sample(c("H", "T"), 10, replace = TRUE) [1] "T" "T" "T" "T" "T" "H" "T" "H" "T" "T"Scopul acestor note de laborator este de a introduce o serie de noțiuni și funcții utile în rezolvarea problemelor de probabilități prin intermediul programului R. În aceste note vom prezenta o serie de exerciții și probleme de probabilități, de dificultăți diferite, pentru a ilustra cum pot fi ele rezolvate prin intermediul limbajului R.
În acest exemplu vrem să simulăm aruncarea unei monede (echilibrate) folosind funcția sample(). Această funcție permite extragerea, cu sau fără întoarcere (prin intermediul argumentului replace = TRUE sau replace = FALSE - aceasta este valoarea prestabilită), a unui eșantion de volum dat (size) dintr-o mulțime de elemente x.
Spre exemplu dacă vrem să simulăm \(10\) aruncări cu banul atunci apelăm:
sample(c("H", "T"), 10, replace = TRUE) [1] "T" "T" "T" "T" "T" "H" "T" "H" "T" "T"Pentru a estima probabilitatea de apariției a stemei (H) repetăm aruncarea cu banul de \(10000\) de ori și calculăm raportul dintre numărul de apariții ale evenimentului \(A=\{H\}\) și numărul total de aruncări:
# atunci cand moneda este echilibrata
ban <- sample(c("H","T"), 10000, replace = TRUE)
table(ban)/length(ban)ban
H T
0.5004 0.4996 Pentru cazul în care moneda nu este echilibrată putem specifica prin argumentul prob =, probabilitatea de a obține cap respectiv coadă:
ban <- sample(c("H","T"), 10000, replace = TRUE, prob = c(0.2, 0.8))
table(ban)/length(ban)ban
H T
0.1987 0.8013 Putem vedea cum evoluează această frecvență relativă în funcție de numărul de aruncări
N <- 10000
ban <- sample(c("H","T"), N, replace = TRUE)
# sirul frecventelor relative
y <- cumsum(ban == "H")/(1:N)
plot(1:N, y, type = "o", col = myblue, bty = "n",
xlab ="Numar aruncari", ylab = "Frecventa relativa",
ylim = c(min(y), max(y)), pch = 16)
abline(h = 0.5, lty = 2, col = myred)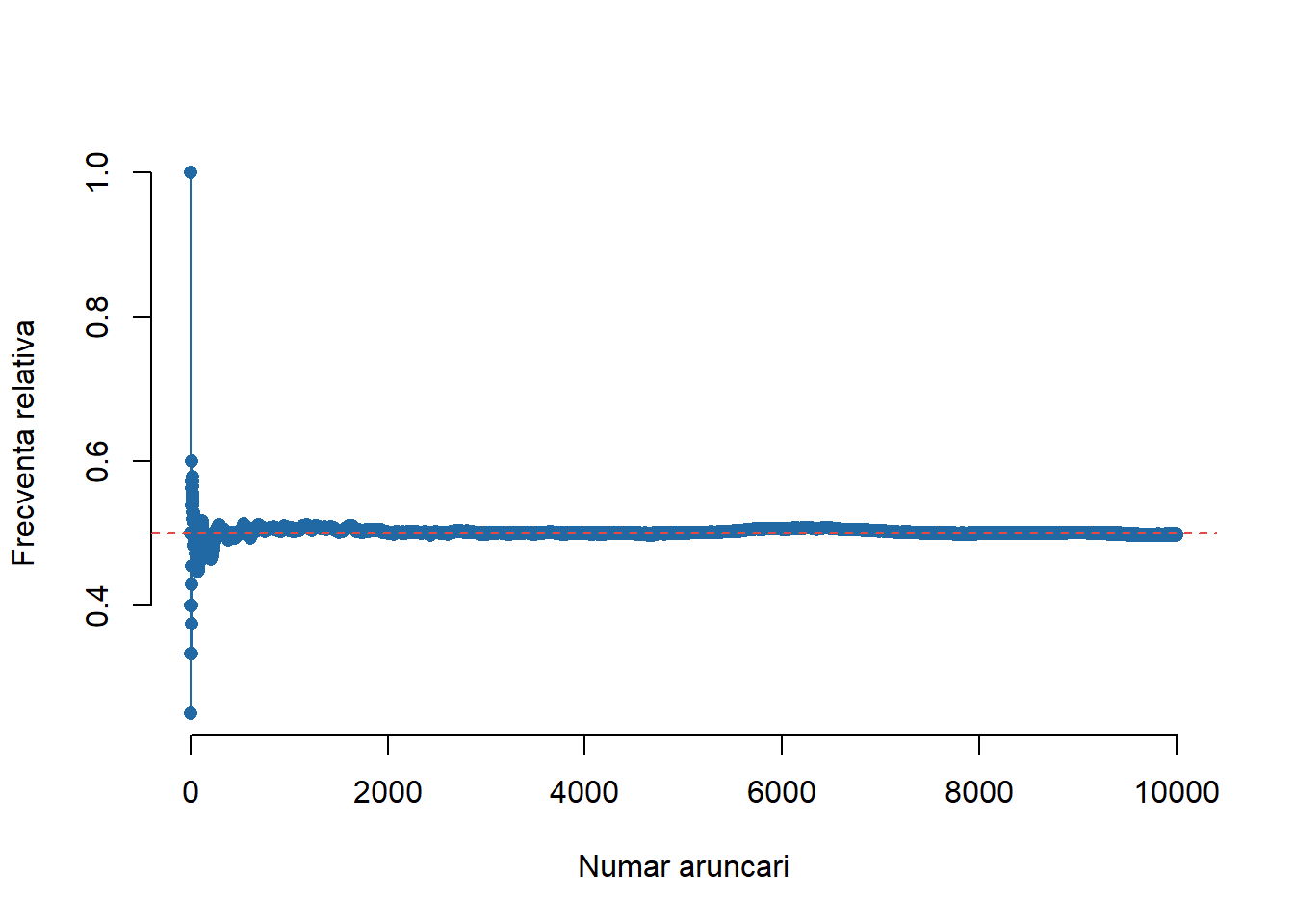
În lucrarea Mathematical games din revista Scientific American numărul 200 (pag. 164-174), Martin Gardner a formulat următoarea problemă:
Exercițiul 2.1 O familie are doi copii. Care este probabilitatea ca ambii copii să fie băieți știind că cel puțin unul dintre copii este băiat ? Care este probabilitatea ca ambii copii să fie băieți știind că cel mai tânăr este băiat ?
Pentru a răspunde la cele două întrebări să observăm că cei doi copii (copilul mai mare și cel mai mic) pot fi ambii de sex masculin sau feminin, prin urmare avem patru combinații de sexe, pe care le presupunem egal probabile. Putem reprezenta spațiul stărilor prin
\[ \Omega = \{BB,BF,FB,FF\} \]
unde \(\mathbb{P}(BB)=\mathbb{P}(BF)=\mathbb{P}(FB)=\mathbb{P}(FF)=\frac{1}{4}\).
Pentru a răspunde la prima întrebare avem:
\[ \begin{aligned} \mathbb{P}\left(BB\,|\,\text{cel puțin unul este băiat}\right) &= \mathbb{P}\left(BB\,|\,BF\cup FB\cup BB\right)\\ &= \frac{\mathbb{P}\left(BB\cap (BF\cup FB\cup BB)\right)}{\mathbb{P}\left(BF\cup FB\cup BB\right)} \\ &= \frac{\mathbb{P}\left(BB\right)}{\mathbb{P}\left(BF\cup FB\cup BB\right)} = \frac{1}{3}. \end{aligned} \]
Iar pentru cea de-a doua întrebare:
\[ \begin{aligned} \mathbb{P}\left(BB\,|\,\text{cel mai tânăr este băiat}\right) &= \mathbb{P}\left(BB\,|\,FB\cup BB\right)\\ &= \frac{\mathbb{P}\left(BB\cap (FB\cup BB)\right)}{\mathbb{P}\left(FB\cup BB\right)} \\ &= \frac{\mathbb{P}\left(BB\right)}{\mathbb{P}\left(FB\cup BB\right)} = \frac{1}{2}. \end{aligned} \]
Vom încerca să răspundem la aceste întrebări și cu ajutorul limbajului R, prin simulare. Din abordarea frecvenționistă am văzut că prin repetarea de \(N\) ori a unui experiment în condiții identice,
\[ \mathbb{P}(A|B)\approx \frac{N(A\cap B)}{N(B)} \]
unde \(N(A\cap B)\) este numărul de realizări (din \(N\)) a evenimentului \(A\cap B\) iar \(N(B)\) este numărul de realizări a evenimentului \(B\). Să considerăm \(N = 10^5\) și fie
N <- 10^5
copil1 <- sample(c("baiat", "fata"), N, replace = TRUE)
copil2 <- sample(c("baiat", "fata"), N, replace = TRUE)Aici copil1 este un vector de lungime N care reprezintă sexul primului copil și în mod similar copil2 reprezintă sexul celui de-al doilea copil.
Fie \(A\) evenimentul ca ambii copii să fie băieți și \(B\) evenimentul prin care cel mai tânăr este băiat.
nB <- sum(copil2 == "baiat")
nAB <- sum(copil1 == "baiat" & copil2 == "baiat")
p2 <- nAB/nBPrin urmare probabilitatea (simulată) ca familia să aibă cei doi copii băieți știind că cel tânăr este băiat este 0.4988765.
Considerând acum \(C\) evenimentul prin care familia are cel puțin un copil băiat, avem
nC <- sum(copil1 == "baiat" | copil2 == "baiat")
p1 <- nAB/nCde unde probabilitatea ca familia să aibă doar băieți știind că cel puțin unul este băiat este 0.3309466.
Să presupunem acum că vrem să rezolvăm următoarea problemă
Exercițiul 2.2 O familie are doi copii. Să se determine probabilitatea ca ambii copii să fie de sex feminin știind că cel puțin unul dintre ei este fata născută iarna. Vom presupune că avem șanse egale ca un copil să se fi născut în oricare din cele patru anotimpuri și că între sexul copilului și anotimp nu există nicio legătură.
Pentru a răspunde la întrebare, vom defini spațiul stărilor prin
\[ \Omega = \{BP,BV,BT,BI, FP, FV, FT, FI\}^2 \]
unde \(B, F\) înseamnă băiat, respectiv fată iar \(P, V, T, I\) fac referire la anotimp (primăvară, vară, toamnă și respectiv iarnă), astfel un element \(\omega\in\Omega\) este de forma \(\omega=(BT, FI)\) și se citește primul copil este de sex masculin născut toamna iar cel de-al doilea copil este de sex feminin născut iarna. În ipotezele suplimentare din problemă, ne aflăm în contextul câmpului de probabilitate al lui Laplace, în care \(\mathbb{P}(\omega)=\frac{1}{64}\) pentru orice \(\omega\in\Omega\).
Problema ne cere să calculăm
\[ \mathbb{P}(\text{ambii să fie F } | \text{ cel puțin unul este FI} ) = ? \]
Cum
\[ \mathbb{P}(\text{ cel puțin unul este FI} ) = \frac{\#\{\text{cel puțin unul este FI}\}}{64} \]
iar \(|\{\text{cel puțin unul este FI}\}| = 15\), deoarece sunt \(8\) elemente de forma \((FI,\cdot)\) (i.e. care încep cu \(FI\)) și 7 elemente de forma \((\cdot,FI)\) (i.e. care se termină cu \(FI\)) găsim că
\[ \mathbb{P}(\text{ cel puțin unul este FI} ) = \frac{15}{64}. \]
În mod similar, probabilitatea
\[ \mathbb{P}(\text{ambii să fie F } \cap \text{ cel puțin unul este FI} ) = \frac{\#\{\text{ambii să fie F și cel puțin unul este FI}\}}{64} = \frac{7}{64} \]
deoarece sunt \(4\) elemente de forma \((FI, F\_ )\) și \(3\) de forma \((F\_, FI)\), fără să numărăm de două ori \((FI,FI)\).
Astfel, probabilitatea căutată este
\[ \mathbb{P}(\text{ambii să fie F } | \text{ cel puțin unul este FI} ) = \frac{7}{15}. \]
Ca și în cazul soluției din Exercițiul 2.1, putem găsi răspunsul la problemă și prin simulare. Mai precis, generând \(N = 10^5\) familii, avem
# generam N familii
N <- 10000 # numarul de repetari ale experimentului
copil1 <- sample(c("baiat-primavara", "baiat-vara", "baiat-toamna", "baiat-iarna",
"fata-primavara", "fata-vara", "fata-toamna", "fata-iarna"), N, replace = TRUE)
copil2 <- sample(c("baiat-primavara", "baiat-vara", "baiat-toamna", "baiat-iarna",
"fata-primavara", "fata-vara", "fata-toamna", "fata-iarna"), N, replace = TRUE)Dacă notăm cu \(B=\{\text{cel puțin unul este FI}\}\) evenimentul cu care condiționăm, atunci frecvența de apariție acestuia este
nB <- sum(copil1 == "fata-iarna" | copil2 == "fata-iarna")iar dacă \(A=\{\text{ambii să fie F}\}\), frecvența de apariție a evenimentului \(A\cap B\) este
nAB <- sum(copil1 == "fata-iarna" & (copil2 == "fata-vara" | copil2 == "fata-primavara" | copil2 == "fata-toamna" | copil2 == "fata-iarna")) +
sum(copil2 == "fata-iarna" & (copil1 == "fata-vara" | copil1 == "fata-primavara" | copil1 == "fata-toamna"))Probabilitatea căutată, \(\mathbb{P}(A|B)\), o putem estima prin
p_AB <- nAB/nBși obținem 0.4711579 (probabilitatea teoretică fiind \(\frac{7}{15}=\) 0.4666667).
Exercițiul 3.1 Să presupunem că aruncăm trei zaruri echilibrate (sau cu un zar de trei ori). Care este probabilitatea ca suma punctelor de pe fața superioară să fie egal cu \(8\)? Care este probabilitatea ca primul zar (sau la prima aruncare) să arate mai puțin de \(3\) puncte dat fiind că suma punctelor de pe fețele celor trei zaruri este mai mare sau egală cu \(8\)?
Vom considera următoarea funcție în R:
prob_zar <- function(d = 3, s = 8, n = 1000){
# d - numarul de zaruri
# s - suma valorilor celor d zaruri
# n - nr de repetari ale experimentului
rez <- rep(0, n)
# repet experimentul de n ori
for (i in 1:n){
x <- sample(1:6, d, replace = TRUE)
rez[i] <- sum(x)
}
return(list(r1 = sum(rez == s)/n,
r2 = table(rez)/n))
}Obținem că pentru \(n = 10000\) de repetări ale experimentului, probabilitatea este:
z <- prob_zar(3, 8, 10000)
z$r1[1] 0.0976Următoarea figură ilustrează repartiția sumei celor trei zaruri:
barplot(height = as.numeric(z$r2),
names.arg = names(z$r2))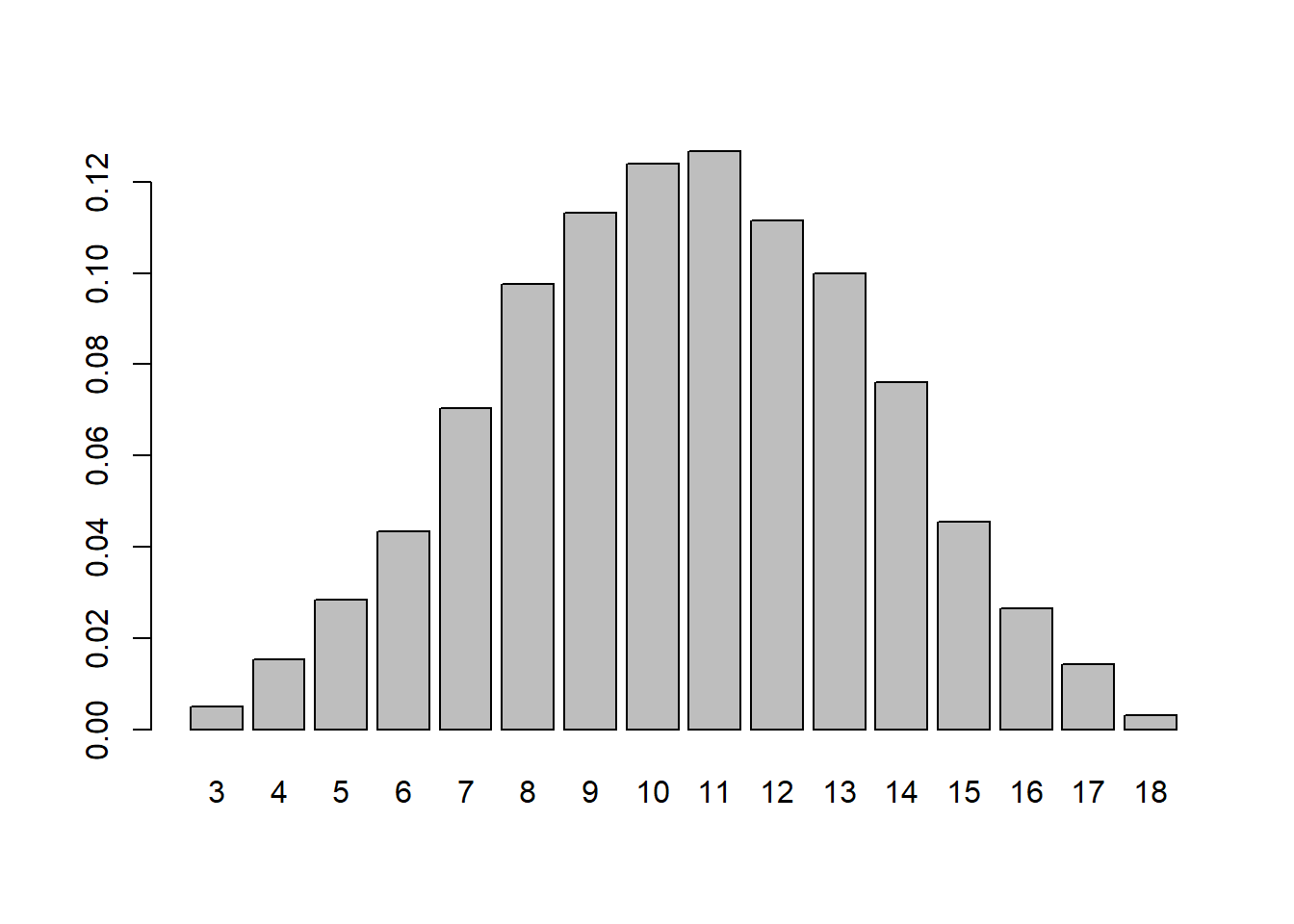
Pentru o scriere mai compactă putem folosi funcția replicate:
zard <- function(d){
return(sample(1:6, d, replace = TRUE))
}
prob_zar2 <- function(d = 3, s = 8, n = 1000){
rez <- replicate(n, sum(rolld(d)))
return(list(r1 = sum(rez == s)/n,
r2 = table(rez)/n))
}Pentru partea a doua a exercițiului avem de-a face cu o probabilitate condiționată. Dacă notăm cu \(A\) evenimentul prin care suma zarurilor este \(\geq 8\) și cu \(B\) evenimentul prin care primul zar are mai puțin de \(3\) puncte atunci căutăm \(\mathbb{P}(B|A)\). Următorul cod ne permite aproximarea acestei probabilități:
n <- 1000
cA <- 0 # suma zarurilor
cBA <- 0 # X1 < 3 si suma >= 8
for (i in 1:n){
x <- sample(1:6, 3, replace = TRUE)
if (sum(x) >= 8){
cA <- cA + 1
if (x[1] < 3){
cBA <- cBA + 1
}
}
}
# estimarea probabilitatii
cBA/cA[1] 0.2458234Exercițiul 4.1 Construiți în R o funcție care să simuleze jocul de loto \(6/49\). Acest joc consistă din extragerea aleatoare a \(6\) numere dintr-o urnă cu \(49\) de numere posibile, fără întoarcere. Fiecare extragere se face de manieră uniformă din numerele rămase în urnă (la a i-a extragere fiecare bilă din urnă are aceeași șansă să fie extrasă). De exemplu putem avea următorul rezultat: \(10, 27, 3, 45, 12, 24\).
Notă: Funcția sample() poate face această operație, ceea ce se cere este de a crea voi o funcție care să implementeze jocul fără a folosi funcția sample. Bineînțeles că puteți folosi funcții precum: runif , floor, choose, etc.
Începem prin a construi o funcție care ne permite generarea unei variabile aleatoare uniform repartizate pe mulțimea \(\{1,2,\dots,n\}\) (această funcție este cea care simulează procesul de extragere de la fiecare pas):
myintunif <- function(n){
# functia care genereaza un numar uniform intre 1 si n
r <- n*runif(1)
u <- floor(r)+1
return(u)
}Funcția care realizează extragerea fără întoarcere a \(k\) numere aleatoare din \(n\), este:
myrandsample <- function(n,k){
x <- 1:n
q <- rep(0,k)
for(i in 1:k){
l <- length(x)
u <- myintunif(l)
q[i] <- x[u]
x <- x[x!=q[i]]
}
return(q)
}Pentru a vedea ce face această funcție putem scrie:
n <- 49
k <- 6
myrandsample(n,k)[1] 29 18 3 4 37 27Exercițiul 4.2 Să presupunem acum că la extragerea loto de Duminică seara au fost alese numerele: 31, 7, 17, 15, 10, 42 și că toți cei \(100000\) de locuitori ai unui orășel și-au cumpărat un bilet. Care este probabilitate ca o persoană care poate completa o singură grilă să piardă ? (o persoană pierde dacă a nimerit cel mult două numere din cele extrase) Comparați rezultatul teoretic cu cel empiric.
Pentru \(0\leq k \leq 6\), fie \(A_k\) evenimentul ca jucătorul să fi nimerit exact \(k\) numere din cele câștigătoare. Atunci, cum putem alege cele \(k\) numere din cele \(6\) în \(\binom{6}{k}\) moduri iar pe celelalte \(6 - k\) în \(\binom{43}{6-k}\) moduri, găsim că
\[ \mathbb{P}(A_k) = \frac{\binom{6}{k}\binom{43}{6-k}}{\binom{49}{6}}. \]
Prin urmare probabilitatea ca jucătorul să piardă este
\[ \mathbb{P}(A_0) + \mathbb{P}(A_1) + \mathbb{P}(A_2) = \frac{\binom{6}{0}\binom{43}{6} + \binom{6}{1}\binom{43}{5} +\binom{6}{2}\binom{43}{4}}{\binom{49}{6}} \]
adică \(\mathbb{P}(A_0) + \mathbb{P}(A_1) + \mathbb{P}(A_2)\approx\) 0.9813625.
Să testăm rezultatul empiric
a <- c(31, 7, 17, 15, 10, 42)
n <- 100000
u <- replicate(n, sum(myrandsample(49, 6) %in% a))
# rezultatul
res <- table(u)/n
# probabilitatea empirica de pierdere
sum(res[c("0", "1", "2")])[1] 0.98201Exercițiul 5.1 Sunteți participant într-un joc televizat în care gazda vă prezintă trei uși închise. Acesta vă spune că în spatele unei uși se află o mașină iar în spatele celorlalte două se află câte o capră. Jocul decurge în felul următor: trebuie să alegeți una dintre cele trei uși; gazda, care știe în spatele cărei uși se află mașina, deschide una dintre celelalte două uși, în spatele căreia se află o capră apoi vă întreabă dacă vreți să rămâneți la alegerea inițială sau vreți să alegeți cealaltă ușă rămasă închisă. Presupunând că vreți să câștigați o mașină, ce alegere preferați ?
Considerăm evenimentele \(U_1\), \(U_2\) și \(U_3\) ca indicând ușa în spatele căreia se află mașina. Aceste evenimente au probabilitatea de \(1/3\) fiecare.
Evenimentul prin care jucătorul alege ușa cu numărul 1 este notat cu \(J_1\) și evenimentul prin care gazda deschide ușa cu numărul 3 este notat cu \(G_3\). Avem că \(\mathbb{P}(U_i|J_1) = 1/3\) iar \(\mathbb{P}(G_3|U_1,J_1) = 1/2\), \(\mathbb{P}(G_3|U_2,J_1) = 1\) și \(\mathbb{P}(G_3|U_3,J_1) = 0\).
Avem că probabilitatea ca jucătorul să câștige adoptând schimbarea ușilor este (în condițiile în care a ales inițial poarta 1 și gazda a deschis poarta 3)
\[ \begin{aligned} \mathbb{P}(U_2|G_3,J_1) &= \frac{\mathbb{P}(G_3|U_2,J_1)\mathbb{P}(U_2\cap J_1)}{\mathbb{P}(G_3\cap J_1)}\\ &=\frac{\mathbb{P}(G_3|U_2,J_1)\mathbb{P}(U_2\cap J_1)}{\mathbb{P}(G_3|U_1,J_1)\mathbb{P}(U_1\cap J_1)+\mathbb{P}(G_3|U_2,J_1)\mathbb{P}(U_2\cap J_1)+\mathbb{P}(G_3|U_3,J_1)\mathbb{P}(U_3\cap J_1)}\\ &= \frac{\mathbb{P}(G_3|U_2,J_1)}{\mathbb{P}(G_3|U_1,J_1)+\mathbb{P}(G_3|U_2,J_1)+\mathbb{P}(G_3|U_3,J_1)} = \frac{1}{1/2+1+0} = \frac{2}{3} \end{aligned} \]
Intuiție (să presupunem că ne aflăm în situația în care am ales ușa cu numărul 1):
| Ușa 1 | Ușa 2 | Ușa 3 | Schimbăm | Nu schimbăm |
|---|---|---|---|---|
| Mașină | Capră | Capră | Pierdut | Câștigat |
| Capră | Mașină | Capră | Câștigat | Pierdut |
| Capră | Capră | Mașină | Câștigat | Pierdut |
Vom încerca să simulăm jocul descris de problema noastră:
monty <- function(random = TRUE) {
doors <- 1:3
if (random){
# alege aleator unde se afla masina
cardoor <- sample(doors,1)
}else{
print("Scrieti numarul usii in spatele careia se afla masina:")
cardoor = scan(what = integer(), nlines = 1, quiet = TRUE)
}
# Monty ii spune jucatorului sa aleaga usa
print("Monty Hall spune ‘Alege o usa, orice usa!’")
# alegerea jucatorului (1,2 sau 3)
chosen <- scan(what = integer(), nlines = 1, quiet = TRUE)
# Monty intoarce o usa cu capra (nu poate fi usa aleasa
# de jucator si nici usa cu masina)
if (chosen != cardoor){
montydoor <- doors[-c(chosen, cardoor)]
}else{
montydoor <- sample(doors[-chosen],1)
}
# jucatorul schimba sau...
print(paste("Monty deschide usa ", montydoor, "!", sep=""))
print("Doresti sa schimbi usa (y/n)?")
reply <- scan(what = character(), nlines = 1, quiet = TRUE)
# ce incepe cu "y" este da
if (substr(reply,1,1) == "y"){
chosen <- doors[-c(chosen,montydoor)]
}
# Rezultatul jocului
if (chosen == cardoor){
print("Bravo! Ai castigat !")
}else{
print("Pacat! Ai pierdut!")
}
}Putem modifica funcția de mai sus așa încât să determinăm probabilitățile de câștig în funcție de strategia aleasă:
monty_hall <- function(j = 1, s = 1, random = TRUE) {
# j - usa aleasa de jucator
# s - strategia aleasa: 1 - nu schimbam, 2 - schimbam
# random - usa masinii este aleasa aleator
doors <- 1:3
if (random){
# alege aleator unde se afla masina
cardoor <- sample(doors,1)
}else{
# daca random = FALSE alegem usa 1 pentru masina
cardoor <- 1
}
# alegerea jucatorului (1,2 sau 3)
chosen <- j
# Monty intoarce o usa cu capra (nu poate fi usa aleasa
# de jucator si nici usa cu masina)
if (chosen != cardoor){
montydoor <- doors[-c(chosen, cardoor)]
}else{
montydoor <- sample(doors[-chosen],1)
}
# jucatorul schimba sau nu...
if (s == 1){
rez <- chosen == cardoor
}else if (s == 2){
chosen <- doors[-c(chosen, montydoor)]
rez <- chosen == cardoor
}else {
stop("Strategia este 1 sau 2!")
}
return(rez)
}
# simulare
N <- 10000
# strategia 1 - nu schimbam
st1 <- sum(replicate(N, monty_hall(j = 1, s = 1)))/N
# strategia 2 - schimbam
st2 <- sum(replicate(N, monty_hall(j = 1, s = 2)))/NAstfel am obținut, pentru 10^{4} repetări ale jocului, o probabilitate empirică de 0.334 pentru strategia de a păstra ușa și respectiv 0.669 pentru strategia de a schimba ușa.
Exercițiul 6.1 Să ne imaginăm că \(20\) de persoane merg la operă și că fiecare persoană poartă o pălărie. În momentul în care ajung la intrare își lasă pălăria la garderobă. Pe parcursul reprezentării artistice, persoana responsabilă cu garderoba se încurcă, pierde lista cu numerele locațiilor și returnează în mod aleator pălăriile persoanelor la plecare. Care este probabilitatea ca cel puțin o persoană să fi primit pălăria cu care a venit?
Să presupunem că persoanele și pălăriile sunt numerotate de la \(1\) la \(n = 20\) și inițial persoana \(i\) a venit cu pălăria \(i\). Fie \(\Omega = S_n\) mulțimea permutărilor cu \(n\) elemente, \(\mathcal{F} = \mathcal{P}(\Omega)\) și \(\mathbb{P}\) echiprobabilitatea pe \((\Omega, \mathcal{F})\). Să notăm cu \(E_i\) evenimentul prin care a \(i\)-a persoană primește pălăria cu numărul \(i\), adică primește pălăria cu care a venit. Evenimentul \(A\) prin care cel puțin o persoană a primit pălăria cu care a venit este
\[ A = E_1 \cup E_2 \cup\cdots\cup E_n. \]
Cum \(E_i\) reprezintă mulțimea permutărilor \(\sigma\in\S_n = \Omega\) pentru care \(\sigma(i) = i\) avem că
\[ \mathbb{P}(E_i) = \frac{(n-1)!}{n!} = \frac{1}{n} \]
deoarece \(|\Omega| = n!\) iar cele \(n-1\) valori diferite de \(i\) pot fi așezate în \((n-1)!\) moduri. În mod similar,
\[ \mathbb{P}(E_i\cap E_j) = \frac{(n-2)!}{n!} \]
și în general
\[ \mathbb{P}(E_{i_1}\cap E_{i_2}\cap\cdots\cap E_{i_k}) = \frac{(n-k)!}{n!}. \]
Formula lui Poincare permite calcularea probabilității dorite
\[ \mathbb{P}(A) = \mathbb{P}(E_1 \cup E_2 \cup\cdots\cup E_n) = \sum_{k = 1}^{n} (-1)^{k-1} \sum_{1\leq i_1<\cdots<i_k\leq n}\mathbb{P}(E_{i_1}\cap E_{i_2}\cap\cdots\cap E_{i_k}) \]
de unde
\[ \mathbb{P}(A) = \sum_{k = 1}^{n} (-1)^{k-1} \binom{n}{k}\frac{(n-k)!}{n!} = \sum_{k = 1}^{n} \frac{(-1)^{k-1}}{k!} \to 1 - \frac{1}{e} \approx 0.63212 \]
Să vedem că același rezultat îl obținem și prin simulare:
# repetam experimentul de un nr mare de ori
m <- 10000
# nr de persoane
n <- 20
n.potriviri <- rep(0, m)
persoane <- 1:n
for (i in 1:m){
palarii <- sample(1:n, n)
n.potriviri[i] <- sum(palarii == persoane)
}
# proportia persoanelor cu cel putin o potrivire
sum(n.potriviri > 0) / m[1] 0.6334Exercițiul 7.1 Un bărbat vrea să își cumpere un obiect (de exemplu o mașină sau o casă) care costă \(N\) unități monetare. Să presupunem că el are economisit un capital de \(0 < k < N\) unități monetare și încearcă să câștige restul jucând un joc de noroc cu managerul unei bănci. Jocul este următorul: bărbatul aruncă o monedă echilibrată în mod repetat iar dacă moneda pică cap (\(H\)) atunci managerul îi dă o unitate monetară, în caz contrar bărbatul plătește o unitate monetară băncii. Jocul continuă până când unul din două evenimente se realizează: sau bărbatul câștigă suma necesară și își cumpără obiectul dorit sau pierde banii și ajunge la faliment. Ne întrebăm care este probabilitatea să ajungă la faliment?
Fie \(A\) evenimentul ca bărbatul să ajungă la ruină și \(B\) evenimentul ca la prima aruncare moneda a picat cap. Atunci din formula probabilității totale avem
\[ \mathbb{P}_k(A) = \mathbb{P}_k(A|B)\mathbb{P}(B)+\mathbb{P}_k(A|B^c)\mathbb{P}(B^c) \]
unde \(\mathbb{P}_k\) este probabilitatea calculată în funcție de valoarea \(k\) a capitalului inițial al jucătorului. Să observăm că \(\mathbb{P}_k(A|B)\) devine \(\mathbb{P}_{k+1}(A)\) deoarece dacă la prima aruncare avem cap atunci capitalul inițial a crescut la \(k+1\). În mod similar, dacă la prima aruncare am obținut coadă atunci \(\mathbb{P}_k(A|B^c) = \mathbb{P}_{k-1}(A)\). Notând cu \(p_k = \mathbb{P}_k(A|B)\) obținem următoarea ecuație
\[ p_k = \frac{1}{2}p_{k+1} + \frac{1}{2}p_{k-1}, \]
cu valorile inițiale \(p_0=1\) (dacă jucătorul a pornit cu un capital inițial nul atunci el este în faliment) și respectiv \(p_N=0\) (dacă jucătorul are din start suma necesară pentru a achiziționa obiectul dorit atunci nu mai are loc jocul).
O simulare a jocului pentru \(N = 50\) și \(k = 5\) este prezentată de următoarea funcție:
ruina <- function(N, k){
flag <- TRUE
joc <- 0
capital <- k
y <- capital
while(flag){
x <- 2*rbinom(1,1,0.5)-1
capital <- capital + x
y <- c(y, capital)
joc <- joc + 1
if (capital == 0 || capital == N){
flag = FALSE
}
}
return(y) # daca am 0 este ruina altfel este succes
}Putem ilustra grafic jocul după cum urmează:
N <- 50
k <- 5
set.seed(1234)
y <- ruina(N, k)
joc <- length(y) - 1 # nr de jocuri
plot(0:joc, y, type = "l",
main = "Ruina jucatorului",
xlab = "Numar de jocuri",
ylab = "Capitalul jucaturului",
bty = "n",
lty = 3, col = "grey50")
abline(h = c(0,N), col = "lightgrey", lty = 3)
points(0:joc, y, col = myblue,
pch = 16,
cex = 0.5)
points(0, k, col = myred, pch = 16)
text(0, k, labels = paste0("k = ", k), pos = 1, cex = 0.7)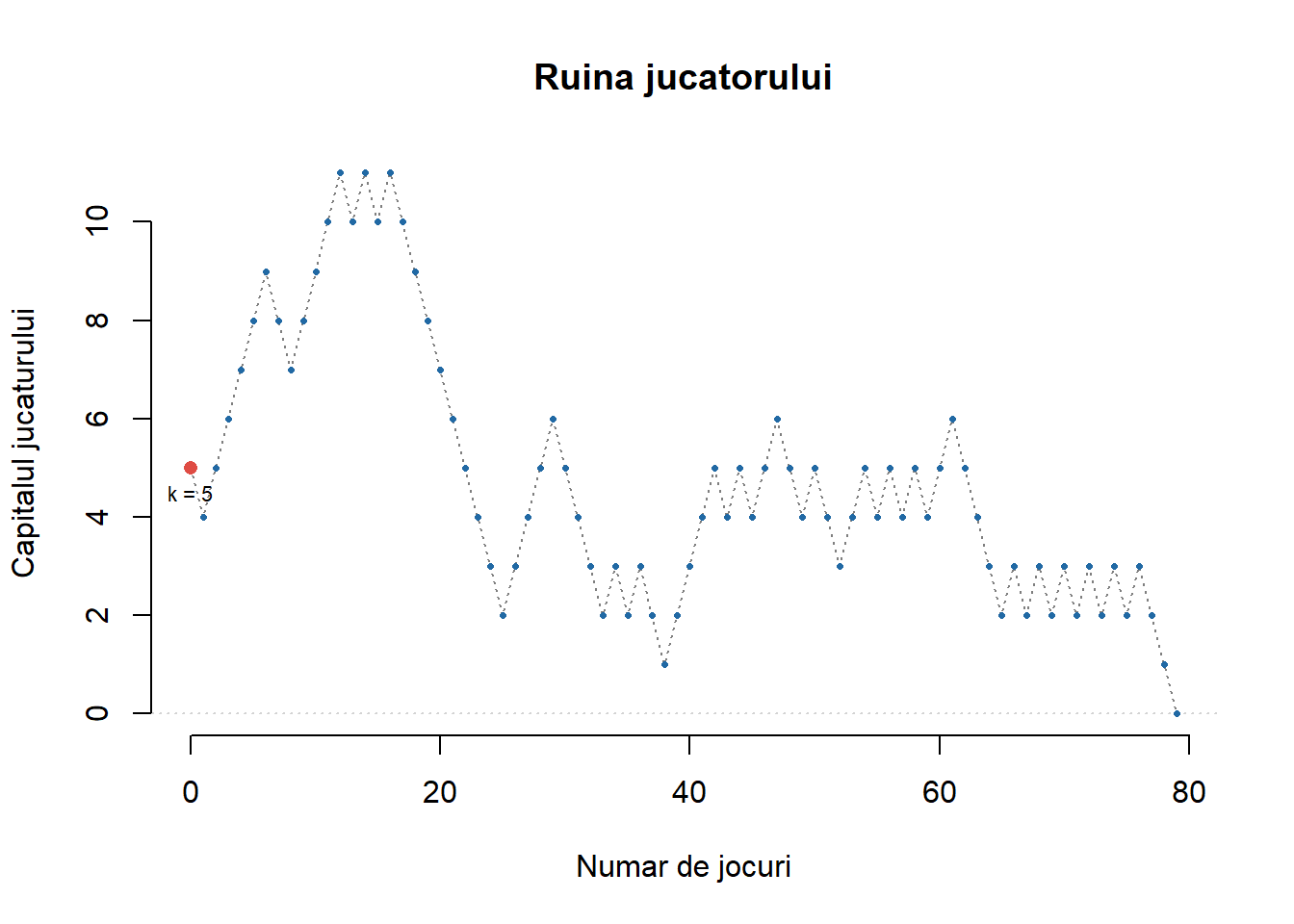
Dacă definim \(b_k = p_k - p_{k-1}\) pentru \(k\geq 1\) atunci \(b_k = b_{k-1}\), \(\forall k\geq2\). Prin urmare \(b_k = b_1\) și \(p_k = b_1+p_{k-1} = kb_1+p_0\). Observând că \(b_1+\cdots+b_N=p_N-p_0=-1\) deducem că \(b_1=-\frac{1}{N}\) iar \(p_k=1-\frac{k}{N}\).
Dorim să repetăm experimentul de \(M = 1000\) de ori (pentru valorile inițiale \(N = 50\) și \(k = 5\)) și ne interesăm de câte ori jucătorul a ajuns la faliment.
N <- 50
k <- 5
M <- 1000
# Obs. - rezultatul functiei ruina trebuie modificat
joc <- replicate(M, ruina(N, k)) # repeta functia de M ori
proba_ruina <- sum(joc == 0)/M Am obținut că probabilitatea empirică de faliment este 0.898 iar cea teoretică este 0.9.
Exercițiul 8.1 Să presupunem că fiecare cutie de cereale conține unul dintre cele \(n\) cupoane diferite existente. Odată ce o persoană a colecționat toate cele \(n\) cupoane poate să le trimită pentru a revendica un premiu. De asemenea, presupunem că fiecare cupon este ales uniform și independent din cele \(n\) posibilități existente și colecționarul nu colaborează cu alte persoane pentru a completa colecția. Întrebarea care se pune este câte cutii de cereale trebuie cumpărate, în medie, pentru a obține cel puțin unul din fiecare cupon?
Pentru a rezolva această problemă, să notăm cu \(X\) variabila aleatoare care descrie numărul de cutii de cereale cumpărate până când obținem toate cupoanele. Vrem să determinăm \(\mathbb{E}[X]\).
Să notăm cu \(X_i\) numărul suplimentar de cutii de cereale pe care trebuie să le cumpărăm atunci când avem \(i-1\) cupoane colecționate pentru a avea \(i\) cupoane diferite, \(i\geq 1\). Astfel putem scrie
\[ X = \sum_{i = 1}^{n}X_i, \]
de unde \(\mathbb{E}[X] = \sum_{i = 1}^{n}\mathbb{E}[X_i]\). Rămâne să determinăm \(\mathbb{E}[X_i]\) pentru \(i\in\{1,2,\ldots,n\}\).
Să remarcăm faptul că atunci când avem colectate \(i-1\) cupoane ne mai rămân \(n-i+1\) cupoane de colecționat, prin urmare probabilitatea de a alege un nou cupon este \(p_i=\frac{n-i+1}{n}\) și cum \(X_i\sim\text{Geom}(p_i)\) deducem că \(\mathbb{E}[X_i] = \frac{1}{p_i}\).
Avem
\[ \mathbb{E}[X] = \sum_{i = 1}^{n}\mathbb{E}[X_i] = \sum_{i = 1}^{n}\frac{1}{p_i} = \sum_{i = 1}^{n}\frac{n}{n-i+1} = n\sum_{i = 1}^{n}\frac{1}{i} = nH_n \]
ceea ce implică \(\mathbb{E}[X] = n\left(\log(n) + \mathcal{O}(1)\right)\) deoarece \(H_n = \log(n)+O(1)\)1).
Următorul cod R simulează problema colecționarului de cupoane:
simcollect <- function(n) {
coupons <- 1:n # multimea cupoanelor
collect <- numeric(n)
nums <- 0
while (sum(collect)<n)
{
# extragere cu intoarcere
i <- sample(coupons, 1)
collect[i] <- 1
nums <- nums + 1
}
return(nums)
}Pentru calculul mediei vom considera \(n = 20\) și vom repeta procedeul \(N = 10000\) de ori. Vom compara rezultatul empiric cu cel teoretic:
## Calculul mediei
n <- 20
Nrep <- 10000
simlist <- replicate(Nrep, simcollect(n))
# media empirica
mean(simlist)[1] 72.0268# media teoretica
n*sum(1/(1:n))[1] 71.95479Pentru calculul varianței avem că \(Var(X_i) = \frac{1-p_i}{p_i^2}\) și cum \(X_i\) sunt independente rezultă că
\[ Var(X) = \sum_{i = 1}^{n}Var(X_i) = \sum_{i = 1}^{n}\frac{1-p_i}{p_i} = n\sum_{i = 1}^{n}\frac{i-1}{(n-i+1)^2}. \]
Pentru compararea rezultatului empiric cu cel teoretic avem:
# varianta empirica
var(simlist)[1] 559.3548# varianta teoretica
n*sum((0:(n-1))/((n:1)^2))[1] 566.5105O aplicație a problemei colecționarului de cupoane este următoarea: să presupunem că într-un parc național din India, o cameră video automată fotografiază \(n\) tigrii care trec prin dreptul ei pe parcursul unui an și analizând fotografiile se constată că \(t\) dintre aceștia sunt diferiți. Ne propunem să estimăm (aproximăm) numărul total de tigrii din parc. În contextul problemei colecționarului de cupoane, presupunem că avem \(n\) cupoane diferite și că am cumpărat \(t\) cutii de cereale și ne întrebăm care este numărul mediu de cupoane distincte din cele \(t\).
Fie \(Y\) variabila aleatoare care ne dă numărul de cupoane distincte după \(t\) cutii cumpărate. Atunci putem scrie
\[ Y = I_1 + I_2 +\cdots+I_n \]
unde pentru \(j \in\{1,2,\ldots,n\}\)
\[ I_j = \left\{\begin{array}{ll} 1, \text{cuponul j se află printre cele t}\\ 0, \text{altfel} \end{array}\right. \]
Astfel,
\[ \begin{aligned} \mathbb{E}[I_j] &= \mathbb{P}(\text{cuponul j se află printre cele t}) = 1 - \mathbb{P}(\text{cuponul j nu se află printre cele t})\\ &= 1 - \left(1 - \frac{1}{n}\right)^t \end{aligned} \]
ceea ce conduce la
\[ \mathbb{E}[Y] = \sum_{j = 1}^{n}\mathbb{E}[I_j] = n\left[1 - \left(1 - \frac{1}{n}\right)^t\right]. \]
Pentru a determina numărul de tigrii din parc trebuie să găsim valoarea lui \(n\) știind numărul \(t\) de tigrii fotografiați de camera automată și de numărul mediu de tigrii distincți \(d\) determinați manual, deci trebuie să rezolvăm ecuația:
\[ d\approx \mathbb{E}[Y] = n\left[1 - \left(1 - \frac{1}{n}\right)^t\right] \]
Ecuația nu are o soluție explicită dar poate fi determinată numeric folosind funcția uniroot care permite găsirea unei rădăcini într-un interval dat a unei funcții reale:
f <- function(n, t = 100, d = 50){
n*(1 - (1 - 1/n)^t) - d
}
# pentru 100 de tigrii fotografiati dintre care 50 diferiti
ans <- uniroot(f, c(50, 200), t = 100, d = 50)
ans$root[1] 62.40844Pentru \(t = 100\) și \(d = 50\) estimăm în jur de 62 tigrii în parc.
Exercițiul 9.1 O monedă are probabilitatea să pice cap \(p\) și să pice coadă \(q\) astfel ca \(p+q=1\). Moneda este aruncată succesiv și independent până când evenimentul \(A\), am obținut două capete unul după altul sau două cozi una după alta, s-a realizat. Determinați numărul mediu de aruncări necesare realizării evenimentului de interes, \(A\).
Vom prezenta două soluții pentru acest exercițiu. În prima soluție vom începe prin a calcula funcția de masă pentru variabila care descrie experimentul și apoi vom calcula media. În cea de-a doua soluție vom calcula media cu ajutorul condiționării.
Fie \(X\) variabila aleatoare care reprezintă numărul de aruncări necesare pentru ca evenimentul \(A\) să se realizeze (numărul de aruncări necesare obținerii a \(2\) capete unul după altul sau a \(2\) cozi una după alta) și \(X_i\in\{H,T\}\) variabila aleatoare care descrie rezultatul obținut la cea de-a i-a aruncare. Evenimentul \(\{X=n\}\) poate fi exprimat ca reuniunea dintre \(A_n\) și \(B_n\), unde \(A_n\) reprezintă evenimentul să obținem două capete consecutive pentru prima oară la cea de-a \(n\)-a aruncare iar \(B_n\) este evenimentul să obținem două cozi consecutive la a \(n\)-a aruncare.
Se poate observa cu ușurință că un eveniment elementar din \(A_n\) are forma \(\omega = \underbrace{\cdots}_{n-2} HH\) și se poate determina în întregime datorită faptului că în primele \(n-2\) aruncări nu putem avea două realizări consecutive. În plus dacă \(n = 2k+1\) atunci
\[ \mathbb{P}(A_{2k+1}) = \mathbb{P}(X_1 = T, X_2 = H, \cdots, X_{2k-1}=T, X_{2k} = H, X_{2k+1} = H) \overset{indep.}{=} (pq)^kp \]
iar dacă \(n=2k+2\) atunci
\[ \mathbb{P}(A_{2k+2}) = \mathbb{P}(X_1 = H, X_2 = T, \cdots, X_{2k}=T, X_{2k+1} = H, X_{2k+2} = H) \overset{indep.}{=} (pq)^kp^2 \]
În mod similar se poate calcula probabilitatea evenimentului \(B_n\) pentru \(n=2k+1\)
\[ \mathbb{P}(B_{2k+1}) = \mathbb{P}(X_1 = H, X_2 = T, \cdots, X_{2k-1} = H, X_{2k} = T, X_{2k+1} = T) \overset{indep.}{=} (pq)^kq \]
și respectiv \(n=2k+2\)
\[ \mathbb{P}(B_{2k+2}) = \mathbb{P}(X_1 = T, X_2 = H, \cdots, X_{2k} = H, X_{2k+1} = T, X_{2k+2} = T) \overset{indep.}{=} (pq)^kq^2 \]
Cum \(\mathbb{P}(X=n) = \mathbb{P}(A_n) + \mathbb{P}(B_n)\) deducem că
\[ \mathbb{P}(X=n) =\left\{\begin{array}{ll} (pq)^{\frac{n-1}{2}}, & \text{$n$ impar}\\ (pq)^{\frac{n-2}{2}}(p^2+q^2), & \text{$n$ par} \end{array}\right. \]
Următoarea funcție simulează evenimentul din enunțul problemei:
flip_coins <- function(p){
flip <- sample(c("H", "T"), 1, prob = c(p, 1-p))
nflips <- 1
flag <- TRUE
while(flag){
x <- sample(c("H", "T"), 1, prob = c(p, 1-p))
nflips <- nflips + 1
if (flip == x){
flag <- FALSE
}
flip <- x
}
return(nflips)
}
flip_coins(0.2)[1] 2Înainte de a calcula media ne propunem să repetăm de \(N = 10000\) de ori experimentul (pentru \(p=0.3\)) și să comparăm rezultatul empiric cu cel teoretic.
N <- 10000
p <- 0.3
rez_flips <- replicate(N, flip_coins(p))Rezultatele sunt incluse în tabelul de mai jos:
| n | Empiric | Teoretic |
|---|---|---|
| 2 | 0.5833 | 0.58000 |
| 3 | 0.2069 | 0.21000 |
| 4 | 0.1233 | 0.12180 |
| 5 | 0.0432 | 0.04410 |
| 6 | 0.0257 | 0.02558 |
| 7 | 0.0094 | 0.00926 |
| 8 | 0.0047 | 0.00537 |
| 9 | 0.0019 | 0.00194 |
| 10 | 0.0007 | 0.00113 |
| 11 | 0.0005 | 0.00041 |
| 12 | 0.0002 | 0.00024 |
| 13 | 0.0001 | 0.00009 |
| 14 | 0.0001 | 0.00005 |
Pentru a calcula media avem
\[ \mathbb{E}[X] = \sum_{n=2}^{\infty}n\mathbb{P}(X=n) \]
iar dacă seriile \(\sum_{k=1}^{\infty}(2k+1)\mathbb{P}(X=2k+1)\) și \(\sum_{k=0}^{\infty}(2k+2)\mathbb{P}(X=2k+2)\) sunt convergente atunci putem scrie
\[ \mathbb{E}[X] = \sum_{n=2}^{\infty}n\mathbb{P}(X=n) = \sum_{k=1}^{\infty}(2k+1)\mathbb{P}(X=2k+1) + \sum_{k=0}^{\infty}(2k+2)\mathbb{P}(X=2k+2). \]
Se poate arăta cu ușurință că
\[ \sum_{k=1}^{\infty}(2k+1)\mathbb{P}(X=2k+1) = 2\sum_{k=1}^{\infty}(k+1)(pq)^k - \sum_{k=1}^{\infty}(pq)^k = \frac{pq(3-pq)}{(1-pq)^2} \]
și
\[ \sum_{k=0}^{\infty}(2k+2)\mathbb{P}(X=2k+2) = 2(p^2+q^2)\sum_{k=0}^{\infty}(k+1)(pq)^k = \frac{2(p^2+q^2)}{(1-pq)^2} \]
de unde concluzionăm că \(\mathbb{E}[X] = \frac{pq(3-pq)}{(1-pq)^2} + \frac{2(p^2+q^2)}{(1-pq)^2} = \frac{2+pq}{1-pq}\).
O a doua soluție pentru determinarea mediei este bazată pe condiționare. Fie \(H_k\) și respectiv \(T_k\) evenimentele prin care capul respectiv coada a apărut la cea de-a \(k\)-a aruncare și \(\mathbb{P}(H_k) = p\) iar \(\mathbb{P}(T_k) = q\). Din formula probabilității totale, avem că
\[ \mathbb{E}[X] = \mathbb{E}[X|H_1]\mathbb{P}(H_1) + \mathbb{E}[X|T_1]\mathbb{P}(T_1) = p\mathbb{E}[X|H_1] + q\mathbb{E}[X|T_1]. \]
Mai mult,
\[ \mathbb{E}[X|H_1] = p\mathbb{E}[X|H_1\cap H_2] + q\mathbb{E}[X|H_1\cap T_2] \]
și cum \(\mathbb{E}[X|H_1\cap H_2] = 2\) (evenimentul \(A\) s-a realizat la a doua aruncare) iar \(\mathbb{E}[X|H_1\cap T_2] = 1 + \mathbb{E}[X|T_1]\) (dacă jocul nu este gata doar ultima aruncare este importantă) obținem că
\[ \mathbb{E}[X|H_1] = 2p + q(1+\mathbb{E}[X|T_1]). \]
În mod similar găsim \(\mathbb{E}[X|T_1] = 2q + p(1+\mathbb{E}[X|H_1])\). Rezolvând sistemul de două ecuații cu două necunoscute obținem soluțiile \(\mathbb{E}[X|H_1] = \frac{2+q^2}{1-pq}\) și \(\mathbb{E}[X|T_1] = \frac{2+p^2}{1-pq}\) de unde media este \(\mathbb{E}[X] = \frac{2+pq}{1-pq}\).
Putem verifica numeric dacă formula pe care am găsit-o este corectă. Pentru aceasta vom repeta experimentul (\(p = 0.3\)) de \(N = 10000\) de ori.
Obținem că media empirică este 2.789 iar cea teoretică este 2.797.
Următoarele exerciții sunt exemple de utilizare a elementelor de probabilități în implementarea algoritmilor, rezultând în algoritmi randomizați. De cele mai multe ori, algoritmii rezultați sunt mai eficienți (în medie) decât versiunile deterministe existente.
Exercițiul 10.1 (Egalitatea a două polinoame) Având date două polinoame \(F(x)\) și \(G(x)\), cu \(F(x)=\prod_{i=1}^d(x-a_i)\) și \(G(x)\) dat sub forma canonică (\(\sum_{i=0}^d c_ix^i\)), vrem să verificăm dacă are loc identitatea
\[ F(x) \overset{?}{\equiv} G(x). \]
Știm că două polinoame sunt egale atunci când coeficienții lor în descompunerea canonică sunt egali. Observăm că dacă am transforma polinonum \(F(x)\) la forma sa canonică prin înmulțirea consecutivă a monomului \(i\) cu produsul primelor \(i-1\) monoame atunci am avea nevoie de \(\Theta(d^2)\) operații. În cele ce urmează presupunem că fiecare operație de înmulțire se poate face în timp constant, ceea ce nu corespunde în totalitate cu realitatea în special în cazurile în care vrem să înmulțim coeficienți mari.
Ne propunem să construim un algoritm randomizat care să verifice această egalitate într-un număr mai mic de operații (\(O(d)\) operații). Să presupunem că \(d\) este gradul maxim al lui \(x\) (exponentul cel mai mare) în \(F(x)\) și \(G(x)\). Algoritmul poate fi descris astfel: alegem uniform un număr \(r\) din mulțimea \(\{1,2,\ldots,100d\}\) (prin uniform înțelegem că cele \(100d\) numere au aceeași șansă să fie alese) și calculăm valorile lui \(F(r)\) și \(G(r)\). Dacă \(F(r)\neq G(r)\) atunci algoritmul întoarce că cele două polinoame nu sunt egale iar dacă \(F(r)=G(r)\) atunci algoritmul întoarce că cele două polinoame sunt egale. Algoritmul poate greși doar dacă cele două polinoame nu sunt egale dar \(F(r)=G(r)\). Vrem să evaluăm această probabilitate.
Experimentul nostru poate fi modelat cu ajutorul tripletului \((\Omega, \mathcal{F}, \mathbb{P})\) unde \(\Omega = \{1,2,\ldots,100d\}\), \(\mathcal{F}=\mathcal{P}(\Omega)\) iar \(\mathbb{P}\) este echirepartiția pe \(\Omega\). Fie \(E\) evenimentul că algoritmul greșește, acest eveniment se realizează doar dacă numărul aleator \(r\) este o rădăcină a polinomului \(F(x)-G(x)\), de grad cel mult \(d\). Cum din Teorema Fundamentală a Algebrei acest polinom nu poate avea mai mult de \(d\) rădăcini rezultă că
\[ \mathbb{P}(\text{algoritmul greseste}) = \mathbb{P}(E) \leq \frac{d}{100d} = \frac{1}{100}. \]
Putem să îmbunătățim această probabilitate? O variantă ar fi să mărim spațiul stărilor la \(\Omega = \{1,2,\ldots,1000d\}\) și atunci șansa ca algoritmul să greșească ar fi de \(\frac{1}{1000}\). O altă variantă ar fi să repetăm procedeul de mai multe ori, iar în această situație algoritmul ar fi eronat doar dacă ar întoarce că cele două polinoame sunt egale când în realitate ele nu sunt. Atunci când repetăm procesul, alegerea numărului aleator \(r\) se poate face în două moduri diferite: cu întoarcere (nu ținem cont de numerele ieșite) sau fără întoarcere (ținem cont de numerele ieșite).
Dacă luăm \(E_i\) evenimentul prin care la a i-a rulare a algoritmului am extras o rădăcină \(r_i\) astfel încât \(F(r_i)=G(r_i)\), atunci probabilitatea ca algoritmul să întoarcă un răspuns greșit după \(k\) repetări, este
\[ \mathbb{P}(E_1\cap E_2\cap \cdots\cap E_k). \]
În cazul în care alegerea se face cu întoarcere (evenimentele sunt independente) obținem
\[ \mathbb{P}(E_1\cap E_2\cap \cdots\cap E_k) = \prod_{i=1}^{k}\mathbb{P}(E_i)\leq\prod_{i=1}^{k}\frac{d}{100d} = \left(\frac{1}{100}\right)^k, \]
iar dacă extragerea s-a făcut fără întoarcere (evenimentele nu mai sunt independente), atunci folosind regula de multiplicare avem
\[\begin{align*} \mathbb{P}(E_1\cap E_2\cap \cdots\cap E_k) &= \mathbb{P}(E_1)\mathbb{P}(E_2|E_1)\cdots\mathbb{P}(E_k|E_1\cap\cdots\cap E_{k-1})\\ &\leq \prod_{i=1}^{k}\frac{d - (i-1)}{100d - (i-1)} \leq \left(\frac{1}{100}\right)^k. \end{align*}\]
Fx = function(x){
return((x+1)*(x-2)*(x+3)*(x-4)*(x+5)*(x-6))
}
Gx = function(x){
return(x^6 - 7*x^3 + 25)
}
Gx2 = function(x){
return(x^6 - 3*x^5 - 41*x^4 + 87*x^3 + 400*x^2 - 444*x - 720)
}
comparePols = function(Fx, Gx){
k = 3 # repetam algoritmul de 3 ori
d = 6 # gradul polinomului
for (i in 1:k){
r = floor(100*d*runif(1)) + 1
f1 = Fx(r)
g1 = Gx(r)
if (f1!=g1){
return(cat("Cele doua polinoame sunt diferite ! \nPentru r =",
r, "avem ca F(r)!=G(r) (", f1, "!=", g1, ")"))
}
}
return(cat("Polinoamele sunt egale. Eroarea este de", 100^(-k)))
}
comparePols(Fx, Gx)Cele doua polinoame sunt diferite !
Pentru r = 461 avem ca F(r)!=G(r) ( 9.534242e+15 != 9.598548e+15 )comparePols(Fx, Gx2)Polinoamele sunt egale. Eroarea este de 1e-06În cele ce urmează vom prezenta o altă aplicație în care algoritmul randomizat este mult mai eficient decât orice algoritm determinist cunoscut până în acest moment.
Exercițiul 10.2 (Produsul a două matrice) Să presupunem că avem trei matrice pătratice \(\bf{A}\), \(\bf{B}\) și \(\bf{C}\) de dimensiune \(n \times n\). Pentru simplitate considerăm că avem de-a face cu matrice cu elemente de \(0\) și \(1\) iar operațiile se fac \(\mod2\). Vrem să construim un algoritm randomizat care să verifice egalitatea:
\[ \bf{A}\cdot\bf{B}=\bf{C} \qquad (\text{mod 2}). \]
O modalitate ar fi să calculăm elementele matricii \(\bf{C}'=\bf{A}\cdot\bf{B}\), folosind relația \(C'_{i,j} = \sum_{k=1}^{n}A_{i,k}B_{k,j}\), și să le comparăm cu elementele matricii \(\bf{C}\). Metoda naivă de multiplicare a celor două matrice necesită cel mult \(O(n^3)\) operații. Știm că există algoritmi (netriviali) care permit multiplicarea matricilor într-un număr mai mic de operații, ca de exemplu:
Propoziție 10.1 (Strassen 1969) Este posibil să înmulțim două matrice în aproape \(n^{\log_27}\approx n^{2.81}\) operații.
iar o versiune îmbunătățită a algoritmului lui Strassen (și cea care deținea recordul până în 20142)
Propoziție 10.2 (Coppersmith-Winograd 1987) Este posibil să înmulțim două matrice în aproape \(n^{2.376}\) operații.
Noi nu vom vorbi despre algoritmi de multiplicare a două matrice, ci de algoritmi de verificare a acestei operații. Pentru aceasta vom considera un algoritm randomizat care verifică înmulțirea în aproximativ \(n^2\) operații (\(O(n^2)\)) cu precizarea că acest algoritm poate conduce la un răspuns eronat.
Propoziție 10.3 (Freivalds 1979) Există un algoritm probabilist care poate verifica dacă \(\bf{A}\cdot\bf{B}=\bf{C} \quad (\text{mod 2})\) în \(O(n^2)\) operații și având o eroare de \(2^{-200}\).
Algoritmul lui de bază a lui Freivalds este următorul:
Alegem uniform un vector \(\bf{r}=(r_1,r_2,\ldots,r_n)\in\{0,1\}^n\) (unde prin ales uniform înțelegem că fiecare \(r_i\) este ales de manieră independentă cu probabilitatea de \(0.5\) să ia valoarea \(0\) sau \(1\)3)
Calculăm \(y = \bf{A}\bf{B}\bf{r}\) și \(z = \bf{C}\bf{r}\). Dacă \(y = z\) atunci algoritmul întoarce multiplicarea este corectă altfel multiplicarea matricelor este eronată.
Observăm că acest algoritm necesită trei operații de multiplicare între o matrice și un vector, prin urmare acesta necesită \(O(n^2)\) pași. De asemenea, remarcăm că algoritmul întoarce un răspuns eronat atunci când \(\bf{A}\cdot\bf{B}\neq\bf{C}\) dar \(\bf{A}\bf{B}\bf{r} = \bf{C}\bf{r}\). Probabilitatea ca algoritmul să întoarcă un raspuns eronat verifică
\[ \mathbb{P}(\text{algoritmul intoarce raspuns gresit}) = \mathbb{P}(\bf{A}\bf{B}\bf{r} = \bf{C}\bf{r}) \leq \frac{1}{2}. \]
Pentru a verifica acest rezultat, fie \(\bf{D} = \bf{A}\cdot\bf{B}-\bf{C} \neq 0\). Evenimentul \(\{\bf{A}\bf{B}\bf{r} = \bf{C}\bf{r}\}\) implică \(\bf{D}\bf{r}=0\) și cum \(\bf{D}\neq 0\) putem presupune că elementul \(d_{1,1}\neq 0\). Deoarece \(\bf{D}\bf{r}=0\) rezultă că \(\sum_{j=1}^{n}d_{1,j}r_j=0\) sau, echivalent
\[ r_1 = -\frac{\sum_{j=2}^{n}d_{1,j}r_j}{d_{1,1}}. \]
Avem
\[\begin{align*} \mathbb{P}(\bf{A}\bf{B}\bf{r} = \bf{C}\bf{r}) &= \sum_{(x_2,\cdots, x_n)\in\{0,1\}^n}\mathbb{P}\left(\{\bf{A}\bf{B}\bf{r} = \bf{C}\bf{r}\}\cap \{(r_2,\cdots, r_n) = (x_2,\cdots, x_n)\}\right)\\ &\leq \sum_{(x_2,\cdots, x_n)\in\{0,1\}^n}\mathbb{P}\left(\left\{r_1 = -\frac{\sum_{j=2}^{n}d_{1,j}r_j}{d_{1,1}}\right\}\cap \{(r_2,\cdots, r_n) = (x_2,\cdots, x_n)\}\right)\\ &\leq \sum_{(x_2,\cdots, x_n)\in\{0,1\}^n}\mathbb{P}\left(\left\{r_1 = -\frac{\sum_{j=2}^{n}d_{1,j}r_j}{d_{1,1}}\right\}\right)\mathbb{P}\left(\{(r_2,\cdots, r_n) = (x_2,\cdots, x_n)\}\right)\\ &\leq \sum_{(x_2,\cdots, x_n)\in\{0,1\}^n}\frac{1}{2}\mathbb{P}\left(\{(r_2,\cdots, r_n) = (x_2,\cdots, x_n)\}\right)\\ &= \frac{1}{2}. \end{align*}\]
În relațiile de mai sus am folosit faptul că \(r_1\) și \((r_2,\cdots, r_n)\) sunt independente.
Pentru a îmbunătății eroarea algoritmului putem să repetăm procedeul de \(k\) ori4 și în acest caz probabilitatea de eroare devine \(2^{-k}\) iar numărul de operații \(O(kn^2)\).
FreivaldsAlg <- function(A, B, C){
# Algoritmul Freivalds
n <- dim(A)[1] # dimensiunea matricelor
k <- ceiling(log(n)) # numarul de repetari ale algoritmului
for (i in 1:k){
r <- rbinom(n, 1, prob = 0.5)
y <- B %*% r
y <- A %*% y
y <- y %% 2
z <- C %*% r
z <- z %% 2
if (any(y != z)){
return(print("Multiplicarea matricelor este incorecta!"))
}
}
return(cat("Multiplicarea matricelor este corecta!
\nProbabilitatea de eroare a algoritmului este", 2^{-k}))
}
# Exemplul 1
set.seed(1234)
A <- matrix(rbinom(225, 1, 0.5), nrow = 15)
B <- matrix(rbinom(225, 1, 0.5), nrow = 15)
C <- A %*% B
C <- C %% 2
FreivaldsAlg(A, B, C)Multiplicarea matricelor este corecta!
Probabilitatea de eroare a algoritmului este 0.125# Exemplul 2
set.seed(5678)
A1 <- matrix(rbinom(625, 1, 0.5), nrow = 25)
B1 <- matrix(rbinom(625, 1, 0.5), nrow = 25)
C1 <- A1 %*% t(B1)
C1 <- C1 %% 2
C2 <- A1 %*% B1
C2 <- C2 %% 2
FreivaldsAlg(A1, B1, C1)[1] "Multiplicarea matricelor este incorecta!"FreivaldsAlg(A1, B1, C2)Multiplicarea matricelor este corecta!
Probabilitatea de eroare a algoritmului este 0.0625# Exemplul 3
set.seed(5678910)
A3 <- matrix(rbinom(1000000, 1, 0.5), nrow = 1000)
B3 <- matrix(rbinom(1000000, 1, 0.5), nrow = 1000)
C3 <- A3 %*% B3
C3 <- C3 %% 2
FreivaldsAlg(A3, B3, C3)Multiplicarea matricelor este corecta!
Probabilitatea de eroare a algoritmului este 0.0078125În practică, algoritmul Quicksort este unul din cei mai rapizi și mai populari algoritmi de sortare. Unul dintre motivele acestui fapt este că algoritmul nu necesită memorie de stocare suplimentară. Cu toate acestea, algoritmul Quicksort este un algoritm destul de slab atunci când luăm în calcul scenariile teoretice de tipul cel mai rău caz. Vom vedea, în cele ce urmează, că versiunea randomizată a acestui algoritm are, în medie, o performanță foarte bună.
Algoritmul primește ca input o listă \(S = \{x_1,\ldots, x_n\}\) de \(n\) numere care, pentru ușurință, vor fi presupuse diferite. Pseudocodul algoritmului este:
Input: O listă \(S = \{x_1,\ldots, x_n\}\) de \(n\) elemente distincte pe o mulțime total ordonată.
Output: Elementele listei \(S\) sortate crescător.
Următoarea animație este ilustrativă (doar în versiunea HTML):
Să observăm că există situații (de tipul cel mai rău caz) în care algoritmul Quicksort necesită \(\Omega(n)\)5 operații de comparare. De exemplu să presupunem că lista de input este \(S = \{x_1=n,x_2=n-1,\ldots,x_n=1\}\) și să presupunem că pentru alegerea pivotului adoptăm regula ca acesta să fie primul element din listă. Prin urmare primul pivot ales este \(n\) și algoritmul necesită \(n-1\) comparații. În urma diviziunii, rezultă două subliste, una de lungime \(0\) (care nu necesită nicio operație suplimentară) și una de lungime \(n-1\) (ce elementele \(n-1, n-2, \ldots, 1\)). La pasul doi, următorul pivot ales este \(n-1\) iar algoritmul necesită \(n-2\) comparații și întoarce sublista cu elemente \(n-2, \ldots, 1\). Continuând procedeul deducem că algoritmul Quicksort efectuează
\[ (n-1) + (n-2) + \cdots + 1 = \frac{n(n-1)}{2} \quad \text{operații}. \]
Din exemplul de mai sus, este clar că alegerea pivotului influențează puternic numărul de operații pe care le efectuează algoritmul. O alegere mai bună a pivotului ar consta în determinarea unui element, la fiecare pas, care să împartă lista în două subliste cam de aceeași mărime (\(\lceil n/2\rceil\) elemente).
Întrebarea care se pune este cum putem garanta că algoritmul alege un pivot bun suficient de des ? O modalitate ar fi să alegem pivotul aleator, de manieră uniformă între elementele disponibile. Această abordare face ca algoritmul Quicksort să devină randomizat.
Exercițiul 10.3 (Quicksort randomizat) Să presupunem că ori de câte ori un pivot este ales pentru algoritmul Quicksort randomizat, acesta este ales independent și uniform din mulțimea elementelor posibile. Arătați că numărul mediu de comparări ale algoritmului este de \(2n\log(n)+O(n)\). Scrieți o funcție care implementează algoritmul Quicksort randomizat cu pivot ales uniform.
Fie \(y_1,\ldots, y_n\) elementele \(x_1,\ldots, x_n\) ordonate crescător. Pentru \(i<j\), fie \(X_{ij}\) variabila aleatoare care ia valoarea \(1\) dacă elementele \(y_i\) și \(y_j\) au fost comparate pe parcursul rulării algoritmului și valoarea \(0\) altfel. Atunci numărul total de comparări \(X\) satisface relația
\[ X = \sum_{i = 1}^{n-1}\sum_{j = i+1}^{n}X_{ij} \]
și din proprietatea de liniaritate a mediei
\[ \mathbb{E}[X] = \mathbb{E}\left[\sum_{i = 1}^{n-1}\sum_{j = i+1}^{n}X_{ij}\right] = \sum_{i = 1}^{n-1}\sum_{j = i+1}^{n}\mathbb{E}[X_{ij}]. \]
Cum \(X_{ij}\) este o variabilă aleatoare de tip Bernoulli care ia doar valoarea \(0\) și \(1\), \(\mathbb{E}[X_{ij}]=\mathbb{P}(X_{ij}=1)\) prin urmare trebuie să determinăm probabilitatea ca elementele \(y_i\) și \(y_j\) să fie comparate pe parcursul algoritmului. Să observăm că elementele \(y_i\) și \(y_j\) sunt comparate dacă și numai dacă oricare dintre cele două elemente sunt alese ca pivot din mulțimea \(A_{ij} = \{y_i,y_{i+1},\ldots, y_j\}\). Acest lucru se datorează faptului că dacă \(y_i\) (sau \(y_j\)) a fost primul pivot ales din mulțimea \(A_{ij}\) atunci elementele \(y_i\) și \(y_j\) rămân în aceeași sublistă, deci vor fi comparate ulterior. În mod similar, dacă niciunul din elementele \(y_i\) și \(y_j\) nu este primul pivot ales din mulțimea \(A_{ij}\) atunci cele două elemente vor face parte din subliste separate și nu vor mai fi comparate.
Cum pivoții sunt aleși de manieră independentă și uniform din fiecare sublistă de elemente, prima dată când un pivot este ales din mulțimea \(A_{ij}\) acesta are aceeași șansă să fie oricare element. Prin urmare probabilitatea ca \(y_i\) sau \(y_j\) să fie primul pivot ales este \(\frac{2}{j-i+1}\). Astfel obținem
\[\begin{align*} \mathbb{E}[X] &= \sum_{i = 1}^{n-1}\sum_{j = i+1}^{n}\mathbb{E}[X_{ij}] = \sum_{i = 1}^{n-1}\sum_{j = i+1}^{n}\frac{2}{j-i+1} \\ &= \sum_{i = 1}^{n-1}\sum_{k = 2}^{n-i+1}\frac{2}{k} = \sum_{k = 2}^{n}\sum_{i = 1}^{n+1-k}\frac{2}{k} \\ &= \sum_{k = 2}^{n}(n+1-k)\frac{2}{k} = (2n+2)\sum_{k = 1}^{n}\frac{1}{k} - 4n. \end{align*}\]
Prin urmare \(\mathbb{E}[X] = 2(n+1)H_n - 4n = 2n\log(n) + O(n)\) (am folosit faptul că \(H_n = \log(n)+O(1)\).
Următorul cod implementează algoritmul Quicksort randomizat:
quickSort <- function(vect) {
# Args:
# vect: Vector numeric
# daca lungimea este <= 1 stop
if (length(vect) <= 1) {
return(vect)
}
# alege pivotul
ide <- sample(1:length(vect),1)
element <- vect[ide]
partition <- vect[-ide]
# Imparte elementele in doua subliste (< pivot si >= pivot)
v1 <- partition[partition < element]
v2 <- partition[partition >= element]
# Aplica recursiv algoritmul
v1 <- quickSort(v1)
v2 <- quickSort(v2)
return(c(v1, element, v2))
}
n <- 25
S <- sample(1:n, n, replace = FALSE)
# lista neordonata
S [1] 6 16 25 17 23 18 21 15 14 24 12 20 2 3 8 5 4 22 19 7 10 9 11 13 1# lista ordonata
quickSort(S) [1] 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25Numărul mediu de comparații pe care le efectuează algoritmul Quicksort randomizat, versiunea empirică versus cea teoretică de mai sus, este ilustrat în figura următoare:
N <- 1000
y <- rep(0, N)
for (i in 1:N){
S <- sample(1:i, i, replace = FALSE)
count <- 0
S_sort <- quickSort(S)
y[i] <- count
}
# Functia care calculeaza numarul de operatii teoretice
T_n <- function(n){
return(2*(n+1)*sum(1/(1:n))-4*n)
}
theo_T <- sapply(1:N, function(x){T_n(x)})
# Graficul
plot(1:N, y, type = "l",
col = "grey80",
bty = "n",
main = "Algoritmul Quicksort",
xlab = "Numar de elemente de comparat",
ylab = "Numar de comparatii",
lty = 3,
lwd = 0.5)
points(1:N, y,
col = "royalblue",
pch = 16,
cex = 0.6)
lines(1:N, theo_T, col = "brown3", lwd = 3, lty = 2)
legend('bottomright',
legend = c("Empiric", "Teoretic"),
fill = c("royalblue", "brown3"),
bty = "n")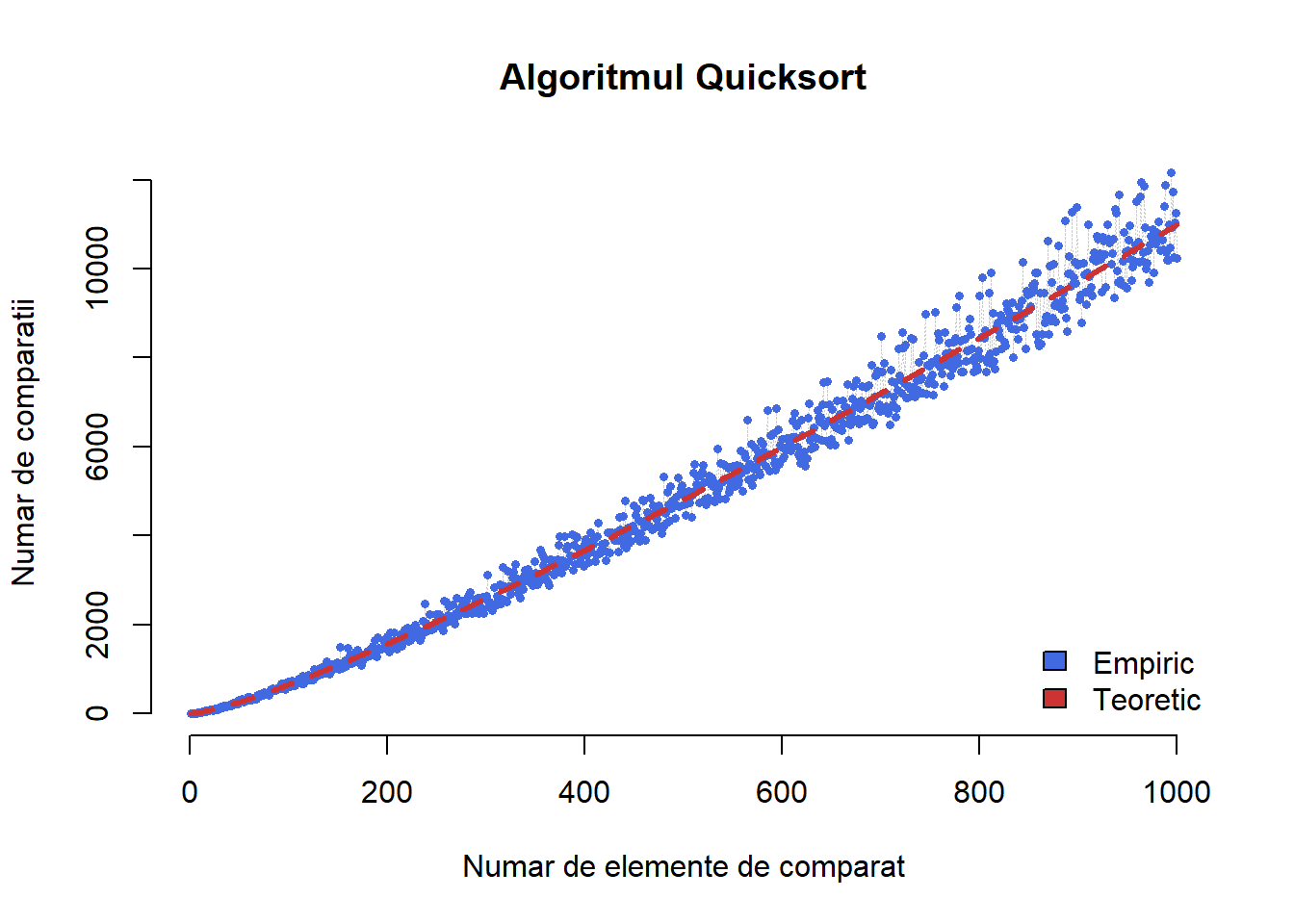
A se vedea pagina de wikipedia armonic_number↩︎
Actualul record este \(O(n^{2.3728})\) dat de Vassilevska Williams↩︎
Putem să ne imaginăm că aruncăm cu un ban echilibrat de \(n\) ori și convertim capul în \(1\) și pajura în \(0\).↩︎
Algoritmul lui Freivalds presupune \(k = 200\).↩︎
A se vedea pagina de wikipedia Big_O_notation↩︎