea. Prin apelarea acestei funcții se specifică, în general, atât setul de date (în format data.frame) care va fi folosit în ilustrația grafică precum și proprietățile estetice (ce țin de aspect) care vor fi aplicate (vor corespunde) obiectelor geometrice folosite ulterior. Cu alte cuvinte, vom spune funcției ggplot care sunt datele pe care urmărim să le ilustrăm grafic și cum fiecare variabilă din acest set de date va fi folosită (e.g. ca și coordonate x, y sau ca variabile de colorare - colour ori mărime - size, etc.). Este important de specificat că setul de date trebuie să fie sub forma unui data.frame adus la un format tidy. Codul generic este:
# il atribuim unui obiect
obiect <- ggplot(data = <DATAFRAME>, aes(x = <COLOANA_1>, y = <COLOANA_2>))
# nu il atribuim unui obiect
ggplot(data = <DATAFRAME>, aes(x = <COLOANA_1>, y = <COLOANA_2>))Sumarizând avem următorii pași ilustrați în Figura 4 de mai jos:
- Apelăm funcția
ggplot()care ne va crea o suprafață de desen goală - Specificăm corespondențele estetice (aesthetic mappings) dintre variabilele setului de date și elemente ce țin de aspect. În acest caz, pentru setul de date
gapminder_2018, între variabilelegdpPerCapșilifeExpși axele x și y. - Adăugăm obiecte geometrice care vor apărea pe grafic. În cazul nostru vom folosi stratul
geom_point()pentru a adăuga puncte ca elemente grafice care să reprezinte datele.
# crearea suprafetei de desenare
ggplot(gapminder_2018)
# variabilele de interes sunt afisate
ggplot(gapminder_2018, aes(x = gdpPerCap, y = lifeExp))
# datele desenate
ggplot(gapminder_2018, aes(x = gdpPerCap, y = lifeExp)) +
geom_point()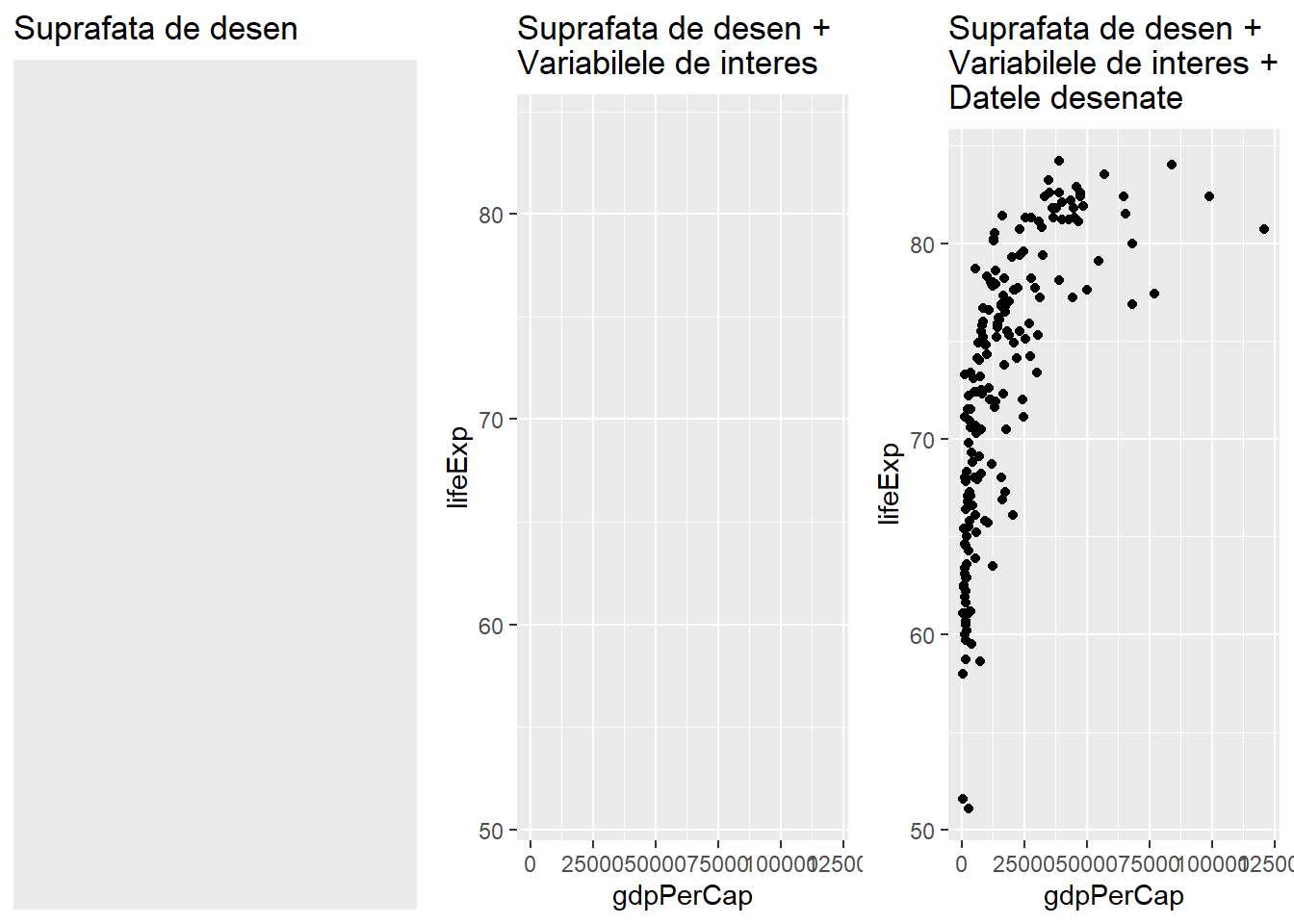
Este de remarcat faptul că atunci când am folosit stratul geom am utilizat operatorul +. De fiecare dată când vom adăuga un nou strat grafic la figura noastră o vom face prin intermediul operatorului +. Funcția geom_point() este doar o scriere prescurtată de trasare a graficului, în realitate se apelează funcția layer() care în fapt construiește un nou strat în care se specifică una din cele cinci componente principale mapping, data, geom, stat și position:
ggplot(gapminder_2018, aes(x = gdpPerCap, y = lifeExp)) +
layer(
mapping = NULL,
data = NULL,
geom = "point",
stat = "identity",
position = "identity"
)Structura generică a unui grafic realizat în ggplot2 este:
ggplot(data = [DATA]) + # element obligatoriu
[GEOM_FUNCTION](
mapping = aes([MAPPINGS]), # element obligatoriu
stat = [STAT], # element optional
position = [POSITION] # element optional
) +
[COORDINATE_FUNCTION] + # element optional
[FACET_FUNCTION] + # element optional
[SCALE_FUNCTION] + # element optional
[THEME_FUNCTION] # element optionalReferințe
Wickham, Hadley. 2016. Ggplot2: Elegant Graphics for Data Analysis. Springer-Verlag New York. https://ggplot2.tidyverse.org.
Wilkinson, Leland. 2005. The Grammar of Graphics (Statistics and Computing). First. Secaucus, NJ: Springer-Verlag.